前言
我是[提前退休的java猿](https://juejin.cn/user/465848660928872 "https://juejin.cn/user/465848660928872"),一名7年java开发经验的开发组长,分享工作中的各种问题!(抖音、公众号同号)
🔈PS: 最近多了一个新的写作方向,就是会把出版社寄来的【java深度调试技术】按照书的骨架提取其中干货进行丰盈写成博客,大家可以关注我的新专栏
第二章的主题是通过堆栈分析性能瓶颈,但是介绍通过的堆栈分析的性能瓶颈的内容其实不多。更多的是介绍性能瓶颈相关的基本原理,其次是分享了一些造成性能瓶颈的不合理的设计或者是编码或者是配置,最后分享了定位性能瓶颈的相关手段和解决方案下面就给大家分享一下具体的内容吧
通过堆栈分析性能瓶颈
基本原理分析
这一章节在书中主要讲了:计算机的几大核心计算任务,各自主要消耗哪种硬件的性能;以及哪些操作会消耗 CPU 资源,哪些操作不需要 CPU 参与。
比如我们的IO操作,以及3D加速图形渲染这些操作几乎是不消耗我们CPU的性能的。
比如我们现在的服务器大多都是多核系统,所以在做CPU密集型任务的时候,可以采用多线程的形式的,提高CPU的使用率,从而提高系统的执行效率。
常见性能瓶颈问题
CPU 瓶颈
CPU瓶颈又分为两大类,一类是过度消耗CPU,一类是没有把CPU利用起来。 也可能因为其他的配置导致我们JVM GC频繁也会导致我们的CPU飙高。
CPU过度消耗或者说是CPU被滥用: 比如不恰当API的使用,低效算法的使用等消耗CPU的操作
String +的滥用,在拼接字符串的时候会产生临时对象这个期间不仅仅会消耗CPU也会占用内存。
低效算法的使用,比如高频的使用冒泡排序,或者for循环遍历,可以考虑是否使用Hash算法以空间换取时间的策略,减少CPU的消耗
双重 for 循环匹配(低效)
java
public List<FullData> dataUnion(List<DataA> listA, List<DataB> listB) {
List<FullData> result = new ArrayList<>();
// 外层循环遍历 listA(1000次)
for (DataA a : listA) {
// 内层循环遍历 listB(1000次)
for (DataB b : listB) {
// 每次循环都要比较 id(CPU 密集型操作)
if (a.getId().equals(b.getId())) {
result.add(new FullData(a, b));
break; // 找到匹配后跳出内层循环
}
}
}
return result;
}Hash 结构(HashMap)匹配(高效),减少CPU的使用率以空间换时间
java
public List<FullData> dataUnion(List<DataA> listA, List<DataB> listB) {
// 1. 将 listB 转为 HashMap(key=id,value=DataB),耗时 O(m)
Map<Long, DataB> bMap = new HashMap<>();
for (DataB b : listB) {
bMap.put(b.getId(), b); // 哈希计算耗时极短,平均 O(1)
}
// 2. 遍历 listA,通过 id 从 HashMap 中直接获取匹配数据,耗时 O(n)
List<FullData> result = new ArrayList<>();
for (DataA a : listA) {
DataB b = bMap.get(a.getId()); // 直接通过哈希定位,无需循环比较
if (b != null) {
result.add(new FullData(a, b));
}
}
return result;
}CPU没有被利用起来: 比如锁的粒度过大,导致所有线程都等待IO操作 或者 在处理CPU密集型任务的时候,使用单线程处理。线程池数量设置得太低等操作。
▶ 反例(低效)CPU密集型任务:单线程处理效率:
java
List<File> files = getFiles(); // 100 个文件
for (File file : files) {
parseFile(file); // 单线程逐个解析,总耗时 100×10=1000 秒
}▶ 优化(高效)使用多线程提高CPU的使用率:
java
ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
List<File> files = getFiles();
files.forEach(file -> executor.submit(() -> parseFile(file))); // 并行解析
executor.shutdown();
executor.awaitTermination(1, TimeUnit.HOURS); // 总耗时约 100/8≈12.5 秒(8 核 CPU)IO 瓶颈
要提高IO效率的,先不考虑硬件的性能(当然硬件的性能是基础了,磁盘IO速度本身就慢的话,代码效率才高也是微乎其微啦) 代码层面上提高IO效率的方式主要有以下几种减少 I/O 次数、优化 I/O 效率、避免 I/O 阻塞
减少IO次数的因为是我们程序员最应该注意的,比如和数据库交互,能批量处理的就批量处理,不仅仅能减少网络IO也能减少磁盘IO大大提高程序性能
这里也要注意了,有些人认为一次查询的性能远大于多次查询的性能。 在需要多表联查的情况,一次多表join返回结果确实能提高IO的效率,但是join操作时比较消耗数据库的CPU的,我们站在整个系统的角度来看,我们数据库就是我们性能短板(大多数情况),所以有时候把CPU的压力 转移到 我们应用服务起来这样能提高我们系统整体的性能。
避免循环读取 / 写入单行数据,改用缓冲区一次性批量处理。
▶ 反例(低效):
java
// 逐行写入,每次 write 都可能触发磁盘 I/O
try (FileWriter writer = new FileWriter("data.txt")) {
for (String line : lines) {
writer.write(line + "\n"); // 多次 I/O 操作
}
}▶ 优化(高效):
java
// 先拼接成批量数据(内存操作),再一次性写入
try (BufferedWriter writer = new BufferedWriter(new FileWriter("data.txt"))) {
StringBuilder sb = new StringBuilder();
for (String line : lines) {
sb.append(line).append("\n"); // 内存拼接,无 I/O
}
writer.write(sb.toString()); // 1 次 I/O 完成
}JVM的异常
JVM的异常 比如Full gc 首先也是非常消耗CPU 的,涉及到大量的运算和对象复制回收。同时在这期间还会到 stop the word 问题,可能导致这期间堆积大量的请求 引发更多的系统问题。
当然JVM 还可能出现内存分配效率低、内存溢出(OOM) 这些问题会直接导致服务响应变慢、频繁卡顿甚至崩溃。
所以JVM的稳定运行至关重要:关于Full GC 以及OOM 的问题我都写过相关的文章,大家可以去看看定位过程和解决思路
如何判断系统是否存在性能瓶颈
这块在书中也是介绍了比较多内容,简单的理解就是 通过逐步增加系统压力,CPU使用率呈现(半)抛物线的增长趋势直到CPU使用达到100%,如果随着系统的压力增加 CPU的使用率 无法增长说明系统存在性能瓶颈,当然就算CPU使用率随着压力的增大到达100%了也不能排除没有性能问题,比如CPU被大量String + 所占用。
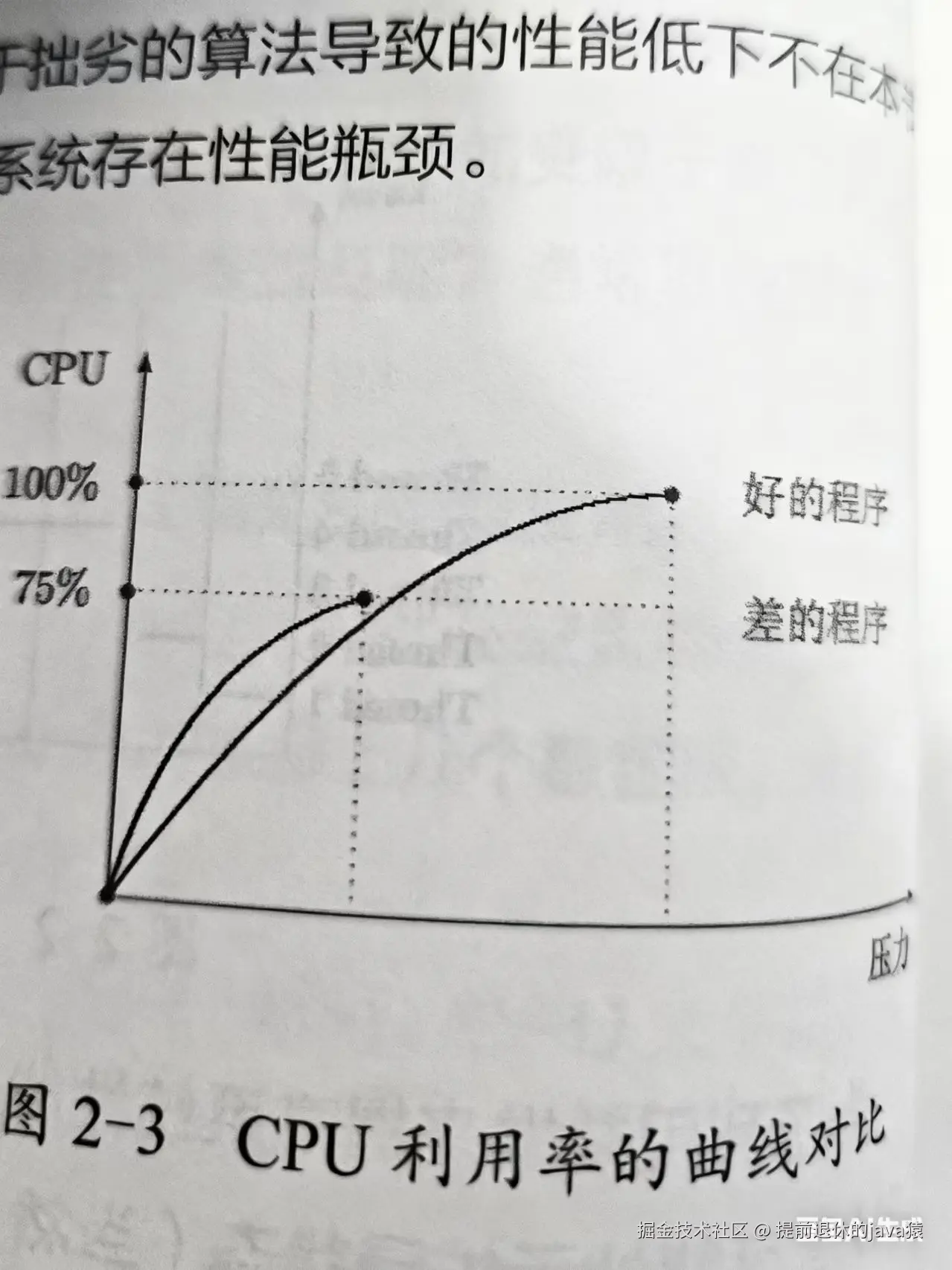
性能瓶颈分析的手段和工具
性能瓶颈是动态的,低负载下不是瓶颈的地方,在高负载下可能成为瓶颈。许多商业工具JProfiler、Optimizeit 本身带来很大的开销。所以这种情况采用线程堆栈才是有效的分析方法。
- 线程数量太少,没有把cpu利用起来
- 锁粒度太大,线程被阻塞(比如锁中有耗时的IO操作等)
- 资源不足,如数据库连接不够,线程被挂起
- 处理效率低(如http操作,SQL性能低)
如果是锁粒度太大,通过堆栈很容易分析出
js
// 等待锁 0x00007f9a880059b8
"Thread-2": waiting to lock monitor 0x00007f9a880059b8 (object 0x00000000f771aec8, a java.lang.Object), which is held by "Thread-11"
// 等待锁 0x00007f9a880059b8
"Thread-1": waiting to lock monitor 0x00007f9a880059b8 (object 0x00000000f771aec8, a java.lang.Object), which is held by "Thread-21"多个线程等待同一把锁,所以我们得到堆栈信息,可以群全局搜索 waiting to lock 看看是否存在等待同一把锁得情况,排查是否锁粒度过大是否有低效率的代码问题
总结
通过本篇内容,能实实在在学到一套 "定位 + 解决" 系统性能问题的实用方法论,不是空泛的理论。
我们讨论了 CPU、IO、JVM 这三大性能瓶颈的具体诱因,以及怎么去分析是否存在性能瓶颈问题。比如看压力增大时 CPU 使用率是否跟着涨,就能初步判断系统卡在哪。通过线程堆栈里的 "waiting to lock" 排查锁竞争,定位线程阻塞的代码。
以 java 深度调式技术 第一章堆栈分析内容为主线,也在其内容骨架上做了一些补充吧。希望本片文章能对你起到一定的作用。