
🌟 SENet 的故事:让网络自己学会"聚焦重点通道"
一句话概括本文:SENet
的核心思想不是"怎么卷得更深",而是"怎么让每一层卷积更聪明"------它教会网络"自我审视":哪些通道重要、哪些可以忽略,从而实现轻量级、通用性强、效果显著的性能提升。
关键数据:在 ResNet-50 上仅增加 0.26% FLOPs 和 10% 参数量,就达到接近 ResNet-101
的精度;ILSVRC 2017 分类冠军(Top-5 Error 仅 2.251%),相对前一年下降 25%!
一、研究背景:CNN 的"空间注意力"已经很火,但"通道注意力"却被长期忽视
传统 CNN(如 AlexNet、VGG、ResNet)通过堆叠卷积层,在局部感受野内融合空间信息(即像素点之间的位置关系)与通道信息(即不同特征图代表的语义,如边缘、纹理、部件等)------这种融合是隐式、静态、均匀的。
近年来,大家开始意识到:并非所有特征都同等重要。于是,"注意力机制"(Attention Mechanism)成为热门研究方向:
- ✅ 空间注意力(代表工作:Spatial
Transformer、Self-Attention、Non-local):关注"图像的哪些区域更重要",比如检测时聚焦目标物体; ❌ - 通道注意力(Channel-wise
Attention):长期被忽略------网络从不主动思考:"这些通道(特征图)里,哪些对当前任务更关键?"
🧠 举个生活例子: 就像医生看 CT 影像:
空间注意力:聚焦肿瘤所在的区域(不看背景); •
通道注意力:判断哪些模态图(如T1加权、T2加权、增强后图像)对诊断该类肿瘤最敏感------比如对脑胶质瘤,T1增强图最关键,而对水肿区域,T2-FLAIR 图更可靠。
而当时主流模型(包括 ResNet、Inception),对通道的使用是固定权重的------就像医生机械地把所有模态图平均加权,从不根据病人病情动态调整。
二、问题(Challenge):为什么"通道重标定"这么难?
Challenge 的本质: 因为 CNN 的卷积操作本身具有局部性 &
通道独立性,所以很难建模"跨通道的全局语义依赖";而这种依赖恰恰是实现动态特征增强的关键。
具体来说,有三层挑战:
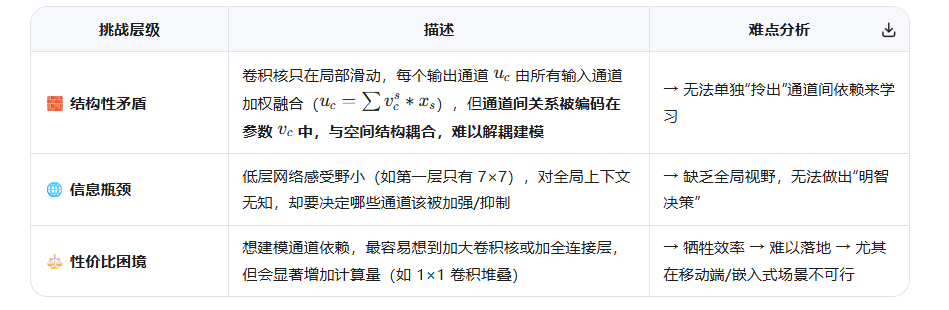
💡 所以:要实现"通道重标定",必须同时满足三个条件:
全局感知(突破局部感受野限制) 显式建模通道依赖(而非隐式耦合) 轻量化设计(几乎不增加 FLOPs/参数)
------这三者看似互相矛盾,传统方法难以兼顾。
三、Finding(关键洞见):"压缩-激励"是一种低成本建模全局通道依赖的普适范式
"通道的重要性不是绝对的,而是与输入信号强相关的;而这种相关性可以通过一个'全局压缩→特征抽象→动态激励'的三步流程,在极低开销下被建模。"
更直白地说:
🌟 "先对空间维度做'全局平均'压缩,得到每个通道的'摘要统计量';再用一个小网络学习这些摘要之间的非线性关系;最后用学到的权重反哺原特征------就像给神经网络装了一个'自适应通道调音台'。"

🌰 举个例子:
假设网络学到 3 个通道:边缘响应, 颜色饱和度, 纹理粗糙度。
对"金鱼"图片:可能 边缘 和 颜色 很重要(鱼鳞反光+轮廓清晰),纹理 不重要;
对"悬崖"图片:可能 纹理 和 边缘 重要(岩石粗糙+轮廓锐利),颜色 不重要(多为灰色调)。
SE Block 就像一个"智能混音师":它先听完整首曲子(全局池化),再根据曲风(输入类别)调整各乐器音量(通道权重),最后输出更清晰的主旋律(重标定特征)。
这个 Finding 的伟大之处在于:它把一个高维、非线性、耦合的问题,通过"压缩→建模→重构"的信息瓶颈思想,转化成了一个可解、可插拔、可泛化的子问题。
四、总结与启示
SENet 的伟大,不在于技术多复杂,而在于思想足够简洁而深刻:
✅ 它告诉我们:"轻量级注意力"的核心不是堆参数,而是找对信息瓶颈";
✅ 它证明:"通道维度"的建模潜力被严重低估;
✅ 它启发后续无数工作:CBAM、ECA-Net、SK-Net、RepVGG 中的 SE-like 模块......
如今,SE Block 已成为现代 CNN 的标配模块之一(如 EfficientNet、RegNet、ConvNeXt 均采用其变体)。
🌟 终极启示:
很多时候,模型性能的瓶颈不在于"算得不够多",而在于"看得不够清"。
SENet 教会我们:让模型学会"自我反思"(Which channels matter?),比盲目堆深更有效。