第一章 计算机视觉与深度学习概述
1.1 计算机视觉的发展历程和应用领域
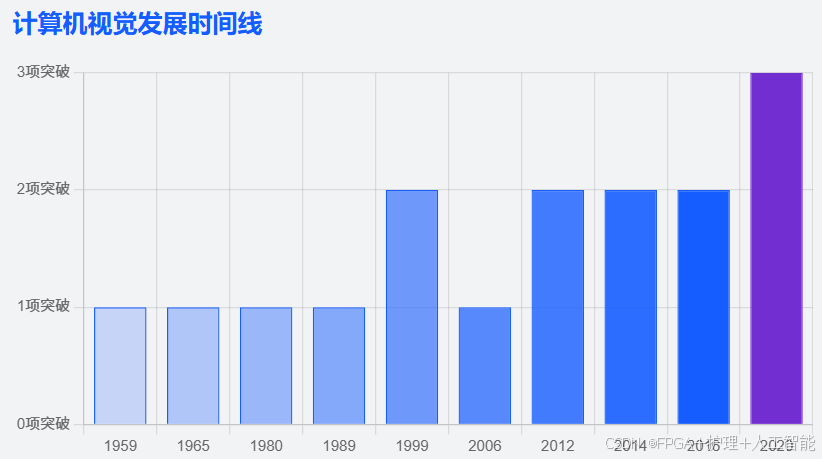
计算机视觉作为人工智能领域的重要分支,其发展历程可以追溯到 20 世纪 50 年代。
1959 年,神经生理学家 David Hubel 和 Torsten Wiesel 通过猫的视觉实验,发现视觉处理过程总是从类似特定方向边缘的简单结构开始,这一发现为 40 年后计算机视觉技术的突破性发展奠定了基础,也成为了深度学习的核心准则之一(4)。
同年,Russell 和他的同学研制出了第一台数字图像扫描仪,这台仪器能够将图片转化为二进制机器可理解的灰度值,为后续的数字图像处理奠定了基础(4)。
进入 20 世纪 60 年代,计算机视觉的研究开始向三维视觉的探索迈进。1965 年,Lawrence Roberts 在论文《三维固体的机器感知》中描述了从二维图片中推导三维信息的过程,这一工作被视为现代计算机视觉的先驱之一,开创了以理解三维场景为目标的计算机视觉研究(4)。他对积木世界的创造性研究为后续研究提供了重要启发。
1966 年,MIT AI 实验室的 Seymour Papert 教授启动了夏季视觉项目,尽管最终未能成功,但这一尝试标志着计算机视觉作为一门科学领域的正式诞生(4)。
20 世纪 70 年代,计算机视觉与人工智能的结合开始加深。1977 年,David Marr 在 MIT AI 实验室提出了计算机视觉理论,这一理论与 Lawrence Roberts 的积木世界分析方法截然不同,为 80 年代的计算机视觉研究提供了重要理论框架(4)。1982 年,David Marr 发表的《视觉》一书,标志着计算机视觉成为一门独立学科(4)。
20 世纪 80 年代见证了计算机视觉技术的重要突破。1980 年,日本计算机科学家 Kunihiko Fukushima 基于 Hubel 和 Wiesel 的研究,建立了首个自组织的人工神经网络 ------Neocognitron,这是现代卷积神经网络(CNN)的早期雏形(4)。1989 年,Yann LeCun 将后向传播学习算法应用于 Fukushima 的卷积神经网络结构,开发了 LeNet-5,这是现代 CNN 的重要里程碑(4)。
进入 20 世纪 90 年代,特征对象识别开始成为研究重点。1997 年,伯克利教授 Jitendra Malik 提出了基于图论算法的图像分割方法(4)。1999 年,David Lowe 发表的《基于局部尺度不变特征(SIFT 特征)的物体识别》标志着研究重点从三维模型重建转向基于特征的对象识别(4)。同年,Nvidia 公司推出的 GPU 概念为图像处理提供了强大算力支持(4)。
21 世纪初,图像特征工程和高质量数据集的出现推动了计算机视觉的快速发展。2001 年,Paul Viola 和 Michael Jones 推出了首个实时工作的人脸检测框架(4)。2005 年,Dalal & Triggs 提出的 HOG 特征被广泛应用于行人检测(4)。2006 年,Pascal VOC 项目启动,提供了标准化的对象分类数据集和评估工具(4)。
2010 年至今的深度学习革命 成为计算机视觉发展史上的分水岭。2009 年,李飞飞教授发布的 ImageNet 数据集成为计算机视觉领域的重要里程碑(4)。2012 年,Alex Krizhevsky 等人开发的 AlexNet 在 ImageNet 挑战赛中取得突破性成果,将错误率从 25% 降低至 16%,展示了 CNN 的强大能力(4)。这一成就不仅标志着深度学习在计算机视觉领域的崛起,更开启了一个全新的技术时代。
在医疗领域的应用方面,计算机视觉正在成为医生的 "第二双慧眼"。AI 可以从 CT、MRI 等医学影像中高精度地检测肿瘤、病变,辅助医生进行早期诊断(14)。在手术中,视觉技术可以辅助机器人进行精准操作;在药物研发中,可以分析细胞图像,加速新药筛选(14)。
医学影像是计算机视觉在医疗领域最成熟的应用,它能辅助医生快速、准确地定位病灶,减少漏诊和误诊,尤其在早期疾病筛查中发挥重要作用(18)。具体应用包括:
-
病灶检测 :如肺癌筛查(CT 影像中检测肺部结节)、糖尿病视网膜病变诊断(眼底图像中检测微血管瘤)、乳腺癌筛查(钼靶影像中检测钙化灶)(18)。
-
病灶分割 :如脑瘤分割(MRI 影像中分割肿瘤的位置和大小)、肝脏分割(CT 影像中分割肝脏,辅助手术规划)(18)。
1.2 深度学习在计算机视觉中的地位和作用
深度学习在计算机视觉领域的地位可以用 "革命性" 来形容。卷积神经网络(CNN)作为专门处理具备空间不变性数据(如图像)的深度学习模型,已经成为该领域的核心技术(61)。CNN 通过局部感知和权值共享机制,能够高效提取影像中的空间层级特征,在医学影像分析中表现优异(66)。
深度学习系统可以为医生提供辅助意见,标注出图像中有问题的区域(61)。CNN 可以在多种医疗影像上训练,包括放射科、病理科、皮肤科和眼科(61)。深度学习还可以通过整合医疗图像、病例、可穿戴设备数据等其他形式的数据进一步增强此类模型(61)。
基于深度学习的医学图像诊断系统能够从海量医学图像数据中自动学习特征,辅助医生进行更准确、高效的诊断(62)。深度学习模型能够处理高维、复杂的医学图像数据,挖掘其中的潜在信息(62)。
在技术架构方面,深度学习特别是 CNN 的应用,在器官分割、病灶检测等方面实现了突破性进展(64)。基于深度学习的配准算法解决了不同模态图像间的空间对应问题,为医生提供更全面的诊断依据(64)。
CNN 作为深度学习的主流模型,在图像特征提取方面展现出卓越性能。CNN 通过卷积层、池化层和全连接层的组合,能够自动学习图像的多层次抽象特征(66)。这种自动特征提取能力彻底取代了传统手工特征设计,极大地提升了图像处理的效率和准确性(64)。

在实际应用中,CNN 的优势体现在多个方面:

强大的特征提取能力:CNN 能够自动从图像中学习到复杂的特征表示,从低级的边缘、纹理特征到高级的语义特征,都能被网络有效地捕捉和表达。
端到端的学习能力:深度学习模型可以实现从原始图像到最终诊断结果的端到端学习,避免了传统方法中复杂的特征工程和参数调优过程。
优异的泛化性能:通过大规模数据训练和适当的正则化技术,深度学习模型展现出良好的泛化能力,能够在不同的数据集和应用场景中保持稳定的性能。
1.3 目标检测技术的发展脉络
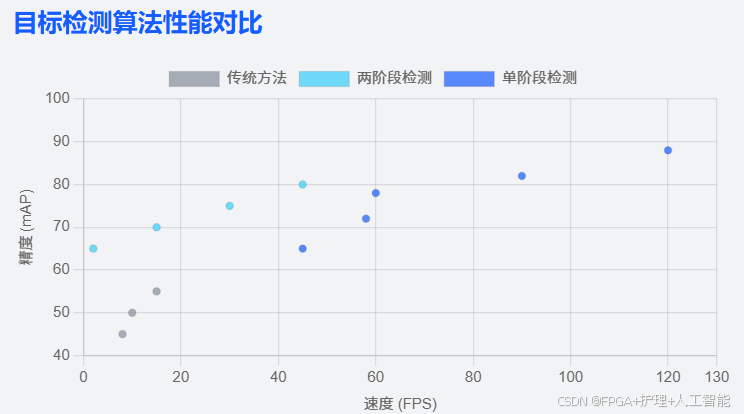
目标检测技术的发展历程可以 2014 年为分水岭,划分为 "传统目标检测期" 和 "基于深度学习的目标检测期" 两个主要阶段(69)。
传统目标检测时期(2000-2012 年)主要基于手工特征和传统机器学习方法。这一时期的代表性技术包括:
-
模板匹配方法:通过在图像中滑动模板窗口来寻找与目标相似的区域,但计算量大且对尺度、旋转变化敏感。
-
特征工程方法:研究者们设计了各种手工特征,如 Haar 特征、LBP 特征、HOG 特征等,并结合 Adaboost、SVM 等机器学习算法进行目标检测。
-
可变形部件模型(DPM) :2009 年 Felzenszwalb 教授提出的 DPM 成为深度学习时代前最成功的物体检测与识别算法(4),它通过建模目标的部件结构和变形关系来实现检测。
深度学习革命时期(2012 年至今)带来了目标检测技术的根本性变革:
- 2012 年,AlexNet 在 ImageNet 图像分类比赛中获得胜利,标志着深度学习在计算机视觉领域的崛起(71)。
- 2013 年,RCNN(Region-based Convolutional Neural Networks)首次将卷积神经网络应用于目标检测,将目标定位任务转化为区域建议的问题(71)。
R-CNN 家族的发展历程 代表了两阶段检测方法的演进:
-
R-CNN(2014 年) :Ross Girshick 等人提出的 R-CNN 彻底改变了目标检测的游戏规则(54)。R-CNN 的核心思想是将传统的区域提议方法与深度卷积神经网络相结合,在 PASCAL VOC 2012 数据集上实现了 53.3% 的 mAP,相比之前的最佳方法提升了 30% 以上。
-
Fast R-CNN(2015 年):为了解决 R-CNN 的效率问题,Ross Girshick 提出了 Fast R-CNN,引入了 ROI Pooling 层和多任务损失函数,将训练时间从 84 小时缩短到 9.5 小时,测试时间从 47 秒缩短到 0.32 秒。
-
Faster R-CNN(2015 年):Shaoqing Ren 等人提出的 Faster R-CNN 引入了区域提议网络(RPN),将区域提议生成也纳入到端到端的训练框架中,实现了真正的实时检测,在 GPU 上达到 5fps 的检测速度。
单阶段检测器的兴起(2016 年至今) 代表了目标检测技术的另一个重要发展方向:
-
YOLOv1(2016 年) :Joseph Redmon 等人提出的 YOLO 首次将目标检测简化为单一回归问题,抛弃了复杂的候选区域生成流程,通过网格划分直接预测目标位置和类别,实现了 45FPS 的实时检测性能,快速版本达到 155FPS(127)。
-
SSD(2016 年):Wei Liu 等人提出的 SSD 在 YOLO 的基础上进一步优化,引入了多尺度特征图和默认框的概念,在保持实时性的同时显著提升了检测精度。
-
YOLO 后续版本的演进 :从 YOLOv2 到 YOLOv8,每个版本都在速度、精度、模型效率等方面进行了持续改进,形成了完整的技术演进路线。
1.4 YOLO 算法的诞生背景和创新意义
YOLO(You Only Look Once)算法的诞生源于对传统目标检测方法局限性的深刻认识。传统的两阶段检测方法(如 R-CNN 系列)虽然精度较高,但存在检测速度慢、计算复杂、无法实现实时检测等问题。在许多实际应用场景中,如自动驾驶、视频监控、移动设备应用等,实时性是一个至关重要的需求。
YOLO 的核心创新在于将目标检测问题重新定义为一个回归问题 。Joseph Redmon 创新性地提出了通过直接回归的方式获取目标检测的具体位置信息和类别分类信息,极大地降低了计算量,显著提升了检测的速度(124)。
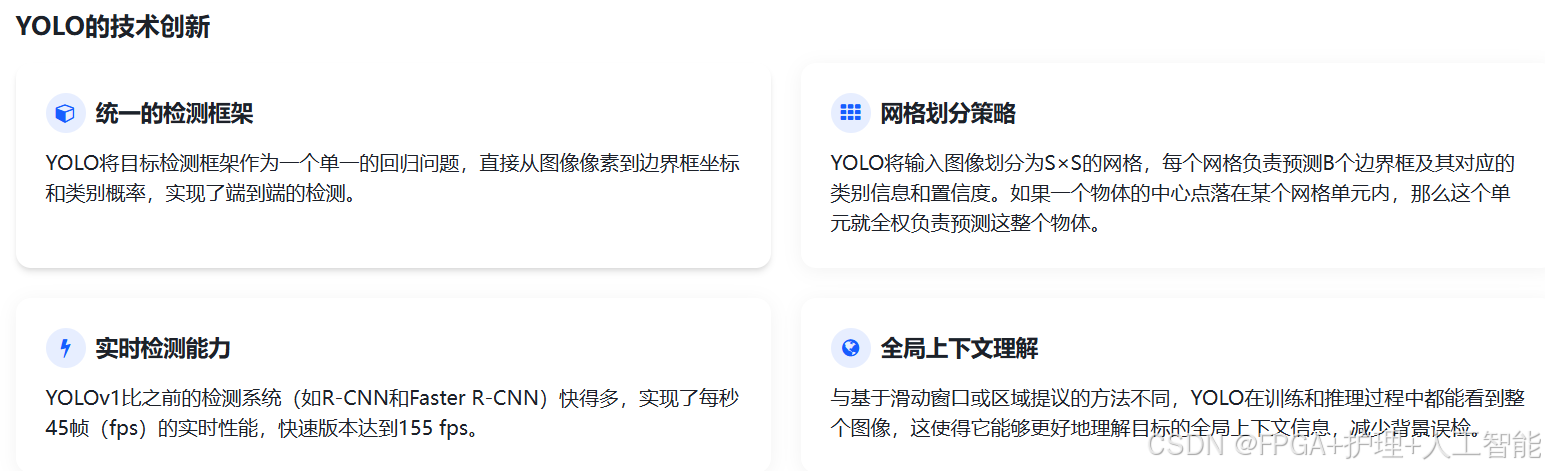
YOLO 的技术创新主要体现在以下几个方面:
-
统一的检测框架 :YOLO 将目标检测框架作为一个单一的回归问题,直接从图像像素到边界框坐标和类别概率,实现了端到端的检测(127)。
-
网格划分策略 :YOLO 将输入图像划分为 S×S 的网格,每个网格负责预测 B 个边界框及其对应的类别信息和置信度。如果一个物体的中心点落在某个网格单元内,那么这个单元就全权负责预测这整个物体(113)。
-
实时检测能力 :YOLOv1 比之前的检测系统(如 R-CNN 和 Faster R-CNN)快得多,实现了每秒 45 帧(fps)的实时性能,快速版本达到 155 fps(127)。
-
全局上下文理解:与基于滑动窗口或区域提议的方法不同,YOLO 在训练和推理过程中都能看到整个图像,这使得它能够更好地理解目标的全局上下文信息,减少背景误检。
YOLO 算法在实际应用中的突破主要体现在以下几个方面:
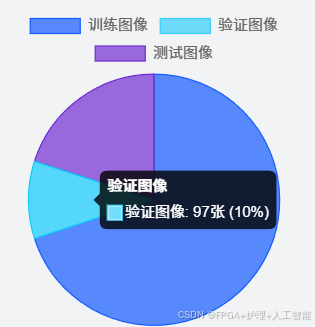
- 在医疗领域的应用突破 方面,YOLO 算法展现出了巨大的潜力。基于 YOLOv8 目标检测算法开发的皮肤病自动识别系统,专门用于检测和分类 7 种常见的皮肤病变,系统训练数据集包含 681 张训练图像、97 张验证图像和 195 张测试图像,涵盖了 Bowen's Disease、基底细胞癌、良性角化病病变、皮肤纤维瘤、黑色素瘤、黑素细胞痣和血管性病变等七类皮肤病(102)。
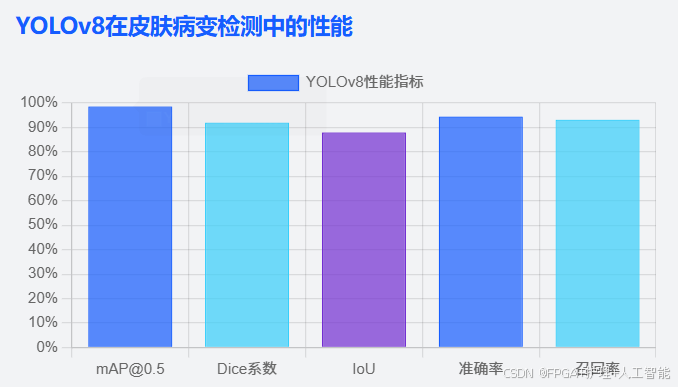
- 在实时检测性能突破 方面,基于 YOLOv8 的深度学习框架在黑色素瘤检测和分割任务中取得了最先进的性能,实现了 98.6% 的平均精度(mAP@0.5)、0.92 的 Dice 系数和 0.88 的交并比(IoU)得分,同时保持了每张图像 12.5 毫秒的实时推理速度(100)。
- 在临床部署应用突破方面,英国国家医疗服务体系(NHS)的一家医院率先采用人工智能诊断皮肤癌,使患者无需就诊医生即可进行关键筛查。切尔西与威斯敏斯特医院的工作人员使用带有放大镜的 iPhone 拍摄任何可疑痣的照片,AI 应用程序会在几秒钟内分析图像。
- 在技术集成创新突破 方面,研究人员开发了 YOLOSAMIC(YOLO 和 SAM 在癌症成像中的应用),这是一个全自动的分割框架,集成了 YOLOv8 用于病变检测和分割任何模型(SAM)-Box 用于精确分割,在公共数据库上实现了 0.9399 的 Dice 分数和 0.9112 的 Jaccard 分数,在混合数据集上实现了 0.8990 的 Dice 分数和 0.8445 的 Jaccard 分数(107)。
YOLO 算法的创新意义不仅在于技术层面的突破,更在于它为实时目标检测开辟了一条全新的道路。通过将复杂的目标检测任务简化为一个统一的回归问题,YOLO 不仅实现了速度上的飞跃,还为后续的算法改进和应用拓展奠定了坚实的基础。在医疗领域,YOLO 算法正在成为辅助诊断、远程医疗、智能筛查等应用的重要技术支撑,为提升医疗服务质量和可及性做出了重要贡献。