在进行MySQL相关的面试时,尤其是在如猿辅导这样注重技术底层实现的公司,面试官往往会问一些关于数据库优化、事务管理、锁机制等方面的问题。以下是一些常见的MySQL面试问题及其详细解答,帮助你更好地准备面试。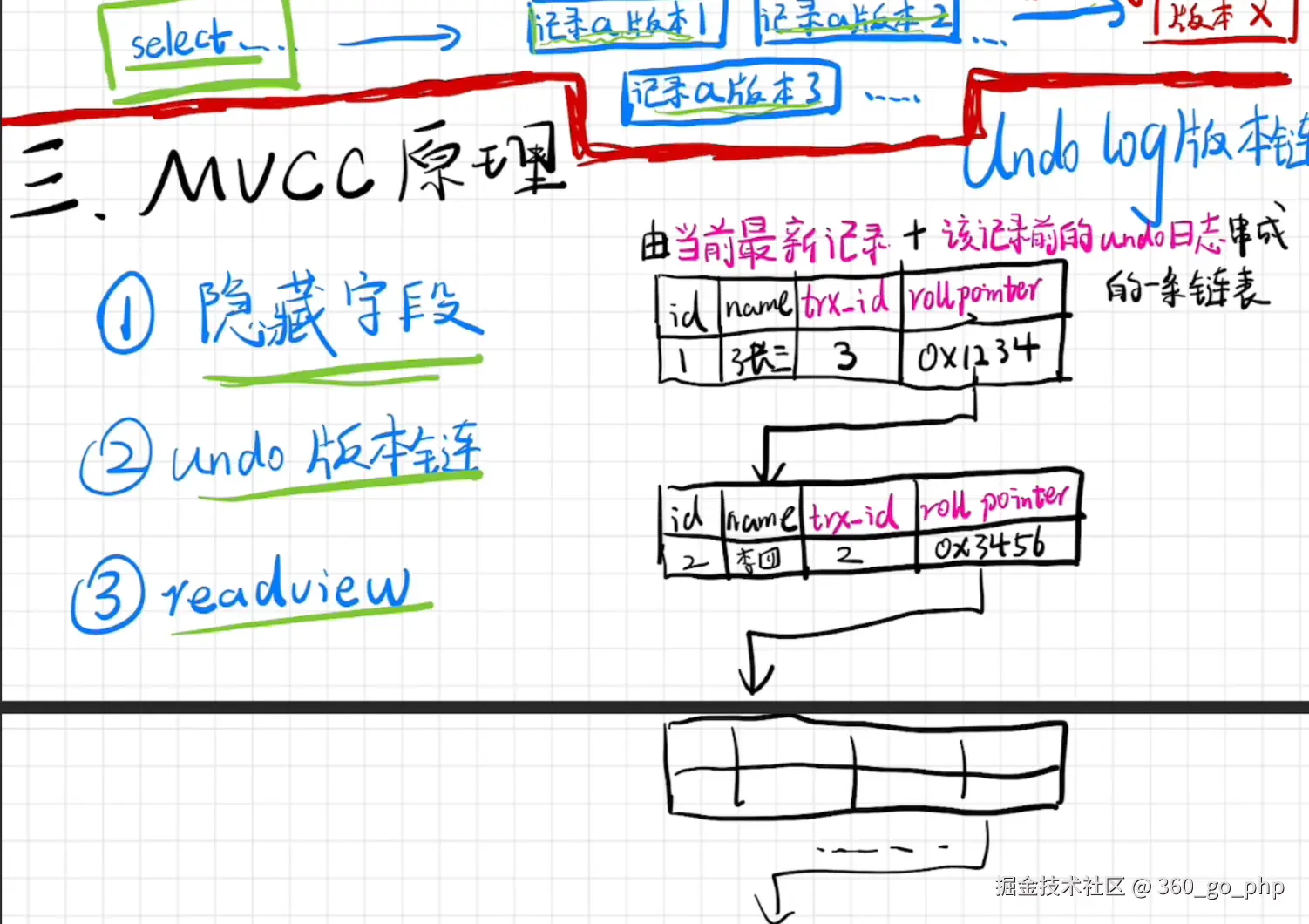 编辑
编辑
1. MySQL建立索引的原则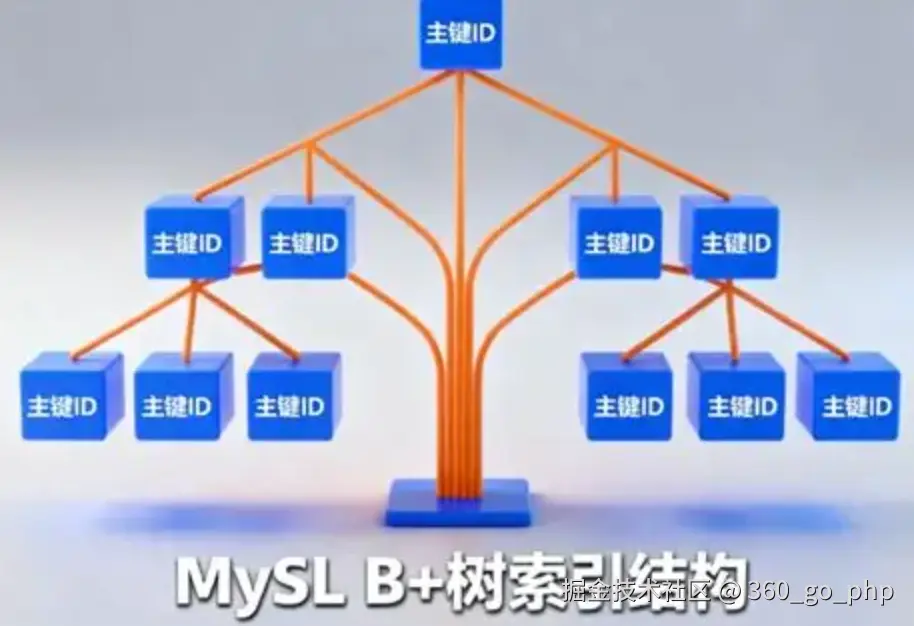 编辑
编辑
在MySQL中,索引是提升查询性能的重要工具。然而,索引虽然能加速查询,但也会占用额外的空间,并且会影响写操作的性能。因此,建立索引时需要遵循一些原则:
- 选择性高的列 :选择性高的列,指的是该列的唯一值多,数据分布较为均匀。对于这些列建立索引,能有效提高查询性能。
- 频繁查询的列 :对于频繁用于
WHERE、ORDER BY、JOIN等条件的列,应该考虑建立索引。 - 范围查询避免使用索引 :范围查询(如
BETWEEN、>、<等)可能会导致索引的效率降低,尤其是在大数据量的情况下。如果查询是范围条件,尽量避免在范围查询列上使用索引。 - 复合索引的选择 :在有多个查询条件的情况下,复合索引(多个列的索引)比单列索引更有效。复合索引的顺序应根据查询条件的顺序来排列。
- 避免过多索引:虽然索引能够提高查询效率,但过多的索引会增加数据库的存储空间,且会影响INSERT、UPDATE、DELETE等操作的性能,因此需要合理规划索引。
2. 聚簇索引和非聚簇索引区别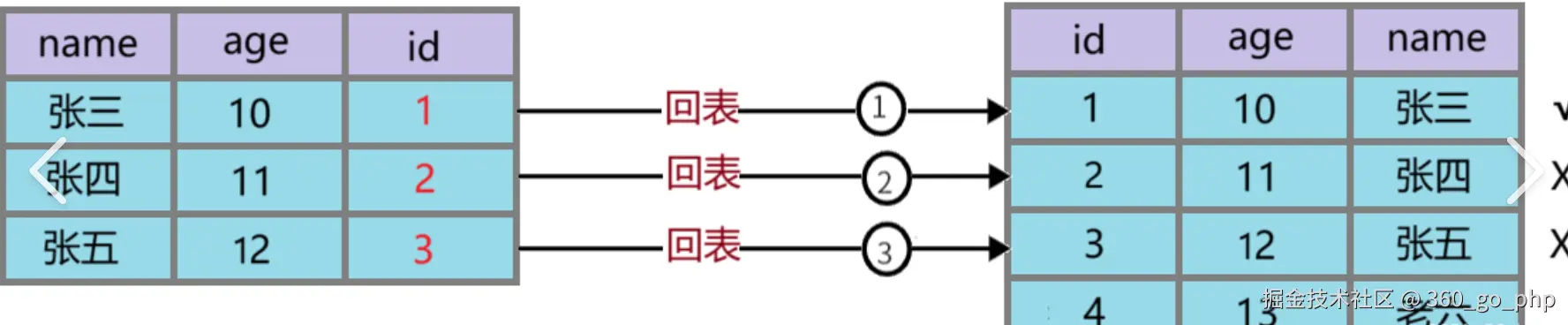 编辑
编辑
在MySQL中,索引有两种主要的类型:聚簇索引 (Clustered Index)和非聚簇索引(Non-clustered Index)。它们之间有以下几个区别:
-
数据存储方式 :
-
聚簇索引 :数据表的实际数据存储与索引存储在同一结构中。表的行按照索引的顺序存储,叶节点存储的是数据行本身,因此聚簇索引的顺序就是表数据的顺序。
-
非聚簇索引:索引结构独立于数据表的存储。非聚簇索引的叶节点存储的是数据行的指针(即数据行的地址或主键),而不是数据行本身。
-
-
索引类型 :
-
聚簇索引 :每个表只能有一个聚簇索引,通常是主键索引。主键索引是聚簇索引的一种特殊形式。
-
非聚簇索引:可以有多个非聚簇索引,通常是针对查询中经常出现的条件列创建的索引。
-
-
性能差异 :
-
聚簇索引 :因为数据存储和索引存储在同一结构中,查询时可以直接获取数据,因此性能较高。
-
非聚簇索引:查询时需要通过索引查找数据的指针,然后再去数据表中获取数据,性能相对较低。
-
3. B+树结构,为什么不用B树或二叉树
MySQL索引通常使用B+树结构,B+树是对B树的优化,它相比于B树有以下优点:
-
叶节点存储数据 :B+树的所有数据都存储在叶节点,而非B树中数据存在各级节点中。这样可以大大减少查找的时间,因为只需要查找到叶节点即可。
-
顺序遍历 :B+树的叶节点之间通过指针连接,支持顺序遍历。对于范围查询(如
BETWEEN、>等),B+树比B树更加高效。 -
更高的扇出性:B+树的内节点不存储数据,只存储索引值,通常可以包含更多的子节点,因此B+树的扇出性更高,树的高度更小,查询效率更高。
-
相比于二叉树:二叉树的查找效率为O(logN),但是其结构不如B树、B+树平衡,且由于其左右子树只能有两个分支,扇出性较差,因此不适用于大量数据的存储和检索。
4. 事务四大特性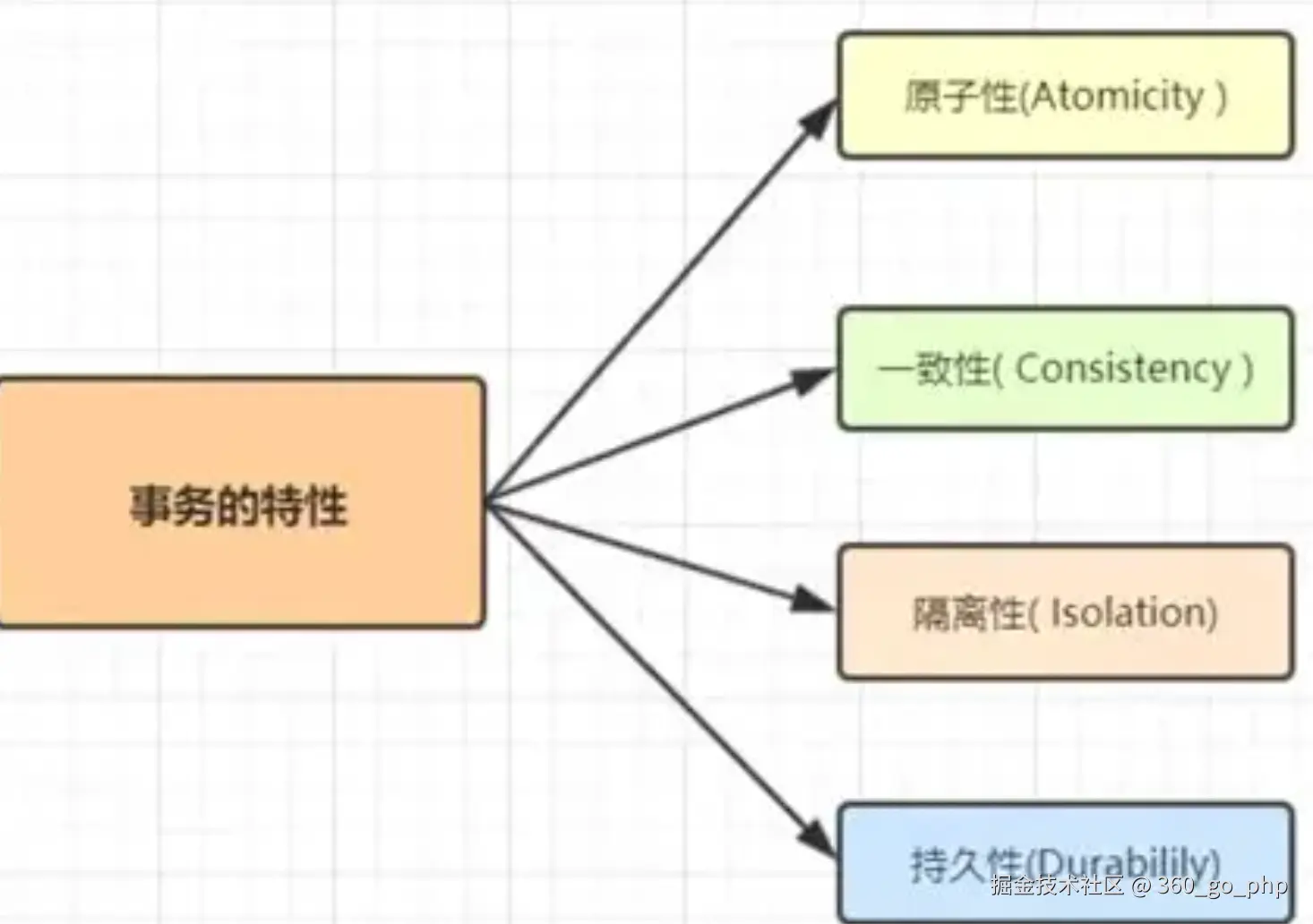 编辑
编辑
事务(Transaction)是数据库管理系统中的一个重要概念,保证了操作的原子性、一致性、隔离性和持久性,简称ACID特性:
-
原子性(Atomicity) :事务中的所有操作要么全部完成,要么全部不做。如果事务中的某个操作失败,整个事务会回滚,保证数据的一致性。
-
一致性(Consistency):事务执行前后,数据库的状态是一致的。即事务的执行不会破坏数据库的完整性约束。
-
隔离性(Isolation):事务的执行不应受到其他事务的干扰。不同事务之间的操作是相互独立的。MySQL通过事务隔离级别来控制并发事务的隔离性。
-
持久性(Durability):一旦事务提交,对数据库的修改就是永久性的,不会丢失,即使发生系统崩溃,提交的事务也能够保证被保存。
5. 事务隔离级别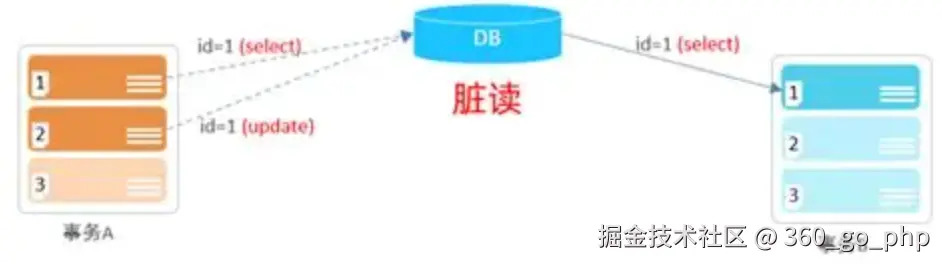 编辑
编辑
事务的隔离级别决定了一个事务可以看到其他事务未提交的修改。MySQL提供了以下四种事务隔离级别:
-
读未提交(READ UNCOMMITTED) :最低的隔离级别,事务可以读取到其他事务未提交的修改,可能会导致脏读、不可重复读、幻读等问题。
-
读已提交(READ COMMITTED):事务只能读取到其他事务已经提交的数据,避免了脏读,但仍然可能会发生不可重复读和幻读。
-
可重复读(REPEATABLE READ):事务在执行过程中,读取的数据不会被其他事务修改,避免了脏读和不可重复读,但仍然可能发生幻读。
-
串行化(SERIALIZABLE):最高的隔离级别,事务完全串行化执行,避免了所有的并发问题,包括脏读、不可重复读和幻读,但性能较差。
6. 用MySQL实现一个分布式锁
实现分布式锁的常见方法是利用MySQL的SELECT ... FOR UPDATE语句。通过锁住数据库中的一行数据,来保证同一时刻只有一个客户端能够获取到锁。
sql
-- 1. 创建一个锁表
CREATE TABLE locks (
lock_name VARCHAR(255) PRIMARY KEY,
locked INT
);
-- 2. 获取锁
START TRANSACTION;
SELECT * FROM locks WHERE lock_name = 'my_lock' FOR UPDATE;
-- 如果查询结果为空,可以插入一条记录来表示锁定
INSERT INTO locks (lock_name, locked) VALUES ('my_lock', 1) ON DUPLICATE KEY UPDATE locked = 1;
COMMIT;
-- 3. 释放锁
START TRANSACTION;
UPDATE locks SET locked = 0 WHERE lock_name = 'my_lock';
COMMIT; 这个方法使用FOR UPDATE语句锁定了locks表中的一行记录,从而实现分布式锁。
7. MVCC具体原理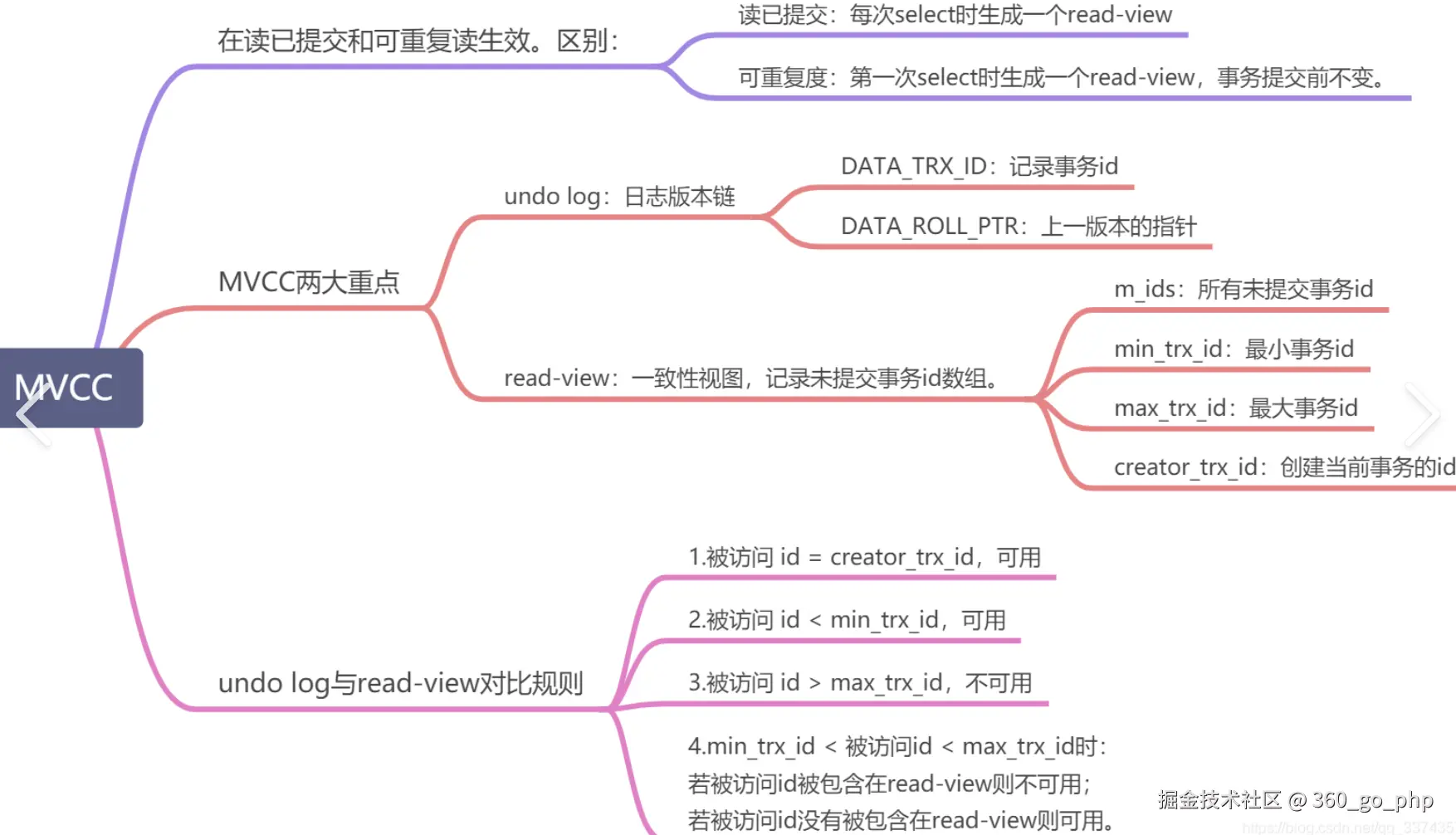 编辑
编辑
MVCC (多版本并发控制)是MySQL实现事务隔离的机制,常用于InnoDB存储引擎中。
-
原理:MVCC通过为每行数据维护多个版本来实现并发控制。每个事务对数据的操作都会生成一个新的版本,并且每个版本都包含了事务的开始时间和结束时间(或提交时间)。这样,事务在执行过程中可以看到自己的数据修改,但看不到其他事务未提交的数据。
-
实现 :
-
Undo Log :记录了数据修改的前一个版本,用于回滚操作。
-
系统版本号 :每个事务都有一个唯一的ID,数据库通过该ID来区分哪些数据版本对当前事务可见。
-
-
可见性判断:每个事务在查询数据时,都会根据当前事务的ID来判断某个数据版本是否可见。
总结
掌握MySQL的基础原理与高级特性是面试成功的关键,尤其是在涉及性能优化、事务控制和分布式系统设计时,良好的数据库理解能够使在面试中脱颖而出。