文章目录
- 一、引言
- 二、选型:面向PB级数据
- [三、Apache IoTDB的架构优势和实践](#三、Apache IoTDB的架构优势和实践)
-
- 3.1、专为IoT设计的分层存储
- 3.2、卓越的写入和查询性能
- [3.3、Schema Tree管理海量元数据](#3.3、Schema Tree管理海量元数据)
- 3.4、国产开源力量
- 3.5、IoTDB的实际应用编程
- 四、选型落地和资源获取
- 五、总结
一、引言
随着工业物联网(IIoT)、智能制造以及能源数字化战略的深入推进,数以亿计的传感器、设备和产线终端正在以毫秒级频率持续产生数据。这些数据有典型的时序特征:写入频率非常的高、总量庞大(轻松达到PB级别),大部分原始数据点属于低价值密度。
面对这种数据特性,沿用关系数据库(RDB)或通用型NoSQL数据库来存储时序数据很快就暴露出致命的缺陷:因为缺乏针对时间序列的优化,索引结构迅速膨胀,存储空间浪费严重;高频写入操作容易造成I/O瓶颈;随着数据量的增长,查询性能急剧衰减,不能满足实时分析和监控的需求。
因此,对任何处理大规模物联网或工业数据的架构师来说,选择一款专业的时序数据库(TSDB)已成为必然。TSDB必须能兼顾高吞吐的写入能力 、极致的数据压缩率 以控制TCO(总拥有成本),以及在海量数据背景下依然保持低延迟的查询响应。寻找能够完美融入现有大数据生态,并具备国产化优势的专业级TSDB,正是本文要深入探讨的。
二、选型:面向PB级数据
处理PB级时序数据时,架构师必须跳出传统数据库的思维定式,关注三个核心技术维度,它们直接决定系统的可扩展性、成本效益和查询效率。
时序数据本质上是按时间顺序记录的一系列测量值。特征是"写多读少"、"数据点高度相关"。行式存储在写入时效率较高,但对于时序数据的查询来说,要读取大量不相关的数据点,导致I/O放大。
相比之下,列式存储结构能把同一时间序列(即同一测点)的数据值连续存储在一起。
- 同一列(同一测点)的数据值变化趋势相对平稳,可以用时间戳和数值的特殊性,采用高效的压缩算法。时序数据库能实现比普通数据库高出数倍甚至数十倍的压缩比,降低存储成本(TCO)。
- 查询特定测点时,系统只需读取相关的列数据块,避免不必要的磁盘寻道和数据加载,提高查询速度。
此外,**时间序列索引(TSIndex)**的设计非常重要。一个高效的TSDB必须具备优化的时间索引结构,能快速定位到特定时间范围的数据块,而不是依赖全表扫描。
面向PB级数据,采用存储与计算分离的架构是实现弹性扩展和高可用性的行业标准。
- 弹性扩展: 存储节点(负责数据持久化)和计算节点(负责查询执行和写入协调)可以独立扩展。当写入压力增大时,可以增加计算节点;当数据量增长时,可以增加存储节点,不用停机。
- 资源隔离: 保证高并发写入操作不会过度占用计算资源,影响正在进行的复杂查询分析任务,确保系统的稳定性。
工业物联网场景的数据采集端往往存在网络不稳定或设备故障,导致数据到达数据库时已经出现**乱序(Out-of-Order)**现象。一个优秀的TSDB必须能处理乱序数据,正确插入到时间轴上的正确位置,而不是简单的丢弃或拒绝写入,这是工业级应用对数据完整性的基本要求。
时序数据库不是孤立存在,必须能无缝融入企业现有的数据湖、数据仓库和实时处理平台。
- 数据管道集成: 良好的TSDB应提供跟主流消息队列和流处理引擎的连接器,支持实时数据摄入和预处理。
- 分析工具兼容: 能通过标准接口或API跟BI工具、机器学习平台对接,实现数据的深度分析和模型训练。
三、Apache IoTDB的架构优势和实践
专为物联网和工业大数据设计的解决方案------Apache IoTDB。作为 Apache 软件基金会(ASF)的顶级项目,IoTDB 独特的设计完美符合前面所说的架构需求,在国产化替代浪潮有着很大的竞争力。
3.1、专为IoT设计的分层存储
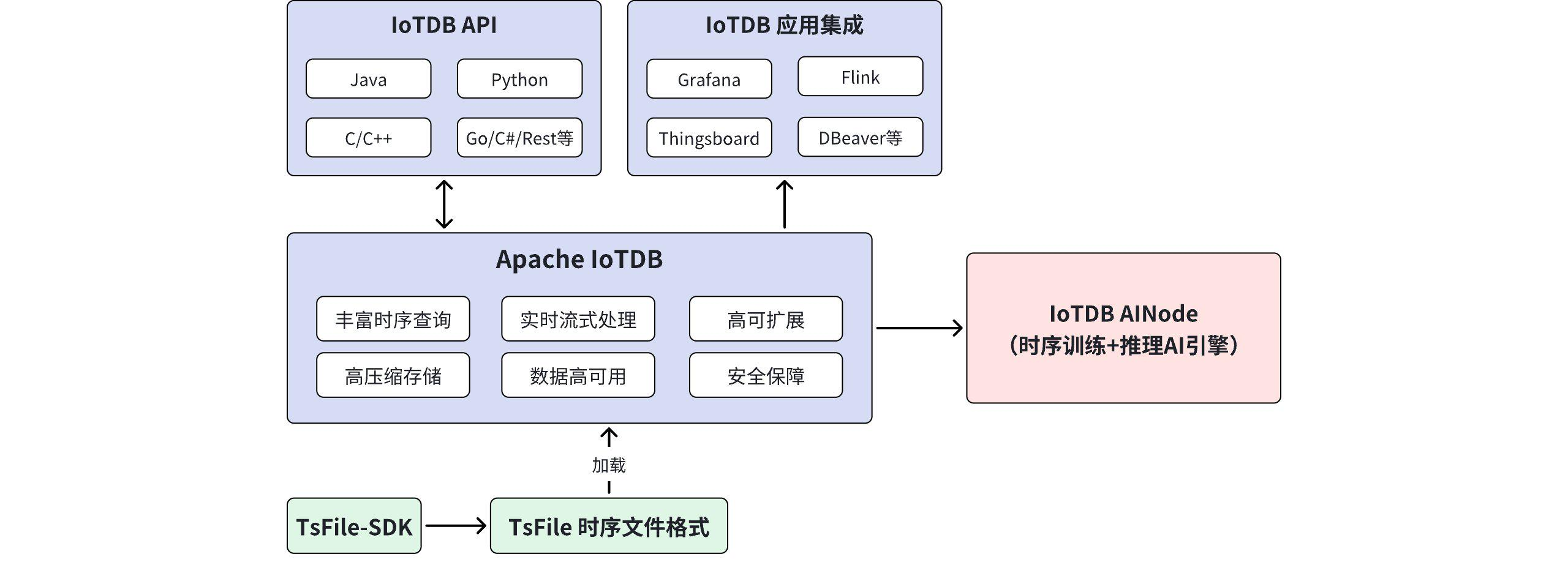
时序数据的生命周期特性:新数据访问频率高,旧数据主要是归档和历史查询。所以,IoTDB 采用**分层存储(Tiered Storage)**架构,可以控制大规模数据存储成本(TCO)。
- 冷热数据分离: 最新的热数据存储在高性能的SSD上保证查询速度,历史冷数据自动迁移到成本更低的HDD或对象存储上。
- IoTDB 用专有的 TsFile 文件格式。这种格式集成列式存储、高效压缩算法和元数据索引,数据在磁盘紧凑存储和高效读取。通过极致的压缩比,IoTDB 能大幅度减少存储空间。
IoTDB 分层存储架构示意图 存储层级 初始存储 策略1: 热转温 (例如: 7天未访问/Compaction完成) 策略2: 温转冷 (例如: 30天未访问/低频查询) 数据写入/采集 数据归档/删除 (Retention Policy)
温存储 (Warm Storage)
热存储 (Hot Storage)
冷存储 (Cold Storage)
3.2、卓越的写入和查询性能
IoTDB 的架构设计避免普通数据库在处理高并发时序数据时常见的瓶颈。
- 高吞吐写入: IoTDB 采用类 LSM Tree 的写入机制,把随机写入转化为顺序写入,提高写入吞吐量,轻松应对工业场景下每秒数百万点的数据洪流。
- 乱序数据处理: IoTDB 原生支持高效的乱序数据处理。能确保乱序到达的数据正确合并和存储,保证数据完整性。
- 针对时序数据的特性,IoTDB 提供丰富的聚合函数和高效的插值查询。这些功能直接在存储层进行优化,避免把大量原始数据拉到应用层进行计算的低效操作,降低查询延迟。
3.3、Schema Tree管理海量元数据
高基数场景管理数百万甚至数十亿的设备和测点是非常大的挑战。IoTDB 引入独特的树形数据模型(Schema Tree)。
- 结构化管理: 把设备、产线、工厂等层级关系映射到树形结构。这种结构不仅让元数据管理清晰,而且在查询时可以通过路径匹配快速定位到目标数据。
- 类SQL接口: IoTDB 提供高度兼容 SQL 的查询语言,让熟悉关系数据库的工程师迅速上手,降低学习和迁移成本。
IoTDB 树形数据模型 存储组 设备 时间序列 root s1: 温度 - INT32 s2: 湿度 - FLOAT s3: 震动频率 - DOUBLE status: 状态 - BOOLEAN root.ln.device_1: 机器编号1 root.ln.device_2: 机器编号2 root.sg_wh.d100: 货架编号100 root.ln: 生产线存储组 root.sg_wh: 仓库存储组
3.4、国产开源力量
作为国内主导的 Apache 顶级开源项目,IoTDB 有天然的国产化优势:
- 技术自主可控: 核心技术由国内团队主导研发和维护,保障技术的安全性和可靠性。
- 社区支持: 高度活跃的中文社区,技术交流和问题解决效率高。
- 企业级服务: 专业的企业级支持,可以获得针对性的性能调优、高可用部署、定制化开发等服务。
3.5、IoTDB的实际应用编程
C++:
cpp
#include "Session.h"
#include <iostream>
#include <string>
#include <vector>
#include <sstream>
int main(int argc, char **argv)
{
Session *session = new Session("127.0.0.1", 6667, "root", "root");
session->open();
std::vector<std::pair<std::string, TSDataType::TSDataType>> schemas;
schemas.push_back({"s0", TSDataType::INT64});
schemas.push_back({"s1", TSDataType::INT64});
schemas.push_back({"s2", TSDataType::INT64});
int64_t val = 0;
Tablet tablet("root.db.d1", schemas, /*maxRowNum=*/ 10);
tablet.rowSize++;
tablet.timestamps[0] = 0;
val=100; tablet.addValue(/*schemaId=*/ 0, /*rowIndex=*/ 0, /*valAddr=*/ &val);
val=200; tablet.addValue(/*schemaId=*/ 1, /*rowIndex=*/ 0, /*valAddr=*/ &val);
val=300; tablet.addValue(/*schemaId=*/ 2, /*rowIndex=*/ 0, /*valAddr=*/ &val);
session->insertTablet(tablet);
tablet.reset();
std::unique_ptr<SessionDataSet> res = session->executeQueryStatement("select ** from root.db");
while (res->hasNext()) {
std::cout << res->next()->toString() << std::endl;
}
res.reset();
session->close();
delete session;
return 0;
}JAVA:
java
package org.apache.iotdb;
import org.apache.iotdb.isession.SessionDataSet;
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
import java.util.ArrayList;
import java.util.List;
public class SessionExample {
private static Session session;
public static void main(String[] args)
throws IoTDBConnectionException, StatementExecutionException {
session =
new Session.Builder()
.host("172.0.0.1")
.port(6667)
.username("root")
.password("root")
.build();
session.open(false);
List<MeasurementSchema> schemaList = new ArrayList<>();
schemaList.add(new MeasurementSchema("s1", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("s2", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("s3", TSDataType.FLOAT));
Tablet tablet = new Tablet("root.db.d1", schemaList, 10);
tablet.addTimestamp(0, 1);
tablet.addValue("s1", 0, 1.23f);
tablet.addValue("s2", 0, 1.23f);
tablet.addValue("s3", 0, 1.23f);
tablet.rowSize++;
session.insertTablet(tablet);
tablet.reset();
try (SessionDataSet dataSet = session.executeQueryStatement("select ** from root.db")) {
while (dataSet.hasNext()) {
System.out.println(dataSet.next());
}
}
session.close();
}
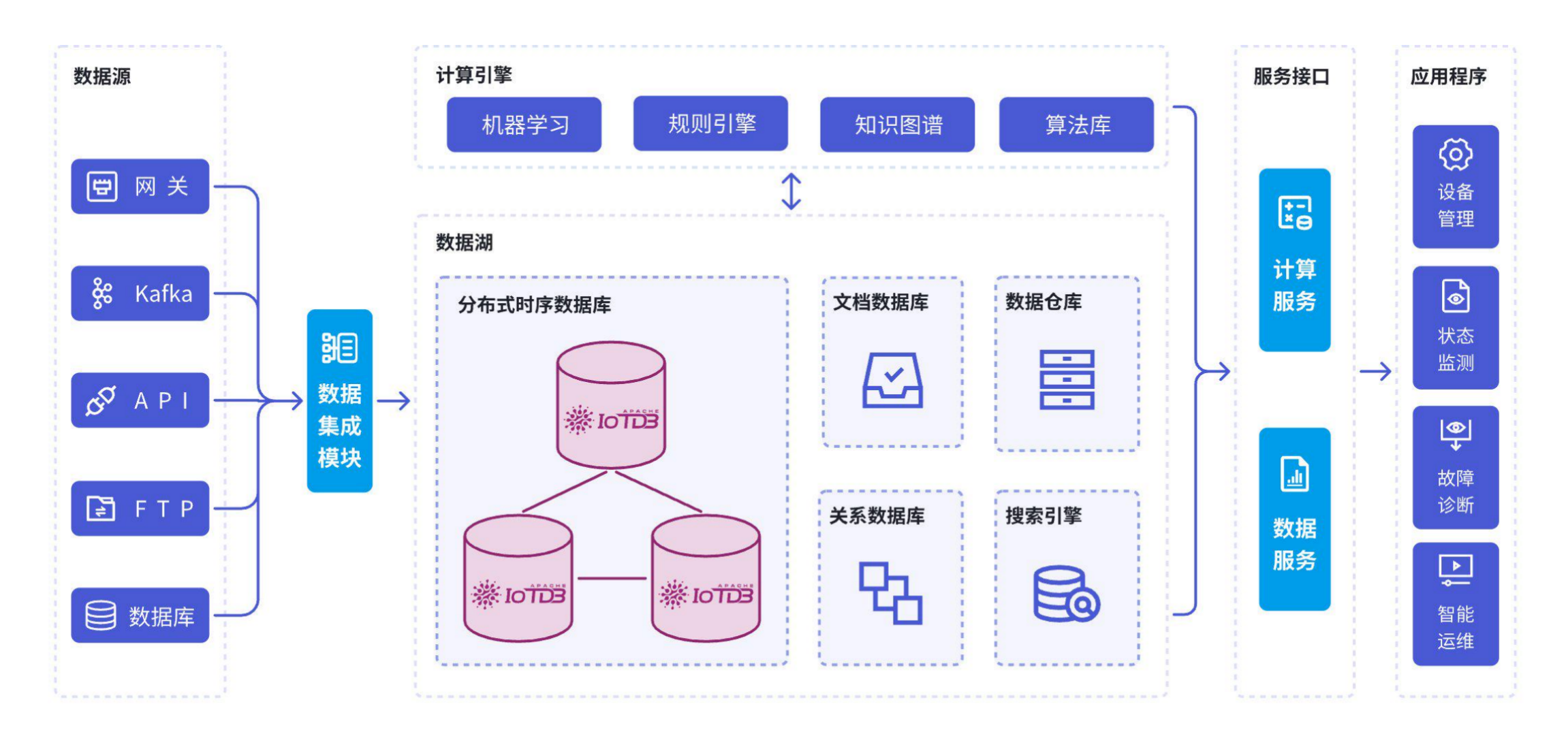
}作为物联网原生的高性能时序数据库,IoTDB 可以从边缘设备到云端的全链路数据同步和存储分析,有高并发处理能力,能满足大规模设备接入的需求。
四、选型落地和资源获取
生产环境对高可用性(HA)是不可妥协的。IoTDB 支持基于 Raft 协议的集群部署,保证数据写入和查询服务的持续在线。另外,企业级应用有完善的权限管理和监控运维体系。
- 高可用: 多副本机制和自动故障转移确保系统在节点失效仍旧能提供服务。
- 细粒度的权限控制,满足不同部门对数据的访问隔离需求。
跟国外主流 TSDB 方案进行功能对比,虽然很多海外产品在特定领域表现优秀,但在面对国内超大规模物联网场景和本土化支持时存在"水土不服"。比如,处理非常高基数(数亿测点)的元数据管理效率、深度定制化需求响应速度,跟国内主流云平台和大数据生态的深度集成方面,国产开源项目有更好的灵活度和响应速度。
不管是基于开源社区进行技术探索,还是企业级的稳定服务和技术保障,Apache IoTDB 都能提供完善的路径。
- 开源版本(获取最新技术,自行部署): https://iotdb.apache.org/zh/Download/
- 企业级服务和支持,企业版官网: https://timecho.com
五、总结
PB级数据洪流对数据库的挑战是结构性的。时序数据库的选型不是简单的性能测试,而是对存储模型、架构弹性、生态融合和长期技术支持的全面考虑。Apache IoTDB 凭借专为 IoT 设计的列式存储、分层架构、高效的乱序处理能力、活跃的国产开源社区支持,是当前面向工业物联网和大数据场景的最佳选择之一。不仅在技术上满足高性能、低成本的需求,更在战略上保障企业数据基础设施的自主可控。
