传统语言模型有个天生缺陷------只能从左往右读,就像你现在读这段文字一样,一个词一个词往下看,完全不知道后面会出现什么。人类可不是这么学语言的。看到"被告被判**_**",大脑会根据上下文直接联想到"有罪"或者"无罪",这就是双向理解在起作用。
Google搞出来的BERT(Bidirectional Encoder Representations from Transformers)终于让机器也有了这种能力。BERT的核心不是简单地双向阅读,而是用了一种叫掩码语言建模(Masked Language Modeling,MLM)的巧妙方法。
通过随机遮住15%的词,BERT反而比那些完整阅读文本的模型学得更好。这有点像做填空题学英语,只不过空是随机出现的,而且BERT要处理的是几十亿个句子。
这篇文章会把MLM的数学机制拆开来逐一讲解。从一个被遮住的句子开始,经过注意力计算、概率分布、梯度下降,看看这些数学操作到底怎么让BERT达到接近人类的语言理解能力。搞懂这些数学原理,对于想要调优BERT或者设计类似模型的人来说很关键。
看完之后你会明白,BERT做的不只是遮词这么简单------注意力机制里的√d_k缩放、80-10-10的掩码策略,这些看似细节的数学设计对性能影响巨大。
核心机制:掩码预测
原理很简单:随机选一些词遮起来,让模型去猜。比如这句话:
"猫坐在MASK上。"
人看到"猫坐在......上",马上就能想到可能是"垫子"、"地板"之类的词。这种推理来自对语法结构和词语关系的理解。BERT学的也是这套推理逻辑,只不过它靠的是数学优化而不是人的直觉。
训练分三步:
- 掩码:随机挑出15%的词,80%换成MASK标记,10%换成随机词,剩下10%保持原样
- 预测:把处理后的句子扔进BERT的transformer层,生成预测结果
- 优化:算出预测和真实答案的差距,用反向传播更新参数
这个简单粗暴的方法逼着BERT学会深层的语言规律。关键在于MLM用了双向上下文------同时看左边和右边的词,不像传统的"下一词预测"模型只能看左边。所以得到的结果就是预测准确率高了很多。
从信息论来看,MLM制造了一个理想的学习信号。遮掉一个词,就产生了明确的预测任务和已知的不确定性。模型必须从上下文里榨取尽可能多的信息来降低这个不确定性。
一个词w在上下文c中的信息量,用惊讶度(surprisal)衡量:
I(w|c) = -log P(w|c)容易预测的词惊讶度低(信息量少),难预测的词惊讶度高。通过训练掩码标记,BERT学会建模完整的概率分布P(w|c),既能掌握常见模式也不会忽略罕见结构。
80-10-10这个掩码策略也是有讲究的。如果只用MASK替换,模型在训练时见到的是特殊标记,但微调和推理时永远看不到这个标记,就会产生gap。随机替换词或者保持原词,强迫BERT在有干扰的情况下也能学出好的表示。
Transformer架构
BERT通过自注意力机制来理解上下文,这个机制用数学方式编码了序列中所有词之间的关系。对于n个token的输入序列,自注意力给每个token生成三个向量:
- Query(Q):这个token想找什么信息
- Key(K):这个token能提供什么信息
- Value(V):这个token提供的具体内容
这些向量通过学习的线性变换得到:
Q = XW_Q
K = XW_K
V = XW_VX是输入嵌入矩阵,W_Q、W_K、W_V是可学习的权重矩阵。
然后注意力机制计算value的加权平均,权重表示每个token对其他token的关注程度:
Attention(Q, K, V) = softmax(QK^T / √d_k)V拆开来看:
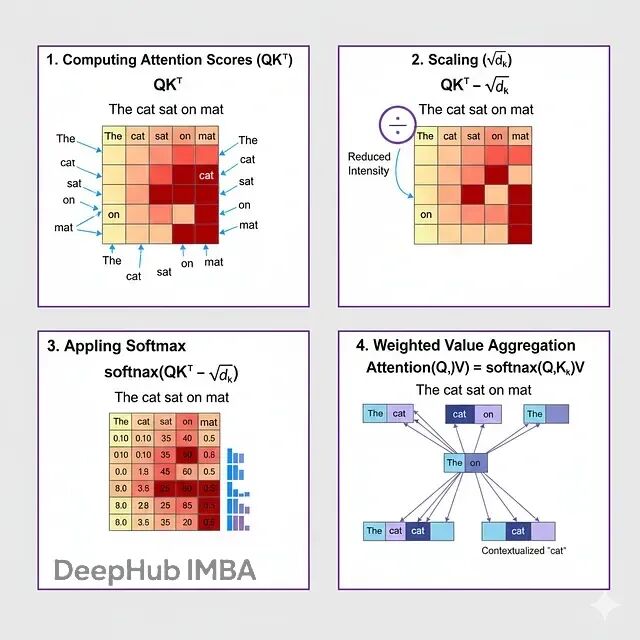
1、 算注意力分数(QK^T)
点积QK^T生成一个n×n的矩阵,元素(i,j)代表token i对token j的关注度。点积越大说明query和key向量在语义或句法上越相似。
2、缩放(√d_k)
除以√d_k(key维度的平方根)防止点积太大。不缩放的话,当d_k很大时,点积方差会很高,把softmax推到梯度极小的区域,训练就不稳定了。
数学上,如果query和key是均值0方差1的随机变量,它们的点积方差就是d_k。除以√d_k把方差归一化回1。
3、Softmax
softmax把分数转成概率分布:
softmax(z_i) = exp(z_i) / Σ_j exp(z_j)保证每个token的注意力权重加起来是1,形成有效的概率分布。指数函数放大了分数之间的差异,让模型能聚焦在相关token上,同时弱化无关的。
4、加权聚合
最后把注意力权重乘以value矩阵V,得到加权和。每个token的输出表示都融合了其他所有token的信息,按相关性加权。
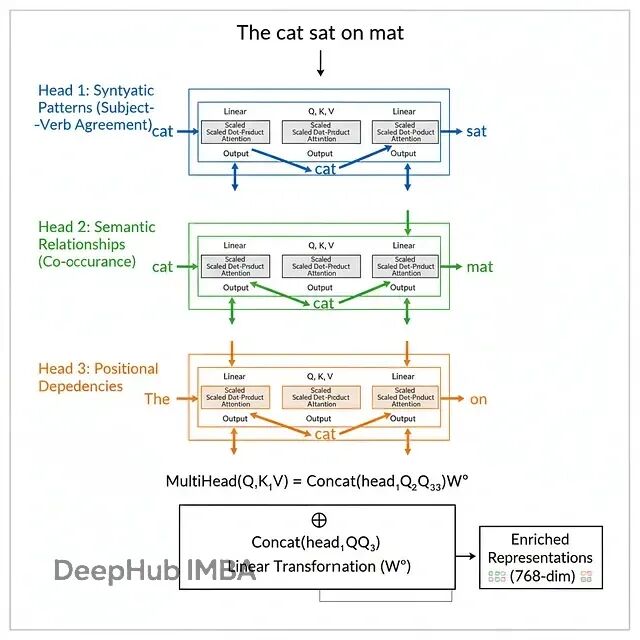
BERT不是算一个注意力函数,而是并行算h个(BERT-base是12个头,BERT-large是16个)。每个头学习关注输入的不同方面:
head_i = Attention(QW_Q^i, KW_K^i, VW_V^i)输出拼接后做线性变换:
MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W_O为什么要多头?每个头可以关注不同类型的关系:
- 有的头专注句法关系(主谓一致)
- 有的头专注语义关系(同义反义)
- 还有的头关注位置模式
这种并行机制让BERT能同时建模多种语言结构。
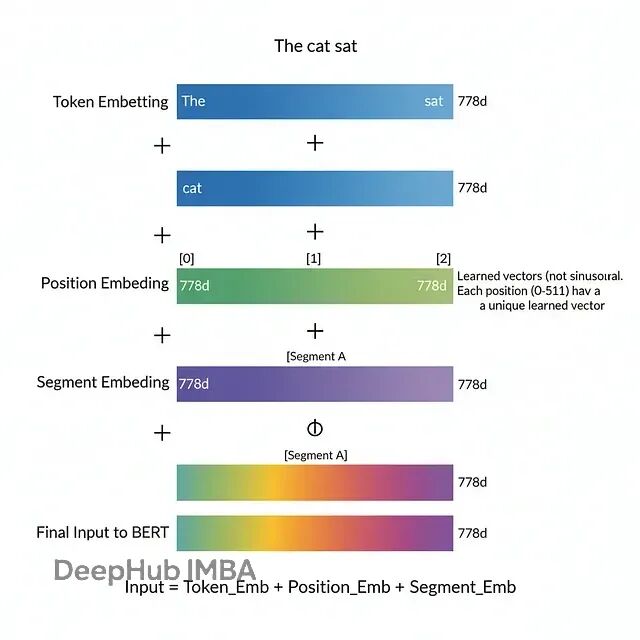
跟按顺序处理的RNN不同,transformer一次性处理所有token。为了让模型知道词的顺序,BERT在输入嵌入里加入了位置编码:
Input = Token_Embedding + Position_Embedding + Segment_EmbeddingBERT用的是可学习的位置嵌入,不是原始Transformer论文里的正弦编码。每个位置(BERT里是0到511)都有一个d维向量可以学习,直接加到token嵌入上。
结果就是一个向量同时包含了位置和token的身份信息------既知道这个词是什么,也知道它在句子里的位置。
MLM预测头:从表示到概率
过完L层transformer(BERT-base是12层,BERT-large是24层)之后,每个token都有一个上下文化的表示h_i ∈ R^d。对于被掩码的token,需要把这些表示转成词汇表上的概率分布。
预测头包含三步变换:
带激活的全连接层
h_mlm = GELU(h_i W_1 + b_1)GELU(Gaussian Error Linear Unit)激活函数引入非线性:
GELU(x) = x · Φ(x)Φ(x)是标准正态分布的累积分布函数。GELU比ReLU的梯度更平滑,训练更稳。
层归一化
h_norm = LayerNorm(h_mlm)层归一化通过归一化激活值来稳定训练:
LayerNorm(x) = γ(x - μ)/σ + βμ和σ是跨特征计算的均值和标准差,γ和β是可学习参数。
输出投影
logits = h_norm W_vocab + b_vocab把归一化后的表示投影到词汇表大小V(BERT一般是30,000),给每个可能的token生成一个logit。
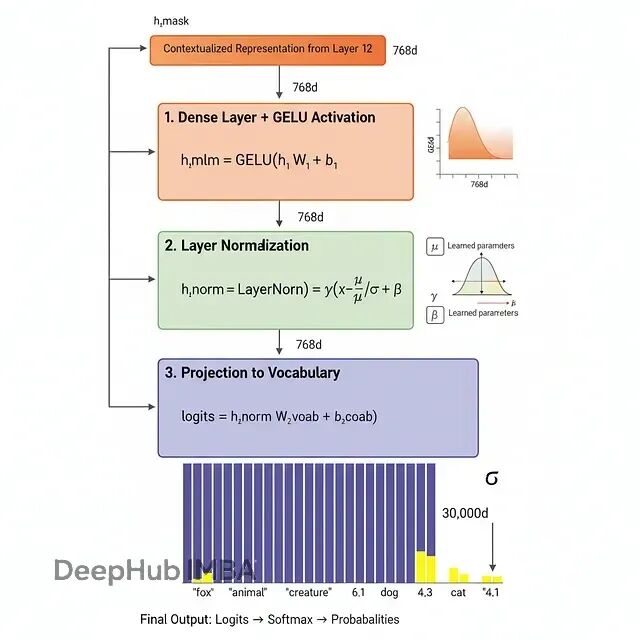
用softmax把logit转成概率:
P(w_i | context) = exp(logit_i) / Σ_{j=1}^V exp(logit_j)softmax有几个关键特性:
- 输出范围:所有概率都在(0, 1)之间
- 归一化:概率总和是1
- 单调性:logit越高概率越大
- 敏感性:指数放大了logit之间的差异
分母(配分函数)保证归一化,但计算开销很大------每次预测要对30,000多项求和。训练时这个成本避不开,但推理时可以用分层softmax之类的技术加速。
损失函数
对每个掩码token,用交叉熵衡量BERT预测分布和真实分布的差距(真实分布把全部概率放在正确token上):
L_token = -log P(w_true | context)这个损失函数特性很好:
- 范围:L_token ∈ [0, ∞)
- 最小值:当P(w_true | context) = 1时达到
- 梯度:直接关联到预测误差
负对数概率处理了预测接近1时softmax指数增长的问题。模型给正确token分配高概率时,log P接近0,损失就低。反之概率低时,-log P变大,给学习提供强信号。
对于B个序列的batch,每个序列有M个掩码token,总MLM损失是:
L_MLM = (1/BM) Σ_{b=1}^B Σ_{m=1}^M -log P(w_m^b | context_b)这个平均操作保证损失大小不依赖batch大小或掩码率,让不同配置下的训练都稳定。
反向传播时计算损失相对于所有参数θ的梯度:
∇_θ L_MLM = (1/BM) Σ_{b=1}^B Σ_{m=1}^M ∇_θ (-log P(w_m^b | context_b))相对于正确token的logit的梯度特别简单:
∂L/∂logit_true = P_predicted - 1错误token的:
∂L/∂logit_wrong = P_predicted梯度就是预测误差------预测概率和真实概率的差,这个干净的梯度结构让训练既稳定又高效。
优化
BERT用Adam优化器,它维护梯度及其平方的滑动平均:
m_t = β_1 m_{t-1} + (1-β_1)g_t
v_t = β_2 v_{t-1} + (1-β_2)g_t^2g_t是第t步的梯度,β1=0.9,β2=0.999是衰减率。
这些平均值需要做偏差修正:
m̂_t = m_t / (1 - β_1^t)
v̂_t = v_t / (1 - β_2^t)参数更新用自适应学习率:
θ_t = θ_{t-1} - α · m̂_t / (√v̂_t + ε)α是基础学习率,ε=10^-8防止除零。
Adam的自适应学习率能处理不同参数梯度的不同尺度,这对训练BERT这种有110M(base)或340M(large)参数的深度网络很关键。
BERT用两阶段学习率调度:
- 线性预热:前10,000步把学习率从0升到α_max
- 线性衰减:剩余步骤把学习率从α_max降到0
数学表达:
α(t) = α_max · min(t/t_warmup, (t_total - t)/(t_total - t_warmup))预热避免训练初期梯度不稳时做大幅参数更新。末期衰减让模型细粒度收敛到最优解。
预测掩码词
走一遍完整流程看看这些数学组件怎么配合工作。

输入句子
原始:"The quick brown fox jumps over the lazy dog"掩码:"The quick brown MASK jumps over the lazy dog"
步骤1:分词和嵌入
BERT的tokenizer把句子转成token ID:
[101, 1996, 4248, 2829, 103, 14523, 2058, 1996, 13971, 3899, 102]101是CLS,103是MASK,102是SEP。
每个token ID转成768维嵌入(BERT-base)。加上位置嵌入和段嵌入:
X = Token_Emb + Pos_Emb + Seg_Emb位置4的MASK token包含:
- Token嵌入:token 103的学习向量
- 位置嵌入:位置4的学习向量
- 段嵌入:段A(第一句)的向量
步骤2:自注意力计算
第一层注意力里,每个token和所有其他token计算注意力。对MASK token:
Q_mask = X_mask W_Q
K_all = X_all W_KMASK和各个上下文token的注意力分数:
scores = Q_mask · K_all^T / √64(BERT-base有12个头,d_k = 64,每个头维度是768/12=64)
softmax之后,假设得到注意力权重:
- "brown"(左边):0.35
- "jumps"(右边):0.40
- 其他token:0.25
这些权重乘以value向量:
output_mask = 0.35·V_brown + 0.40·V_jumps + 0.25·V_others这个输出进入下一层,"brown"和"jumps"的信息被整合进MASK表示。
步骤3:层层堆叠
这个过程在12层transformer里重复。每层都细化表示,整合越来越抽象的上下文信息。到最后一层,MASK表示h_mask包含了丰富的局部上下文(相邻词)和全局上下文(句子结构)信息。
步骤4:预测
MLM头转换最终隐藏状态:
h_mlm = GELU(h_mask W_1 + b_1)
h_norm = LayerNorm(h_mlm)
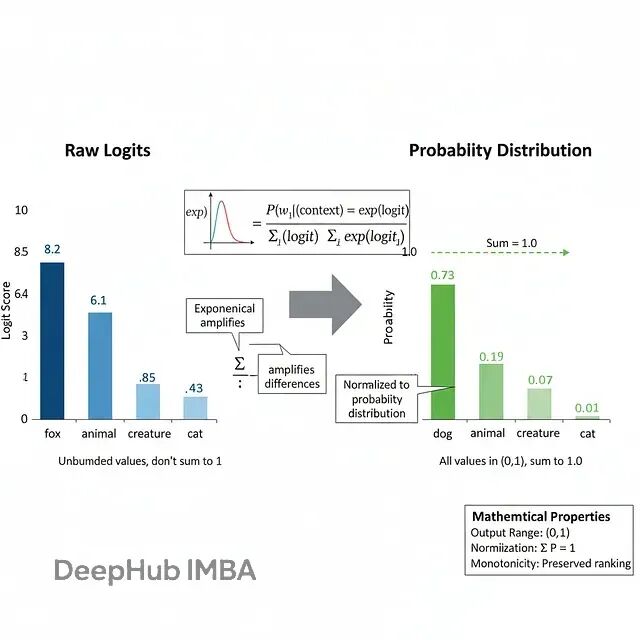
logits = h_norm W_vocab + b_vocab假设前5个logit是:
- "fox":8.2
- "animal":6.1
- "creature":5.8
- "dog":4.3
- "cat":4.1
softmax之后(简化显示):
P("fox" | context) = exp(8.2) / Z ≈ 0.73
P("animal" | context) = exp(6.1) / Z ≈ 0.15
P("creature" | context) = exp(5.8) / Z ≈ 0.11
...Z = Σ exp(logit_i)是配分函数。
步骤5:计算损失
正确token是"fox",所以:
L = -log P("fox" | context) = -log(0.73) ≈ 0.31损失梯度反向传播更新所有参数,让模型在将来类似上下文中提高P("fox" | context)。
MLM为什么有效
传统从左到右的语言模型只能基于前面的token:
P(w_i | w_1, ..., w_{i-1})MLM同时用两个方向:
P(w_i | w_1, ..., w_{i-1}, w_{i+1}, ..., w_n)双向上下文让预测准确率大幅提升。看这个例子:
"河的MASK被淹没了。"
单向模型看不到"淹没","bank"(银行/河岸)就很模糊。双向上下文里BERT看到"淹没"就能正确预测是"河岸"。
MLM逼着BERT学习能泛化语义和句法属性的密集向量表示。语义相似的token应该有相似的表示,这样才能在相似上下文里做出相似预测。这个预测目标创造了一个语义空间:
- 同义词聚在一起
- 不同句法类别(名词、动词)在不同区域
- 关系(king-queen、man-woman)表现为一致的向量偏移
MLM预训练产生的通用表示可以用在下游任务上。预训练过程中模型学到:
- 句法:语法结构和词语关系
- 语义:词义和上下文依赖
- 世界知识:训练数据里包含的事实和关系
微调特定任务时,模型能利用这些学到的表示,需要的任务数据比从头训练少很多。
总结
BERT的掩码语言建模在数学上是一套精巧的语言表示学习机制。自注意力通过查询-键空间的相似度计算,用值向量的加权平均学习上下文关系。多头注意力并行学习不同的语言表示。MLM目标逼着模型基于双向上下文预测掩码token,通过交叉熵损失和梯度下降优化不断改进。
理解这些数学原理不只是学术练习------它让实践者能在模型架构、训练流程、微调策略上做出明智决策。不管是针对特定领域调整BERT,开发新的预训练目标,还是debug训练不稳定,扎实的数学基础都很有价值。
自然语言理解不断突破边界,BERT体现的原则------基于注意力的上下文聚合、自监督学习、迁移学习------仍然是核心。未来的架构可能规模更大训练更快,但会建立在BERT奠定的数学基础上。
参考文献
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
- Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv preprint arXiv:1909.11942.
- Clark, K., Luong, M. T., Le, Q. V., & Manning, C. D. (2020). ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. arXiv preprint arXiv:2003.10555.
https://avoid.overfit.cn/post/dc093dcb26fe4e00b7d43c4715c91546
作者:Harish K