一、进程和线程的相关概念
1、进程是操作系统进行资源分配的基本单位。
- 资源分配的基本单位
- 当你运行一个程序时,操作系统就会为它启动一个进程。
- 操作系统会给这个进程分配一块独立的内存空间、CPU时间片、文件句柄等资源。
- 独立性
- 进程之间是相互独立的。
- 你打开的每个进程,它们各自拥有自己的内存空间,互不干扰。
- 重量级
- 启动一个新进程,需要操作系统为它分配一整套独立的资源,所以开销比较大,过程相对较慢。
2、线程是CPU调度的基本单位,是进程内的一个执行单元。
- CPU调度的基本单位
- CPU真正执行计算任务时,是识别到线程这个级别的。
- 进程内的一个执行单元
- 线程是进程的一部分,不能独立存在
- 资源共享
- 共享所在进程的资源,线程间共享资源
- 轻量级
- 创建和销毁的开销小
3、对比表格
|----------|--------------------|--------------------|
| 特性 | 进程 | 线程 |
| 定义 | 资源分配的基本单位 | CPU调度的基本单位 |
| 包含关系 | 一个进程可以包含一个或多个线程 | 线程是进程的一部分,不能独立存在 |
| 资源 | 拥有独立的内存和系统资源,进程间隔离 | 共享所在进程的资源,线程间共享 |
| 开销 | 创建和销毁的开销大 (重量级) | 创建和销毁的开销小 (轻量级) |
| 稳定性 | 一个进程崩溃不影响其他进程 | 一个线程崩溃会导致整个进程崩溃 |
| 通信 | 进程间通信比较复杂,需要借助特殊手段 | 线程间通信简单,可以直接读写共享数据 |
4、总结
- 进程是正在运行程序的实例,进程中包含了线程,每个线程执行不同的任务。
- 不同的进程使用不同的内存空间,在当前进程下的所有线程可以共享内存空间。
- 线程更轻量,线程上下文切换成本一般上要比进程上下文切换低
- 上下文切换是指 CPU从一个正在运行的任务(进程或线程)切换到另一个任务,并在切换时保存当前任务的状态,加载新任务的状态,以便之后能恢复执行。
- 进程切换因为需要切换独立的内存空间等大量系统资源,所以是重量级的,开销大。
- 线程切换因为它们在同一个进程内,共享内存空间,所以是轻量级的,开销小,。
二、线程个数设置
1、CPU密集型------ "烧脑型"
解释: 系统的瓶颈在于 CPU处理器的计算能力。
-
特点: 程序需要进行大量的逻辑判断、复杂的数学运算或数据处理。CPU 几乎一直处于 100% 的满负荷工作状态,没有时间休息。
-
瓶颈: 只要 CPU 更快,程序就跑得更快。硬盘和网络通常都在等 CPU 算完。
-
常见场景:
-
高清视频解码/转码。
-
加密/解密数据。
-
3D 图形渲染。
-
机器学习的模型训练。
-
挖矿。
-
-
优化策略:
-
换更强的 CPU。
-
多进程:因为一个 CPU 核心忙不过来,就利用多核 CPU 同时算。
-
-
**线程数推荐公式:**线程数=N+1(N 为 CPU 逻辑核心数)
-
为什么要 +1?
-
理论上,如果有N个核心,跑N个线程就能把 CPU 吃满。
-
设置+1是为了防备偶尔发生的缺页中断或其他系统层面的阻塞。当某个线程因为内存页缺失稍微暂停一下时,多出来的那个线程可以立刻补位,保证 CPU 不休息。
-
**切忌:**不要开几十个或上百个线程。因为 CPU 只有N个坑位,线程太多会导致 CPU 频繁在不同线程间切换。这种切换是需要消耗资源的,结果就是调度的时间比干活的时间还长,效率反而下降。
-
2、IO密集型------ "等待型"
核心意思: 系统的瓶颈在于 I/O,即数据的读取和写入,包括磁盘读写、网络传输等。
-
特点: CPU 实际上很闲,它大部分时间都在等待数据从硬盘读出来,或者等待数据从网络上传过来。CPU 的占用率通常较低,但任务耗时很长。
-
瓶颈: 只要硬盘读写更快、网速更快,程序就跑得更快。CPU 计算能力再强也没用,因为它得等数据。
-
**常见场景:**数据库操作,频繁读写数据。
-
爬虫程序,等待网页下载。
-
文件备份、复制大文件。
-
-
优化策略:
-
多线程或协程: 既然 CPU 也是闲着,不如在等待 A 任务数据的时候,切换去处理 B 任务。
-
**升级硬件:**换固态硬盘,增加内存,提升网络带宽。
-
-
线程数设置核心原则:线程数 > CPU 核心数
-
**推荐公式(经验值):**线程数=2N(或者更多,取决于 IO 等待时间)(N 为 CPU 逻辑核心数)
-
科学计算公式(最佳理论值):
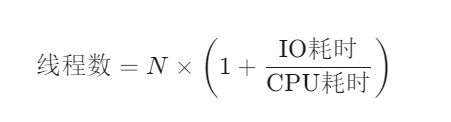
-
原理解析:
-
IO 密集型任务的大部分时间都在等,比如等数据库返回、等网页下载。
-
假设一个任务总共耗时 100ms,其中 CPU 计算只要 10ms,等待 IO 需要 90ms。
-
这意味着 CPU 有 90% 的时间是空闲的。为了把这段空闲利用起来,你需要在一个线程等待时,让 CPU 去处理其他线程。
-
套用公式:N×(1+90/10)=10N。如果你是 4 核 CPU,理论上可以开 40 个线程。
-
-
实际操作建议:
-
因为很难精确计算IO耗时/CPU耗时的比例,通常做法是:
-
起步设置: 2N(N 为 CPU 逻辑核心数)。
-
高并发场景: 如果是爬虫或高并发 Web 服务,IO 等待极长,线程数可以设得很大,比如 50、100 甚至更多。
-
压测调整: 必须通过压力测试来观察。不断增加线程数,直到 CPU 利用率达到 80%~90% 左右,就是最佳值。
-
3、总结对比
|-------------|----------------|---------------|
| 特性 | CPU密集型 (计算密集型) | IO密集型 |
| 主要动作 | 算算算 | 等等通 |
| 瓶颈 | CPU 运算速度 | 磁盘/内存/网络速度 |
| CPU 占用率 | 极高 (往往接近 100%) | 较低 (大部分时间在空转) |
| 典型例子 | 视频压缩、挖矿、AI训练 | 网站后台、爬虫、数据库 |
| 编程首选 | 多进程 (利用多核) | 多线程 / 异步IO |
三、虚拟线程
1、定义
虚拟线程(Virtual Threads)是 Java 语言近年来最重大的更新之一,正式在 Java 21 中成为标准功能(Project Loom 的核心产物)。它是一种由 JVM 管理的轻量级线程,它不直接与操作系统的内核线程一一对应。我们可以创建数百万个虚拟线程,而系统开销却很小。它的出现主要是为了解决高并发场景下"传统线程昂贵"的问题。
2、与传统的平台线程对比
|----------|-------------------|----------------------------|
| 特性 | 虚拟线程 | 平台线程 |
| 管理者 | Java 虚拟机 | 操作系统 |
| 本质 | JVM 管理的轻量级结构 | 操作系统内核线程的薄包装 |
| 资源占用 | 非常小,每个线程约几百字节到几KB | 较大,每个线程需要分配较大的栈内存(通常为MB级别) |
| 创建成本 | 极低,可以大量、快速地创建和销毁 | 较高,受限于系统资源,数量有限 |
| 调度方式 | JVM 内部的调度器负责调度 | 操作系统的调度器负责调度 |
| 适用场景 | I/O 密集型任务和高并发场景 | CPU 密集型任务 |
3、适用场景
-
高并发 I/O 密集型应用:
- 这是虚拟线程最典型的应用场景,例如处理大量并发请求的 Web 服务器、微服务网关、数据库连接代理等。一般虚拟线程的引入就是为了解决I/O密集型任务无法确定设置多少个线程数的问题。
-
大量的并发任务:
- 当需要同时处理大量生命周期较短的任务时,例如并行调用多个下游服务。
-
采用一个请求一个线程模型的应用:
- 主流的 Java Web 框架(如 Spring MVC/Tomcat)天然适合与虚拟线程结合,只需少量配置改动即可获得巨大性能提升。
4. 局限性与注意事项
-
不适用于 CPU 密集型任务: 对于需要长时间进行大量计算的任务,虚拟线程并不能带来性能提升,因为它们始终需要占用 CPU 资源。这种场景下,平台线程仍然是更好的选择。
-
synchronized 关键字的限制: 当虚拟线程运行在 synchronized 修饰的代码块或方法时,它可能会被"钉"在载体线程上,导致载体线程被阻塞而无法被释放。在虚拟线程中,推荐使用 java.util.concurrent.locks.ReentrantLock 来替代 synchronized。
-
避免线程池化 : 虚拟线程的创建成本极低,因此不需要像平台线程那样进行池化管理。需要时直接创建,用完即可丢弃。
-
JNI 调用: 当调用本地方法时,如果本地代码阻塞,同样会阻塞载体线程。
-
ThreadLocal 的使用: 由于虚拟线程数量可能非常庞大,过度使用 ThreadLocal 可能会导致内存消耗问题,需要谨慎评估。
四、总结
本文系统性地描绘了一条从计算机基础到现代并发编程前沿的演进路线。它始于对进程 (资源分配单元)与平台线程 (CPU调度单元)核心概念的清晰界定,随即切入传统并发模型中最棘手的现实问题:如何为不同类型的任务(CPU密集型 vs. IO密集型)合理配置线程数,并揭示了平台线程因其"昂贵"的本质而导致的并发瓶颈。最终,文章介绍了JDK21后的一个重大改变虚拟线程------它通过由JVM管理的、几乎无成本的轻量级特性,巧妙地解决了IO密集型场景下的资源困境,让开发者能以最直观的同步代码风格,轻松构建起以往需要复杂异步设计才能实现的超大规模高并发系统。