之前学得有点迷迷糊糊、囫囵吞枣,现在重新学一遍。
1 核心框架
零、二分查找框架
cpp
int binarySearch(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
while (...) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
...
} else if (nums[mid] < target) {
left = ...
} else if (nums[mid] > target) {
right = ...
}
}
}为什么 mid = left + (right - left) / 2 而不是 (left + right) / 2?
核心原因:避免整数溢出。
- 假设
left和right都是接近int最大值的数(比如left = 2^30,right = 2^30),那么left + right会超过int的取值范围(int 最大值约 2^31-1),导致整数溢出(结果变成负数)。 - 而
left + (right - left) / 2等价于(left + right) / 2(数学上完全相等),但计算过程中right - left不会溢出(因为right >= left,且差值远小于int最大值),因此更安全。 - 补充:在 C++11 及以上,也可以用
mid = (long long)left + right / 2强制类型转换避免溢出,但left + (right - left)/2是更通用的写法。
2 边界处理
二分查找的核心痛点就是边界处理,绝大多数错误都源于「区间定义」和「更新规则」不一致。想要彻底掌握边界细节,关键是先固定「区间定义」,再严格遵循对应的规则。以下是一套可落地的边界注意事项和避坑指南:
一、先明确:二分查找的 2 种核心区间定义(二选一,全程不变)
所有边界规则都围绕「区间是否包含端点」展开,先选一种风格,不要混用:
| 区间风格 | 核心定义 | 初始值 | 循环条件 | 核心特点 |
|---|---|---|---|---|
闭区间 [L, R] |
包含左、右边界 | L=0,R=len-1 | L ≤ R | 需检查最后一个元素(L==R 时) |
左闭右开 [L, R) |
包含左边界,不包含右边界 | L=0,R=len | L < R | R 永远是 "越界 / 不检查" 的位置 |
二、按区间风格,牢记「边界更新 + 终止处理」规则(避坑核心)
1. 闭区间 [L, R] 规则(新手优先)
核心:每一步都要明确「排除已检查的 mid」,避免死循环 / 漏查
- ✅ 循环条件:
L <= R(因为[L, R]非空时都要检查,比如 L=R 时还有 1 个元素); - ✅ 当
nums[mid] < target:目标在右侧,排除 mid →L = mid + 1; - ✅ 当
nums[mid] > target:目标在左侧,排除 mid →R = mid - 1; - ✅ 当
nums[mid] == target:按需处理(找值返回 mid / 找左边界继续左移 R / 找右边界继续右移 L); - ✅ 循环终止后:
L > R,此时 L 是「第一个大于 target 的位置」,R 是「最后一个小于 target 的位置」。
避坑点:
- ❌ 不要写
L = mid或R = mid:比如 L=2、R=3 时,mid=2,若更新 L=mid,循环永远无法终止; - ❌ 循环条件写
L < R:会漏掉最后一个元素(比如数组只有 1 个元素时,循环直接不执行)。
2. 左闭右开 [L, R) 规则(进阶)
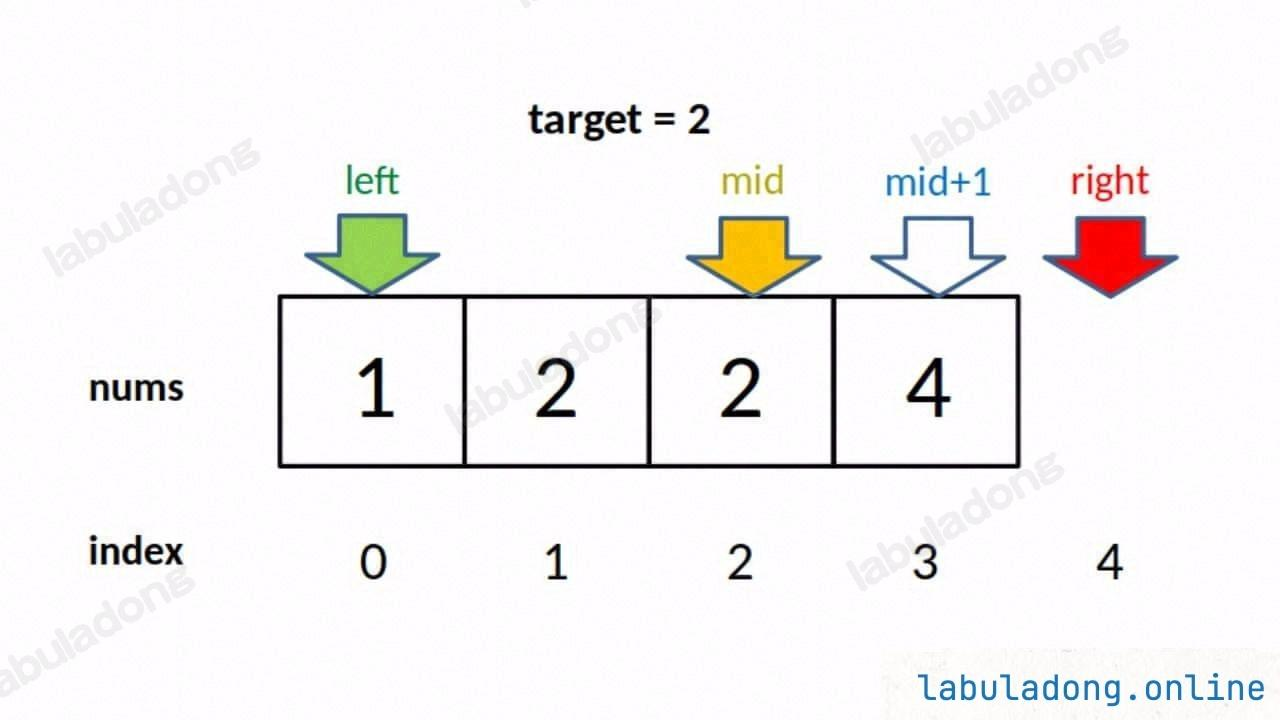
核心:R 是 "不检查的位置",更新时保留候选 mid
- ✅ 循环条件:
L < R(因为[L, R)为空时终止,比如 L=R 时无元素); - ✅ 当
nums[mid] < target:目标在右侧,排除 mid →L = mid + 1; - ✅ 当
nums[mid] > target:mid 是候选,保留 →R = mid(因为 R 不检查,无需 - 1); - ✅ 当
nums[mid] == target:按需处理(找左边界→R=mid / 找右边界→L=mid+1); - ✅ 循环终止后:
L == R,指向候选位置(若 L=len 则说明无符合条件的元素)。
避坑点:
- ❌ 初始 R 不要写
len-1:比如数组长度为 3,R=3(而非 2),才能覆盖「0,1,2」三个元素; - ❌ 当
nums[mid] > target时写R = mid - 1:会排除候选 mid,导致漏查; - ❌ 循环终止后直接返回 L:需先判断 L 是否等于 len(越界则按题意处理,比如返回 0)。
三、通用边界注意事项(所有场景都要遵守)
1. mid 计算:避免溢出,统一写法
无论哪种区间风格,mid 都要写:mid = L + (R - L) / 2(而非 (L+R)/2)。
- 原因:L 和 R 接近 int 最大值时,
L+R会溢出(变成负数),而R-L不会; - 补充:C++ 中也可写
mid = (long long)L + R / 2,但前者更通用。
2. 重复元素的边界处理(找第一个 / 最后一个目标值)
题目要求 "找第一个大于 target 的字符""找第一个等于 target 的下标" 时,核心是「不直接返回 mid,而是收缩区间保留候选」:
- 找第一个≥target 的位置:闭区间风格下,
nums[mid] >= target→R = mid - 1,循环结束返回 L; - 找最后一个≤target 的位置:闭区间风格下,
nums[mid] <= target→L = mid + 1,循环结束返回 R。
3. 越界处理(无符合条件元素时)
- 闭区间:循环结束后 L 可能 = len(比如 target 比所有元素大),R 可能 =-1(比如 target 比所有元素小);
- 左闭右开:循环结束后 L 可能 = len(无大于 target 的元素),需按题意返回(比如返回数组第一个元素)。
4. 死循环排查(边界错误的典型表现)
如果出现死循环,90% 是区间更新规则错误:
- 闭区间下:检查是否写了
L=mid或R=mid(比如 L=2、R=3,mid=2,L=mid 会让 L 永远 = 2); - 左闭右开下:检查是否在
nums[mid] > target时写了R=mid-1(导致 R<L,循环提前终止,或后续死循环)。
四、实战案例:用规则验证边界(以 744 题为例)
题目要求:找大于 target 的最小字符,无则返回第一个字符。
- 选左闭右开风格:
- 初始:L=0,R=len(比如数组长度 3,R=3);
- 循环条件:L < R;
target < letters[mid]→ R=mid(保留候选);target >= letters[mid]→ L=mid+1(排除 mid);- 循环结束:若 L=len(无符合条件),返回 letters 0,否则返回 letters L。
- 错误对比:
- 若初始 R=len-1,循环结束后 L 最大 = len-1,无法判断是否 "所有元素≤target",需额外检查
letters[L] > target; - 若更新 R=mid-1,会漏掉候选 mid,导致返回错误字符。
- 若初始 R=len-1,循环结束后 L 最大 = len-1,无法判断是否 "所有元素≤target",需额外检查
五、总结:边界处理的 "口诀"
- 先定区间(闭 / 左闭右开),再定规则,全程不换;
- 闭区间:L≤R,更新 ±1,终止看 L/R;
- 左闭右开:L<R,R 不 - 1,终止查越界;
- mid 计算防溢出,重复元素不早返;
- 死循环看更新,越界场景提前想。
核心原则:让每一次区间更新都 "排除已确定无关的元素",保留候选元素,边界错误本质是 "要么漏了候选,要么没排除无关元素"。
3 逻辑统一
第一个,最基本的二分查找算法:
bash
因为我们初始化 right = nums.length - 1
所以决定了我们的「搜索区间」是 [left, right]
所以决定了 while (left <= right)
同时也决定了 left = mid+1 和 right = mid-1
因为我们只需找到一个 target 的索引即可
所以当 nums[mid] == target 时可以立即返回第二个,寻找左侧边界的二分查找:
bash
因为我们初始化 right = nums.length
所以决定了我们的「搜索区间」是 [left, right)
所以决定了 while (left < right)
同时也决定了 left = mid + 1 和 right = mid
因为我们需找到 target 的最左侧索引
所以当 nums[mid] == target 时不要立即返回
而要收紧右侧边界以锁定左侧边界第三个,寻找右侧边界的二分查找:
bash
因为我们初始化 right = nums.length
所以决定了我们的「搜索区间」是 [left, right)
所以决定了 while (left < right)
同时也决定了 left = mid + 1 和 right = mid
因为我们需找到 target 的最右侧索引
所以当 nums[mid] == target 时不要立即返回
而要收紧左侧边界以锁定右侧边界
又因为收紧左侧边界时必须 left = mid + 1
所以最后无论返回 left 还是 right,必须减一