注:本文测试图像均为AI生成;
概念
眼镜祛反光算法是一个非常有用的拍照功能,对于戴眼镜的小伙伴而言,很多时候,阳光明媚的天气,旅游拍照都会存在眼镜反光问题,非常影响照片效果,比如下面的场景:

眼镜反光区域影响了五官的完整效果,受人诟病,而祛反光的需求也就由此而生。
算法方案
目前主流的技术方案有两种:传统CV方案和AIGC方案
传统CV方案
1.基于光线反射模型的深度学习算法;
Paper: Anti-Glare: Tightly Constrained Optimization for Eyeglass Reflection Removal
专门针对眼镜反光的专业论文只有这一篇,主要基于反射模型来构建,如下图所示。用"反射稀疏 + 人脸对称性 + 反射颜色一致性"三种强先验,通过逐步收紧约束的非凸优化,在极少迭代内从单张图像中分离眼镜反射。感兴趣的小伙伴可以去下载看一下。学术界对于通用反光祛除的论文是非常多的,这里不再赘述。这一类算法的优点是速度快,缺点也比较明显,过度依赖先验假设约束,效果一般,自适应能力差,比如假设人脸左右近似对称,在实际应用中,往往是大角度侧脸,这种左右近似对称就不太合理了。

2.基于GAN进行端到端训练,得到眼镜反光祛除效果;
这个方案典型案例就是像素蛋糕,厦门真景科技在24年申请了对应的专利:一种基于深度学习的图像去反光方法,详细介绍了眼镜反光数据集的构建,并以端到端的GAN网络进行了眼镜反光祛除的模型训练。像素蛋糕的效果在可编辑图像生成大模型出来之前,一直是最好的。
方案思路:
①数据集构建
准备一些不戴眼镜的人脸数据+眼镜素材,根据3D人脸建模将眼镜素材贴到人脸上,构建大量戴眼镜的人脸数据;
在眼镜区域模拟镜面反射,将反光以不同的图层混合模式叠加到眼镜区域,同时,对反光图层区域进行模拟退化降质处理,以此来构建大量的戴眼镜无反光原图和有反光效果图,组成海量数据对;
②祛反光网络
有了成对数据,使用类似Pix2Pix的GAN网络来进行祛反光模型训练,LOSS使用VGG、L1和GAN损失即可。
这种方案的难点就是成对数据集的构建,优点是速度快,基本上像素蛋糕的处理速度在毫秒级,算法本身也可以做到手机端实时处理,同样适合手机场景使用。
市面上像素蛋糕和百度网盘AI云修大概率都是基于GAN网络技术方案来构建的,对应效果举例如下图所示:

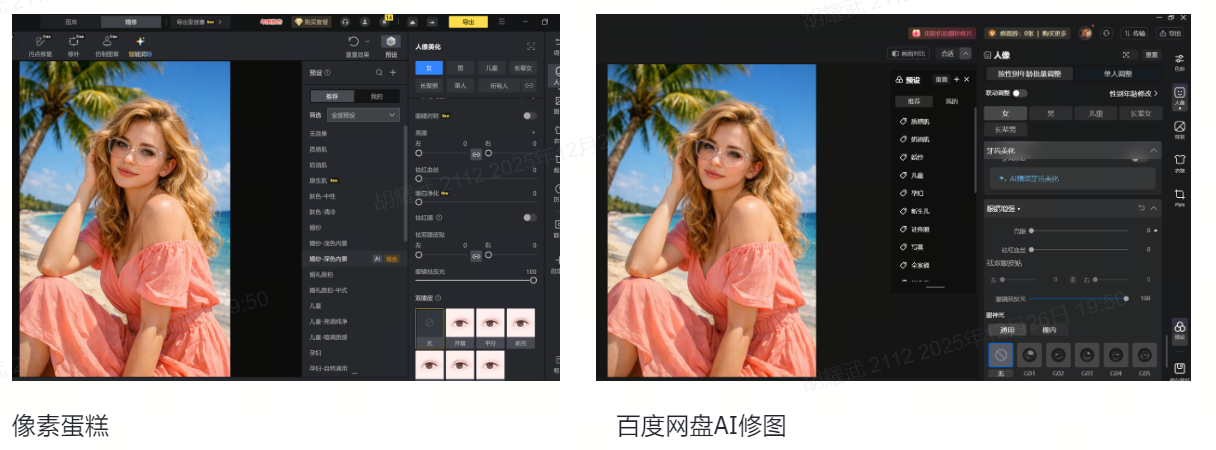
从效果上来看,像素蛋糕效果最佳,百度效果一般,估计是数据集分布不够或者数据集太少。
AIGC方案
目前基于图像编辑的大模型,基本都可以实现眼镜祛反光效果,可用的大模型如:Banana,Flux kontext, Qwen image edit等;
以Flux kontext为例,Prompt描述:Removal of reflections on eyeglasses,Other content remains unchanged.
中文prompt:祛除眼镜反光,其他内容保持不变
我们使用ComfyUI进行测试,效果举例如下:

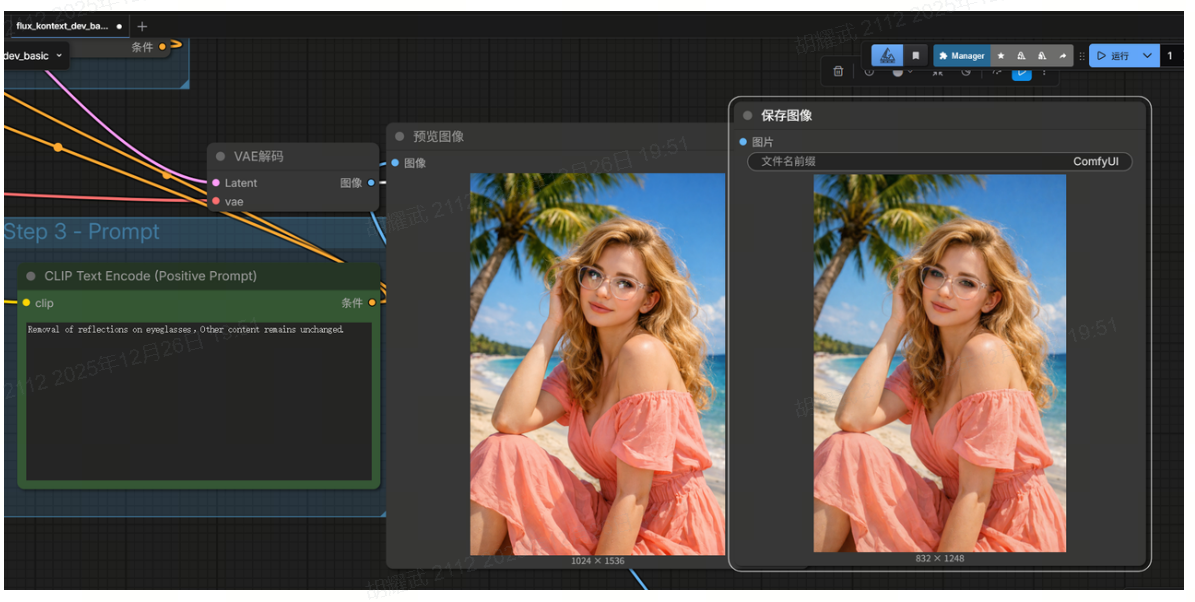
对于这一类,如果要保证比较稳定的效果,单单依靠Prompt还是不太够,最稳妥的方法是训练一个lora,来减少抽卡问题。以flux kontext和qwen image edit为例,训练Lora的代价极低,仅需要10-20个数据对(有眼镜+反光,有眼镜+无反光),使用AI Toolkit工具即可完成训练。
AI Toolkit:https://github.com/ostris/ai-toolkit
基于图像编辑大模型的方案,有以下几个问题:
①模型本身无法处理较高分辨率,一般在2048以下,现有方案大多是结合超分来提升分辨率,但最终效果与高分辨率的原图在人物细节上还是有比较大的差异,尤其是人脸面积占比较小的场景,人脸细节还原度较差。
②效果图与原图在细节以及颜色上可能存在偏差,比如qwen image edit存在漂移等问题,直到最新的qwen image edit2511也只是减弱了这个问题,并没有完全解决。
③处理速度较慢,资源消耗大,单卡24G 4090一般在10s+,量化模型造成细节损失,原版的qwen image edit 24G显存无法运行。
④对于多人合照场景,每个人的人脸去反光(或其他编辑)效果不可控。
当然,该方案最大的优点是效果好,整体效果观感要超越传统CV效果;
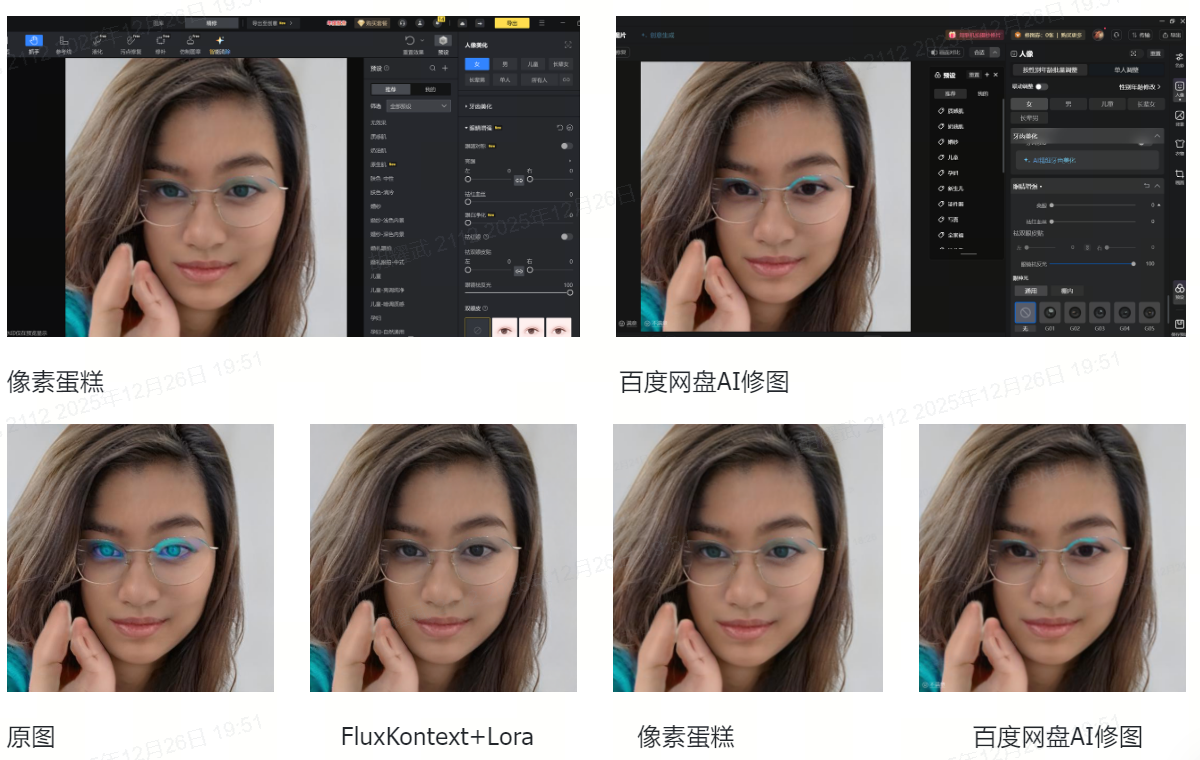
这里给出一些实例对比:
实例一


兼顾性能和效果的方案
这里本人给出一种个人建议方案:
1.数据集构建
①准备200张带有眼镜反光的图像,裁剪出人脸区域并做对齐,尺寸512×512,然后进行StyleGan训练,得到眼镜反光人脸生成器,生成5W张有眼镜反光的人脸数据集;当然,也可以直接由图像生成大模型来生成数据集,但时间成本较大,不可控性较强;
②准备10对有-无反光的戴眼镜数据对,裁剪512×512人脸区域,训练Flux kontext lora,得到眼镜反光祛除lora模型;
③用Flux kontext+反光祛除lora,批量处理①中的5W有眼镜反光人脸数据集,人工筛选得到符合要求的有眼镜反光-无眼镜反光的数据对;
2.模型训练
设计Gan网络模型(根据场景需求,处理高清图片的场景可基于transformer设计稍大的模型,处理手机端图像或视频,可使用轻量GAN模型),训练得到人脸区域眼镜反光祛除模型;
3.模型使用
对任意一张用户图,检测人脸,对每个人脸区域进行裁剪对齐,分别送入祛眼镜反光模型,得到人脸祛眼镜反光效果,设计人脸区域Mask蒙版(或眼镜检测分割得到精确眼镜区域蒙版),将效果图和原图进行融合,至此,实现任意人脸个数的眼镜反光祛除效果。
优点:
使用StyleGan构建眼镜反光人脸生成器,可无限生成反光数据,结合Lora模型,可构建高质量的成对数据集;
基于GAN构建模型,避免了大模型的耗时和资源占用问题;