1 -> 前言
在国家信创战略的浪潮下,政务系统国产化改造已成为构建自主可控数字政府的"必答题"。电子证照系统作为"一网通办"的核心基石,其改造之路却常因两大技术难题而步履维艰:"文档-关系型数据库架构适配" 与 "高并发场景承载"。福建某地市的成功实践,为我们提供了一个极具参考价值的破局样本。
2 -> 核心挑战:国产化道路上的"三座大山"
2.1 -> 数据架构适配断层
问题根源:电子证照数据(如元数据、结构化信息、非结构化附件)在MongoDB中以灵活的JSON/BSON文档形式存储。而国产关系型数据库遵循严格的Schema定义,二者之间存在天然的"鸿沟"。
MongoDB中的典型文档结构:
cpp
// MongoDB中一份电子营业执照文档示例
{
"_id": ObjectId("507f1f77bcf86cd799439011"),
"certificateId": "123456789012345678",
"type": "business_license",
"enterpriseName": "某某科技有限公司",
"legalPerson": "张三",
"registeredCapital": "1000万元人民币",
"issueDate": ISODate("2023-01-15"),
"expiryDate": ISODate("2043-01-14"),
"attachments": [
{
"name": "营业执照正本.jpg",
"hash": "e4d909c290d0fb1ca068ffadd...",
"storagePath": "/fs/2023/01/15/abc123.jpg"
}
],
"metadata": {
"createdBy": "市场监督管理局",
"createdAt": ISODate("2023-01-15T08:00:00Z"),
"version": "1.0"
}
}迁移至关系数据库时,必须将此嵌套、灵活的文档"扁平化"为符合范式的多张表,并保证数据100%准确,满足政务"零差错"要求。
2.2 -> 高并发场景性能不足
系统服务全市500余家单位,业务高峰期并发连接数超1000。在原架构下,高频操作如证照亮证、跨部门核验响应延迟显著,影响办事体验。
典型高并发查询场景:
亮证查询:根据公民身份信息实时调取其名下所有证照。
证照核验:第三方机构通过二维码/编号验证证照真伪与状态。
2.3 -> 大规模数据迁移风险
2TB核心数据(含历史证照、权限、日志)需在有限迁移窗口内完成转移,并确保零丢失、零差错。这如同一场不容有失的"心脏外科手术"。
3 -> 金仓多模方案:技术破局的"三重奏"
3.1 -> 第一重:多模兼容,实现零代码平滑替换
金仓数据库通过多模数据引擎和原生协议兼容,实现了应用层代码的"无缝切换"。
- MongoDB协议兼容
应用层原有的MongoDB驱动和查询语法可直接连接金仓数据库,无需修改代码。
示例:应用层查询代码无需改动
cpp
// 原基于MongoDB Node.js驱动的查询代码
const MongoClient = require('mongodb').MongoClient;
const uri = "mongodb://kes:password@kingbase_host:port/admin";
const client = new MongoClient(uri);
async function findBusinessLicense(licenseId) {
try {
await client.connect();
const database = client.db("certificate_db");
const collection = database.collection("business_licenses");
// 原有的MongoDB查询语句在金仓数据库中可直接运行
const query = { certificateId: licenseId };
const license = await collection.findOne(query);
return license;
} finally {
await client.close();
}
}- 关系型与文档型数据一体化管理
金仓数据库支持在同一数据库中同时管理关系表和JSON文档,兼顾灵活性与规范性。
示例:在金仓数据库中创建支持JSON字段的业务表
cpp
-- 在金仓数据库中创建电子证照主表,使用JSON类型存储灵活数据
CREATE TABLE t_business_license (
id BIGSERIAL PRIMARY KEY,
certificate_id VARCHAR(20) NOT NULL UNIQUE,
enterprise_name VARCHAR(200) NOT NULL,
legal_person VARCHAR(50),
-- 使用JSON类型存储MongoDB中的attachments和metadata等动态字段
extended_data JSONB,
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 即可以关系型方式查询固定字段
SELECT certificate_id, enterprise_name
FROM t_business_license
WHERE legal_person = '张三';
-- 也可以使用JSON路径查询动态字段
SELECT certificate_id, extended_data->'attachments'->0->>'name' as main_attachment
FROM t_business_license
WHERE extended_data->'metadata'->>'createdBy' = '市场监督管理局';3.2 -> 第二重:读写分离集群,突破高并发瓶颈
金仓数据库基于主备读写分离架构,实现智能负载分担与深度性能优化。
- 读写智能分流配置
示例:在金仓数据库中配置读写分离
sql
-- 配置读写分离路由策略(示例语法)
-- 写操作自动路由到主节点
ALTER SYSTEM SET read_write_separation = on;
ALTER SYSTEM SET write_host = 'primary_node';
ALTER SYSTEM SET read_hosts = 'replica_node1,replica_node2';
-- 应用层可通过Hint强制指定查询路由
/*+ READ_ONLY(replica_node1) */
SELECT certificate_id, enterprise_name
FROM t_business_license
WHERE certificate_id = '123456789012345678';通过此架构:
写操作(证照签发、信息更新)定向至主库,保障数据一致性
读操作(证照亮证、核验查询)负载均衡至多个只读从库
系统并发承载能力从1000+提升至1600+连接数
- 场景化SQL性能调优
针对企业注册等复杂查询场景,金仓数据库进行了深度SQL优化。
优化前:复杂嵌套查询(响应约5秒)
sql
-- 原3层嵌套查询,涉及证照表、企业表、信用码表的多表关联
SELECT
c.certificate_id,
e.enterprise_name,
c.credit_code
FROM t_business_license c
JOIN t_enterprise_info e ON c.enterprise_id = e.id
WHERE c.credit_code IN (
SELECT credit_code FROM t_credit_rating
WHERE rating_level = 'A'
AND industry_type IN (
SELECT industry_code FROM t_industry
WHERE category = '高新技术企业'
)
);优化后:拆分为两次简单查询(响应0.3秒)
sql
-- 第一次查询:获取符合条件的信用码列表
/*+ READ_ONLY(replica_node1) */
SELECT credit_code
INTO TEMP TABLE tmp_credit_codes
FROM t_credit_rating
WHERE rating_level = 'A'
AND industry_type IN ('G0101', 'G0102', 'G0103'); -- 预定义的行业代码
-- 第二次查询:基于临时表进行关联查询
/*+ READ_ONLY(replica_node1) */
SELECT
c.certificate_id,
e.enterprise_name,
c.credit_code
FROM t_business_license c
JOIN t_enterprise_info e ON c.enterprise_id = e.id
JOIN tmp_credit_codes t ON c.credit_code = t.credit_code;3.3 -> 第三重:定制化迁移工具,保障数据安全高效迁移
金仓数据库提供了一站式数据迁移平台,并针对此项目进行了定制化开发。
- 自动化迁移脚本示例
sql
#!/usr/bin/env python3
# 金仓定制化迁移工具核心逻辑示例
def migrate_mongodb_to_kingbase():
"""从MongoDB到金仓数据库的迁移主流程"""
# 1. 全量数据迁移
migrator = KingbaseMigrator(
source_mongodb_uri="mongodb://source_host:27017",
target_kingbase_uri="kingbase://target_host:5432/cert_db",
batch_size=50000 # 优化批处理大小
)
# 配置集合到表的映射规则
migration_plan = {
"business_licenses": "t_business_license",
"personal_certificates": "t_personal_certificate",
"usage_logs": "t_usage_log"
}
# 执行迁移
migrator.execute_migration(migration_plan)
# 2. 数据一致性校验
validator = DataValidator()
consistency_report = validator.validate_data_consistency()
if consistency_report.is_success():
print("✅ 数据迁移成功,所有校验通过!")
# 3. 触发业务切换
trigger_switchover()
else:
print("❌ 数据不一致,需要人工干预")
consistency_report.print_details()- 多层次数据校验机制
示例:证照文件完整性校验
sql
-- 随机抽样1000份证照进行OFD签章验证
SELECT
certificate_id,
-- 调用金仓数据库的文件处理函数验证OFD完整性
kingbase_validate_ofd(certificate_file) as is_valid,
kingbase_extract_digest(certificate_file) as file_digest
FROM t_business_license
TABLESAMPLE SYSTEM(1000 ROWS); -- 随机抽样1000行
-- 压测核心查询接口,确保迁移后性能达标
SELECT
query_name,
avg_execution_time_ms,
max_execution_time_ms,
success_rate
FROM kingbase_performance_test('certificate_validation_queries', 10000);4 -> 业务价值体现
- 技术自主可控
-
彻底摆脱对国外数据库产品的依赖
-
筑牢政务数据安全底座
-
符合国家信创战略要求
- 服务高效便捷
-
高频操作响应时间从秒级降至毫秒级
-
群众办事体验显著提升
-
有力推动"一网通办"深化
- 路径可复制推广
-
验证标准化国产化路径
-
为全国政务系统改造提供样板
-
降低后续改造项目的技术风险
5 -> 技术架构演进
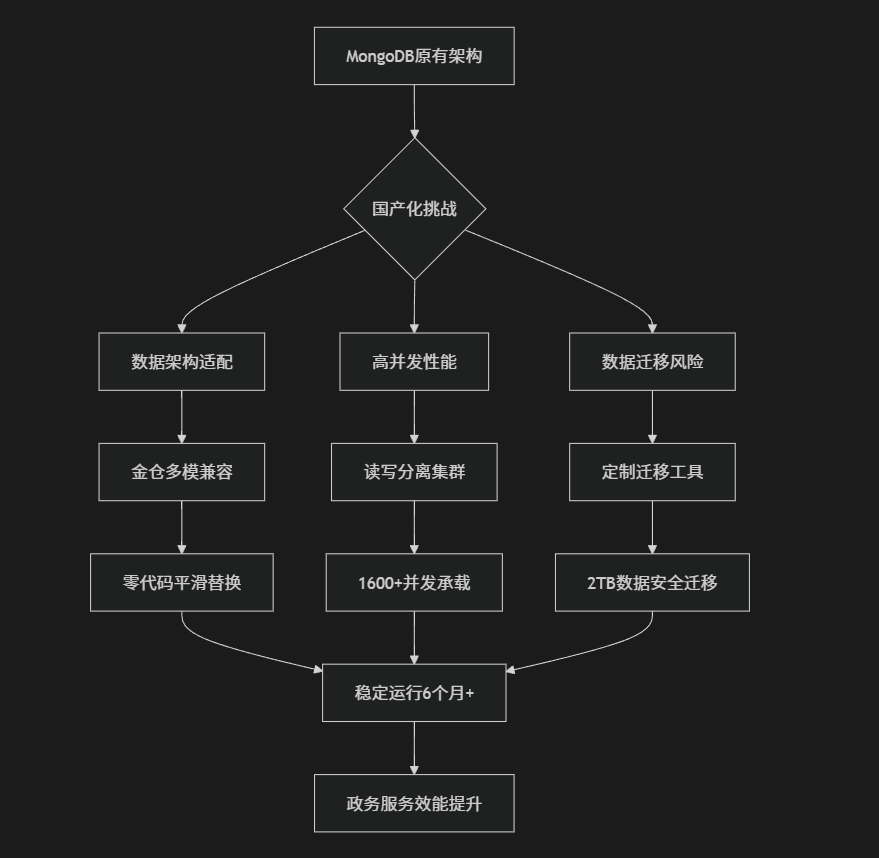
6 -> 经验总结与展望
6.1 -> 成功关键因素
- 技术选型精准
-
多模数据库解决架构适配难题
-
读写分离架构应对高并发场景
-
定制化工具保障迁移安全
- 实施方法科学
-
分阶段迁移,降低业务风险
-
全方位测试,确保系统稳定
-
持续优化,提升用户体验
- 生态合作紧密
-
数据库厂商深度参与
-
业务部门积极配合
-
技术团队能力提升
6.2 -> 未来展望
随着数字政府建设的深入推进,金仓数据库的国产化解决方案将在更多政务场景中发挥重要作用:
-
横向扩展:复制成功经验到其他政务系统
-
纵向深化:探索更多数据类型的国产化支持
-
生态建设:构建完整的国产化技术生态链
7 -> 结语
福建某地市的成功实践证明,政务系统国产化改造的深水区并非不可逾越。金仓数据库凭借其多模数据管理能力、深度性能优化实力与全流程迁移保障,将电子证照系统的国产化替换从一道"风险题"变为了"加分题",为构建安全、高效、智能的"数字政府"提供了坚实的技术基座。