💬 :如果你在阅读过程中有任何疑问或想要进一步探讨的内容,欢迎在评论区畅所欲言!我们一起学习、共同成长~!
👍 :如果你觉得这篇文章还不错,不妨顺手点个赞、加入收藏,并分享给更多的朋友噢~!
1. MySQL CRUD 核心操作
MySQL 表的增删改查简称 CRUD,依次对应Create(插入数据)、Retrieve(查询数据)、Update(更新数据)、Delete(删除数据) ,面试中常要求手写对应 SQL。
1.1 Create(插入数据)
1.1.1 基础插入通用语法
sql
insert [into] 表名 [(列1, 列2, ...)] values (值列表1) [, (值列表2), ...];
-- []表示可选1.1.2 单行插入
-
全列插入可省略列名
-
指定局部列插入不可省略列名
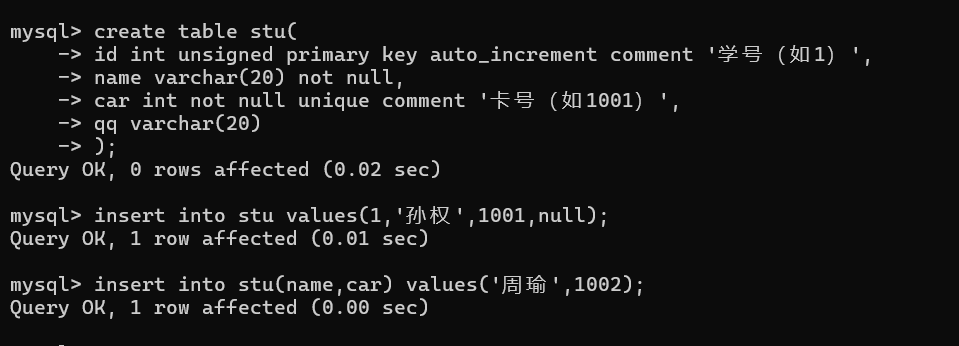
1.1.3 多行插入
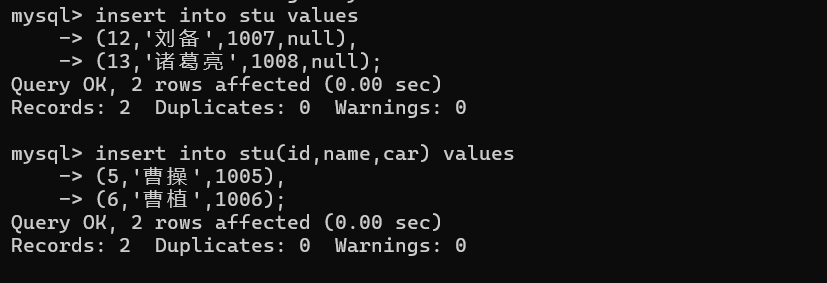
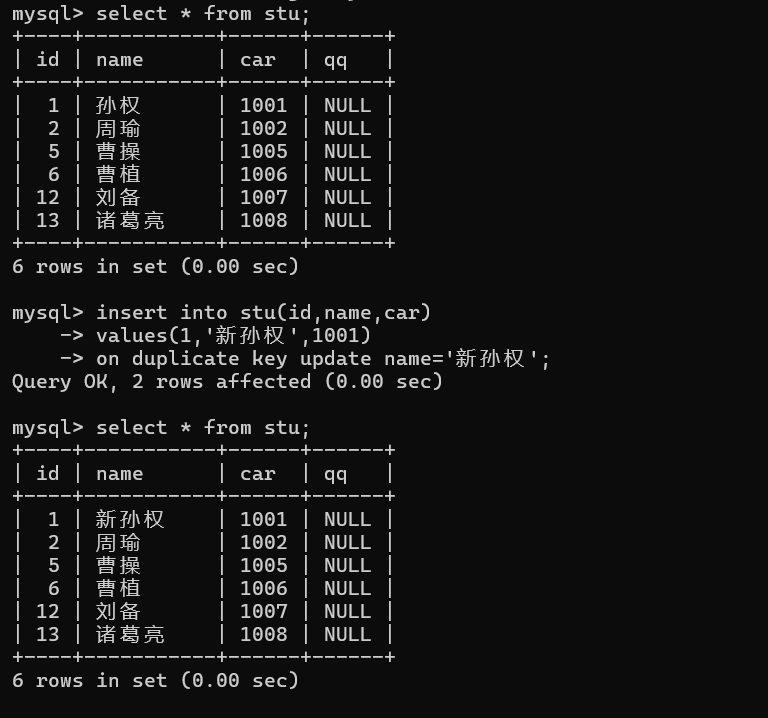
1.1.4 插入否则更新(面试高频)
插入数据含主键 / 唯一键的重复值时会报错,可以用以下语法更新待插行一些列的值:
sql
insert into 表名(列1, 列2, ...)
values(值1, 值2, ...) -- 待插数据
on duplicate key update 列A=新值A[, 列B=新值B,...];
-- 新值与待插数据中的一致主键 id 和唯一键 car 都插入重复:
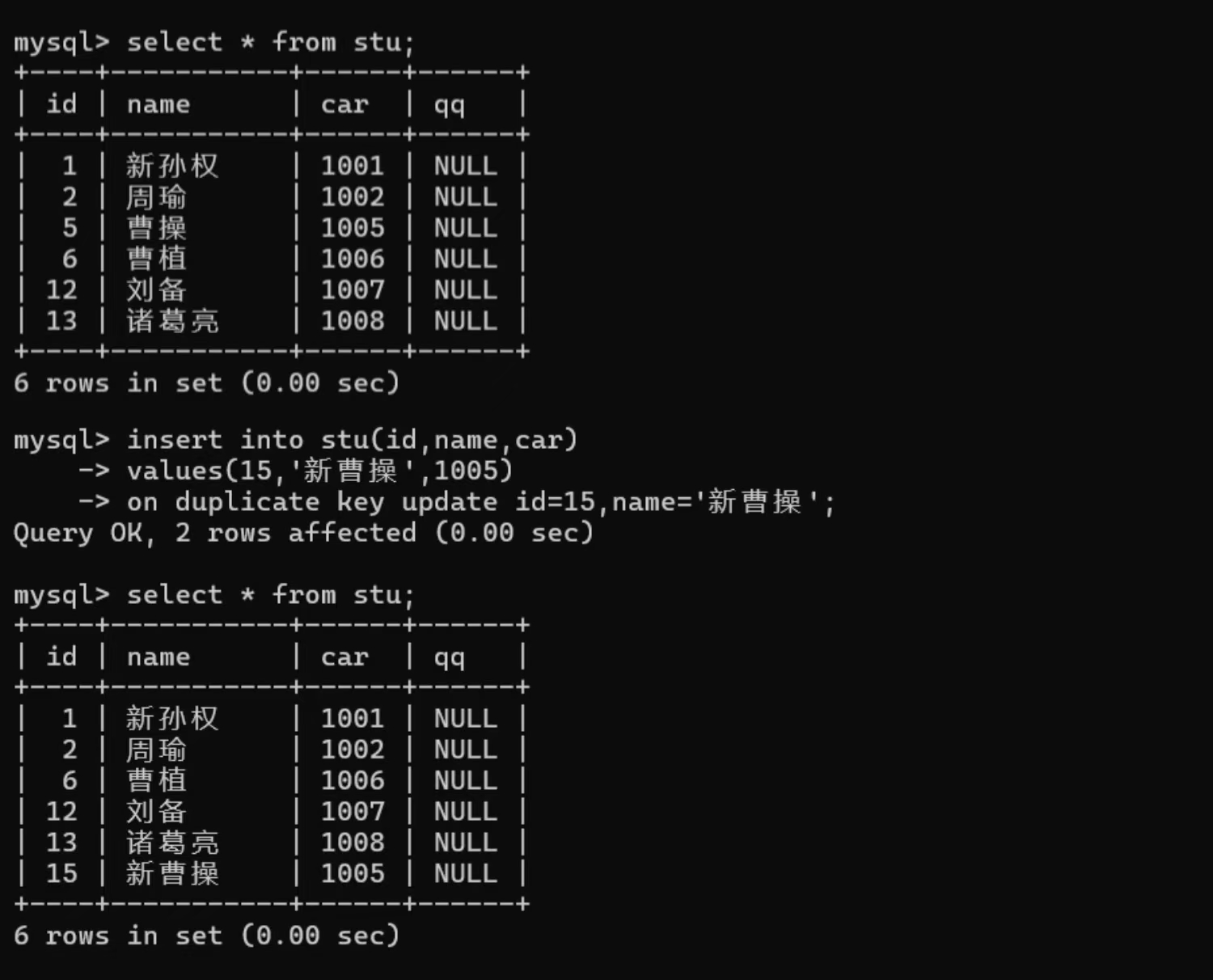
仅唯一键 car 插入重复:
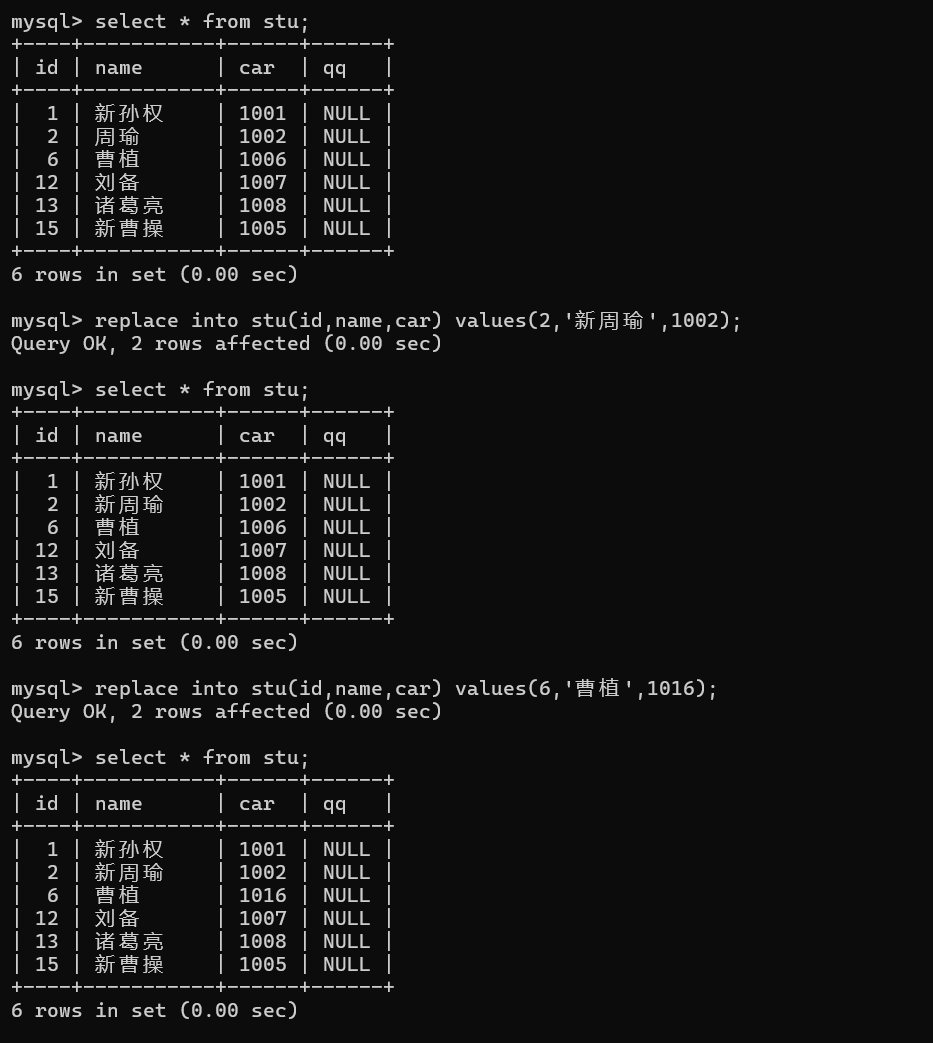
1.1.5 替换插入
插入数据含主键 / 唯一键的重复值时,可以先删除原行数据再插入新数据。
语法是将插入语句的 insert 换成 replace :
1.2 retrieve(数据查询)
1.2.1 基础列查询(必背)
全列查询(不推荐)
sql
select * from 表名;-
* 是通配符,表示表中所有列。
-
数据传输量大,,降低查询效率(尤其大表)。建议明确指定需要的列 ,而非滥用
*。
指定列查询
(顺序可自定义)
sql
select 列1,列2,... from 表名;表达式查询
sql
select 表达式 [as 别名] from 表名;- 表达式为"字段1+字段2"或"字段+常数"或"常数+常数"。
- 别名是表达式结果列的名称。
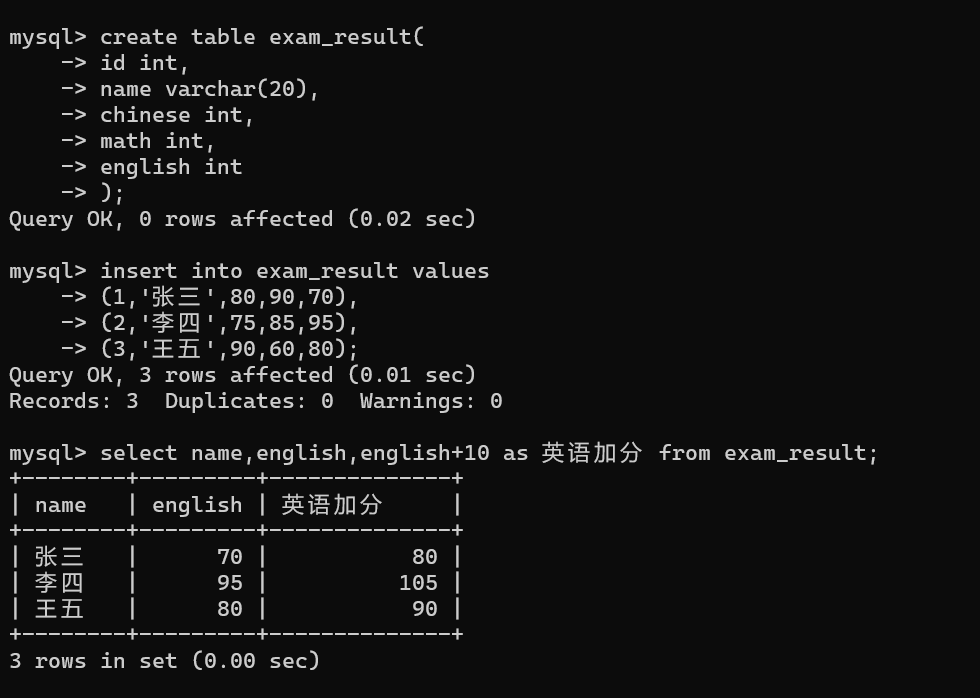
现在建一个含学号、姓名和语数英成绩的表,然后实操展示------
(1)单字段计算(字段+常数)
需求:查询每个学生的姓名、英语成绩,并计算 "英语成绩 + 10 分" 的加分后的结果,命名为 "英语加分"。
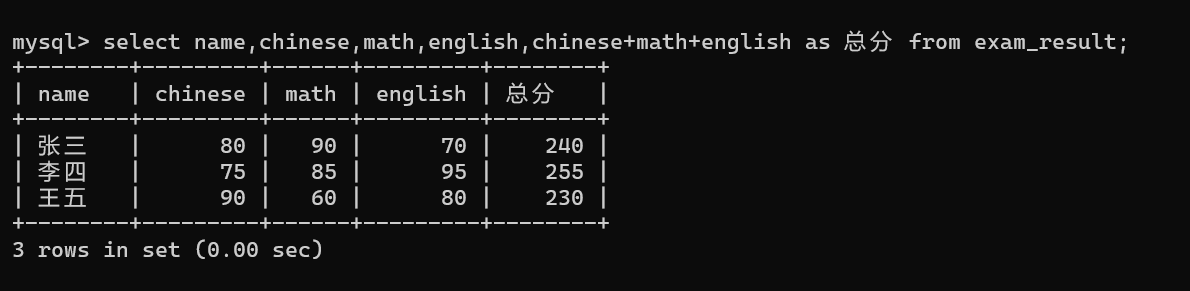
(2)多字段计算(字段 1 + 字段 2+...)
需求:查询每个学生的姓名,并计算 "语文 + 数学 + 英语" 的总分,命名为 "总分"。
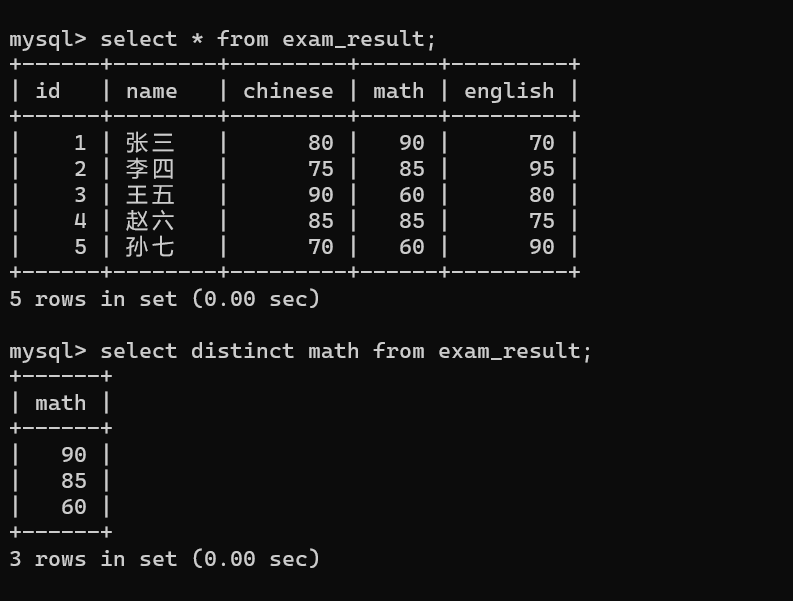
去重查询
使用 distinct 关键字排除查询结果中指定列的重复值,仅保留唯一值:
sql
select distinct 列名 from 表名;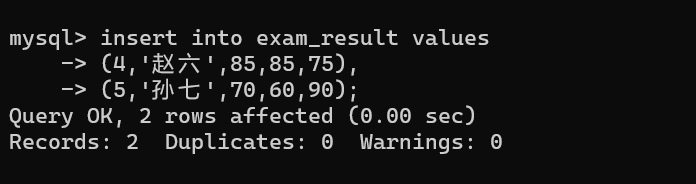
1.2.2 where 条件过滤(面试高频)
以下表格中标为红色表示【常用】
比较运算符
| 运算符 / 语法 | 作用描述 | 示例代码 |
|---|---|---|
= |
等于 | select * from stu where name='新孙权'; |
!=或<> |
不等于 | select * from exam_result where math != 85; |
< > |
小于 大于 | select name, car from stu where car>1005; |
<= >= |
小于等于 大于等于 | select name, math from exam_result where math<=85; |
列名 BETWEEN a AND b |
某列在 a, b 范围内 | select name, chinese from exam_result where chinese between 75 and 85; |
列名 IN (值1, 值2...) |
匹配括号中的任意值 | select * from stu where id in(2, 6, 15); |
列名 NOT IN (值1...) |
不匹配括号中的任何值 | select name from exam_result where id not in(1, 3); |
逻辑运算符
| 运算符 | 作用描述 | 示例代码 | |
|---|---|---|---|
AND |
同时满足多个条件(逻辑与) | 建议用括号明确优先级 | select * from stu where car>1001 and name like '新%'; |
OR |
满足任意一个条件(逻辑或) | 建议用括号明确优先级 | select * from stu where id=6 or name like '新%'; |
NOT |
否定条件(逻辑非) | 建议用括号明确优先级 | select name, math from exam_result where not math=85; * not math = 等价于 math != |
null 判断
| 语法 | 作用描述 | 示例代码 |
|---|---|---|
IS NULL |
判断字段值为 NULL * 不能用 qq = null(NULL 与任何值比较结果都为 NULL) |
select name, qq from stu where qq is null; |
IS NOT NULL |
判断字段值不为 NULL * 同理,不能用 qq != null * 适用于筛选有实际值的记录 |
select name, qq from stu where qq is not null; |
<=> |
安全比较(可判断 NULL 是否相等) | select name, qq from stu where qq <=> null; |
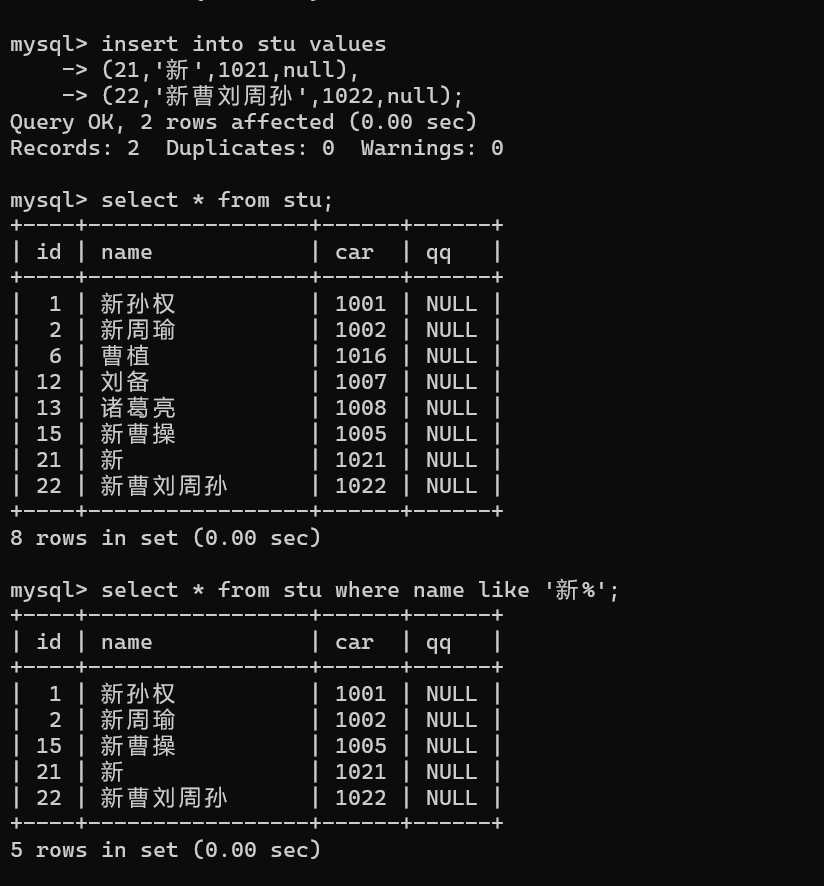
模糊查询(like)
| 作用描述 | 示例代码 | ||
|---|---|---|---|
| 通配符 | % |
匹配 0 个或多个任意字符 * % 可放在字符的开头 / 中间 / 结尾 |
select * from stu where name like '新%'; |
| 通配符 | _ |
匹配 1 个任意字符 * _ 可放在字符的开头 / 中间 / 结尾;有几个_就匹配几个字符 | select * from stu where name like '新_权'; |
NOT LIKE |
不匹配模糊条件 | select name from exam_result where name not like '张%'; |
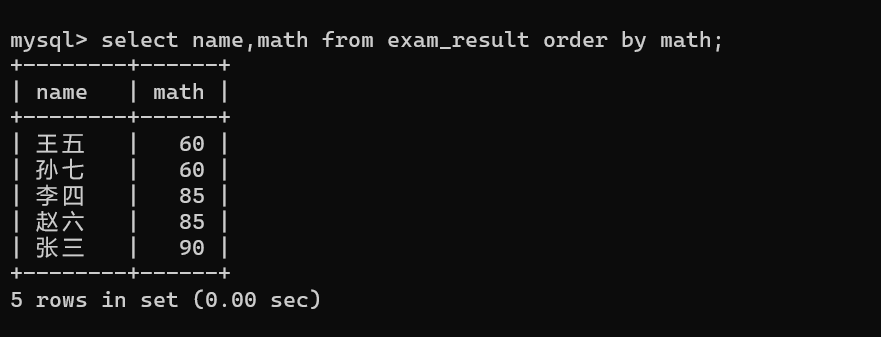
1.2.3 结果排序(order by)
sql
order by 列1 [asc/desc], 列2 [asc/desc]-
asc 升序
-
desc 降序
-
\[\]表示可选,不指明时默认升序
单字段排序
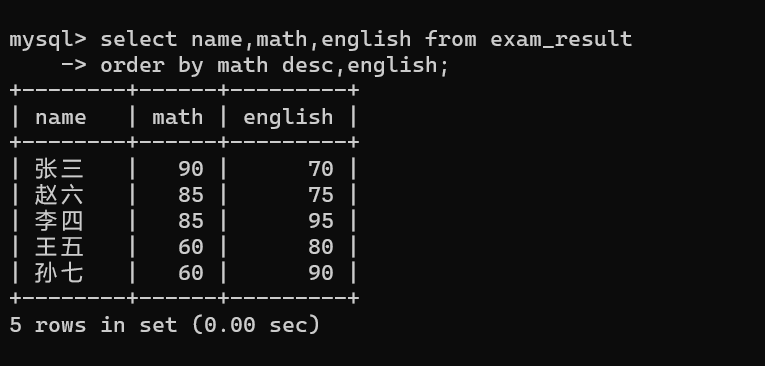
多字段排序(优先级从前到后)
- 先按第一个字段排序,若第一个字段的值不完全相同,直接按第一个字段排序;
- 只有当第一个字段的所有值完全相同时,才会按第二个字段排序;
- 若前两个字段的所有值都分别相同,再按第三个字段排序,以此类推。
按表达式排序
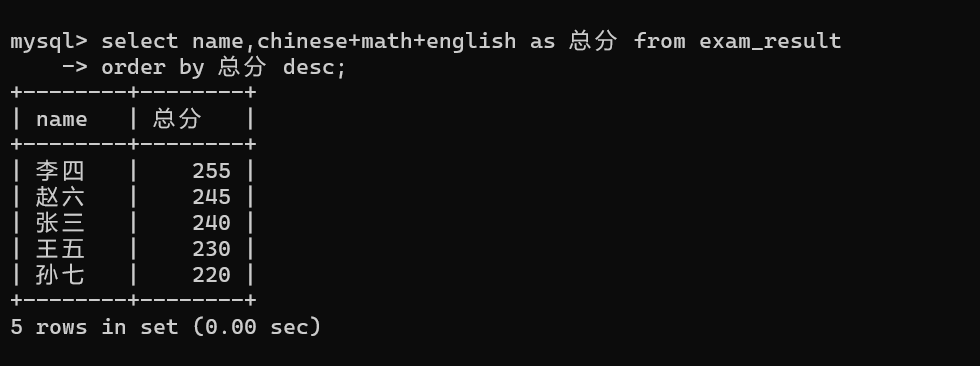
- 别名可在order by中使用,但不可在where语句中使用。
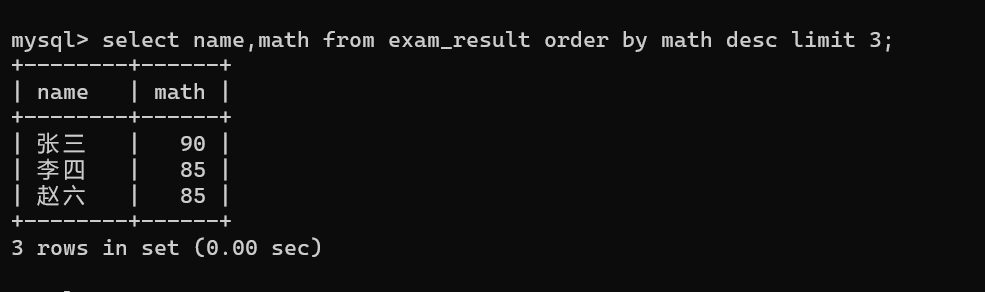
1.2.4 分页查询(limit,面试必背)
- 起始下标从 0 开始
第1条(下标0)开始查询
sql
select ... from 表名 [where 筛选条件] order by ... limit 条数;示例:
指定起始下标查询
sql
select ... from 表名 [where 筛选条件] order by ... limit 条数 offset 起始下标;
-- 传统写法为 select ... from 表名 [where 筛选条件] order by ... limit 起始下标,条数;
-- 推荐前者,offset明确标识 "起始偏移量",语义更清晰,避免混淆参数顺序- 特殊情况:若 "起始下标 + 条数" >表中总记录数,仅返回剩余的所有记录,不会报错
- 起始下标 = (目标页码 - 1)× 每页条数
示例:
sql
select name,math from exam_result order by math limit 5 offset 3;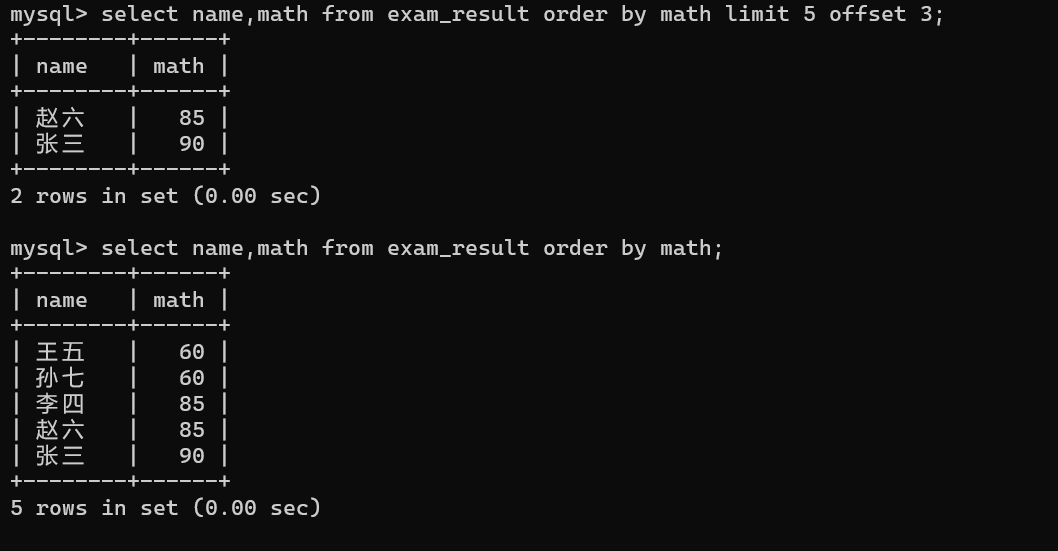
这里相当于第1页有3条记录,查询第2页的数据。
注意
分页查询一定要用 order by,原因:
MySQL 对未加 order by 的查询,返回顺序由存储引擎的底层存储逻辑、查询执行计划等动态决定,属于 "未定义行为"。如果不用order by固定底层返回顺序,多次执行分页查询后,可能出现 "漏查数据" 或 "重复查数据"。
1.3 update(数据更新)
重点掌握 "条件更新""批量更新",避免误更新全表(面试会提醒慎用全表更新)。
1.3.1 常见更新场景(必背代码)
更新单字段
sql
update 表名 set 列名=新值 where 筛选条件;- 若没有where语句,对象就是指定列全列
- 。
示例:
sql
update exam_result set chinese=81 where name='张三';更新多字段
sql
update 表名 set 列名1=新值1,列名2=新值2[,...] where 筛选条件; 示例:
sql
update exam_result set math=87,english=99 where name='李四';基于表达式更新
sql
update 表名 set 列名=字段运算表达式 [order by ...] [limit 条数] where 筛选条件;- 字段运算表达式如"字段1+字段2"或"字段+常数"------MySQL 不支持
math+=30或``chinese*=2这类简化写法,必须写完整math = math + 30。 - order by ... 使得按指定规则排序后再更新。
- limit 条数 限制仅更新前n条。
示例:按总分排序取前3给数学加10分
sql
update exam_result set math=math+10 order by chinese+math+english limit 3;1.4 delete(数据删除)
1.4.1 常见删除场景(必背代码)
删除指定数据
sql
delete from 表名 where 筛选条件;- 若没有where语句会删除表中所有数据。
删除全表数据(慎用)
sql
delete from 表名;- 自增字段不重置 :删除后表的自增字段不会回到初始值,而是延续原最大值------原最大 id 为 n(=下一次插入前自增计数器的值),delete全删后不指定 id 插入时,取"自增计数器值和表中现在最大值的较大者"+1。
示例:
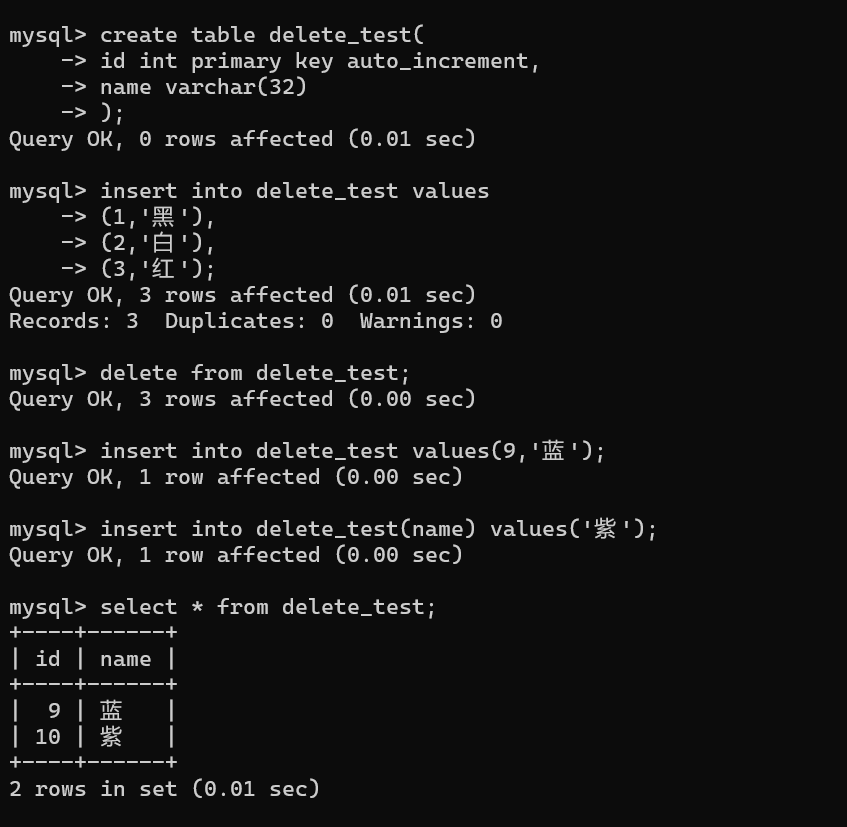
不指定插入时自增计数器值为 3 < 表中最大值 9,所以取 9+1。
再次delete全删:
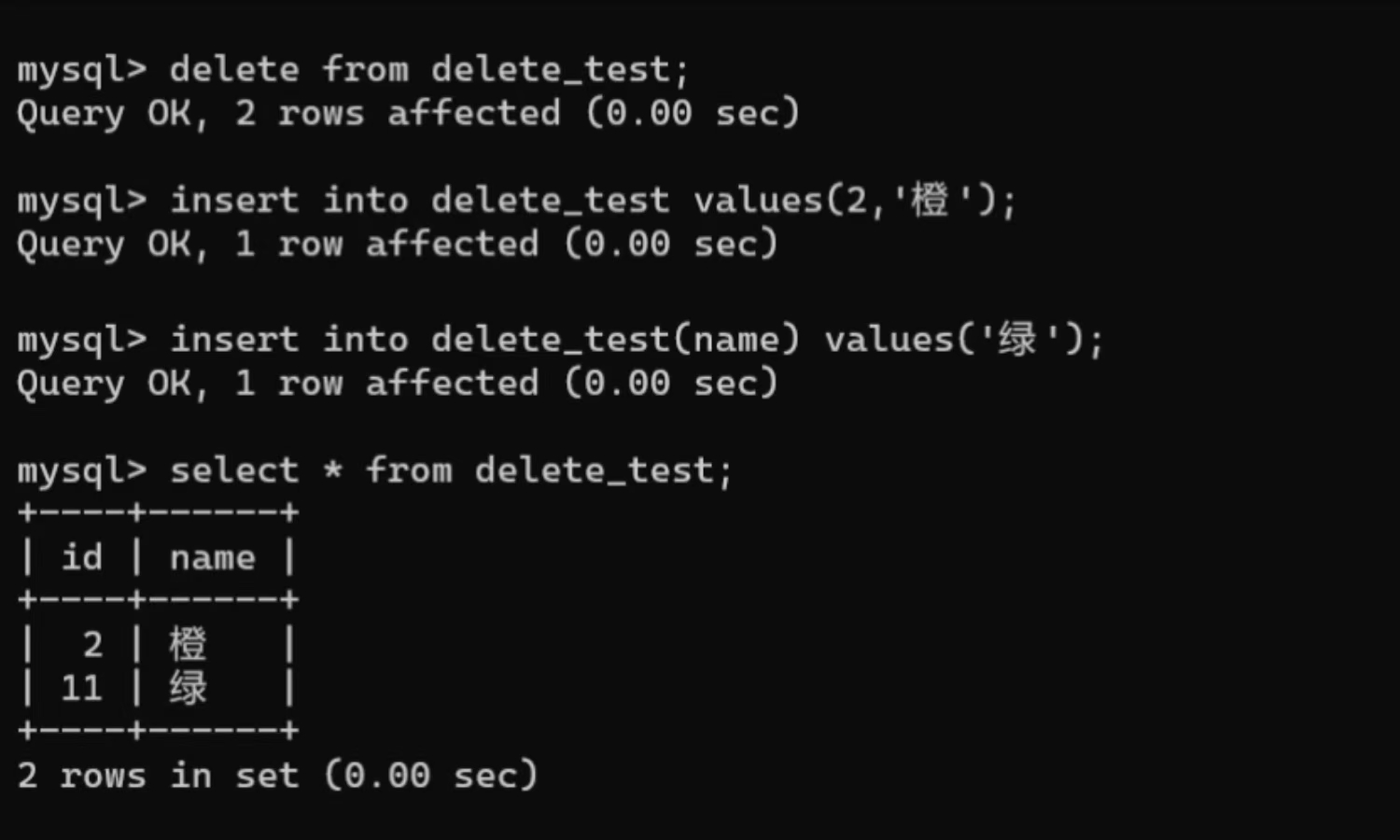
不指定插入时自增计数器值为 10 > 表中最大值 2,所以取 10+1。
截断全表(truncate)
sql
truncate table 表名;- 无法加
where条件筛选,只能清空表中所有数据,不能删除部分记录。 - 其自主计数器重置为初始值(MySQL 中默认是 1)------相当于删掉原表、再按原结构重建一张空表。
1.4.2 delete vs truncate(面试高频)
| 对比维度 | delete | truncate |
|---|---|---|
| 操作粒度 | 可删除部分 / 全表 | 仅能删除全表 |
| 自增字段 | 不重置 | 重置为初始值(MySQL 中默认是 1) |
| 事务支持 | 支持回滚(属于 dml) | 不支持回滚(属于 ddl) |
| 执行效率 | 慢(逐行删除) | 快(直接清空表结构) |
回滚就是数据库里撤销刚做的错误操作(比如误删、误改数据),让数据回到操作前样子的功能。
- delete 是删表中具体数据(属于操作数据的 DML),删错了能通过回滚恢复;
- truncate 是清空表数据还重置表结构(属于操作表结构的 DDL),执行后没法用回滚恢复。
2. 聚合函数与分组查询(统计类面试题)
C++ 面试中常考 "统计数据",如 "求平均成绩""按部门统计工资",需掌握聚合函数 + group by。
2.1 常用聚合函数(必背)
| 函数 | 作用 | 无符合条件的数据时 | |
|---|---|---|---|
| count (distinct 列) | 支持通过 distinct 先排除指定列的重复值 |
* 统计行数(不为null的行 ) * count(*)统计表中所有行(包括为null的行) |
返回0 |
| sum (distinct 列) | 支持通过 distinct 先排除指定列的重复值 |
* 对数字类型的指定列进行求和计算 | 返回null |
| avg (distinct 列) | 支持通过 distinct 先排除指定列的重复值 |
* 对数字类型的指定列或数字表达式(由数字类型的列、常数、算术运算符组成,如多列求和)计算平均值,非数字类型无意义 | 返回null |
| max (distinct 列) | 支持通过 distinct 先排除指定列的重复值 |
* 从指定列的数值中选出最大值 | 返回null |
| min (distinct 列) | 支持通过 distinct 先排除指定列的重复值 |
* 从指定列的数值中选出最小值 | 返回null |
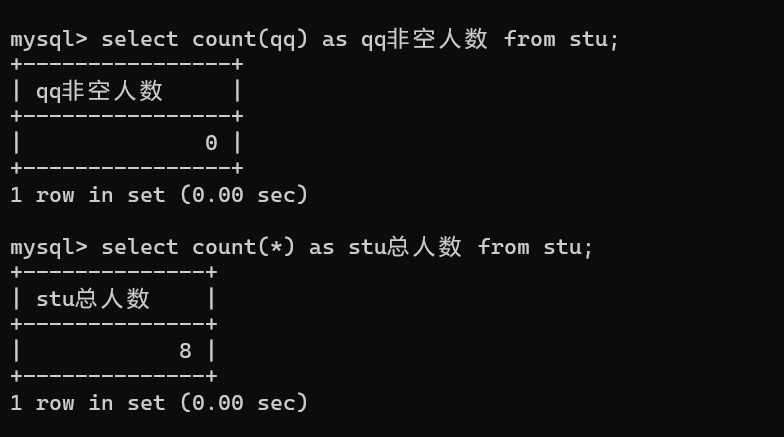
2.1.1 count 示例
2.1.2 sum 示例
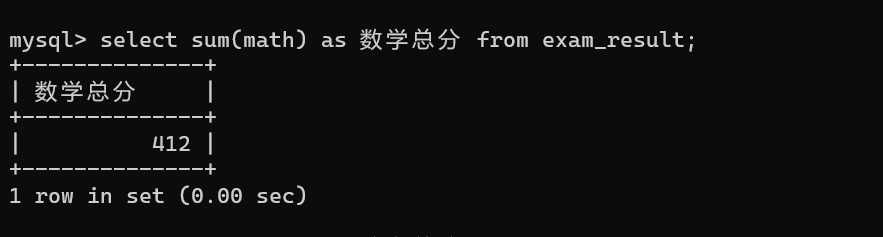
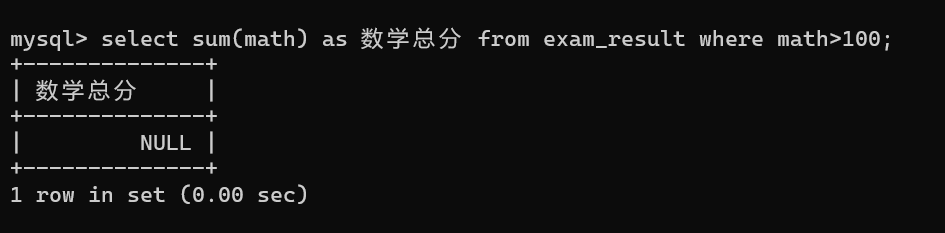
求stu表里math列中大于100的值之和:
2.1.3 avg 示例
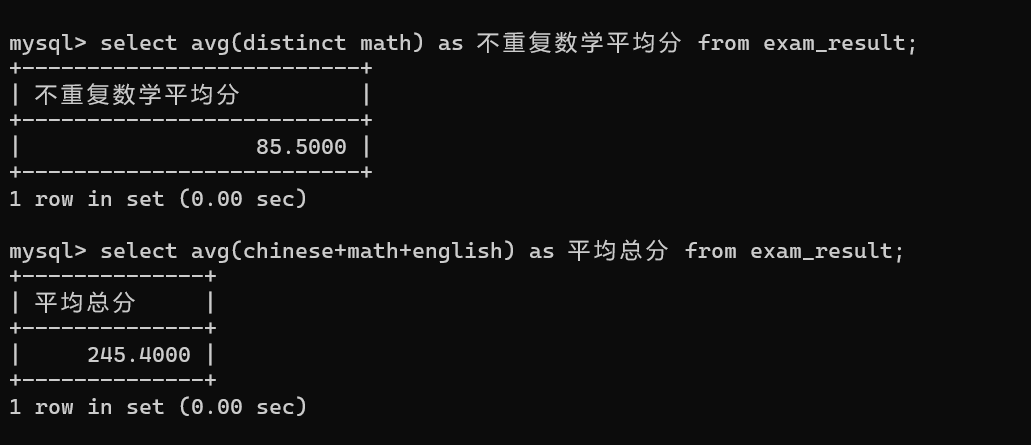
2.1.4 max / min 示例
sql
select max(english) as 英语最高分 from exam_result;
-- 结果:
+-----------------+
| 英语最高分 |
+-----------------+
| 99 |
+-----------------+
select min(chinese) as `>80的语文最低分` from exam_result where chinese>80;
-- 结果:
+-----------------------+
| >80的语文最低分 |
+-----------------------+
| 81 |
+-----------------------+
-- 别名若含特殊字符/与关键字重名/数字开头如123分,需用反引号``或双引号包裹2.2 group by 分组查询(面试高频)
2.2.1 基础分组语法
sql
select 分组列 [别名], 聚合函数名(列名) [别名] -- 别名前的as可有可无
from 表名
[where 行过滤条件] -- 分组前过滤行(不能用聚合函数)
group by 分组列 -- 有多个分组列时,先按第一个分组,再依次按后面的分组
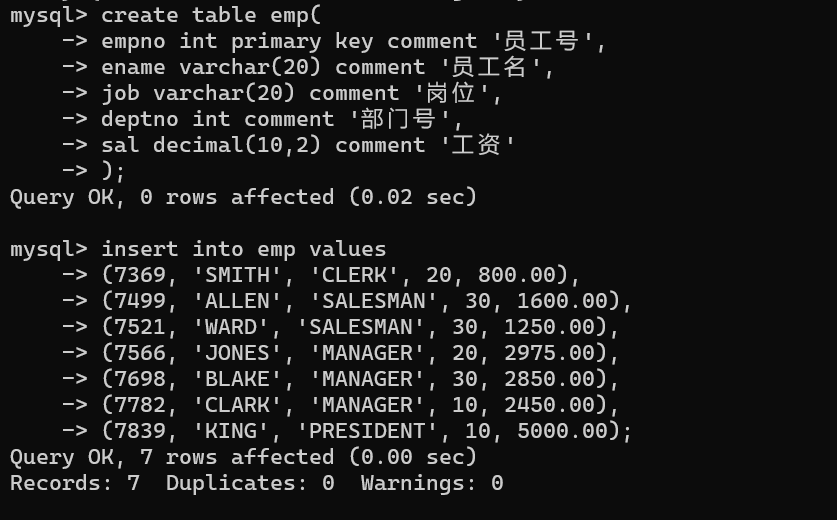
[having 分组过滤条件]; -- 分组后过滤分组(可用聚合函数/聚合函数结果)2.2.2 经典案例:员工表(必背代码)
以emp表(含 job 岗位、deptno 部门号、sal 工资)为例:
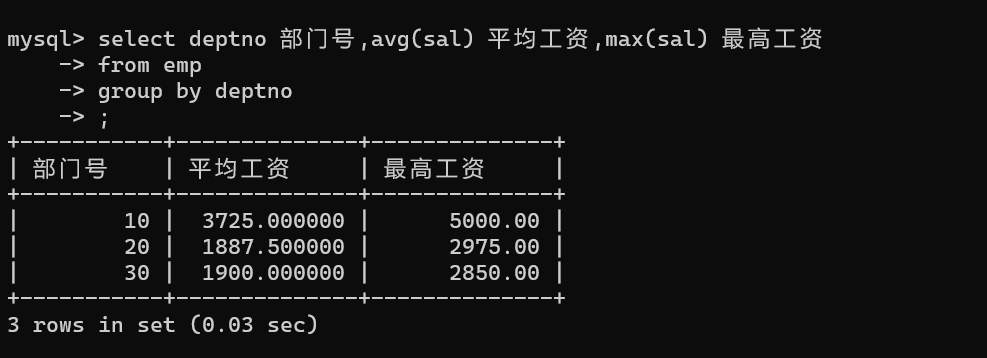
统计各部门平均工资和最高工资
统计每个部门各岗位的平均工资
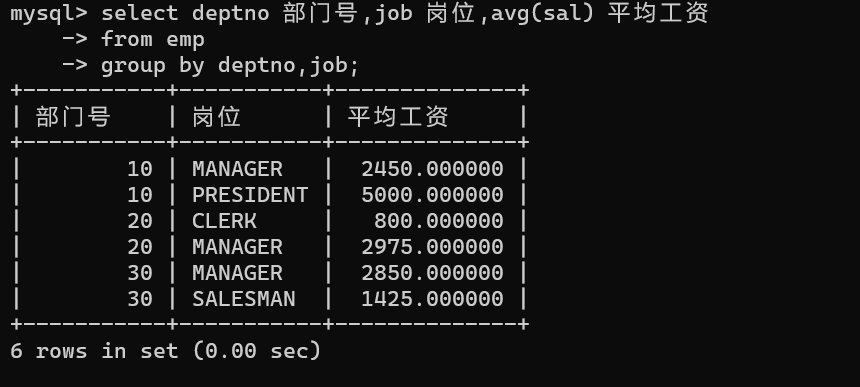
- 有多个分组列时,先按第一个分组,再依次按后面的分组。
过滤分组结果(having)
统计平均工资低于2000的部门:
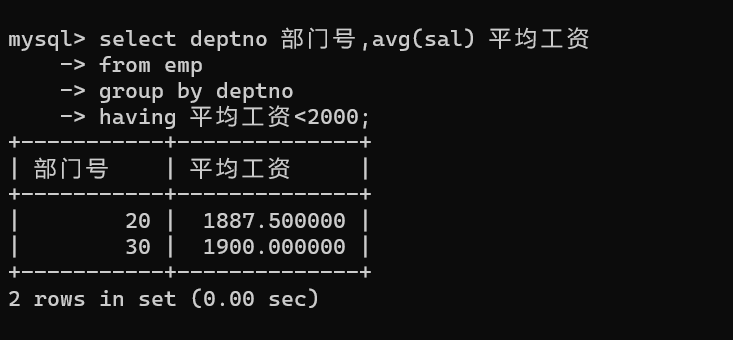
关键区别:
- where:分组前过滤行(不能用聚合函数,如
where avg(sal)<2000错误); - having:分组后过滤分组(可使用聚合函数 / 聚合函数结果)。
3. C++ 面/笔试高频考点总结
3.1 必背核心代码(直接默写)
- 插入冲突处理:
insert ... on duplicate key update; - 分页查询:
select ... order by ... limit n offset s; - 聚合统计:
count(*)/avg(表达式)/max(列); - 分组过滤:
group by ... having 聚合条件; - 删除与截断区别:
delete(回滚、自增不重置)vstruncate(不回滚、自增重置)。
3.2 易混淆考点(面试必答)
- null 判断:必须用
is null,不能用=;null <=> null结果为 1(安全比较); - 别名使用:where 中不能用别名,order by/having 中可以用;
- 排序与分页顺序:必须先
order by,再limit(否则分页结果混乱)。
3.3 常见面试题(实战)
-
问:如何批量插入数据并处理主键冲突?
答:用insert ... on duplicate key update(冲突更新)或replace(冲突删除后插入)。 -
问:如何统计 "语文成绩> 80 且不姓孙" 的同学数量?
答:select count(*) from exam_result where chinese>80 and name not like '孙%'; -
问:delete 和 truncate 删除全表的区别?
答:(分点答自增 id、事务支持、执行效率,参考 1.4.2 表格)。