目录
基础架构
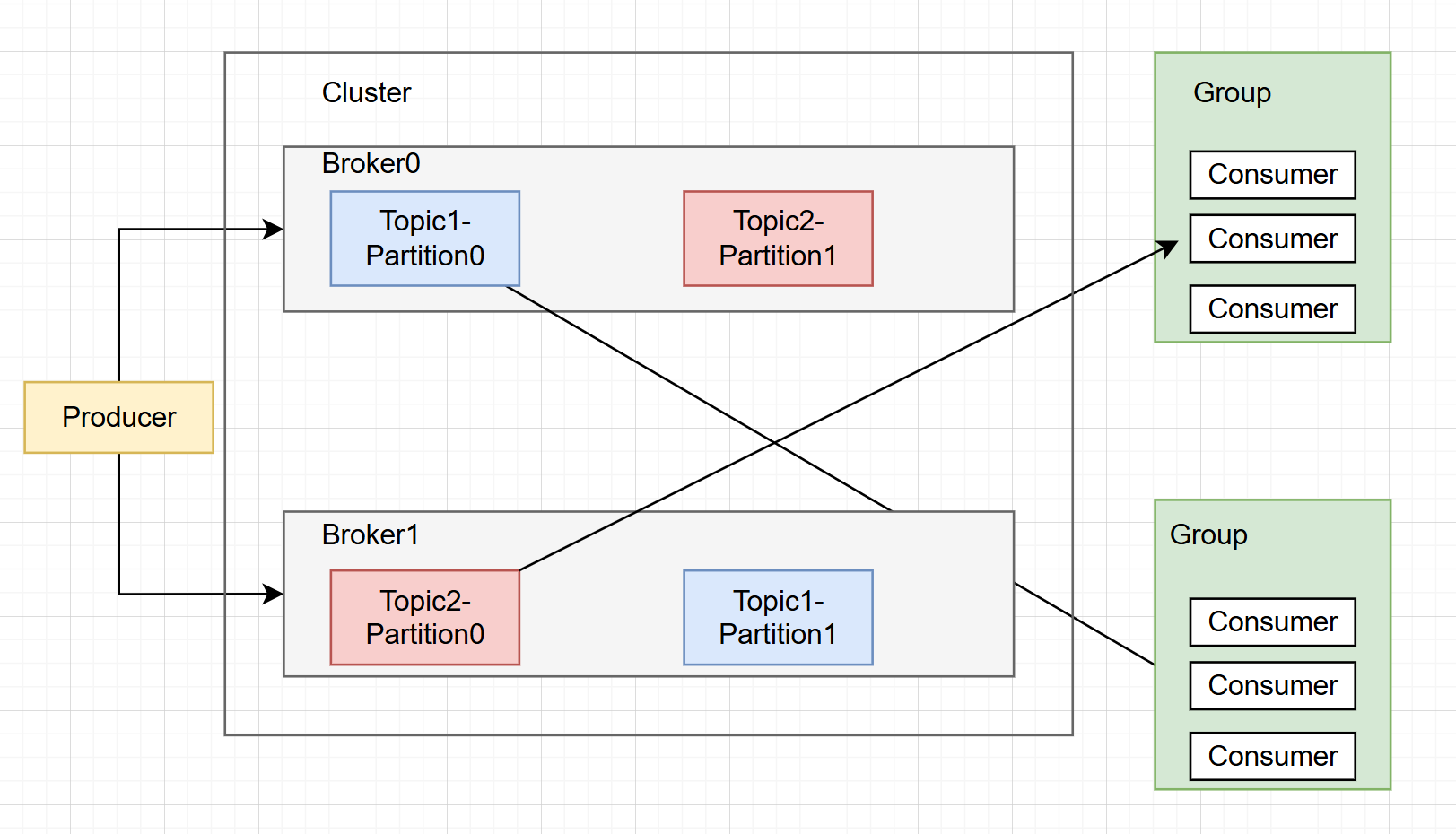
Producer(生产者)
负责将消息发送到 Kafka 集群(Broker 节点)。
- 消息封装:生产者将数据(如日志、事件等)封装成 <Key, Value> 键值对形式的消息。
- 分区策略 :根据消息的 Key 或自定义规则,决定消息发送到Topic 的哪个分区(Partition),以实现负载均衡和顺序性控制。
- 批量发送:通过缓冲区批量发送消息(默认 64KB 或 500ms 触发),提升吞吐量。
- 重试机制:当发送失败时,自动重试(可配置重试次数和间隔)。
Broker
Kafka 集群中的服务器节点,负责存储消息、处理生产者 / 消费者的请求。
- 存储消息 :消息按 **Topic 分区(Partition)**存储在磁盘上,每个分区是有序、不可变的日志文件。
- 副本机制 :每个分区有 1 个 Leader 副本和多个 Follower 副本,Leader 处理读写请求,Follower 同步 Leader 数据,实现高可用。
- 分区管理:由 Controller 节点(集群中选举出的主节点)负责分区 Leader 选举、副本分配等。
- 数据清理:通过日志保留策略(时间或大小)自动删除过期消息,释放磁盘空间。
Consumer(消费者)
从 Kafka 集群订阅并消费消息。
- 消费组(Consumer Group) :多个消费者组成一个消费组,共同消费一个 Topic 的分区,每个分区只能被消费组内的一个消费者消费(避免重复消费)。
- 位移(Offset) :记录消费者已消费的消息位置(保存在
__consumer_offsets内部 Topic 中),支持从指定位置重新消费。 - 消费模式:
-
- 自动提交位移:定期自动提交已消费的 Offset(可能重复消费或丢失消息)。
- 手动提交位移:消费完成后手动提交,确保消息不丢失。
- 再平衡(Rebalance):当消费组内消费者数量变化或分区数量变化时,重新分配分区与消费者的对应关系(可能导致短暂消费停顿)。
Zookeeper
- **集群元数据管理:**记录所有Broker节点的信息,Topic的元数据(名称、分区数量、副本数量、每个分区的 Leader/Follower 副本分布等),消费者组的元数据
- **Broker 集群协调:**Leader的选举,副本故障转移,注册与发现Broker
- **消费者组协调:**记录消费者组信息,实现Rebalance机制
在Kafka2.8以后,Zookeeper逐渐被KRaft模式取代。为什么要取代Zookeeper?
- 性能瓶颈 :ZooKeeper 处理元数据变更的效率有限,当 Kafka 集群规模(Broker/Topic/ 分区数量)过大时,可能成为瓶颈。
- 复杂性 :引入 ZooKeeper 增加了集群部署、维护的复杂度(需单独管理 ZooKeeper 集群)。
- 一致性模型 :ZooKeeper 的强一致性模型与 Kafka 追求的高吞吐需求不完全匹配。
其他
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服 务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower。
- Leader:每个分区多个副本的"主",生产者发送数据的对象,以及消费者消费数 据的对象都是 Leader。
- Follower:每个分区多个副本中的"从",实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
启动Kafka
安装
进入官网https://kafka.apache.org/可以下载最新版本的Kafka,接下来讲解如何在Linux部署Kafka。
$ tar -xzf kafka_2.13-4.1.0.tgz
$ cd kafka_2.13-4.1.0
本地启动
此版本需要JDK17+。
生成集群 UUID
KAFKA_CLUSTER_ID="(bin/kafka-storage.sh random-uuid)"
格式化日志目录
bin/kafka-storage.sh format --standalone -t KAFKA_CLUSTER_ID -c config/server.properties
启动Kafka服务器
$ bin/kafka-server-start.sh config/server.properties
Docker部署
获取 Docker 镜像:
$ docker pull apache/kafka:4.1.0
启动 Kafka Docker 容器:
$ docker run -p 9092:9092 apache/kafka:4.1.0
创建Topic
创建Topic
$ bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
接下来就可以通过Kafka发送和消费消息了。
发送与消费消息
Kafka 客户端通过网络与 Kafka Broker 通信,以写入(或读取)消息。一旦收到消息,Broker 就会将消息持久化到磁盘,存储时间可根据需要延长,甚至永久保存。
运行控制台生产者客户端,将一些事件写入Topic。默认情况下,输入的每一行都会将一个单独的事件写入主题。
$ bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
>This is my first event
>This is my second event
Ctrl-C可以随时停止生产者客户端。
打开另一个终端会话并运行控制台消费者客户端来读取刚刚创建的事件:
$ bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092 This is my first event This is my second event