资料来源:火山引擎-开发者社区
概述
向量检索正在进入"既要又要"的时代:既要高召回、低时延,又要可扩到亿级、成本可控。此前在火山云搜索中,我们引入磁盘化向量索引 DiskANN1,通过将向量存储在磁盘上,内存仅保留图文件,低成本支撑百亿级数据,将向量检索的成本减少 90% 以上。除了磁盘容量型场景,DiskANN 算法也支持全内存性能型场景,火山云搜索团队也已经在上半年将 SOTA 的 RaBitQ 量化算法与 DiskANN 相结合,在性能型场景将内存资源占用降低 85%,为高性能向量搜索带来极致性价比,目前已经实现规模化应用。
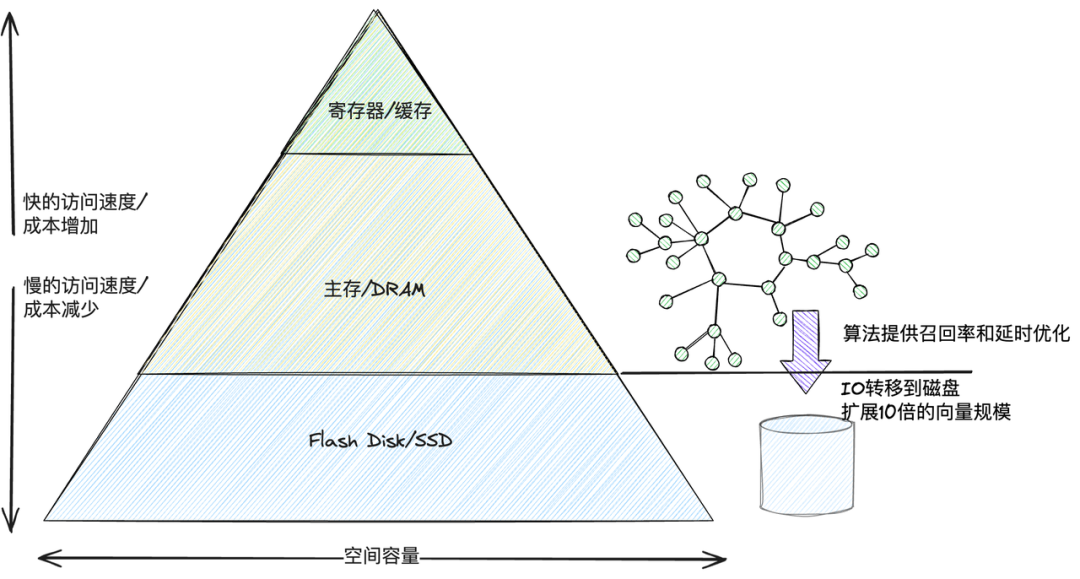
这次,我们将 DiskANN + RaBitQ 算法集成到火山引擎向量数据库 Milvus 版(简称"火山Milvus"),在保持原生 Milvus 丰富的开源生态与向量检索功能的同时,以更高的 QPS、更低的成本支撑亿级数据,其中磁盘索引 QPS 更是达到了 Milvus 社区版的 5 倍以上。
火山 Milvus vs 开源 Milvus
先上结论,在火山 Milvus 无论是容量型向量索引还是性能版向量索引,其性能、成本均全面优于开源 Milvus。
容量型向量索引
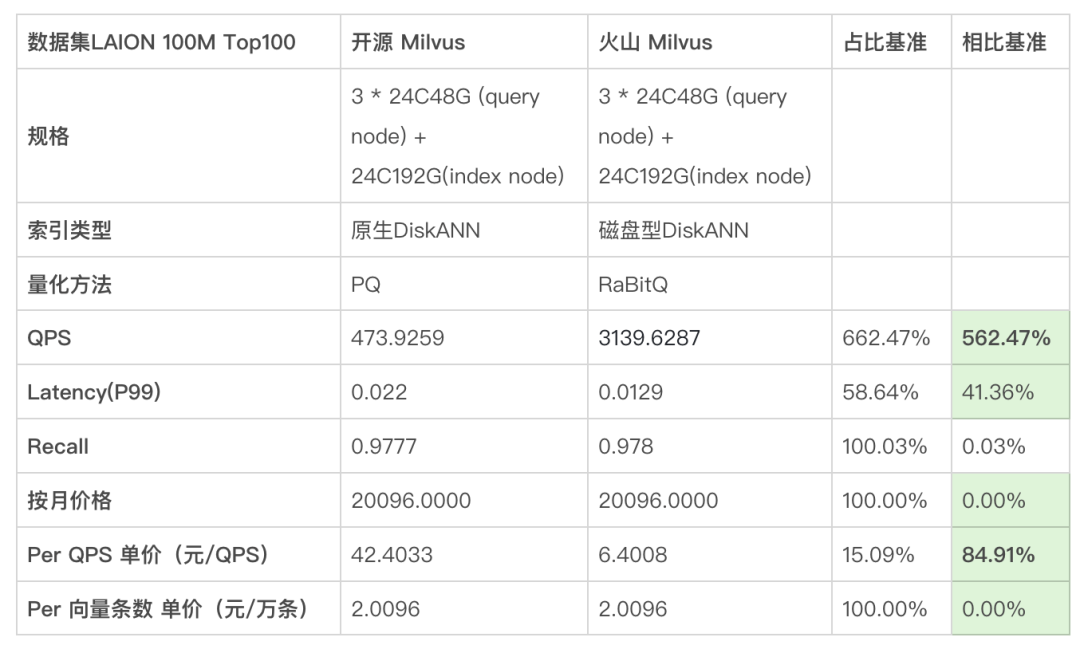
开源 Milvus 的磁盘版索引为 DiskANN,但不支持 RaBitQ 量化。同规格下测试,与支持了 RaBitQ 量化的火山 Milvus 相比:
- 火山 Milvus 性能是开源版 5 倍+
- 火山 Milvus 规格、按月价格与开源版相同,但得益于性能提升,其 Per QPS 单价要低于开源版 80%。
性能型向量索引
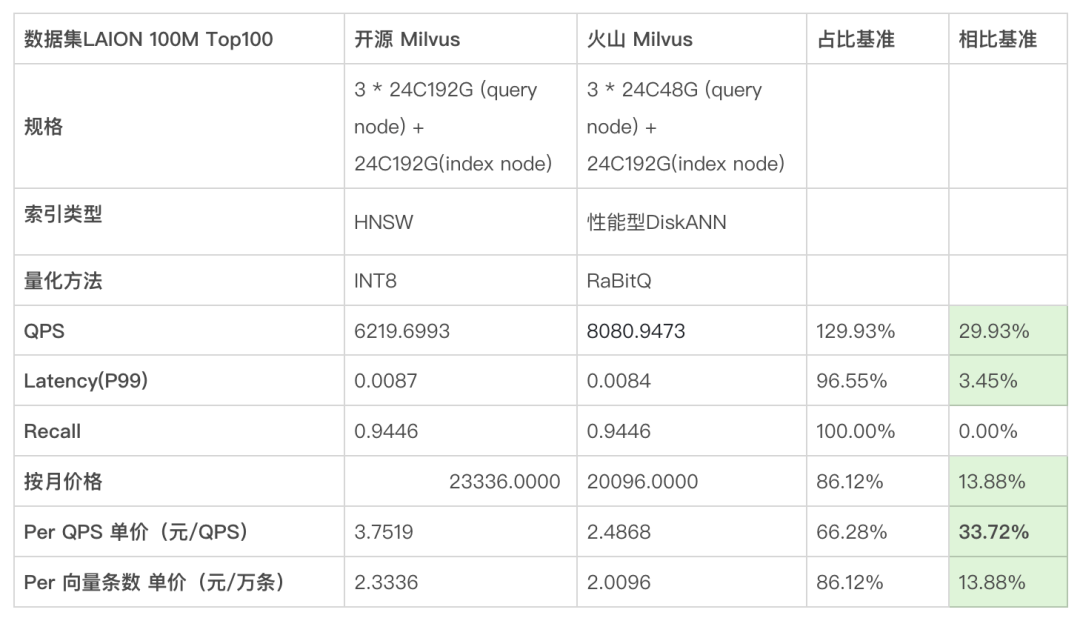
由于开源 Milvus 没有性能版的 DiskANN 索引,这里选择了使用同样为高性能内存索引的 HNSW (INT8 量化) 作为基准,与火山 Milvus 的性能版 DiskANN 对比。
相比于开源 Milvus,火山 Milvus 在性能版索引有以下优势:
- QPS 高于开源版 30%。
- 查询时 Query node 仅需 48G 内存,而开源需要 192G,从而火山 Milvus 按月价格较低。
- Per QPS 单价同样比开源版低 30%。
火山 Milvus 快在哪
之前团队的系列文章1已对 DiskANN 索引有过详细介绍,本节我们不再重复赘述,仅简单回顾一下 DiskANN 与 RaBitQ,及其结合的优势。
DiskANN:把索引搬到 SSD,还能跑得快、找得准
DiskANN来源于论文3,其核心思想是把"重活"交给 SSD:图索引与向量原始数据存放在磁盘,内存只缓存轻量的压缩向量与热点节点,查询时利用磁盘多路读取,成批拉取邻居,极大减少随机读的轮次。
两点关键设计让它既快又准:
- Vamana 图:通过两轮的剪枝构图,图的直径更小、长边更多,搜索收敛所需"跳数"更少,直接压低时延。

二维平面下的 Vamana 构图过程。首行是第一轮剪枝过程,次行是第二轮剪枝过程。可以观察到第二轮剪枝给 Vamana 构图带来了更多的长边,从而搜索收敛所需"跳数"更少。3
- 隐式重排:磁盘同扇区同时存放节点的邻居与其全精度向量数据,磁盘多路读取邻居的过程中顺便带上全精度向量,计算下一轮的邻居的同时也计算了本节点的精确距离。用精确距离做最终 Top-K 重排,召回更稳。
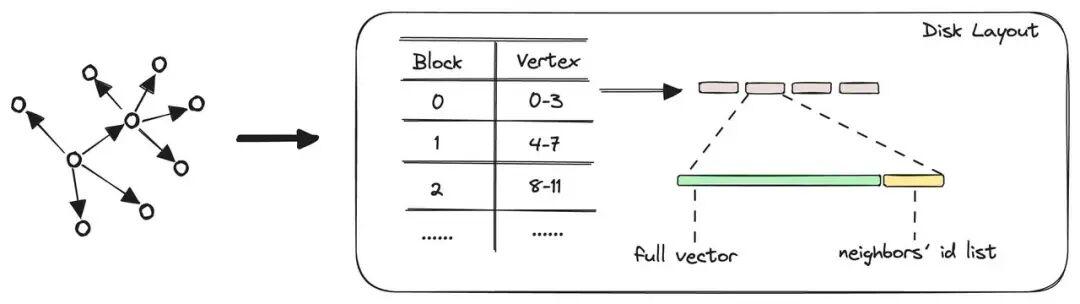
DiskANN 磁盘结构1
RaBitQ:向量极致压缩,算得更快、内存更省
RaBitQ(Random Bit Quantization)来源于论文5,是当下最SOTA的向量量化方案,它基于高维概率原理,通过将高维向量量化到一个单位球上,每一维仅需用1 bit表示。
下图以三维向量空间为例:对于三维向量,当我们把数据全部归一化后,这些数据就会均匀的分布在球面上。这时候有一个立方体(8个码点,坐标为
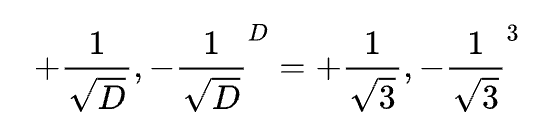
)来量化我们的球面上的点。
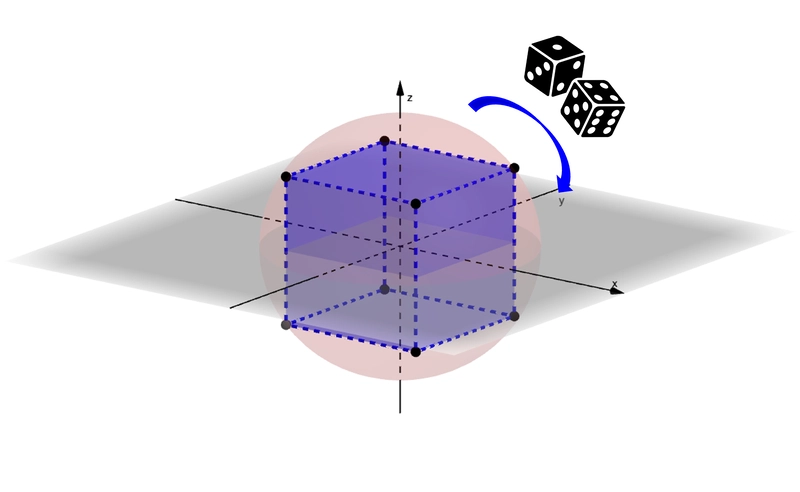
三维空间下,RaBitQ 将向量量化到单位球上,其中立方体的顶点视作向量经 RaBitQ 量化后的 1 bit 表示。4
直观上理解就是将球面上的N个点映射到了立方体的 8 个码点上,这样确实会带来非常大的误差。但是当我们的维度不断增长,比如达到了 1024 维的时候,我们就拥有
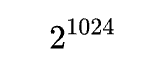
。 对于常见的向量距离比较,我们通过引入 RaBitQ 的计算可以做到比 PQ 更快的速度,更精准的距离计算,更少的内存:
- 内存占用降低:以全精度向量为例,每一维从原先的 32 bit(float32 类型)压缩至 1 bit,压缩比高达 32 倍。
- 计算更快:得益于高压缩比,向量间的距离计算转换为 bit 位运算,工程实现上火山 Milvus 结合了 AVX512 指令集,原先的 1024 维向量计算,现在仅需两次 VPOPCNT 完成,带来了极大的性能提升。
DiskANN + RaBitQ 结合实践:性能与成本的最佳平衡
磁盘版
在磁盘模式下,火山 Milvus 将 RaBitQ 量化后的向量存放于内存中,而原始数据及其邻居存放于磁盘中。搜索时先通过内存中的量化数据快速计算,再通过磁盘原始向量数据精确重排。
在整个搜索过程中,DiskANN + RaBitQ 带来了以下优势:
1.RaBitQ 将向量量化到 1 bit,使得同样内存下能够加载更多向量数据,同时 VPOPCNT 指令带来更快的向量计算。
2.Vamana 单层稀疏图的结构,大大减少了图检索过程中的跳数,进而提高检索效率。此外其磁盘结构能够减少随机 IO 的次数,进一步提升检索性能。
性能版
磁盘模式的 DiskANN 足够支撑大规模向量数据,但其检索过程中的磁盘 IO 对检索性能有一定影响。因此,针对内存充足、对检索性能有高要求的场景,火山 Milvus 提供了 DiskANN 性能模式。
相比磁盘模式,性能模式会将邻居节点以及全精度向量分开存储。检索时一次性加载到内存,避免反复 IO 带来的开销,达到极致性能。
火山 Milvus 是如何使用 DiskANN 索引的
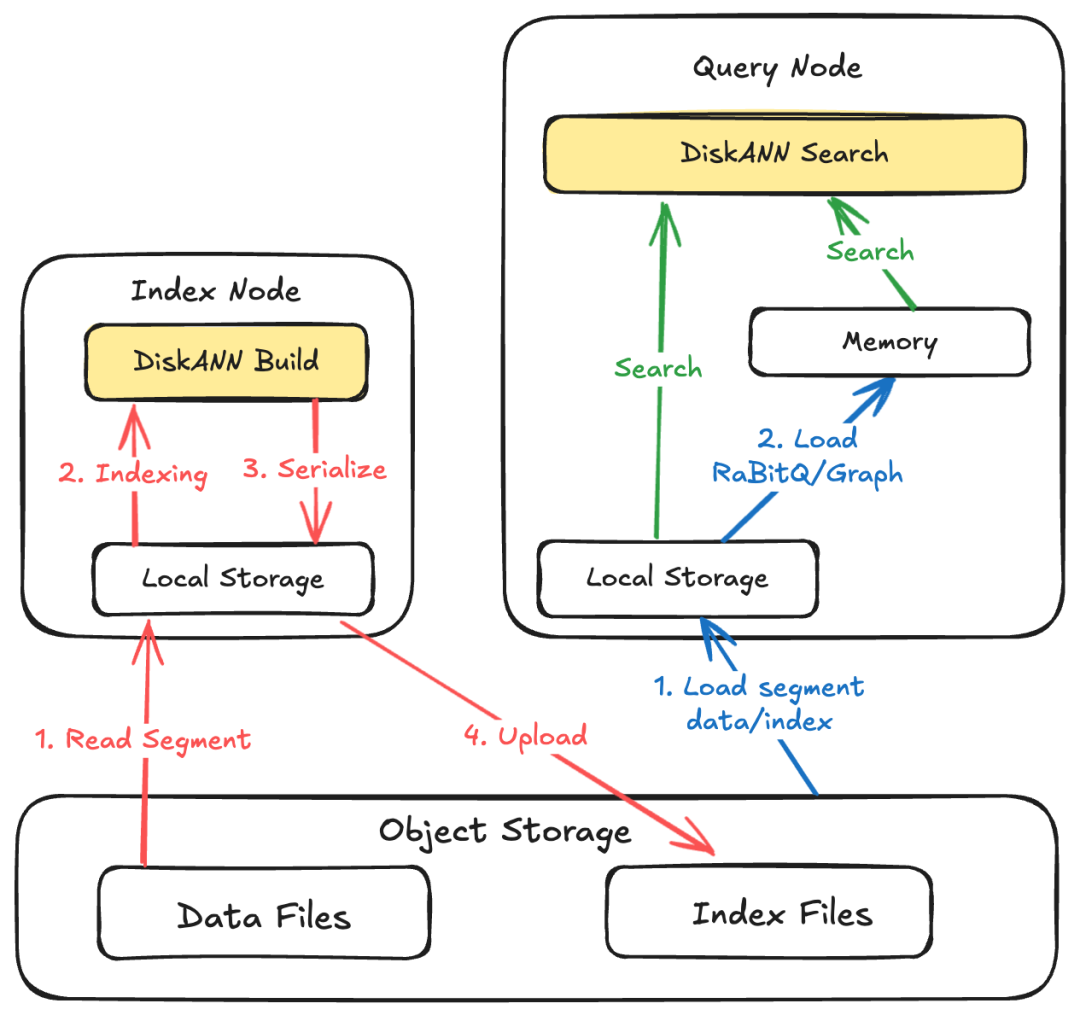
Milvus 向量索引使用流程,红线为构建步骤,蓝线为加载步骤,绿线为检索步骤
Milvus的索引使用分为构建、加载、检索三步:
1.构建:Index Node 从对象存储中加载原始数据到本地存储中,DiskANN 通过读取本地存储中的数据集,构建向量索引并生成索引文件落盘。最终,Index Node 将落盘后的索引文件上传至对象存储。
2.加载:Query Node 从对象存储中将索引文件加载到本地存储中,同时根据 DiskANN 磁盘模式/性能模式选择性加载部分数据到内存。
3.检索:Query Node 执行 DiskANN 检索算法。
火山 Milvus 产品公测预告
火山引擎向量数据库 Milvus 版 10.22 公测启动:AI 时代云原生向量检索,邀企业共探技术新边界!
火山引擎向量数据库 Milvus 版基于开源 Milvus 深度优化,以云原生托管形态打破部署门槛。无需投入底层运维成本,即可直接调用高可用向量检索能力,为企业 AI 应用(如大模型 RAG、图像检索、智能推荐)提供稳定算力支撑:
1.多地域覆盖:首批开放北京、上海、广州三大 Region,就近部署降低网络延迟,满足企业多区域业务架构需求。
2.全栈运维支持:内置实例生命周期管理、实时监控报警等核心运维能力,一键完成实例启停、扩容与异常排查,大幅减少运维人力投入。
3.专属技术对接:企业客户通过火山引擎销售团队申请公测,可获取定制化接入方案与工程师 1v1 技术支持,高效解决集成难题。
公测申请途径
1.进入火山引擎官网(https://www.volcengine.com/)页面,通过右侧【售前咨询】中任意一种方式进行申请。若已有火山客户经理,也可支持联系客户经理进行申请。
2.与售前同学建立联系后,申请向量数据库 Milvus 版邀测资格,并提供已完成火山企业认证的账号 ID,进行邀测开放。账号 ID 可通过火山引擎页面右上角获取。
即刻入局,定义 AI 检索新标准!