目录
一、形象的比喻
我先用一个简单的比喻来解释,保证你一听就懂!
用一个"图书馆"的比喻来理解
我们把数据库想象成一个图书馆,里面放着很多书(数据),你要去查书或者存书(读写数据)。
普通数据库(如 MySQL)
就像一个"小书摊"或者"私人书房"。
-
所有书都在一个地方:所有的书都放在一个小书架上。你想找什么书,都只能去这一个小书摊找。
-
一个管理员:只有一个老板(服务器)负责帮你查书、存书。他忙得过来的时候,速度很快。
-
会遇到的问题:
-
人一多就排队:如果来查书的人(用户访问量)突然暴增,老板就忙不过来了,大家只能排队等着,速度变得非常慢。
-
书太多放不下 :如果你的书(数据量)越来越多,一个小书架根本放不下,你就得换更大的书架,这很麻烦而且成本高(这叫垂直扩展,升级硬件)。
-
风险高 :万一这个小书摊着火(服务器宕机)或者老板生病了,整个书摊就关门了,谁也看不了书(服务不可用)。
-
小结:普通数据库简单、好用,但当数据量或访问量太大时,就会成为瓶颈和单点故障风险。
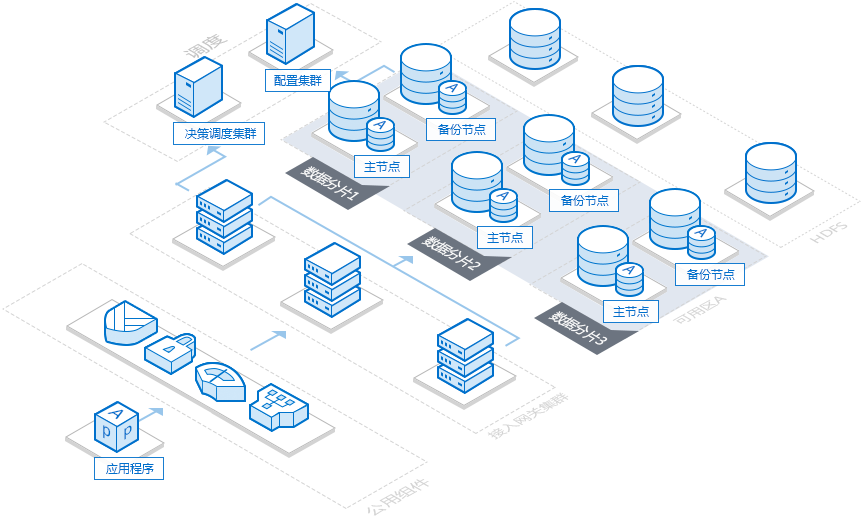
分布式数据库(如 TiDB)
就像一个"超大型现代化图书馆"。
-
书分在很多书架上:图书馆把所有的书复制成多份,然后分散地放在很多很多个书架(服务器节点)上。比如《三国演义》这本书,可能在1号、3号、5号书架上都有。
-
有很多管理员 + 一个总指挥:
-
每个书架都配有一个专门的图书管理员。
-
还有一个总指挥台,它知道哪本书在哪个书架上。
-
-
它是如何工作的:
-
你想借《三国演义》,你先问总指挥。
-
总指挥一看,告诉你:"去3号书架,那里的管理员现在最闲。"
-
你直接去找3号管理员,他很快就把书给你了。
-
-
它的巨大优势:
-
不怕人多 :因为有很多管理员同时工作,可以接待成千上万的读者,不会排队。(高并发)
-
书再多也放得下 :书太多了怎么办?简单,直接往图书馆里加新的书架 就行了(这叫水平扩展,加机器)。
-
非常安全可靠 :万一3号书架着火了(一台服务器宕机),没关系!因为1号和5号书架上还有《三国演义》的副本,总指挥会直接让你去那边拿。图书馆照常营业!(高可用)
-
小结:分布式数据库通过"人多力量大"的方式,把数据和 workload 分散到多台机器上,从而解决了大数据量、高并发和单点故障的问题。
一句话总结
普通数据库是"一个巨人在扛所有担子",而分布式数据库是"一支训练有素的蚂蚁军团在协同搬运"。
当担子轻的时候,巨人效率很高;但当担子变得无比沉重时,只有蚂蚁军团才能胜任。
相信通过上面的例子大家已经大概了解分布式数据库与传统数据库相比的优势了!
二、专业解释
分布式数据库,即所谓的NewSQL。主要代表TiDB(pingcap)、OceanBase(蚂蚁)、Spanner(google)。与传统关系型数据库相比:
-
性能高:在亿级别以上,读和写都会高于传统关系型数据库(MySQL、SQLServer等),在亿级别以下略逊色与传统关系型数据库。
-
可维护性:TiDB、OceanBase都以开源的形式存在,其生态也比较贴近于现代数据库的需求(如完全支持云原生),有较好的社区文档、企业免费的培训课程
-
可靠性:由于分布式的特性,通过副本冗余的方式提升整个集群可靠性。同样由于分布式的特性,无法严格且完全的实现真正意义上的ACID,从事务的角度来看可靠性降低了。
-
可扩展性:分布式的特性就在于近乎无限的水平可扩展,增加集群节点数量可大幅度提高集群的QPS和存储能力。Spanner甚至实现了全球部署。
-
用户体验:兼容大部分SQL标准,但也是由于分布式的原因,很多传统关系型数据库的特性(SQL语法、其他功能)无法支持,如:无法保证自增id的连续性,有限的支持事务的强一致性(对性能略有损失),天生分布式不支持单机部署(小型业务无法使用)。
三、国内数据库排行
这是最新10月国产数据库流行度排行榜,大名鼎鼎的TiDB只排到了第八名!
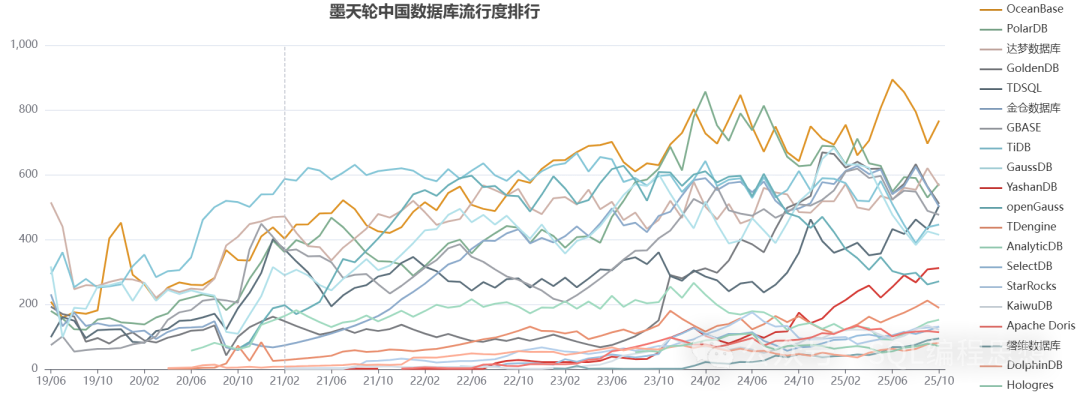
一共有170多款国产数据库参与了排名,这个排名参考了搜索引擎、趋势参数、资质参数、核心案例数、专利数论文数、招聘岗位数以及相关其他的数据。
像大名鼎鼎的TiDB虽然进入了前十,但并不在前五之列,只排到了第八名,而前五名分别是:
-
第五名 TDSQL:腾讯云推出的一个分布式数据库
-
第四名 GoldenDB:中兴旗下一个子公司自主研发的一个国产数据库,银行运营商用的多。
-
第三名 达梦:国央企用的多
-
第二名 PolarDB:阿里推出
-
第一名 OceanBase :蚂蚁推出