一、传统RAG的黄金时代结束了
在过去两年多,检索增强生成(RAG,Retrieval-Augmented Generation)一直是缓解大模型上下文衰减、提升知识问答准确性的主流方法。
RAG 的核心思想是: 让模型在回答问题前,先去外部知识库检索相关信息,再基于检索结果进行生成。这样做可以显著降低幻觉(hallucination),并让中小模型也能具备类似"知识型大模型"的能力。
传统 RAG 通常包括三个关键环节:
1.检索阶段: 利用稀疏检索(如 BM25、SPLADE)或稠密向量检索(如embeddingsearch)从文档库中找出最可能相关的内容。
2.重排序阶段: 使用RRF(倒数排名融合)或交叉编码器(cross-encoder)对候选结果重新打分,筛选出最有价值的片段。
3.生成阶段: 将筛选出的上下文拼接进提示词(prompt),交给 LLM 生成答案、摘要或代码解释。
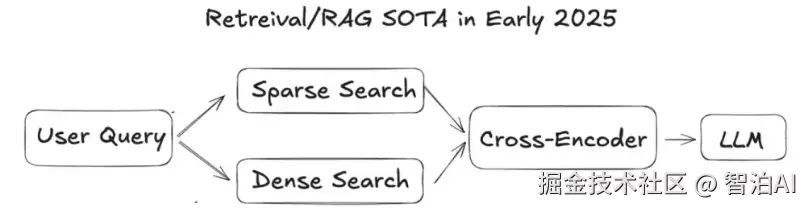
通过这种"外部检索+精选上下文+智能生成"的结构,传统 RAG能在大多数知识问答、论文检索、代码理解等任务中取得远超纯大语言模型的效果。
然而,随着投入更多计算资源或更复杂的流水线,不断改进嵌入模型、重排序器和融合策略,传统RAG的性能提升开始进入边际递减阶段,更多工程堆叠带来的增益越来越有限。
二、智能检索的崛起: 让模型"主动搜索"
在传统 RAG 架构中,检索与生成是割裂的两个阶段: 外部系统(如向量数据库、BM25)负责查找信息,语言模型仅被动地基于检索结果生成答案。模型本身既不了解"该查什么 ",也无法判断"是否需要再查"。
而在新一代的智能体式检索(Agentic Retrieval)中,语言模型不再只是被动地等待检索结果,而是能够主动规划、发起并控制整个检索过程,同时承担两个核心任务:
1.检索、过滤与聚合信息。模型可以决定使用哪种工具、何时发起搜索、何时停止,并整合结果以生成高质量上下文。
2.基于检索的生成与推理。根据检索到的上下文进行生成与推理,如撰写分析报告、编写代码、回答复杂问题等。
这种智能体式检索不再依赖传统的外部系统(如向量数据库、BM25),而是让大语言模型具备工具使用与自我决策能力,能在循环中主动执行检索一推理一再检索,在迭代中完成从"寻找信息 "到"利用信息"的全过程。
这不仅显著降低了延迟与系统复杂度,也让检索与生成过程变得更加自然、智能与高效。
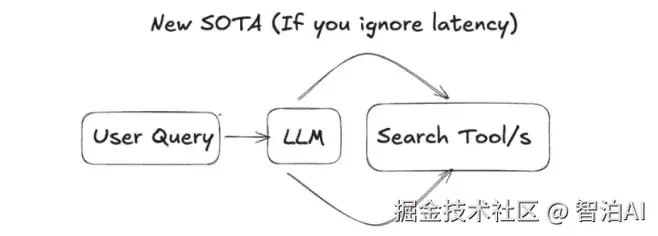
实验发现,即使这些智能体(agent)所使用的工具并不完美,它们的整体表现仍能超越经过精心调优的传统 RAG 系统。
智能体不再是一次性、被动地调用检索,而是能够像人类一样进行动态思考与探索: 它会先发出初步查询,分析返回结果的相关性与有效性,然后根据判断决定是否继续搜索、调整关键词,或切换到其他工具。
这种"推理一检索一再推理"的循环式过程,使模型具备了更强的检索策略优化能力。
三、案例: Grok Code 的极致效率
xAI的 Grok Code 是这一趋势的典型代表。
早期的代码助手(如Copilot或 Code Llama)大多采用传统RAG方式:
先检索项目中的相关文件;
再将检索结果拼接进上下文;
然后交由大模型生成补全或修改。
这类系统虽能工作,但效率低下--模型需要在大量无关上下文中反复推理,导致延迟高、计算成本大、响应不稳定。
Grok Code 的突破在于,它通过强化学习,让模型能够在一个统一的循环中完成整个开发闭环: 检索→分析 → 修改 → 执行 → 验证 → 再检索。
这意味着 Grok Code 不只是一个"会写代码的模型",而是一个能主动发现问题、验证修改并持续优化的智能体。
xAI团队在内部版本 grok-code-fast-1的更新中提到,这种优化后的智能体能:
只检索与当前问题直接相关的代码上下文;
在执行失败后,自动分析错误日志并定位问题文件;
根据结果动态调整检索策略,而非盲目重新搜索。
这让 Grok Code 变得"快得离谱": 它减少了无效搜索与上下文拼接的时间开销,使整个编辑循环更接近人类程序员的思维方式。
然而,Grok Code 的检索对象(代码数据)是相对结构化的。
当我们把这种智能检索思路扩展到非结构化的长文档时,问题会变得更复杂: 模型如何才能在成千上万字的文本中,像人类一样有条理地翻找、理解与推理?
四、PageIndex: 专为长文档设计的新一代检索系统
PageIndex将智能体式检索的理念从代码领域扩展到长文档分析中。它是首个针对长文档的In-Context Index(上下文索引)系统,能够为LLM 构建一个层级化的、目录树式的索引结构(treeindex),并通过以下流程实现高效检索:
1.将整棵索引树直接放入 LLM 的上下文窗口中;
2.让 LLM 像人类翻阅目录一样,在层级树结构中导航与推理,定位到相关章节,并检索所需内容。
这种树索引不再是存在于 LLM 外部的数据结构,而是直接存在于大模型的上下文中。
这意味着模型的检索不再依赖外部的infra(如向量数据库),而是能够像人类一样,在长文档中通过层级目录推理与上下文理解定位信息,实现更智能的"上下文内检索(InContext Retrieval)"
在金融领域的高复杂文档任务中,PageIndex构建的金融问答系统 Mafin2.5在完全未使用向量数据库的情况下,取得了98.7% 的准确率,处于业界领先水平。
五、结语
过去,我们依赖更好的embedding、更复杂的重排序器来提升检索性能;而如今,智能体已经让检索从"被动查询 "进化为"主动探索",使模型能够像人类一样,主动寻找、筛选、组织信息。
更多AI大模型学习视频及资源,都在智泊AI。