摘要:
为了设计快速的神经网络,许多工作一直专注于减少浮点运算(Flops)的数量。然而,由于频繁内存访问,对FLOPs的减少并不一定会导致类似水平的延迟减少 。 提出了一种新的部分卷积算法(PConv) ,可以同时减少冗余计算和内存访问。 在PConv的基础上,进一步提出了FasterNet,这是一种新的神经网络家族,在广泛的设备上获得了比其他网络更高的运行速度,而不会影响各种视觉任务的准确性。
Introduction
设计具有降低计算复杂性的成本效益高的快速神经网络,主要衡量标准是浮点运算(FLOPs)的数量。MobileNets、ShuffleNets和GhostNet等网络利用深度卷积(DWConv)和/或组卷积(GConv)来提取空间特征。然而,在减少FLOPs的过程中,这些算子往往伴随着内存访问的增加。MicroNet进一步分解和稀疏化网络,将其FLOPs推至极低水平。尽管在FLOPs上有所改进,但这种方法导致了低效的碎片化计算。此外,上述网络通常伴随着额外的数据操作,如连接、混洗和池化,这些操作在小型模型中的运行时间往往显著。传统思路只追求降低 FLOPs(减少总计算量),但忽略了 FLOPS(硬件实际运算效率)。
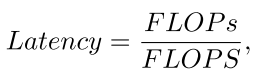
Method
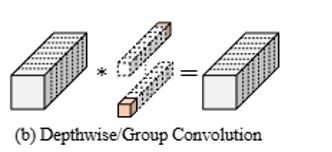

对Resnet的某一特征图不同通道的观察发现,如下图,通道间存在着巨大的冗余,通过利用特征图中的冗余可以进一步优化成本,**仅对输入通道的一部分应用常规卷积以提取空间特征,而其余通道保持不变。为了连续或常规的内存访问,将前或后连续的通道视为整个特征图的代表进行计算。**在不失一般性的情况下,考虑输入和输出特征图具有相同的通道数。

Pconv的FLOPs和内存访问次数如下图:
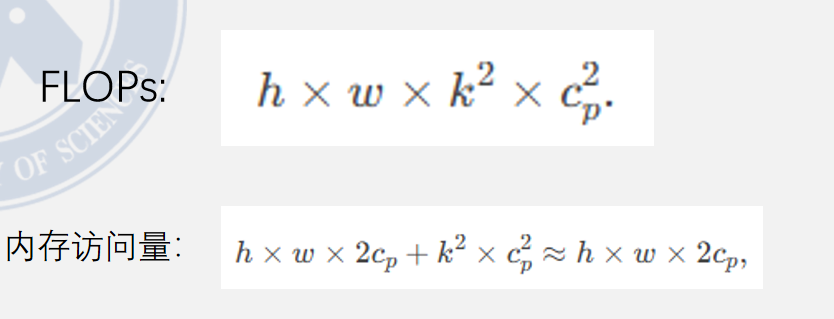 为了充分有效地利用来自所有通道的信息,进一步将逐点卷积(PWConv)附加到的PConv。
为了充分有效地利用来自所有通道的信息,进一步将逐点卷积(PWConv)附加到的PConv。
基于新颖的PConv和现成的PWConv作为主要构建算子,进一步提出了FasterNet,这是一个新的神经网络家族,它在许多视觉任务中运行速度快且高效。旨在保持架构尽可能简单,没有花哨的设计,以使其在硬件上友好。
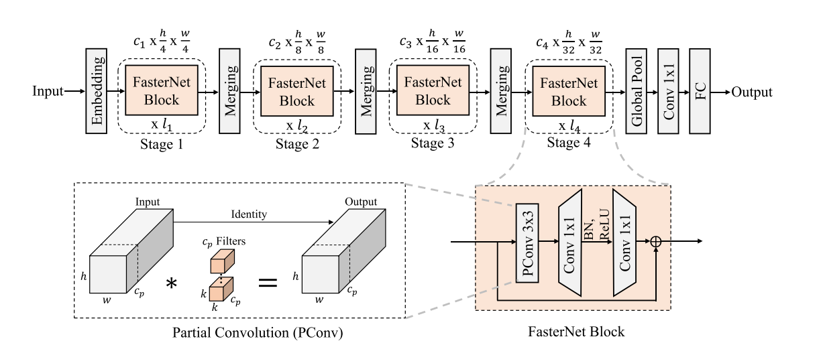
有四个层次阶段,每个阶段之前都有一个嵌入层(一个步幅为4的常规Conv 4×4)或一个合并层(一个步幅为2的常规Conv 2×2),用于空间下采样和通道数扩展。每个阶段都有一堆FasterNet块。
Experiments
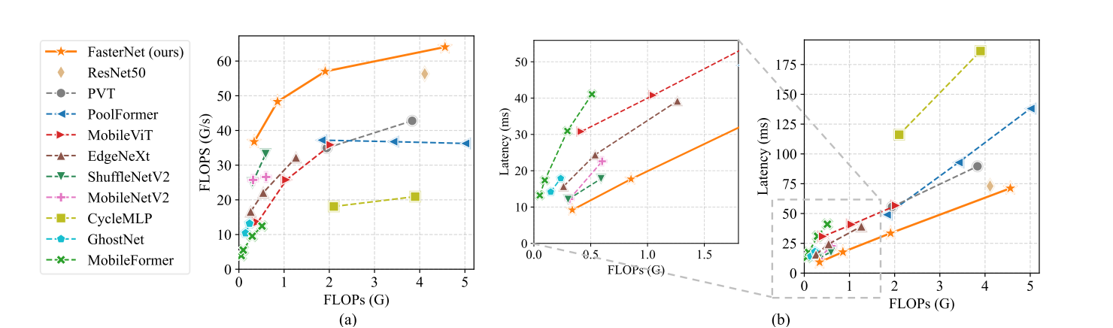
PConv总体上是一个具有高FLOPS和减少FLOPs的有吸引力的选择。它的FLOPs仅为常规Conv的1/16,并且在GPU、CPU和ARM上分别比DWConv高14倍、6.5倍和22.7倍的FLOPS。常规Conv具有最高的FLOPS,因为它已经经过多年的优化。然而,它的总FLOPs和延迟/吞吐量是过高的。GConv和DWConv尽管显著减少了FLOPs,但FLOPS却急剧下降。此外,它们倾向于增加通道数以补偿性能下降,然而,这增加了它们的延迟。
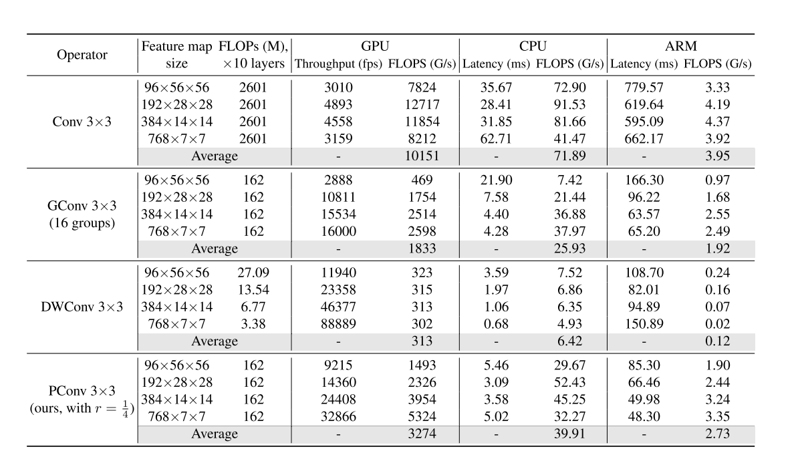
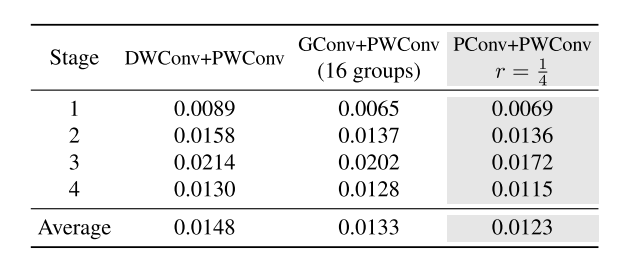
PConv + PWConv实现了最低的测试损失,这意味着它们更好地近似了常规Conv的特征转换。结果还表明,仅从特征图的一部分捕获空间特征是足够且高效的。PConv显示出在设计快速有效神经网络方面成为新选择的巨大潜力。
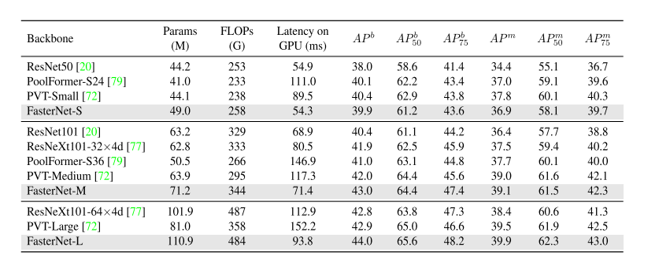
为了进一步评估FasterNet的泛化能力,在COCO数据集上进行了目标检测和实例分割实验。使用ImageNet预训练的FasterNet作为骨干,Mask R-CNN作为检测器。简单地遵循PoolFormer并采用AdamW优化器、1×训练计划(12个epoch)、批量大小为16以及其他训练设置,无需进一步的超参数调整。