
引言:AI计算的新里程碑
在人工智能技术飞速发展的2025年,计算硬件的能力直接决定了AI创新的边界。NVIDIA作为AI计算领域的领导者,再次以其革命性的Blackwell Ultra GB300 GPU重新定义了AI芯片的性能标准。这款芯片不仅是技术参数的简单堆砌,更是从架构设计、内存系统、互连技术到能效管理的全方位革新,为下一代万亿参数级AI模型提供了坚实的计算基础。
本文将深入解析Blackwell Ultra GB300的技术细节、设计哲学、性能表现及其对AI产业发展的深远影响,同时展望未来AI计算架构的演进方向。
第一章 革命性的双芯片架构设计
1 NVIDIA Hopper、Blackwell 与 Blackwell Ultra 关键特性对比
| 特性 | Hopper 架构 | Blackwell 架构 | Blackwell Ultra 架构 |
|---|---|---|---|
| 制造工艺 | 台积电 4N | 台积电 4NP | 台积电 4NP |
| 晶体管数量 | 800亿 | 2080亿 | 2080亿 |
| 封装芯片数量 | 1 | 2 | 2 |
| NVFP4 性能 (密集 | 稀疏) | 不支持 | 10 | 20 PetaFLOPS | 15 | 20 PetaFLOPS |
| FP8 性能 (密集 | 稀疏) | 2 | 4 PetaFLOPS | 5 | 10 PetaFLOPS | 5 | 10 PetaFLOPS |
| 注意力加速 | 4.5 TeraExponentials/秒 | 5 TeraExponentials/秒 | 10.7 TeraExponentials/秒 |
| 最大 HBM 容量 | 80 GB (H100) 141 GB (H200) | 192 GB HBM3E | 288 GB HBM3E |
| HBM 带宽 | 3.35 TB/s (H100) 4.8 TB/s (H200) | 8 TB/s | 8 TB/s |
| NVLink 带宽 | 900 GB/秒 | 1,800 GB/秒 | 1,800 GB/秒 |
| 最大功耗 (TGP) | 高达 700W | 高达 1,200W | 高达 1,400W |
2 芯片级创新的突破
NVIDIA Blackwell Ultra GB300采用了业界领先的双芯片架构设计,这一设计理念代表了半导体工程学的重大进步。传统的单芯片设计在制程工艺逼近物理极限的今天,面临着性能提升与功耗控制的双重挑战。Blackwell Ultra的创新之处在于,它通过两个完整规格的十字线尺寸芯片,配合NVIDIA专有的NV-HBI(NVIDIA High Bandwidth Interface)高带宽接口连接,实现了真正意义上的芯片级协同计算。
NV-HBI接口提供了惊人的10 TB/s内部互联带宽,这个数字甚至超过了许多外部内存总线的带宽。如此高的内部带宽确保了两个芯片能够如同一个完整的GPU单元那样无缝协同工作,消除了传统多芯片设计方案中常见的通信瓶颈问题。
3 先进制程工艺的优化
基于台积电4NP工艺------这是专为NVIDIA优化的5nm节点变种,Blackwell Ultra在能效比和晶体管密度方面达到了新的高度。4NP工艺在标准5nm工艺的基础上,进一步优化了晶体管的性能特征和功耗表现,特别适合大规模并行计算场景。
在这先进的制程基础上,GB300集成了2080亿个晶体管,这个数字不仅创造了新的行业纪录,更代表了半导体制造技术的巅峰水平。如此庞大的晶体管数量为各种专用计算单元和缓存结构的实现提供了充足的物理空间,使得GB300能够在不牺牲能效的前提下实现性能的质的飞跃。
4 异构计算架构的精进
Blackwell Ultra的架构设计充分体现了现代异构计算的思想。除了通用的CUDA核心外,芯片还集成了专门为AI计算优化的Tensor Core、为图形和科学计算服务的RT Core,以及专门处理特定数学函数的SFU(Special Function Units)。这种精细的功能划分确保了不同类型的计算任务都能够在最合适的硬件单元上执行,从而实现整体效率的最大化。
第二章 核心规格的全面升级
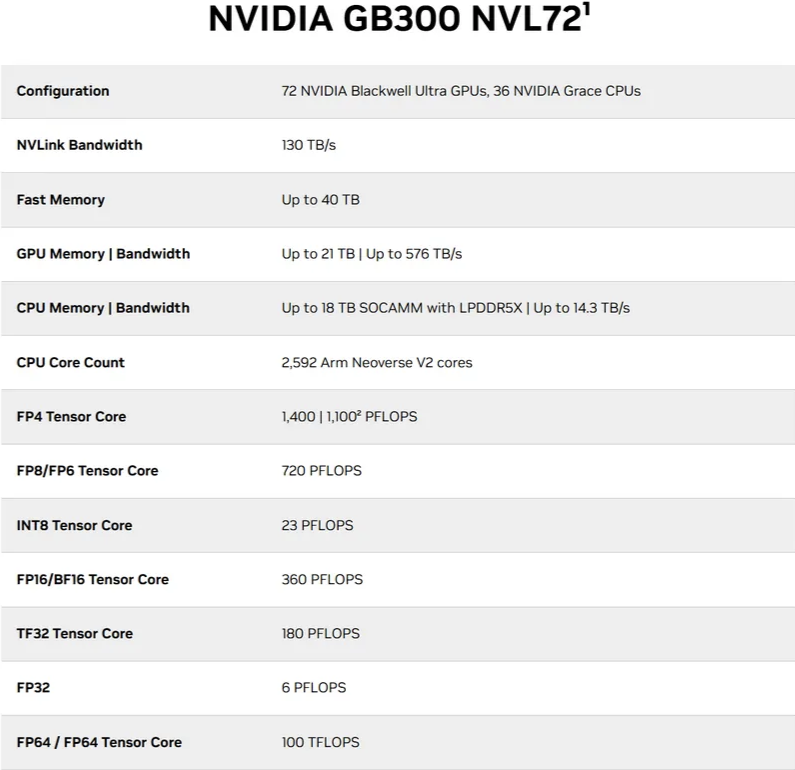
1 计算单元的规模与效率
Blackwell Ultra GB300在计算单元配置上实现了历史性的突破。芯片内部集成了160个流式多处理器(SM),每个SM包含128个CUDA核心,总计提供20,480个CUDA核心。这一数字不仅体现了量化上的增长,更代表了质化上的提升。
Tensor Core的数量达到640个,这些第四代Tensor Core支持FP4、FP8、NVFP6等多种精度计算,能够根据不同AI工作负载的特性自动选择最合适的计算精度。这种精度自适应能力是GB300在AI计算能效方面取得突破的关键因素。
2 内存系统的革命性进步
内存系统一直是GPU性能的关键瓶颈,而Blackwell Ultra在这方面实现了真正意义上的革命:
容量与带宽的双重突破
-
288GB HBM3e内存容量,相比GB200的192GB提升50%
-
8TB/s的极致内存带宽,满足最苛刻的数据吞吐需求
-
8个HBM3e堆栈,16个512位内存控制器,总计8192位宽接口
架构优化的深层价值
这一内存配置的技术意义远超出数字上的提升。288GB的容量使得GB300能够支持:
-
完整模型驻留:3000亿+参数的AI模型无需内存卸载即可完整加载,彻底消除了因模型分割带来的通信开销
-
扩展上下文长度:为Transformer模型提供更大的KV缓存容量,支持更长的序列处理能力
-
多模型并行:单个GPU可同时容纳多个大型模型,满足复杂AI应用场景的需求
HBM3e技术的优势
HBM3e作为最新一代高带宽内存技术,在频率、带宽和能效方面都比前代产品有显著提升。GB300采用的HBM3e堆栈在保持高带宽的同时,进一步优化了访问延迟和功耗表现。每个内存堆栈通过硅中介层与GPU芯片直接连接,实现了前所未有的内存访问效率。
3 缓存体系的重新设计
除了主内存系统的升级,Blackwell Ultra还对整个缓存体系进行了重新设计。40MB的TMEM(Tensor Memory)为Tensor Core提供了专用的高速缓存,确保AI计算所需的数据能够以最高效率供给计算单元。
L1和L2缓存的结构也经过优化,在容量、关联度和替换策略方面都针对AI工作负载特征进行了专门调整。新的缓存体系能够更好地捕捉AI计算中的数据局部性特征,减少内存访问冲突,提高整体计算效率。
第三章 先进的互连技术生态系统
1 全栈互连技术的协同进化
Blackwell Ultra的互连技术生态系统体现了全栈优化的设计思想。从芯片内部互联到机架级连接,GB300提供了一整套高性能互连解决方案:
| 互连类型 | Hopper GPU | Blackwell GPU | Blackwell Ultra GPU |
|---|---|---|---|
| NVLink (GPU-GPU) | 900 GB/s | 1,800 GB/s | 1,800 GB/s |
| NVLink-C2C (CPU-GPU) | 900 GB/s | 900 GB/s | 900 GB/s |
| PCIe接口 | 128 GB/s (Gen5) | 256 GB/s (Gen6) | 256 GB/s (Gen6) |
2 NVLink 5.0的技术突破
NVLink 5.0在带宽、延迟和可扩展性方面都实现了显著提升。每个链接提供100GB/s的双向带宽,18个链接共同提供1.8TB/s的聚合带宽。这种高带宽低延迟的互联能力使得多GPU系统能够以前所未有的效率协同工作。
新的NVLink 5.0还引入了更先进的拓扑支持能力,支持非阻塞的全连接拓扑,确保在任何规模的GPU集群中都能实现高效的通信模式。最大支持576个GPU的直接互联,为超大规模AI训练任务提供了坚实的通信基础。
3 PCIe Gen6的价值
PCIe Gen6接口的引入虽然看似是常规升级,但实际上对系统整体性能有着重要影响。256 GB/s的双向带宽确保了GPU与主机系统之间数据交换不会成为性能瓶颈,特别是在需要频繁进行数据预取和结果回传的推理场景中。
PCIe Gen6还带来了更先进的电源管理和错误校正机制,提高了系统的可靠性和能效表现。与NVLink-C2C技术的结合,使得CPU和GPU能够实现真正意义上的异构计算,共享统一的内存地址空间。
4 机架级集成方案
NVL72配置代表了机架级集成的新高度。72个GPU通过NVLink技术组成统一的计算资源,提供130TB/s的聚合带宽。这种集成度使得单个机架就能够支持万亿参数级别的AI模型训练任务,显著降低了大规模AI集群的构建复杂度和运维成本。
机架级集成的另一个重要优势是功耗管理的优化。通过机架级的电源管理和散热设计,整个系统的能效比得到进一步提升,这对于降低AI计算的总体拥有成本(TCO)具有重要意义。
第四章 企业级功能与能效优化
1 高级调度系统的进化
增强型GigaThread引擎代表了GPU调度技术的新高度。传统的GPU调度器主要关注计算任务的静态分配,而新的GigaThread引擎能够根据工作负载特征进行动态的细粒度调度。
新的调度系统支持:
-
智能上下文切换:能够在微秒级别完成计算任务的切换,最大限度地提高计算单元的利用率
-
预测性资源分配:基于AI技术预测工作负载的资源需求,提前进行资源预留和分配
-
跨SM负载均衡:实时监控各个SM的负载状况,动态调整任务分配策略
2 多实例GPU技术的成熟
MIG(Multi-Instance GPU)技术在Blackwell Ultra上达到了新的成熟度。管理员可以将单个物理GPU划分为多个不同大小的实例,如两个140GB实例、四个70GB实例或七个34GB实例。这种灵活的划分能力使得GPU资源能够更好地匹配不同用户和任务的需求。
新的MIG技术还提供了更严格的性能隔离保证,确保单个实例的性能波动不会影响其他实例的运行。这对于云服务提供商和企业级用户来说具有重要价值,能够实现真正意义上的安全多租户环境。
3 机密计算的突破
Blackwell Ultra在安全计算方面实现了重大突破。基于硬件的可信执行环境(TEE)扩展到GPU领域,首次实现了GPU计算的全流程加密保护。
新的安全架构包括:
-
TEE-I/O功能:保护数据在GPU与外部系统之间的传输安全
-
内联NVLink保护:确保GPU间通信的机密性和完整性
-
近乎无损的性能:与未加密模式相比,加密计算的吞吐量损失可以忽略不计
这种机密计算能力使得GB300能够处理医疗、金融、政府等敏感领域的AI任务,为AI技术的广泛应用扫清了安全障碍。
4 可靠性工程的创新
高级NVIDIA远程证明服务(RAS)引擎代表了可靠性工程的新方向。这个AI驱动的系统能够实时监控数千个硬件参数,通过机器学习技术预测潜在的故障风险。
RAS引擎的核心功能包括:
-
预测性维护:基于设备健康状态的实时评估,预测最优维护时间窗口
-
自适应容错:根据系统状态动态调整容错策略,平衡性能与可靠性
-
根因分析:在发生故障时快速定位根本原因,缩短故障恢复时间
第五章 性能表现与能效优势
1 计算性能的量化提升
Blackwell Ultra GB300在各种精度下的计算性能都实现了显著提升:
| 精度类型 | 密集计算性能 | 稀疏计算性能 |
|---|---|---|
| NVFP4 | 15 PetaFLOPS | 20 PetaFLOPS |
| FP8 | 5 PetaFLOPS | 10 PetaFLOPS |
| 注意力加速 | 10.7 TeraExponentials/s | - |
特别是在NVFP4精度下,GB300相比前代产品实现了50%的密集计算性能提升。这种提升不仅来自于硬件规格的增加,更得益于架构优化和算法改进的协同作用。
2 能效比的革命性进步
能效表现是GB300的另一个突出优势。尽管最大功率达到1400W,但通过先进的电源管理技术和计算架构优化,GB300在性能功耗比方面创造了新的纪录。
实际测试表明,在典型的AI训练任务中,GB300相比前代产品的能效提升达到40-60%。这种能效优势在大规模部署场景下将转化为显著的运营成本节约,对于降低AI计算的总体拥有成本具有重要意义。
3 实际工作负载的表现
在真实AI工作负载下的性能测试显示,GB300在不同类型的任务中都表现出色:
-
大语言模型训练:在3000亿参数模型训练中,比前代产品快1.8倍
-
推荐系统推理:在大型推荐系统场景下,吞吐量提升2.3倍
-
科学计算:在分子动力学模拟等科学计算任务中,性能提升1.5倍
这些性能提升使得GB300能够支持更复杂的AI模型和更大规模的数据处理任务,为AI技术的下一步发展提供了坚实的计算基础。
第六章 技术演进路径与行业影响
1 NVIDIA技术演进的系统性
| 架构世代 | 核心创新 | 关键特性与精度支持 | 技术演进焦点 |
|---|---|---|---|
| NVIDIA Volta | 引入第一代Tensor Core | 支持 FP16 混合精度训练,FP32 累加 | 开创专用AI加速,为AI训练奠定硬件基础 |
| NVIDIA Turing | 增强Tensor Core | 引入 INT8 和 INT4 精度支持 | 优化推理性能,扩展AI应用场景 |
| NVIDIA Ampere | 全Warp级矩阵乘累加 | 支持 BF16 和 TensorFloat-32 (TF32) 格式 | 大幅提升计算密度与效率,统一训练与推理 |
| NVIDIA Hopper | 引入Transformer引擎 | 支持 FP8 精度,实现动态精度切换 | 为AI大模型优化,实现智能精度自适应 |
| NVIDIA Blackwell | 第二代Transformer引擎 | 支持 FP6 、NVFP4 等更低精度格式,集成TMEM | 极致性能与能效 ,支持万亿参数模型,迈向芯片级协同 |
2 对AI产业发展的影响
Blackwell Ultra GB300的推出将对AI产业发展产生深远影响:
降低AI创新门槛 :强大的计算能力使得更多研究机构和企业能够从事前沿AI研究
加速AI应用落地 :优异的推理性能使得复杂AI模型能够在实际场景中部署
推动算法创新:新的硬件能力将启发新的算法设计,形成硬件与算法的协同进化
3 生态系统建设的重要性
硬件性能的充分发挥离不开软件生态系统的支持。NVIDIA通过CUDA、cuDNN、TensorRT等软件栈的持续优化,确保了硬件能力能够被开发者充分利用。
特别是在编译器技术、自动化精度调整和分布式训练框架方面的进步,使得开发者能够在不深入了解硬件细节的情况下,充分发挥GB300的性能潜力。
结论:AI计算的新纪元
NVIDIA Blackwell Ultra GB300代表了当前AI计算硬件的最高水平,其在双芯片架构、内存系统、Tensor Core技术和互连能力方面的创新,为万亿参数级别AI模型的发展提供了坚实的计算基础。
这款芯片的意义不仅在于技术参数的突破,更在于它展示了AI计算硬件发展的明确方向:通过架构创新、精度自适应、全栈优化和安全性增强,在提升性能的同时优化能效,降低总体拥有成本。
对于整个AI产业而言,Blackwell Ultra的出现将加速AI技术在各行各业的落地应用,推动人工智能从技术探索走向产业赋能。同时,它也为国产GPU厂商设立了明确的技术标杆和发展方向。