长上下文(Long Context)建模,已成为大模型行业的前沿研究趋势,是使得大语言模型(LLM)具备真实生产力的关键。
理论上,长上下文 LLM 不仅能够实现更全面的语义理解,还能显著增强多步推理与长期记忆能力,从而像人类一样做到"通读全篇、整体思考"。
然而,当将上下文窗口扩展到百万 token 级时,计算与内存成本也会大幅上升,使得长上下文 LLM 的实际应用受限。
为应对这一挑战,来自清华大学和智谱(Z.ai)的研究团队摒弃了基于 token 的序列扩展范式,转而基于「视觉上下文扩展」全新视角提出了 Glyph 框架,即将长文本渲染成图像,并通过视觉语言模型(VLM)进行处理。

论文:https://arxiv.org/pdf/2510.17800
GitHub:https://github.com/thu-coai/Glyph
实验结果表明,通过持续预训练、由 LLM 驱动的遗传式渲染搜索,以及有针对性的后训练优化,Glyph 在保持与前沿 LLM 相当精度的同时,实现了 3-4 倍的 token 压缩,大幅提高了内存效率、训练和推理速度。
以经典长篇小说《简·爱》(约 240k 个文本 token)为例:
-
传统的 128K 上下文 LLM 无法正确回答需要通篇考虑的问题(如"当简离开桑菲尔德府后陷入困境时,谁给予了她支持?")
-
相比之下,Glyph 将全书内容呈现为紧凑的图像(约 80k 视觉 token),使 128k 上下文的 VLM 能够回答上述问题。
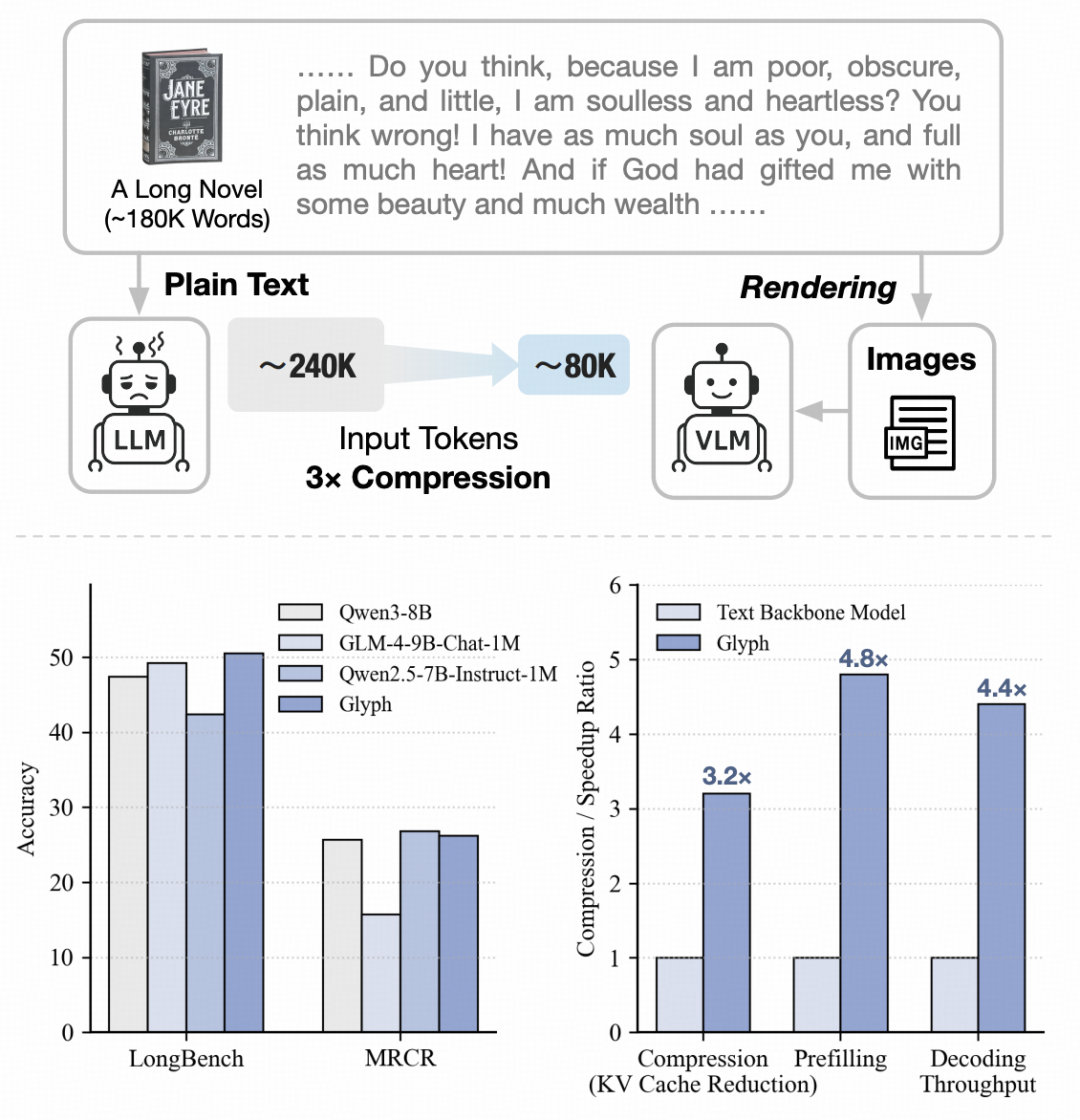
图|(上)两种长上下文任务范式对比:传统方法直接将纯文本输入语言模型,而 Glyph 将文本渲染为紧凑图像,实现显著的输入 token 压缩;(下)在 LongBench 和 MRCR 测试集上,Glyph 展现出具有竞争力的性能,同时在 128K token 输入规模下,相较其文本基准模型实现了显著的压缩率和推理加速。
更进一步,在极限压缩条件下,一个拥有 128K 上下文窗口的 VLM 能够扩展到处理百万级 token 的文本任务。
研究团队表示,提高 token 信息密度为长上下文建模提供了一种有前景的新范式,其与现有基于注意力的方法互为补充,且仍有广阔的探索空间。
从上下文工程的角度来看,这种方法提供了一种优化上下文信息表征和管理的新方式。未来,LLM 或将突破当前的上下文长度限制,将输入 token 从百万级扩展到千万级。
研究方法
Glyph 的核心目标是让模型以"看"的方式理解超长文本。通过将文本渲染为图像,模型能够在有限的 token 数量下接收更丰富的上下文信息,实现高效的文本压缩。
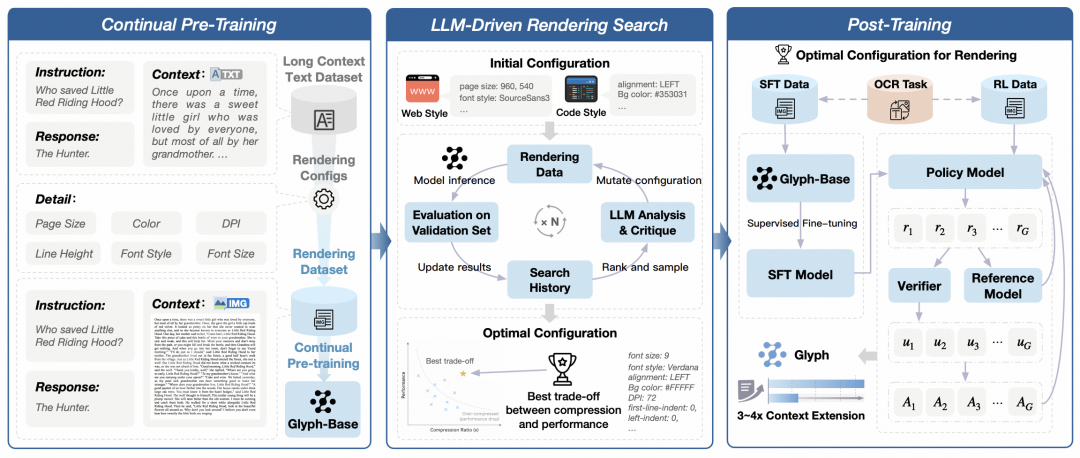
整体框架包含三个主要阶段:
1.持续预训练
研究团队首先将大规模长文本数据渲染为多种视觉风格,包括文档布局、网页结构、代码展示等形式,以模拟不同类型的真实长文本场景。
在此基础上,他们构建多种任务,例如 OCR 识别任务、图文交错建模任务与视觉补全任务,使模型能够同时学习文字的视觉形态与语义含义。 这一阶段的训练帮助模型建立起视觉与语言之间的跨模态语义对齐能力。
2.LLM 驱动渲染搜索
在视觉压缩过程中,渲染配置(如字体、分辨率、排版布局)直接影响模型的感知效果与任务性能。为了在压缩率与理解能力之间取得最优平衡,他们提出了一种由 LLM 驱动的遗传搜索算法。在该框架中,他们在验证集上自动评估不同渲染方案的性能,由 LLM 分析其优劣并生成新的候选配置。通过多轮迭代,Glyph 能够逐步收敛到在语义保持与压缩效率间最优的渲染策略。
3.后训练阶段
在找到最优渲染配置后,他们对模型进行监督微调(SFT)与强化学习优化(使用 GRPO 算法)。此外,他们引入 OCR 辅助任务,进一步强化模型的文字识别与细节理解能力。
效果怎么样
研究团队在多个长上下文基准上系统评估了 Glyph 的效果。如下:
1.在 LongBench 与 MRCR 上,Glyph 实现了平均 3--4 倍的输入压缩率,同时保持与 Qwen3-8B、GLM-4-9B-Chat-1M 等主流模型相当的精度。
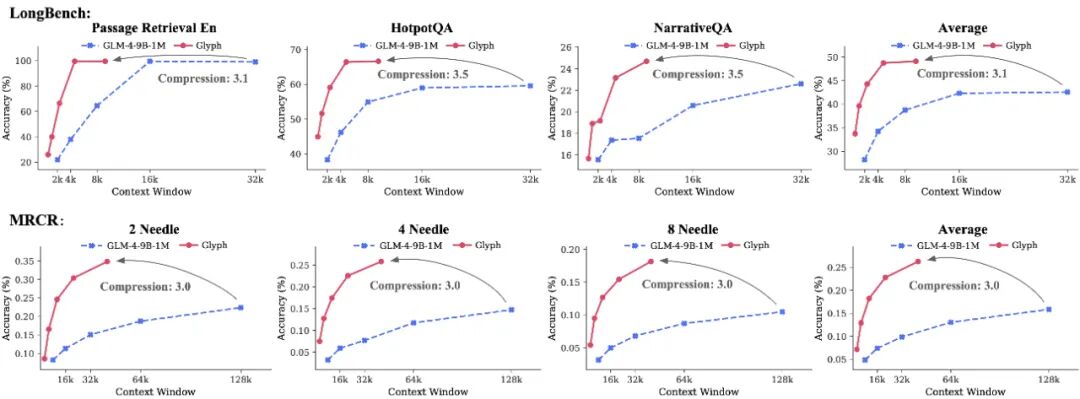
图|Glyph 与基线模型在不同上下文窗口下的性能对比,表明 Glyph 采用显著缩短的上下文窗口即可达到与更长上下文相当的性能。
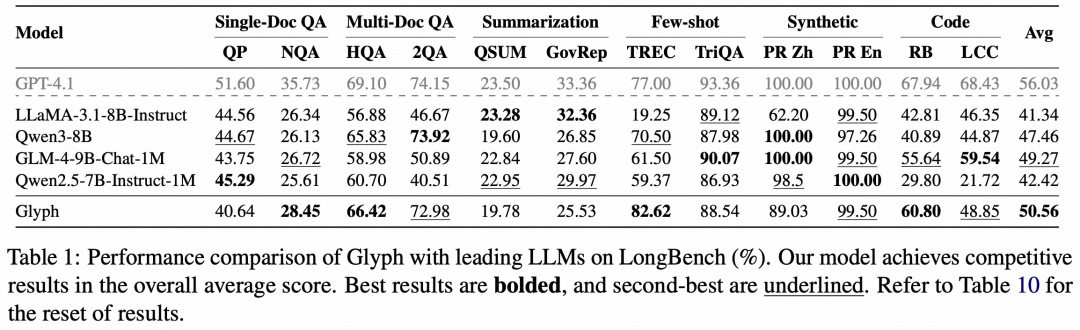
表|Glyph 与主流 LLM 在 LongBench 上的性能对比(%)。
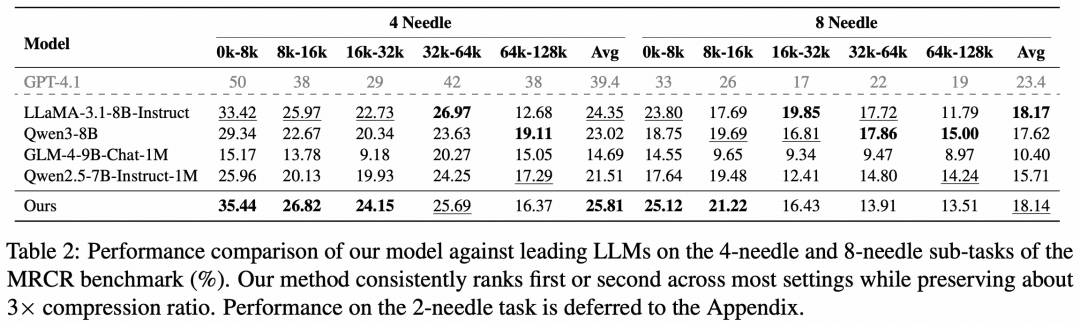
表|模型在 MRCR 基准测试 4-needle 与 8-needle 子任务上的性能对比(%),在多数设置下位于前两名,同时保持约 3 倍压缩率。
2.相比文本基建模型,推理与训练速度分别提升 4× 和 2×,并且随着上下文变长,推理速度的优势也随之增强。
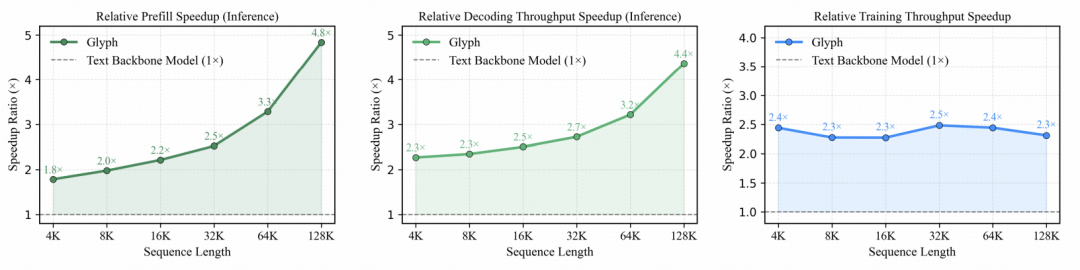
图|在预填充、解码和训练过程中,Glyph 相对于文本骨干模型在不同序列长度下的加速比。
3.在极端压缩场景下(8×压缩比),Glyph 有潜力利用 128k 上下文长度处理百万级上下文任务。
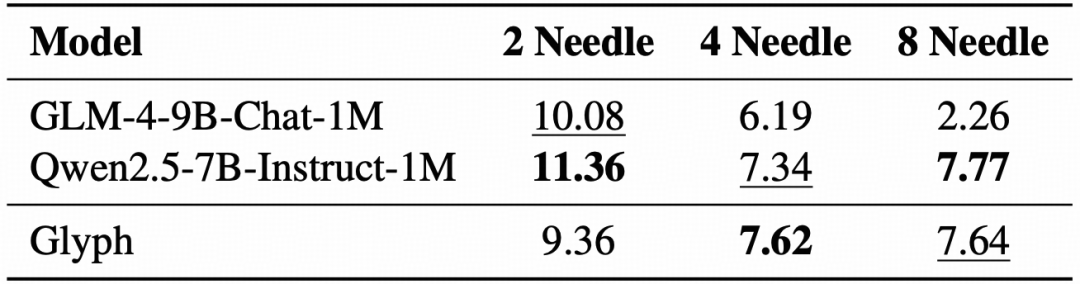
表|在不同 needle 数量下,128K-1M 上下文长度下平均 MRCR 性能(%)。
4.在 MMLongBench-Doc 上,Glyph 在文档理解任务上显著优于原始视觉语言基线,展现了跨模态泛化能力。
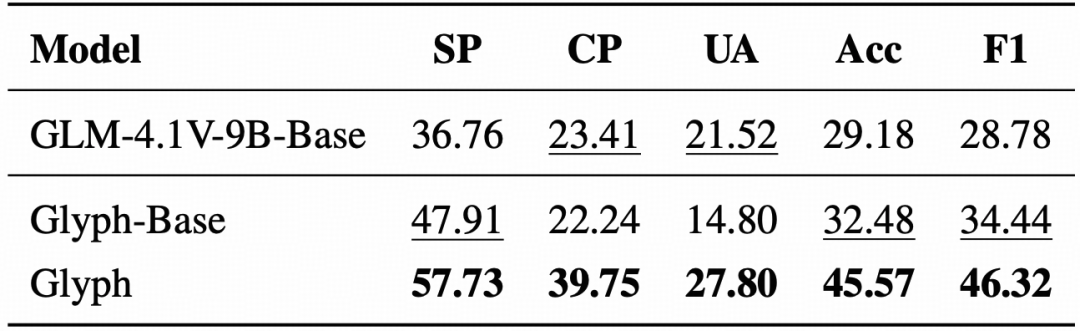
表|MMLongBench-Doc 测试结果(%)。SP、CP、UA 和 Acc 分别表示单页准确率、跨页准确率、无法回答率和总体准确率。
不足与未来方向
当然,Glyph 框架也存在一些局限性。如下:
1.对渲染参数非常敏感
该方法依赖于在处理之前将文本输入渲染成图像,这使得最终性能可能受到分辨率、字体和间距等渲染配置的影响。尽管搜索过程能够找到一个在下游任务上表现良好的配置,但如何使模型在各种渲染设置下更具鲁棒性仍然是一个尚未解决的问题。
2.OCR 保真度仍需提高
UUID 识别对于当前的 VLM 来说仍然特别具有挑战性,即使是 SOTA 模型 Gemini-2.5-Pro 也经常无法正确重现。虽然这对大多数任务影响不大,但提高 OCR 保真度可以提高 Glyph 的上限。
3.评测任务多样性不足。
该工作涉及的基准测试主要侧重于长上下文理解,并未完全涵盖现实世界应用的多样性,如 agentic 任务或推理密集型任务。同时,与文本模型相比,视觉-文本模型在跨任务泛化方面的效果往往较差。扩展评估和训练的范围以涵盖更广泛的任务,将有助于更好地评估和改进 Glyph 的鲁棒性和通用性。
尽管如此,但研究团队认为,他们提出的「视觉-文本压缩」范式可以在未来的研究中得到进一步的扩展,包括以下方向:
首先,一个有前景的途径是训练自适应渲染模型,而不是使用固定的渲染策略,这些模型根据任务类型或用户查询进行条件调整,生成平衡压缩和性能的定制可视化。
其次,增强视觉编码器对细粒度文本识别的能力以及与语言表征的对齐,可以提高跨任务的鲁棒性和可迁移性。
再者,通过知识蒸馏或跨模态监督等方式,改进视觉-文本模型与纯文本模型之间的对齐,可以缩小泛化方面的性能差距。
最后,将这一方法扩展到更广泛的应用,如能够管理长期对话或 agentic 上下文的 agent 记忆系统,以及可以利用结构化视觉布局进行推理和检索的任务。