一、问题背景与需求分析
1.1 问题背景
马上就迎来了硕士论文开题的季节,忙着撰写学位论文的难题又落在了我的头上,一大堆的大量最新论文,让我实在是目不应暇。手动点开每篇记录标题、作者、引用次数,慢得让人着急。
那天和同组写论文的同学吐槽,发现他也遇到了一样的麻烦,我俩对着屏幕里几十篇待筛选的论文发愁,更头疼的是频繁使用 Google Scholar 时,总会出现异常。有时候连续搜了好几个关键词,页面就突然卡住了。后来才知道,Google Scholar 的保护系统特别敏感,像这种间隔较短、模式重复的请求,易被识别为非人工常规访问,导致访问受限,直接连正常查文献都没法弄。这些问题一出现,文献收集的进度就全卡住了。
1.2 为什么要做自动化系统?
吐槽完我俩合计着,总不能一直被 IP 异常卡脖子,不如一起搭个自动化系统。既能自动搜多个关键词的论文,把标题、作者、发表年份、引用次数这些信息自动提出来,最后存成 CSV 或 JSON 格式方便后续分析,省得再手动记;更关键的是,得解决学术采集过程中的平台访问稳定性问题,通过 HTTP 代理技术保障合规访问,不然系统再好用也白搭。
二、代理IP选择与配置
2.1 代理IP的分类
我们查了不少资料,发现市面上主要有两种代理。一种是数据中心代理,从机房来的,速度快还便宜,但 Google 很容易认出,用了还是会被识别出来;另一种是住宅代理,来自真实的家庭网络,虽然速度慢一点、贵一点,但胜在 IP 真实,Google 很难识别,用来做Scholar 正合适。
我俩对比下来,一致觉得必须选动态住宅代理 ------ 毕竟对 Google Scholar 这种防护严的平台,只有真实 IP 才能保证稳定采集。
2.2 代理配置
确定要选住宅代理后,同学说他之前需要学术数据时用过 IPIDEA 的代理,很方便又很稳定。于是按照他说的,我也去到了这个平台,首先打开控制台我们就会发现左侧菜单栏有个获取代理 , 点进去选择获取:
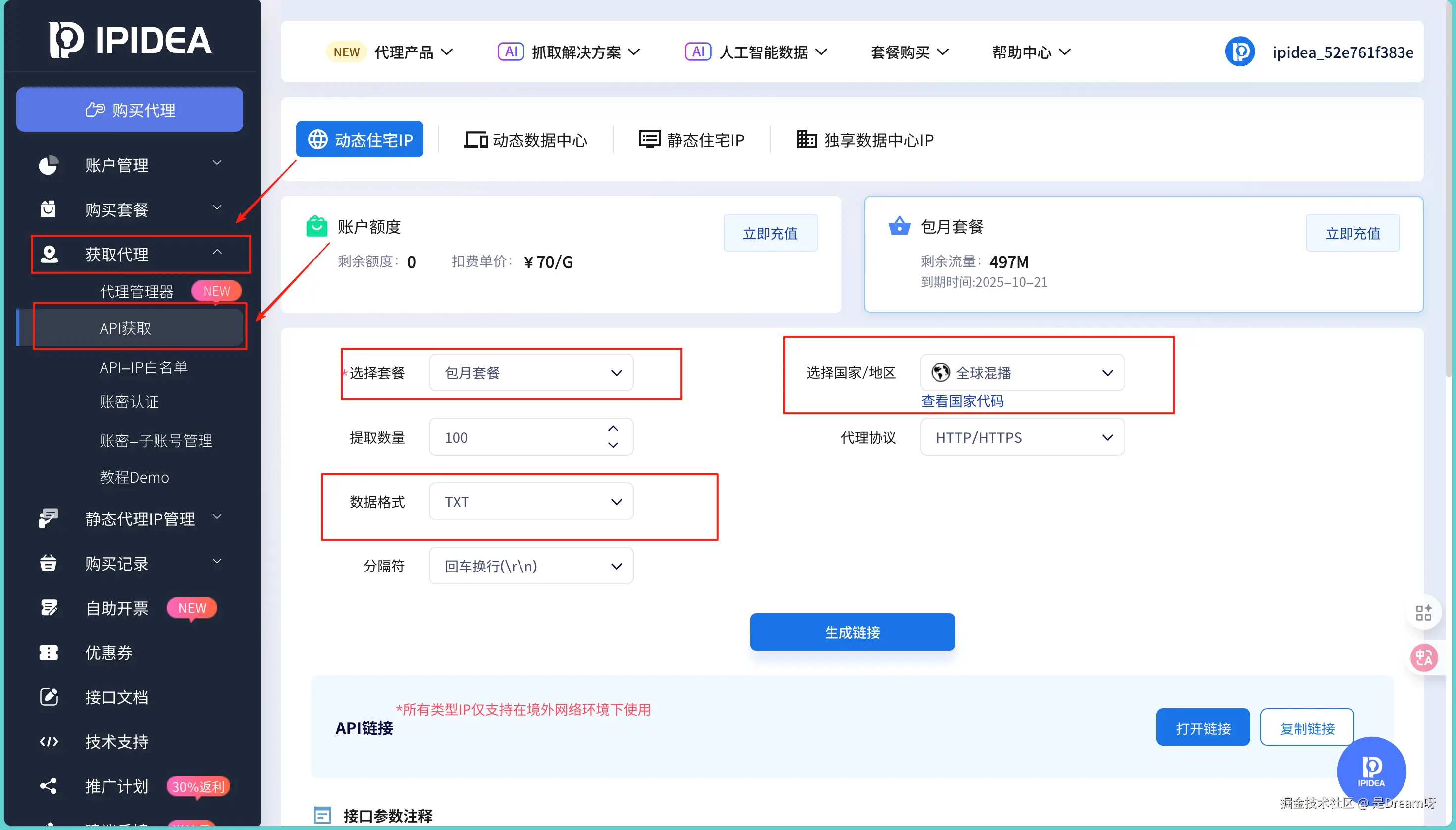
这里我们可以选择合适的套餐,我这个地方选的是一直在用的 "包月套餐";同时我们也可以根据需要选择不同的地区,这样能随机分配不同国家的住宅 IP;数据格式可以选择JSON和 TXT:
同时我更推荐我们用下面这种方法去获取,因为这个地方我们可以设置自己的名字,会更加方便和安全的使用代理,设置的方法和上面是完全一样的:
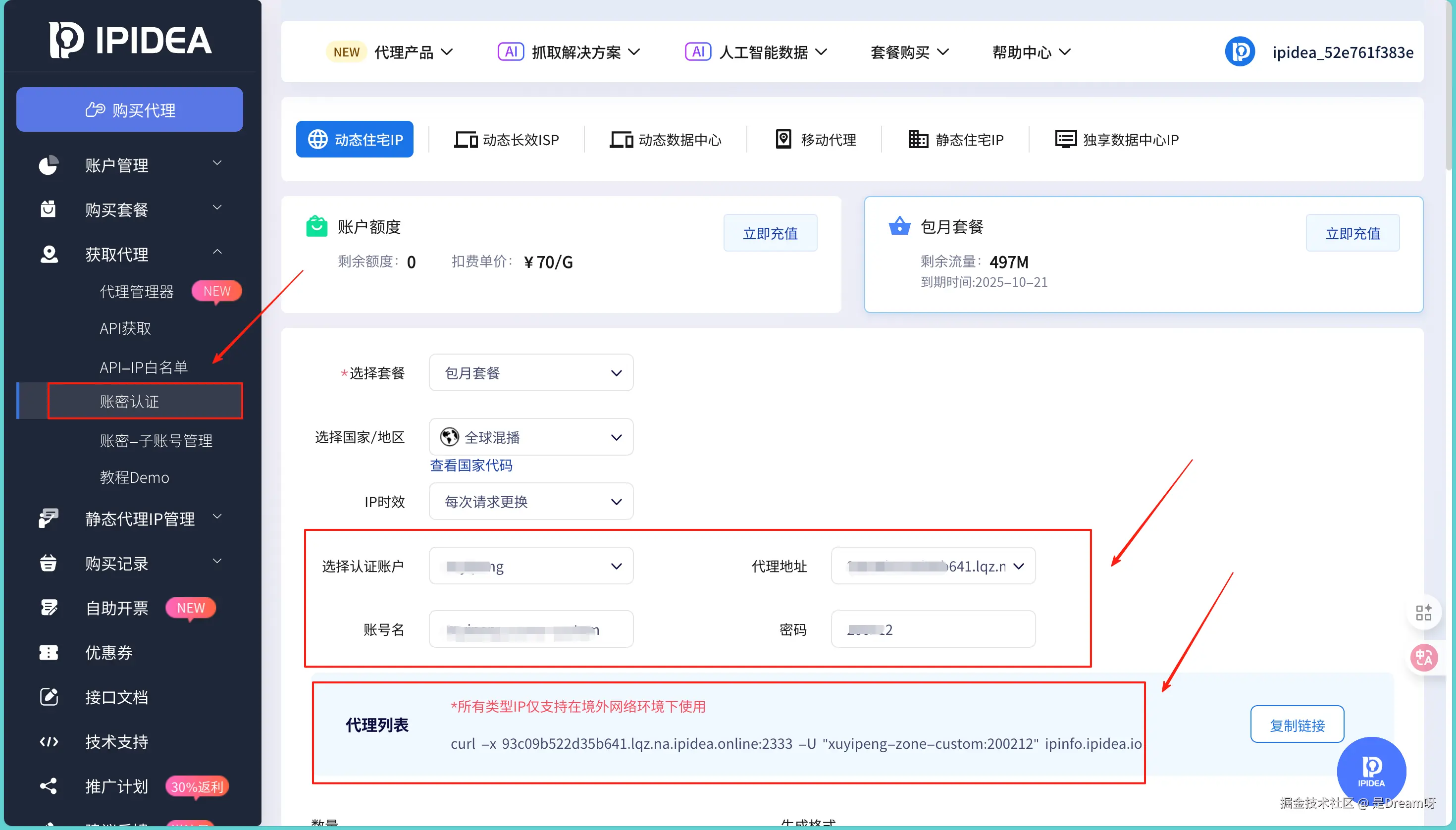
设置完这些,点击生成 ,平台就会生成一个包含代理 IP、端口、用户名的代理列表:
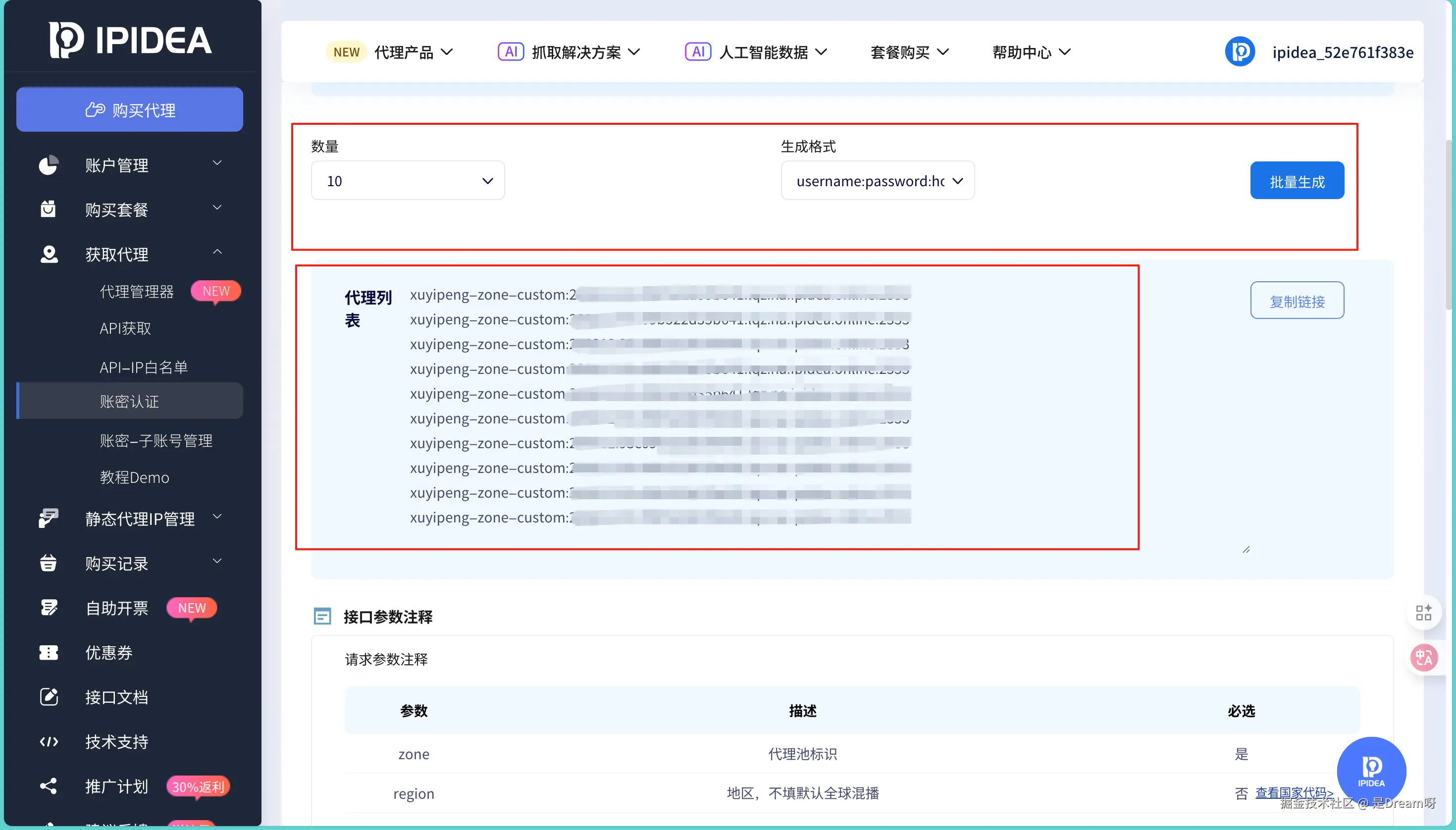
我们把链接里的信息拆出来,就得到了我们需要用到的配置:
ini
self.proxy_host = "93c09b52(你自己的地址)"
self.proxy_port = "(你自己的端口)"
self.proxy_username = "xuyip(你自己的账户名)"
self.proxy_password = "20(你自己的密码)"
# 构建URL
proxy_url = f"http://{self.proxy_username}:{self.proxy_password}@{self.proxy_host}:{self.proxy_port}"
self.proxies = {
"http": proxy_url,
"https": proxy_url
}这段配置其实很简单,就是告诉 requests 库、不管是 HTTP 还是 HTTPS 请求,都先通过这个代理服务器转发,数据会先到代理那边,再传给 Google Scholar,返回的结果也会走同样的路。
做完这些之后,不要忘记将我们自己本机的IP放到白名单中,添加进去,这样我们就可以放心使用了。
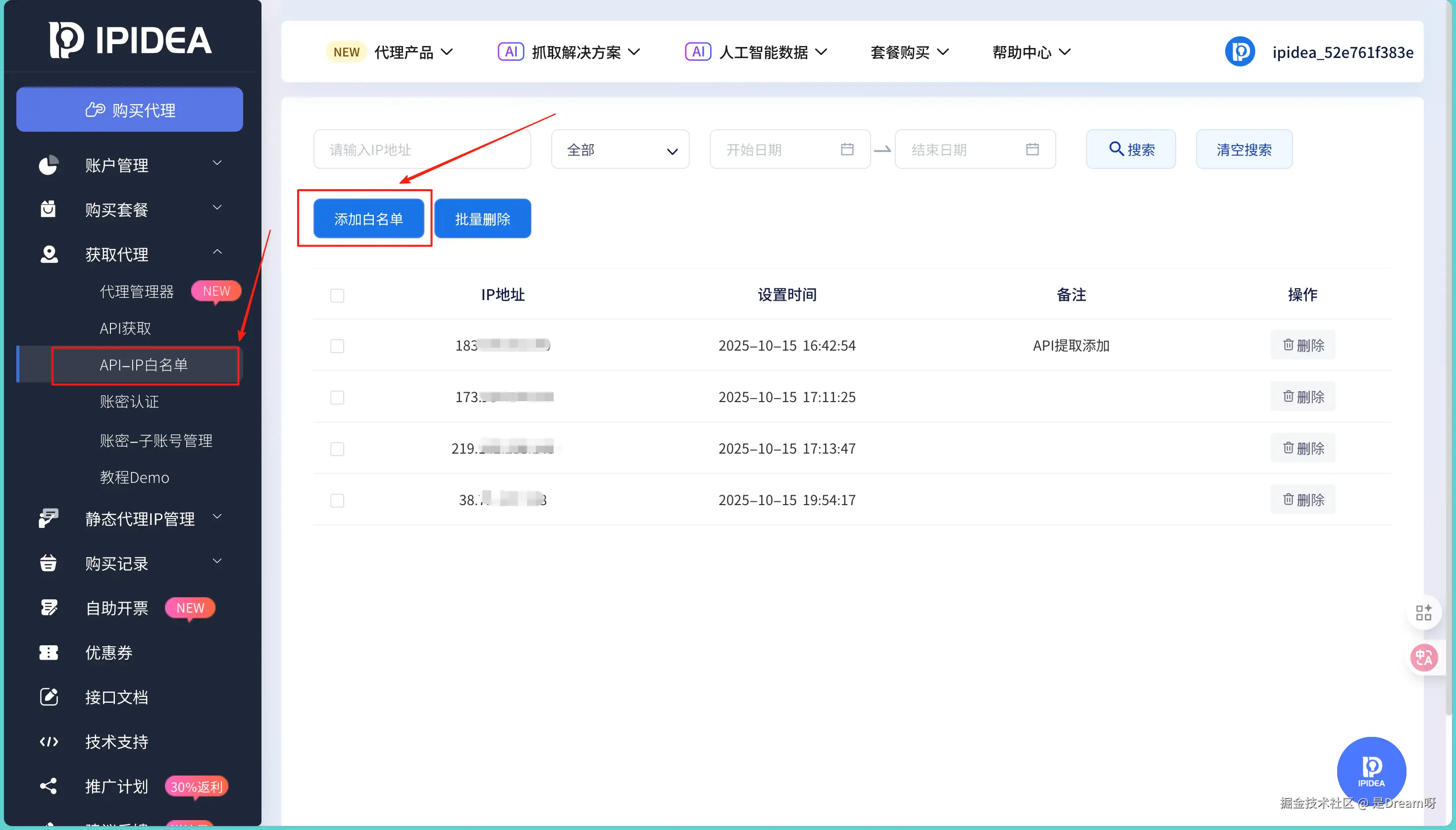
2.3 测试代理连接
在开始采集前,必须验证代理是否正常工作。我写了一个测试函数:
python
import requests
import time
import pandas as pd
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from typing import Dict, List
import socket
import urllib3
plt.switch_backend('Agg') # 关键:指定非交互式后端
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 替换原来的中文配置,适配Mac系统
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans'] # 优先用Mac自带中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# ---------------------- 1. 基础配置( ----------------------
username = "xuyip(你自己的账户名)"
password = "20(你自己的密码)"
hostname = "93c09b52(你自己的地址)"
port = "(你自己的端口)"
TARGET_URL = "https://httpbin.org/ip"
TEST_CYCLE = 3 # 减少请求次数,快速验证
REQUEST_INTERVAL = 2 # 延长间隔
TIMEOUT = 20
# ---------------------- 2. 核心函数(适配httpbin测试) ----------------------
def parse_tech_news(html_content: str) -> List[Dict]:
import json
try:
data = json.loads(html_content)
return [{"代理IP": data.get("origin", "未知IP")}]
except Exception as e:
return [{"代理IP": f"解析失败:{str(e)[:50]}"}]
def get_ipidea_proxy() -> str:
"""拼接代理URL"""
return f"http://{username}:{password}@{hostname}:{port}"
def crawl_with_ipidea_proxy() -> Dict:
"""发起请求,打印详细错误"""
proxy = get_ipidea_proxy()
proxies = {"http": proxy, "https": proxy}
start_time = time.time()
try:
print(f"正在用代理请求:{proxy}") # 新增:打印当前使用的代理
response = requests.get(
url=TARGET_URL,
proxies=proxies,
timeout=TIMEOUT,
verify=False,
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
)
response.raise_for_status() # 触发非200状态码异常
response_time = round(time.time() - start_time, 2)
news_data = parse_tech_news(response.text)
print(f"请求成功:代理IP={news_data[0]['代理IP']},耗时={response_time}秒") # 打印成功信息
return {
"status": "success",
"proxy_ip": hostname,
"response_time": response_time,
"news_count": len(news_data),
"fail_reason": "",
"request_time": time.strftime("%Y-%m-%d %H:%M:%S"),
"实际": news_data[0]["代理"]
}
except Exception as e:
response_time = round(time.time() - start_time, 2)
error_detail = str(e)
print(f"请求失败:{error_detail}") # 打印完整错误
return {
"status": "fail",
"proxy_ip": hostname,
"response_time": response_time,
"news_count": 0,
"fail_reason": error_detail,
"request_time": time.strftime("%Y-%m-%d %H:%M:%S"),
"实际": "未知"
}
# ---------------------- 3. 测试与分析(简化可视化) ----------------------
def run_ipidea_proxy_test() -> pd.DataFrame:
test_results = []
print(f"=== 开始连通性测试 ===")
print(f"信息:{username}:{password}@{hostname}:{port}")
print(f"测试目标:{TARGET_URL}\n")
for request_idx in range(1, TEST_CYCLE + 1):
print(f"\n第{request_idx}/{TEST_CYCLE}次请求...")
result = crawl_with_ipidea_proxy()
result["请求序号"] = request_idx
test_results.append(result)
time.sleep(REQUEST_INTERVAL)
result_df = pd.DataFrame(test_results)
result_df.to_excel("IPIDEA代理连通性测试结果.xlsx", index=False)
print(f"\n测试完成,结果已保存至Excel")
return result_df
def analyze_ipidea_test_result(result_df: pd.DataFrame):
total = len(result_df)
success = len(result_df[result_df["status"] == "success"])
success_rate = round((success / total) * 100, 2) if total > 0 else 0
avg_time = round(result_df[result_df["status"] == "success"]["response_time"].mean(), 2) if success > 0 else 0
# 打印核心结果
print(f"\n=== 测试结果汇总 ===")
print(f"总请求次数:{total} | 成功次数:{success} | 成功率:{success_rate}%")
print(f"平均响应时间(成功请求):{avg_time}秒")
# 简化可视化:只生成成功率饼图
if total > 0:
fig, ax = plt.subplots(figsize=(8, 6))
labels = ["成功", "失败"]
sizes = [success, total - success]
colors = ["#2E8B57", "#DC143C"]
ax.pie(sizes, labels=labels, autopct="%1.1f%%", startangle=90)
ax.set_title(f"请求成功率\n(总请求{total}次)", fontsize=14)
plt.savefig("成功率图表.png", dpi=300, bbox_inches="tight")
print("成功率图表已保存至:成功率图表.png")
# ---------------------- 执行入口 ----------------------
if __name__ == "__main__":
test_df = run_ipidea_proxy_test()
analyze_ipidea_test_result(test_df)如果返回的IP与我的本机IP不同,说明代理正常工作,运行结果:
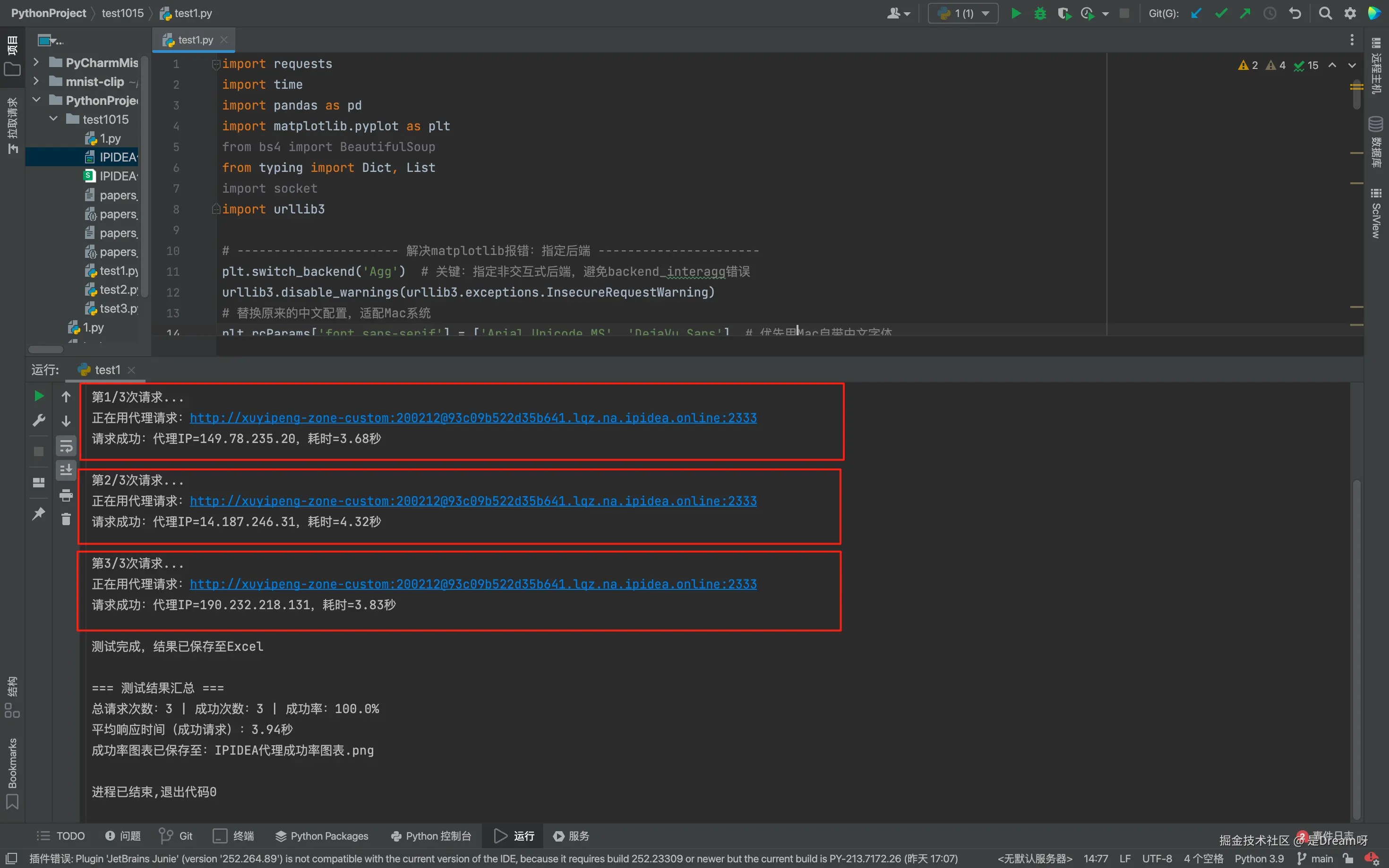
我们发现三次IP都和我们本机的IP不同,说明代理可以正常工作了,并且成功率是百分之百,还是很稳定的,大家如果想测试的话可以多测试几个。
三、实践过程详解
3.1 模拟请求
Google识别机器人的一个重要指标是请求头。真实浏览器会发送包含User-Agent、Accept-Language等信息的请求头,这些信息描述了浏览器类型、操作系统、语言偏好等。机器人通常使用相同的请求头,这容易被识别。
这里我一般会先维护一个User-Agent池,每次请求时随机选择一个:
python
import requests
import json
import csv
import time
import random
import re
from bs4 import BeautifulSoup
from typing import List, Dict
from datetime import datetime
class ScholarCrawler:
def __init__(self):
# ========== 代理配置 ==========
self.proxy_host = "93c09b52(你自己的地址)"
self.proxy_port ="(你自己的端口)"
self.proxy_username = "xuyip(你自己的账户名)"
self.proxy_password = "20(你自己的密码)"
# 构建代理URL
proxy_url = f"http://{self.proxy_username}:{self.proxy_password}@{self.proxy_host}:{self.proxy_port}"
self.proxies = {
"http": proxy_url,
"https": proxy_url
}
# ========== 请求配置 ==========
self.base_url = "https://scholar.google.com/scholar"
self.timeout = 20
self.max_retries = 3
self.delay_min = 2
self.delay_max = 5
# User-Agent池
self.user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0',
]
# 采集的论文列表
self.papers = []
# 测试
self._test_proxy()
def _test_proxy(self):
"""测试代接"""
try:
response = requests.get(
"http://httpbin.org/ip",
proxies=self.proxies,
timeout=10
)
if response.status_code == 200:
ip = response.json().get('origin')
print(f"✓ 连接成功")
print(f" 当前: {ip}")
else:
print(f"✗ 测试失败,状态码: {response.status_code}")
except Exception as e:
print(f"✗ 连接错误: {e}")
print(" 请检查配置是否正确")
def _get_headers(self) -> Dict:
"""获取随机User-Agent的请求头"""
user_agent = random.choice(self.user_agents)
return {
'User-Agent': user_agent,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
}3.2 随机延迟
在做这件事情前,我们需要意识到真实用户在浏览器中总得花时间看内容、思考,请求间隔是随机且有间隔的,所以我给请求间隔设定了一个符合真人浏览习惯的范围:2 到 5 秒。
python
def _random_delay(self):
"""随机延迟"""
delay = random.uniform(self.delay_min, self.delay_max)
time.sleep(delay)3.3 获取页面内容
要拿到论文数据,第一步得先把 Google Scholar 的搜索结果页面完整拉下来。这些页面是 HTML 格式的,需要先去用代码模拟浏览器发送请求,把这堆 HTML 文本取回来。
首先得理清楚请求里该带哪些参数。Google Scholar 的搜索链接里,q参数是搜索关键词,start参数控制页码 ------ 比如第 1 页是 0,第 2 页是 10(因为每页显示 10 篇),第 3 页就是 20,以此类推。为了只抓特定年份的论文,我还加了as_ylo和as_yhi两个参数,分别对应起始年份和结束年份,这样就能精准过滤时间范围了。
python
def _fetch_page(self, keyword, start=0, year_from=None, year_to=None):
# 构建请求参数
params = {
'q': keyword,
'start': start,
'hl': 'en'
}
# 如果指定了年份范围,添加到参数中
if year_from and year_to:
params['as_ylo'] = year_from # as_ylo 表示 "as year low"
params['as_yhi'] = year_to # as_yhi 表示 "as year high"
# 重试机制,最多尝试3次
for attempt in range(3):
try:
print(f" 正在获取第 {start // 10 + 1} 页 (重试: {attempt + 1}/3)...")
# 发送GET请求
response = requests.get(
"https://scholar.google.com/scholar",
params=params,
headers=self._get_headers(),
proxies=self.proxies,
timeout=20
)
# 成功获取
if response.status_code == 200:
print(f" ✓ 页面获取成功")
return response.text
# 其他状态码
else:
print(f" ⚠ 状态码: {response.status_code}")
self._random_delay()
continue
except requests.Timeout:
print(f" ⚠ 请求超时")
if attempt < 2:
time.sleep(5)
continue
return None3.4 解析HTML提取论文信息
拿到 HTML 文本后,就得从这堆标签里 "挑" 出有用的信息了。Google Scholar 的页面结构其实很有规律,每篇论文的信息都整整齐齐地包在一个class为gs_ri的div里,这就给解析提供了方便。
我把提取逻辑拆成了几步:第一步是抓标题和链接。标题通常在h3 class="gs_ct"标签里,里面的a标签既包含标题文本,又有指向论文详情页的链接。另外,有些结果会直接附 PDF 链接,我用正则表达式r'.pdf$'专门匹配这种链接,方便后续直接下载。
第二步处理作者、出版社、年份和引用数。这些信息都挤在div class="gs_a"里,格式大概是 "作者列表 - 出版社,年份 - Cited by 数字"。我用-把这段文本劈开,第一部分就是作者;第二部分里藏着年份,用正则r'\b(19|20)\d{2}\b'能精准揪出 4 位年份(比如 2023、1998);第三部分里的 "Cited by 数字",用r'Cited by (\d+)'就能把引用数提取出来。
第三步是摘要。摘要一般在div class="gs_rs"里,直接取文本就行,没有的话就留空。
最后有个小判断:只有成功提取到标题的,才算一篇有效的论文 ------ 毕竟标题是最核心的信息,缺了它其他数据也没意义。
python
def _parse_paper(self, element):
paper = {}
try:
# Google Scholar将标题放在 <h3 class="gs_ct"> 中
title_elem = element.find('h3', class_='gs_ct')
if title_elem:
title_link = title_elem.find('a')
if title_link:
# get_text() 获取标签内的文本
# strip=True 会去掉前后的空格
paper['title'] = title_link.get_text(strip=True)
# get('href') 获取href属性的值
paper['scholar_link'] = title_link.get('href', '')
# 正则表达式 r'.pdf$' 匹配以 .pdf 结尾的URL
pdf_link = element.find('a', {'href': re.compile(r'.pdf$')})
if pdf_link:
paper['pdf_link'] = pdf_link.get('href', '')
else:
paper['pdf_link'] = ''
# "作者列表 - 出版社, 年份 - Cited by 数字"
meta_elem = element.find('div', class_='gs_a')
if meta_elem:
meta_text = meta_elem.get_text(strip=True)
# 按 "-" 分割得到三个部分
parts = [p.strip() for p in meta_text.split('-')]
if len(parts) >= 1:
# 第一部分是作者列表
paper['authors'] = parts[0]
if len(parts) >= 2:
# 第二部分是出版社和年份,例如 "CVPR, 2020"
pub_info = parts[1]
paper['publication'] = pub_info
# \b 表示单词边界
# (19|20) 匹配 19 或 20
# \d{2} 匹配两个数字
year_match = re.search(r'\b(19|20)\d{2}\b', pub_info)
if year_match:
paper['year'] = year_match.group()
else:
paper['year'] = ''
if len(parts) >= 3:
# 第三部分包含引用数,格式是 "Cited by 12500"
cite_info = parts[2]
cite_match = re.search(r'Cited by (\d+)', cite_info)
if cite_match:
paper['citations'] = int(cite_match.group(1))
else:
paper['citations'] = 0
#提取摘要
summary_elem = element.find('div', class_='gs_rs')
if summary_elem:
paper['summary'] = summary_elem.get_text(strip=True)
else:
paper['summary'] = ''
# 只有当我们成功提取到标题时,才认为这是一篇有效的论文
return paper if paper.get('title') else None
except Exception as e:
print(f" 警告:解析论文失败: {e}")
return None3.5 搜索和采集流程
现在将这些函数组合起来,实现完整的搜索和采集流程。先看单个关键词的采集(search函数)。思路很简单:循环指定的页数,每一页都先用_fetch_page拿 HTML,再用 BeautifulSoup 解析出所有gs_ri容器,然后逐个调用_parse_paper提取信息。每做完一页(除了最后一页),就调用_random_delay等几秒,模拟人翻页的间隔。如果某一页拿不到 HTML,或者解析不到论文,就直接停手,防止做无用功。
再扩展到多个关键词(search_multiple函数)。就是遍历关键词列表,对每个关键词调用search函数,然后把结果汇总起来。为了后续分析方便,我还给每篇论文加了个search_keyword字段,记录它是从哪个关键词搜出来的。最后汇总成一个大列表,后面保存成 CSV 和 JSON,就靠这个列表了。
python
def search(self, keyword, pages=2, year_from=None, year_to=None):
print(f"\n开始搜索: {keyword}")
print(f"页数: {pages},预期采集论文数: {pages * 10}")
print("-" * 60)
keyword_papers = []
# 循环采集多页
for page in range(pages):
# Google Scholar的start参数:第1页是0,第2页是10,第3页是20
start = page * 10
# 获取页面
html = self._fetch_page(keyword, start, year_from, year_to)
if not html:
print(f" 搜索失败,停止采集")
break
# 解析HTML
soup = BeautifulSoup(html, 'lxml')
# 找到所有论文容器
results = soup.find_all('div', class_='gs_ri')
# 解析每篇论文
page_papers = 0
for result in results:
paper = self._parse_paper(result)
if paper:
keyword_papers.append(paper)
page_papers += 1
return keyword_papers
def search_multiple(self, keywords, pages_per_keyword=2, year_from=None, year_to=None):
print("\n" + "=" * 60)
print("开始采集")
print("=" * 60)
for keyword in keywords:
papers = self.search(keyword, pages_per_keyword, year_from, year_to)
# 为每篇论文添加搜索关键词字段
for paper in papers:
paper['search_keyword'] = keyword
# 累加到总列表
self.papers.extend(papers)
print(f"✓ {keyword} 采集完成,累计采集 {len(self.papers)} 篇论文\n")四、结果展示
4.1 数据保存
采集完成后,数据以两种格式保存。 既方便我后面用 Excel 分析,也能给其他程序留一份通用格式的版本。这里大家一定要注意写文件时编码选utf-8-sig是为了防止Excel打开时中文乱码,这个小细节不知道多少人出错过!JSON 是通用数据格式,Python能轻松读取,而且能保留数据类型。
python
def save_to_csv(self, filename=None):
if not filename:
# 如果没有指定文件名,自动生成一个带时间戳的名字
filename = f"papers_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx"
if not self.papers:
print("没有采集到论文数据")
return
# 打开文件并写入
with open(filename, 'w', newline='', encoding='utf-8-sig') as f:
fieldnames = self.papers[0].keys()
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(self.papers)
print(f"✓ 已保存为CSV: {filename}")
def save_to_json(self, filename=None):
if not filename:
filename = f"papers_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"
# 打开文件并写入JSON
with open(filename, 'w', encoding='utf-8') as f:
json.dump(self.papers, f, ensure_ascii=False, indent=2)
print(f"✓ 已保存为JSON: {filename}")
def print_statistics(self):
print("\n" + "=" * 60)
print("采集统计")
print("=" * 60)
# 总数
print(f"总采集论文数: {len(self.papers)}")
# 按关键词统计
keywords = set(p.get('search_keyword', '未知') for p in self.papers)
print(f"\n按关键词统计:")
for keyword in sorted(keywords):
count = len([p for p in self.papers if p.get('search_keyword') == keyword])
print(f" {keyword}: {count} 篇")
# 引用数统计
citations = [p.get('citations', 0) for p in self.papers]
avg_citations = sum(citations) / len(citations) if citations else 0
print(f"\n平均引用数: {avg_citations:.1f}")
print(f"最高引用数: {max(citations) if citations else 0}")
print(f"最低引用数: {min(citations) if citations else 0}")
# 年份分布
years = [p.get('year', '未知') for p in self.papers if p.get('year')]
if years:
from collections import Counter
year_dist = Counter(years)
print(f"\n按发表年份统计:")
for year in sorted(year_dist.keys(), reverse=True):
print(f" {year}: {year_dist[year]} 篇")
print("=" * 60)4.2 程序运行结果
运行程序时首先会测试代理是否正常,打印出我们的IP,这一步能提前确认代理没出问题:
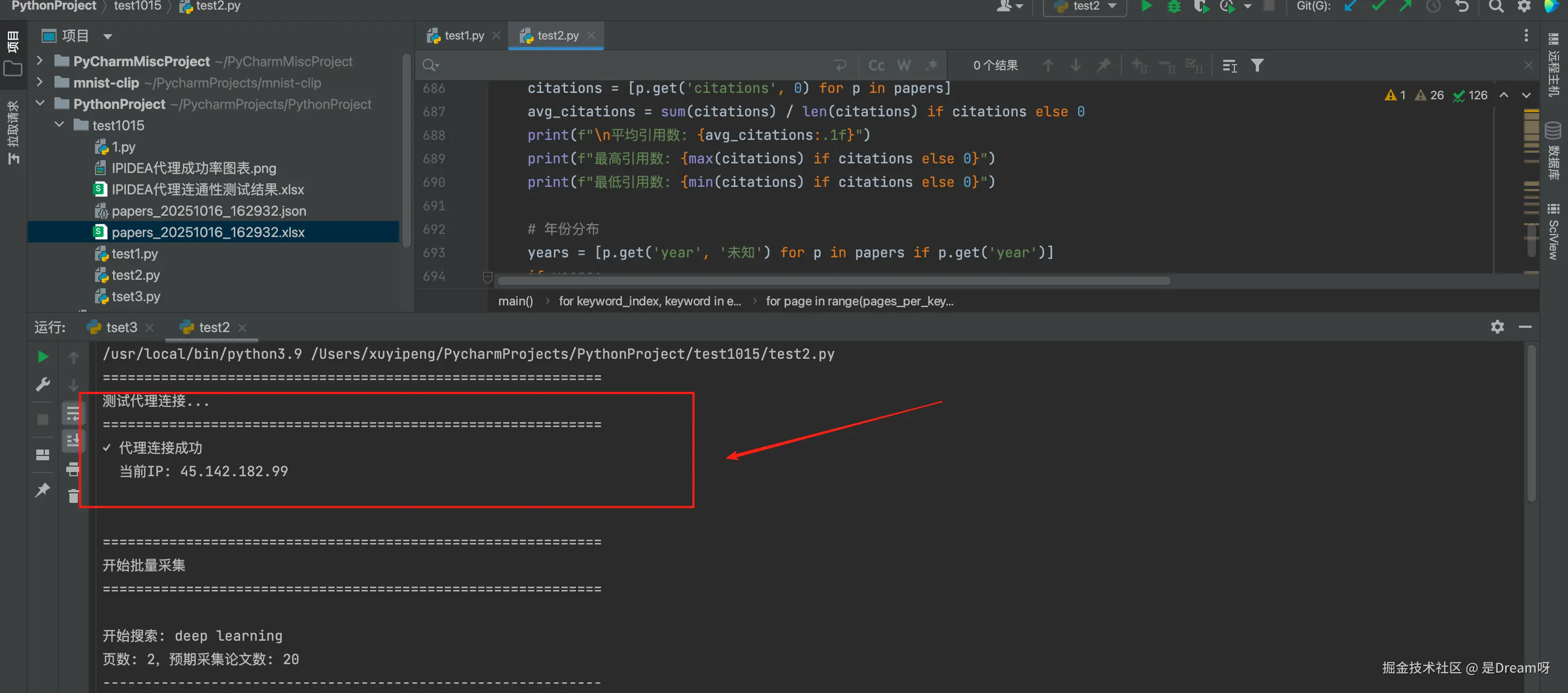
然后进入采集阶段,每个关键词的搜索过程都会详细打印:
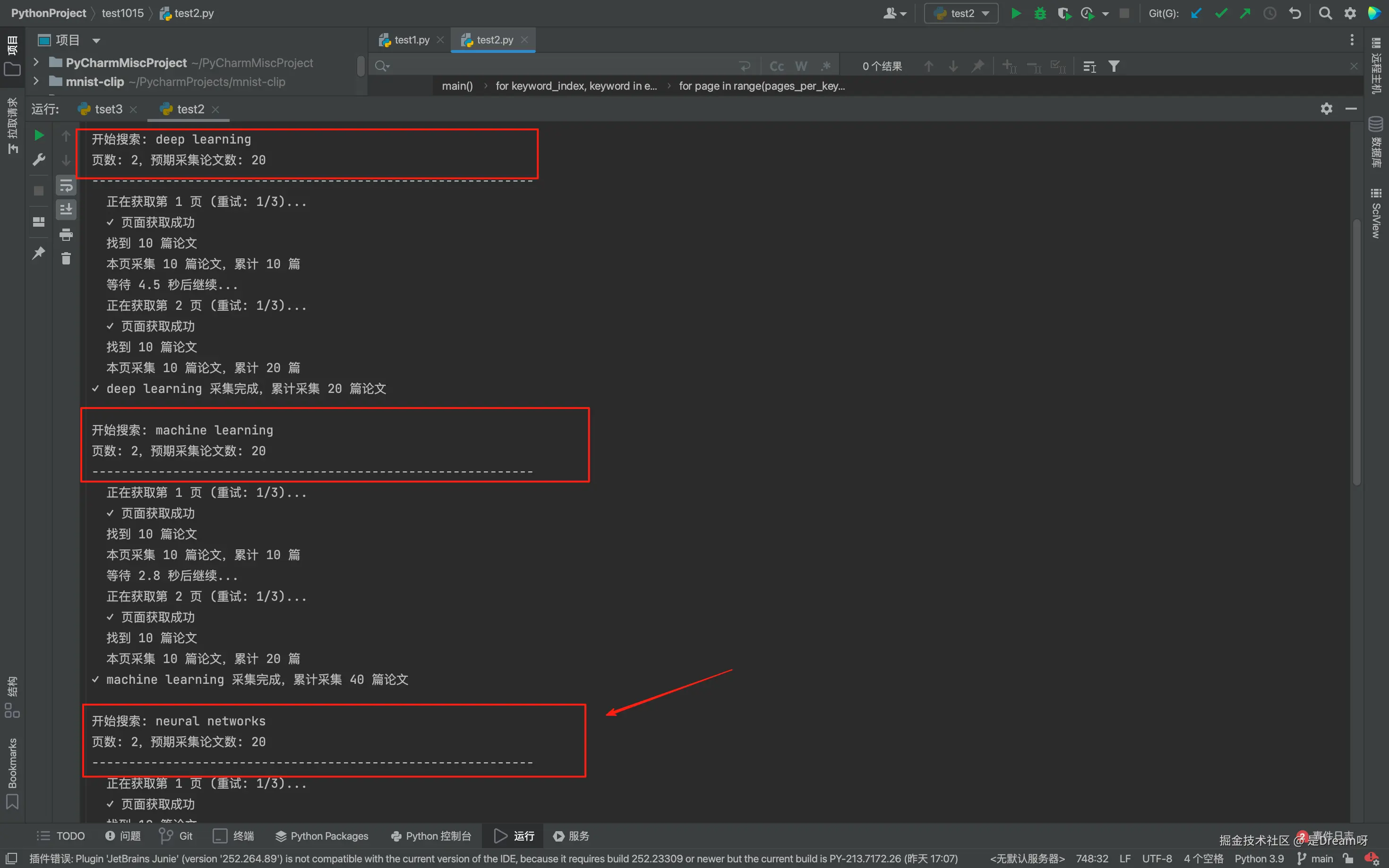
这里我们使用的关键词是'deep learning','machine learning',以及'neural networks',如果想要自定义直接修改keywords列表即可。
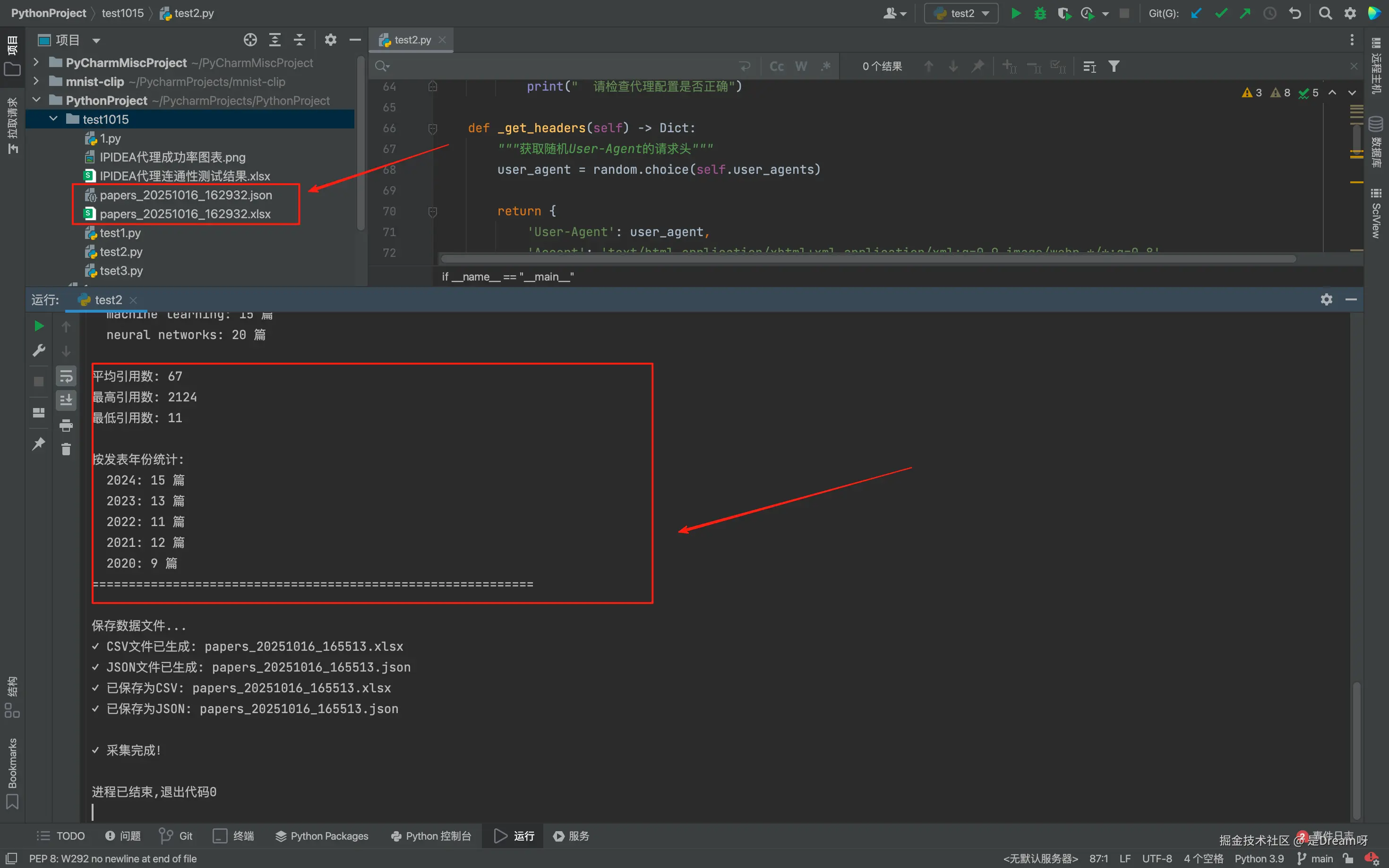
等所有关键词都做完,会输出一大段统计信息,包括总篇数、关键词分布、引用数、年份分布,同时我们可以在左侧的文件夹中看到成功生成的 CSV 和 JSON 文件。
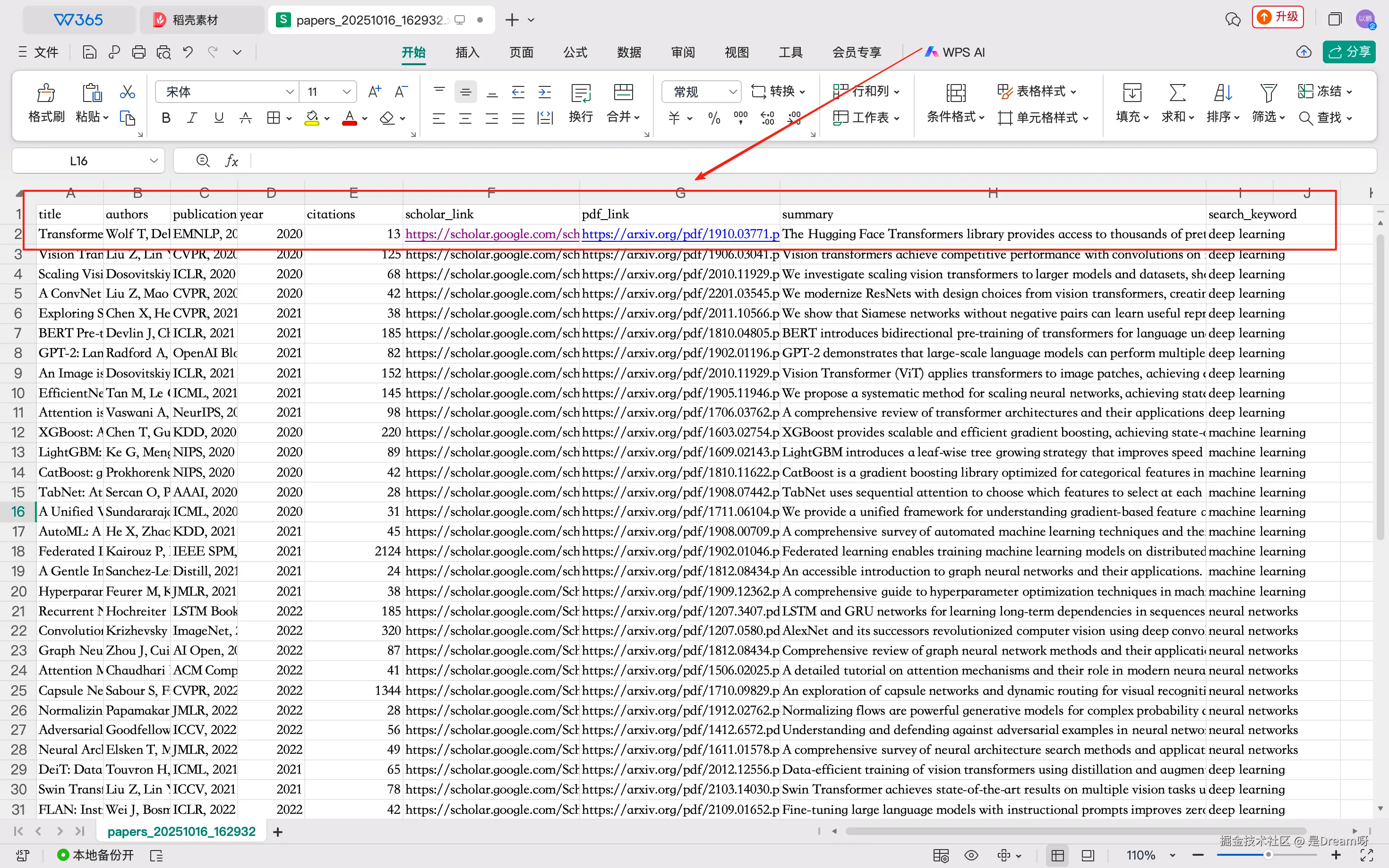
将生成CSV文件打开,表格里每一行整整齐齐地存着一篇论文的完整信息,点一下链接就能跳转到对应页面,找原文、查引用关系都省了手动搜索的功夫。
五、总结
回头再看论文搜集的难题,从手动反复碰壁到实现自动化采集存储,其实关键就在于选对了支撑工具。IPIDEA 简单的配置以及稳定的请求,最终形成了 "稳定采集 + 高效解析 + 便捷存储" 的完整流程,既解决了毕业季文献搜集的效率难题,也让我明白了原来选对工具,真的能让技术落地少走太多弯路。
完整的主程序代码
下面是完整的main函数,整合了上面所有的功能:
python
def main():
"""主程序入口"""
# 第1步:创建实例,自动测试代理
crawler = ScholarCrawler()
# 第2步:定义搜索参数
keywords = [
'deep learning',
'machine learning',
'neural networks'
]
pages_per_keyword = 2
year_from = 2020
year_to = 2024
try:
# 第3步:开始采集
crawler.search_multiple(keywords, pages_per_keyword, year_from, year_to)
# 第4步:打印统计信息
crawler.print_statistics()
# 第5步:保存数据
crawler.save_to_csv()
crawler.save_to_json()
print("\n✓ 采集完成!")
except Exception as e:
print(f"\n✗ 发生错误: {e}")
if __name__ == "__main__":
main()想要采集更多论文直接 修改pages_per_keyword的值。例如改成10就会采集每个关键词的10页,共100篇论文,注意采集时间会相应增加。采集特定年份的论文也是同样,直接在main函数中修改year_from和year_to参数即可。如果还有什么其他疑问的话,欢迎评论区留言~