前言
上篇文章《LangGraph实战项目:从零手搓DeepResearch(二)------DeepResearch架构设计与实现》详细分享了如何基于 Pipeline-Agent 架构编写多智能体,实现了一个完整的 DeepResearch 应用。该系统通过任务规划、网络搜索和报告生成三个核心智能体的协同工作,通过代码完成了从问题分析到研究报告生成的全流程。
不过,上篇文章结尾留下了一个值得思考的问题:既然身处 LangChain/LangGraph 的开发环境,而 LangGraph 本身就是一个天然的多智能体框架,为什么不直接利用它来整合这三个智能体,构建更优雅的多智能体应用呢?本期文章就来深入探讨如何利用 LangGraph 的图模式重新构建 DeepResearch 多智能体应用,并将最终成果部署为可访问的 Web 服务。让我们一起来看看这个升级过程吧!
《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏内容源自笔者在实际学习和工作中对 LangChain 与 LangGraph 的深度使用经验,旨在帮助大家系统性地、高效地掌握 AI Agent 的开发方法,在各大技术平台获得了不少关注与支持。目前基础部分已更新 20 讲,接下来将重点推出实战项目篇,并随时补充笔者在实际工作中总结的拓展知识点。如果大家感兴趣,欢迎关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。
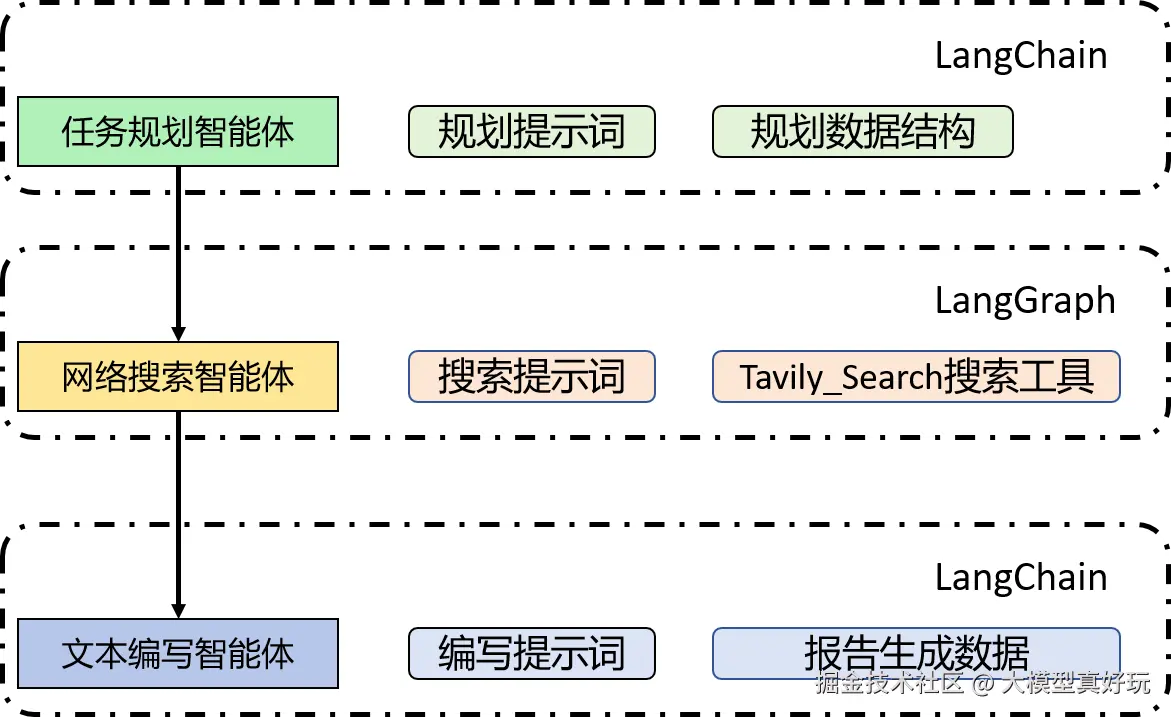
一、 LangGraph多智能体图结构封装
接下来,我们将上篇文章中编写的三个智能体------任务规划智能体、网络搜索智能体和报告生成智能体使用 LangGraph 封装成一个完整的图结构。
该图共包含五个节点:
- 一个开始节点
- 一个结束节点
- 三个智能体节点
节点之间的连接顺序为:
任务规划智能体 → 网络搜索智能体 → 报告生成智能体
以下的代码会涉及到比较多的LangGraph底层图搭建的基本内容,不太了解的大家可参考笔者文章 深入浅出LangGraph AI Agent智能体开发教程(六)---LangGraph 底层API入门。下面是具体步骤:
- 首先引入构建图的依赖:
python
from langchain_core.runnables import Runnable
from langgraph.graph import StateGraph, MessagesState, START, END这里的MessageState是LangGraph内置的State类型,其源码结构如下:(与笔者在文章《深入浅出LangGraph AI Agent智能体开发教程(八)---LangGraph底层API实现ReACT智能体》中多轮对话机器人实现一致,通过列表保存上下文消息)
python
class MessagesState(TypedDict):
messages: Annotated[list, add_messages]- 将任务规划智能体封装为 LangGraph 节点。该节点从消息列表中取出最近的用户提问,本图中不同智能体间的消息传递全部通过消息列表
messages传递。调用planner_chain生成WebSearchPlan,并加入异常处理逻辑,确保类型解析的稳定性:
python
def planner_node(state: MessagesState):
user_query = state['messages'][-1].content
raw = planner_chain.invoke({
'query': user_query
})
# 这里要注意的是 执行结果可能是WebSearchPlan类型,也可能是字典类型(被python解析了), 为了严谨性,这里加一个捕捉一场逻辑
try:
plan = parse_obj_as(WebSearchPlan, raw)
except ValidationError:
if isinstance(raw, dict) and isinstance(raw.get('searches'), list):
plan = WebSearchPlan(
searches = [WebSearchItem(query=q, reason=r) for q,r in raw['searches']]
)
else:
raise
return {
'plan': plan, # 保存原生对象到状态中,后面节点也可以直接使用
'messages': [AIMessage(content=plan.model_dump_json())]
}- 将网络搜索智能体封装为LangGraph节点,遍历搜索列表,调用搜索智能体获取结果,并将所有搜索摘要整合为一条 AI 消息:,
python
def search_node(state: MessagesState):
plan_json = state["messages"][-1].content
plan = WebSearchPlan.model_validate_json(plan_json)
summaries = []
for item in plan.searches:
run = search_agent.invoke({"messages": [HumanMessage(content=item.query)]})
msgs = run['messages']
# 取可读内容:也就是最后一条ToolMessage 或 AIMessage的内容
readable = next(
(m for m in reversed(msgs) if isinstance(m,(ToolMessage, AIMessage))), msgs[-1]
)
summaries.append(f'## {item.query}\n\n{readable.content}')
combined = "\n\n".join(summaries)
return {
'messages': [AIMessage(content=combined)]- 将报告编写智能体转化为LangGraph节点,将原始问题和搜索摘要整合,输入
writer_chain生成最终报告:
python
def writer_node(state: MessagesState):
original_query = state['messages'][0].content
combined_summary = state['messages'][-1].content
writer_input = (
f'原始问题: {original_query}\n\n'
f'搜索摘要:\n{combined_summary}'
)
report:ReportData = writer_chain.invoke({'content': writer_input})
return {
'messages': [AIMessage(content=json.dumps(report.dict, ensure_ascii=False, indent=2))]
}- 添加对应的点和边完成图的构建与编译:
python
# 构建图
builder=StateGraph(MessagesState)
builder.add_node("planner node", planner_node)
builder.add_node("search node",search_node)
builder.add_node("writer node", writer_node)
builder.add_edge(START, 'planner_node')
builder.add_edge('planner_node', 'search_node')
builder.add_edge('search_node', 'writer_node')
builder.add_edge('writer_node', END)
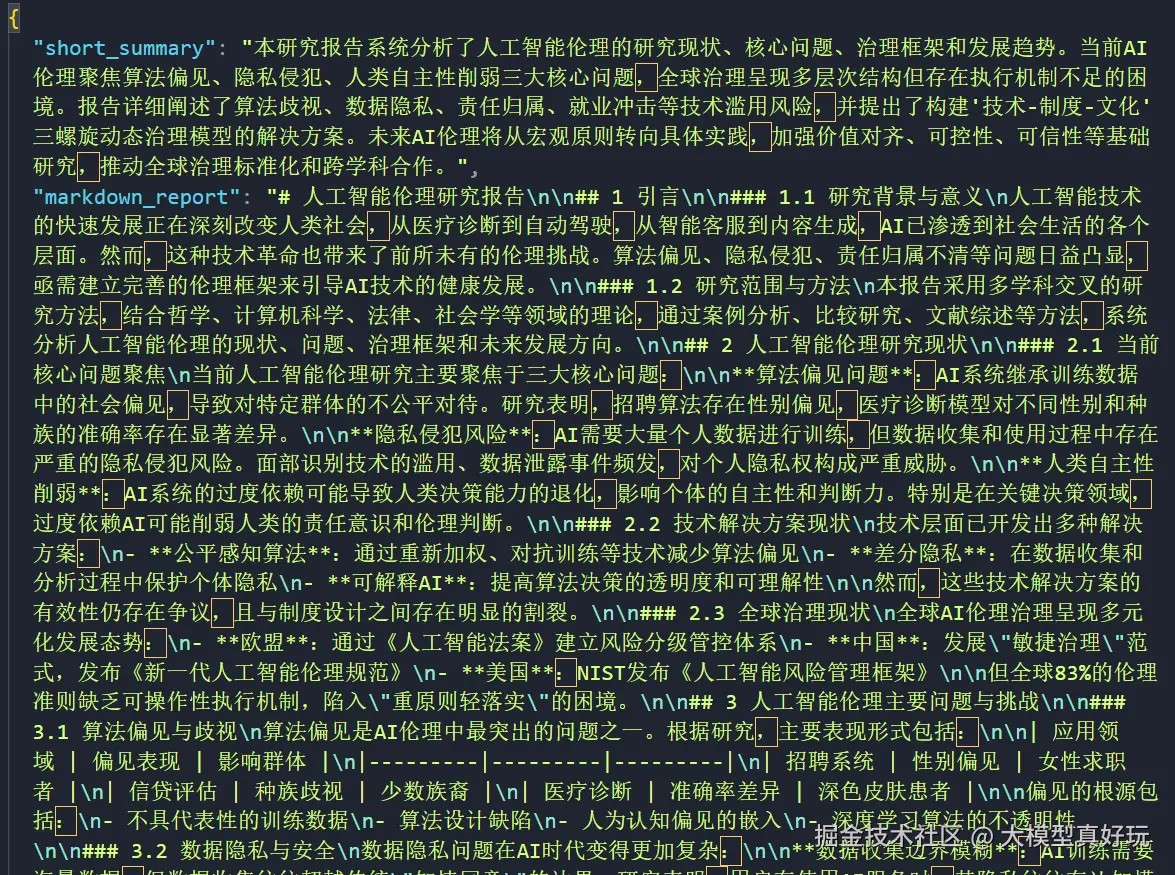
graph = builder.compile()- 编译完成后可以测试该 DeepResearch 应用,例如让它生成一份关于"人工智能伦理"的研究报告:
python
initial_state = {
'messages': [HumanMessage(content='请生成一份关于人工智能伦理的研究报告')]
}
final_state = graph.invoke(initial_state)
print(final_state['messages'][-1].content)可以看到智能体成功输出了一份指定格式的报告内容:
二、多智能体应用部署
除了使用 LangGraph 框架整合三个智能体外,还需要进一步完善应用功能。目前的应用还停留在代码运行层面,距离真正的可用产品还有差距。该项目的目标是将构建好的智能体打包上线,让用户能够通过前端界面实时体验其运行效果。
下面笔者将利用 LangGraph 的技术生态,快速完成 DeepResearch 多智能体应用的打包和部署。这部分内容在笔者的教程中已有详细讲解,具体步骤可参考:深入浅出LangGraph AI Agent智能体开发教程(五)--- LangGraph 数据分析助手智能体项目实战
2.1 后端服务部署
-
创建一个名为
langgraph_chatbot文件夹作为项目根目录 -
在文件夹中新建
requirements.txt文件, 填入项目运行所需的依赖:pythonpydantic python-dotenv langgraph langchain-core langchain-deepseek langchain-tavily langsmith langchain-openaidapters UV -
新建
.env文件,填入敏感信息配置,这里要注意的是如果不需要LangSmith监控智能体运行状态,不需要设置中间三个环境变量,关于LangSmith API KEY的注册使用大家可以参考笔者的文章:深入浅出LangGraph AI Agent智能体开发教程(四)---LangGraph全生态开发工具使用与智能体部署pythonDEEPSEEK_API_KEY= LANGSMITH_TRACING=true LANGSMITH_API_KEY= LANGSMITH_PROJECT=langgraph_studio_chatbot TAVILY_API_KEY= -
创建
graph.py文件,将之前编写的智能体代码整合到该文件中,直至完成graph = builder.compile()。由于篇幅原因具体代码这里就不再赘述,大家需要源码的可关注笔者的同名微信公众号 大模型真好玩 ,并私信LangChain智能体开发免费获取该系列所有代码。 -
创建
langgraph.json文件,在该json文件中配置项目入口和依赖信息。遵循规范如下:- 必须包含 dependencies和graphs 字段
- graphs 字段格式:"图名":"文件路径:变量名"
- 配置文件必须放在与Python文件同级或更高级的目录
- 注意:项目文件的名称必须为langgraph.json。
python{ "dependencies": [ "./" ], "graphs": { "chatbot": "./graph.py:graph" }, "env": ".env" } -
进入到
langgraph_chatbot文件夹下,执行langgraph dev即可启动项目。启动成功后看到三个链接,第一个链接是部署完成的服务端口,第二个是LangSmith的监控页面,第三个是端口的说明文档。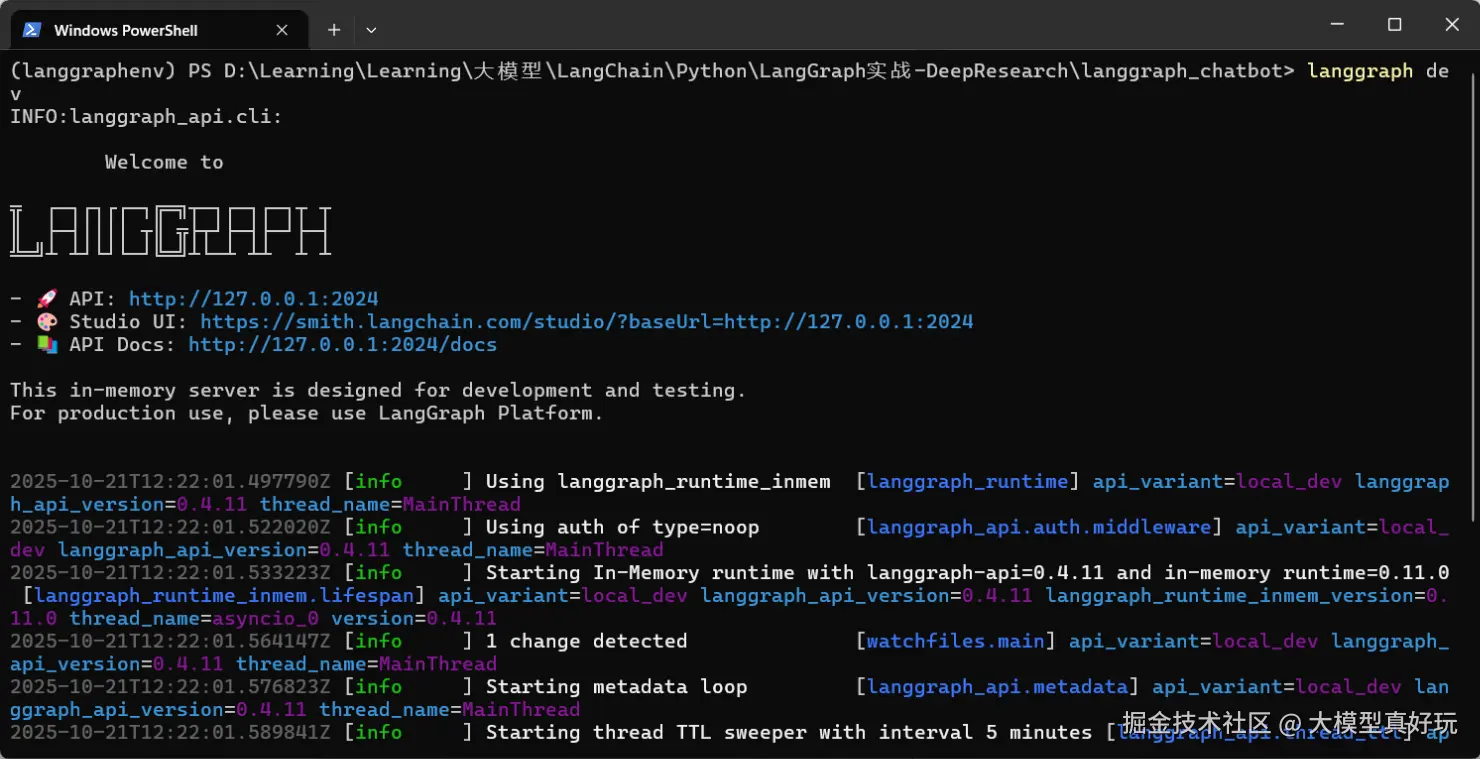
2.2 前端界面部署
部署好后端服务后我们还需要为当前后端接入一个前端页面,详细步骤如下:
-
访问 Agent Chat UI GitHub 页面,克隆项目到本地:
-
在已安装
node.js的基础上,进入agent-chat-ui文件夹,依次执行以下命令:pythonnpm install # 安装项目依赖 npm run dev # 启动开发服务器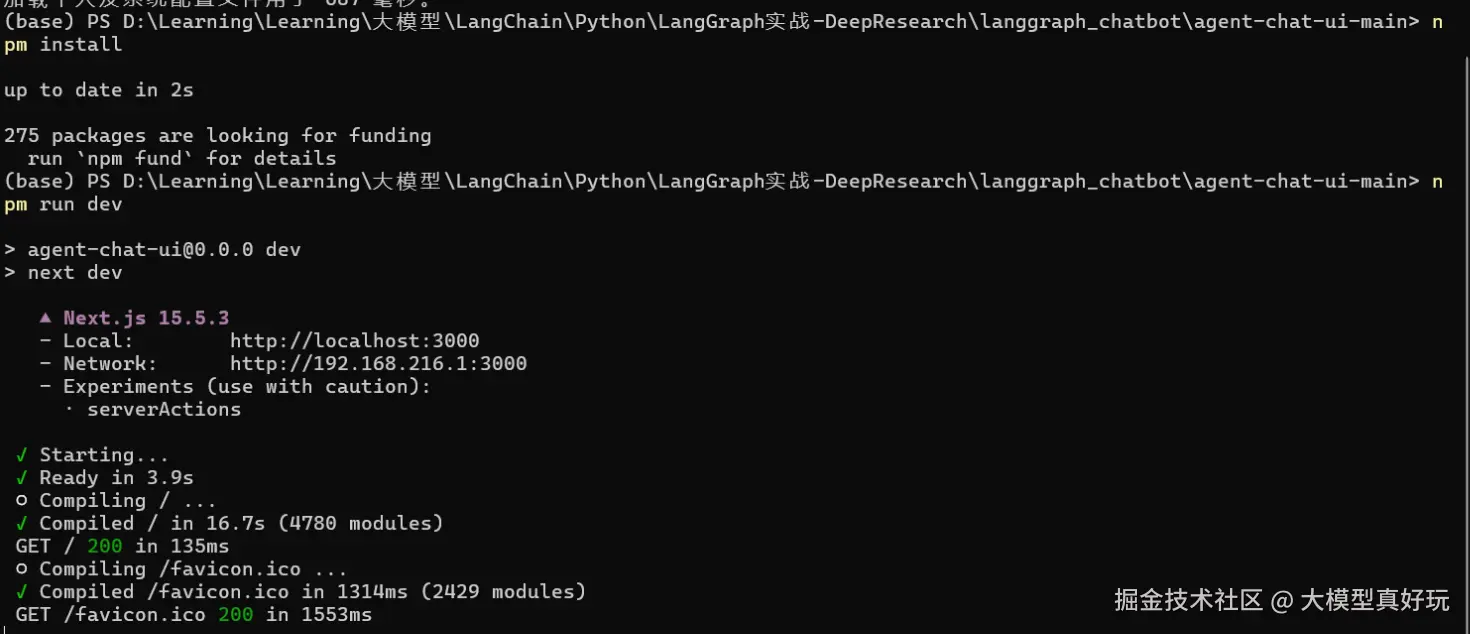
-
打开
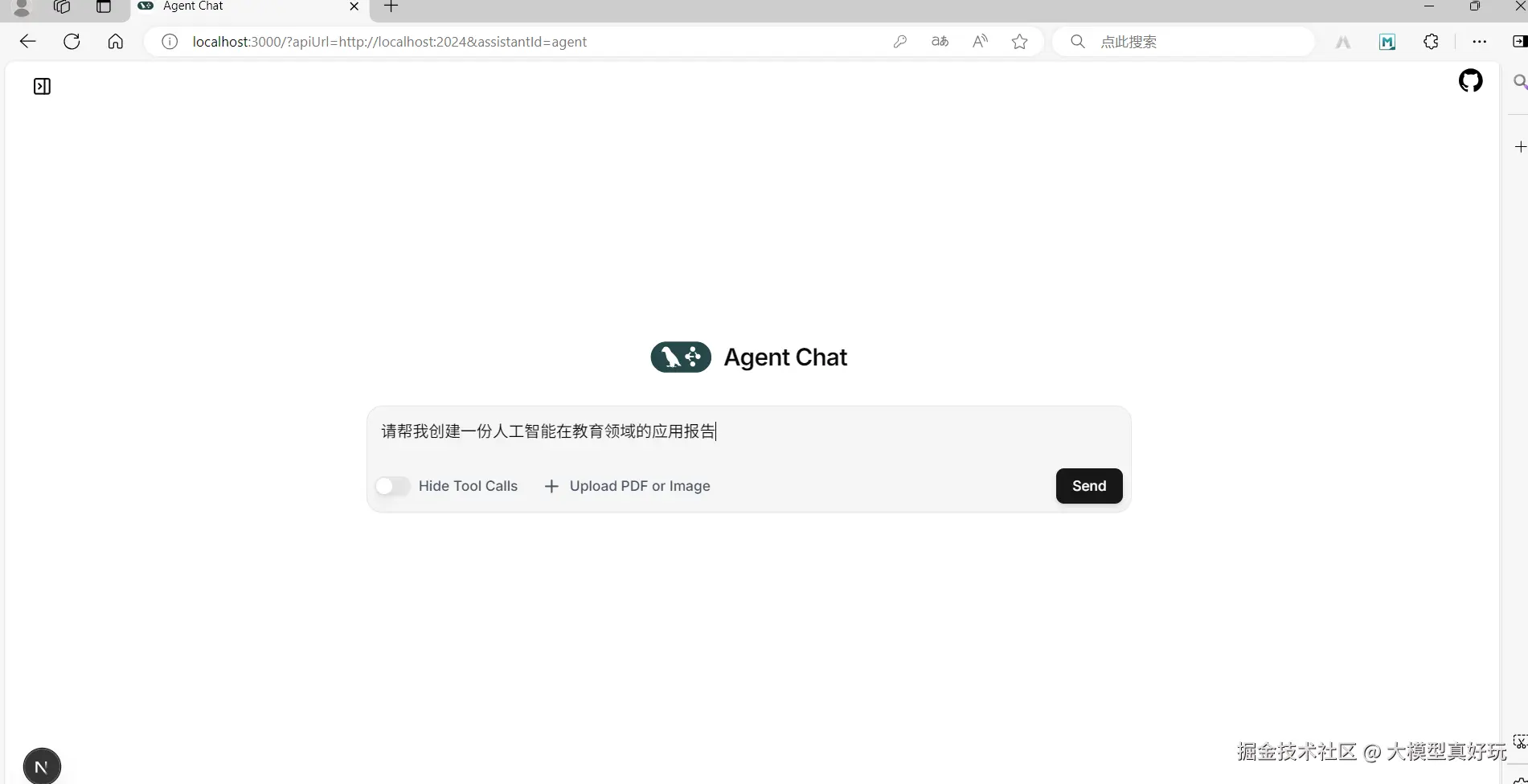
http://localhost:3000,在配置项中填入后端langgraph.json中定义的入口名称:chatbot,点击确认后会跳转到对话页面。在对话页面中输入测试问题:请帮我创建一份人工智能在教育领域的应用报告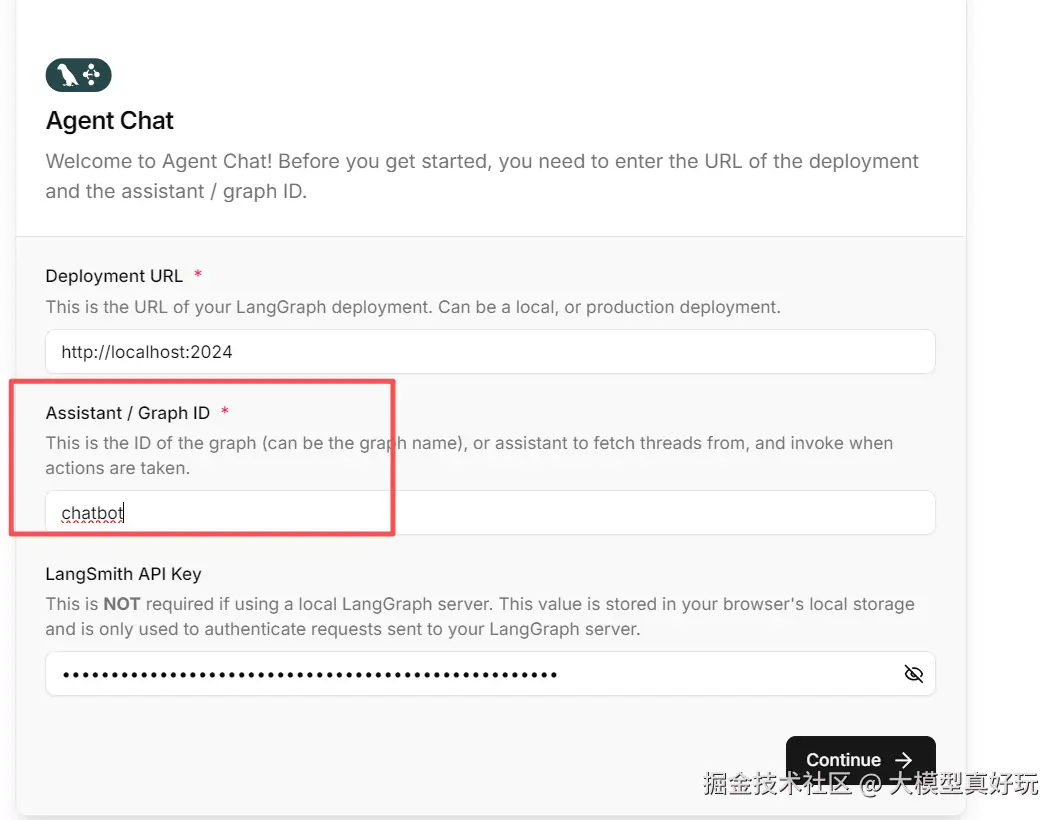
-
可以看到智能体成功调用了搜索工具,查询了多个网页,并最终生成完整的研究报告:


三、总结与展望
本文详细演示了如何利用LangGraph构建包含任务规划、网络搜索和报告生成三个智能体的DeepResearch应用,并完成了前后端一体化部署。通过图结构封装和多节点协同,实现了从问题输入到研究报告生成的全流程自动化。这里还是要说一句,当前实现的DeepResearch仅为基础版本,其实目前业界已有多种成熟的架构设计。下一期笔者将深入解析主流的DeepResearch开源架构,并分享如何高效阅读和理解复杂智能体的源码实现,帮助大家掌握更高级的多智能体系统设计模式。大家敬请期待。
《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏内容源自笔者在实际学习和工作中对 LangChain 与 LangGraph 的深度使用经验,旨在帮助大家系统性地、高效地掌握 AI Agent 的开发方法,在各大技术平台获得了不少关注与支持。目前基础部分已更新 20 讲,接下来将重点推出实战项目篇,并随时补充笔者在实际工作中总结的拓展知识点。如果大家感兴趣,欢迎关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。