目录
[1. 编译环境准备](#1. 编译环境准备)
[1.1 软件下载](#1.1 软件下载)
[1.2 解压与权限配置](#1.2 解压与权限配置)
[1.3 环境变量配置](#1.3 环境变量配置)
[2. Spark 3.5.7 源码编译](#2. Spark 3.5.7 源码编译)
[2.1 修改 Maven 配置](#2.1 修改 Maven 配置)
[2.2 修改编译脚本](#2.2 修改编译脚本)
[2.3 执行编译](#2.3 执行编译)
[3. Spark 3.5.7 客户端部署与集成](#3. Spark 3.5.7 客户端部署与集成)
[3.1 单节点安装包分发](#3.1 单节点安装包分发)
[3.2 基础配置初始化](#3.2 基础配置初始化)
[3.3 配置 spark-env.sh (关键)](#3.3 配置 spark-env.sh (关键))
[3.4 配置 spark-defaults.conf](#3.4 配置 spark-defaults.conf)
[4. 脚本封装](#4. 脚本封装)
[4.1 创建 spark-sql-3.5](#4.1 创建 spark-sql-3.5)
[4.2 创建 spark3-submit](#4.2 创建 spark3-submit)
[4.3 赋权与注册](#4.3 赋权与注册)
[5. 功能验证](#5. 功能验证)
[5.1 Spark Pi 测试 (验证 YARN 调度)](#5.1 Spark Pi 测试 (验证 YARN 调度))
[5.2 SQL 与 Hive 互通测试](#5.2 SQL 与 Hive 互通测试)
[5.3 Paimon 读写测试](#5.3 Paimon 读写测试)
[5.4 Hive sql on spark对Paimon表的操作](#5.4 Hive sql on spark对Paimon表的操作)
[5.4.1 更新数据](#5.4.1 更新数据)
[5.4.2 删除数据](#5.4.2 删除数据)
[5.4.3 插入数据](#5.4.3 插入数据)
[5.4.4 查看表结构](#5.4.4 查看表结构)
[5.5 spark sql 对paimon表的操作](#5.5 spark sql 对paimon表的操作)
[5.5.1 插入数据](#5.5.1 插入数据)
[5.5.2 更新数据](#5.5.2 更新数据)
[5.5.3 删除数据](#5.5.3 删除数据)
[5.5.4 查看表结构](#5.5.4 查看表结构)
[6. 所遇问题及解决方案](#6. 所遇问题及解决方案)
[6.1 问题1:执行编译命令报错](#6.1 问题1:执行编译命令报错)
[6.2 问题2:连接Paimon报错](#6.2 问题2:连接Paimon报错)
[6.3 hive sql on spark对paimon进行数据更新,数据未修改](#6.3 hive sql on spark对paimon进行数据更新,数据未修改)
文档摘要: 本文档详细记录了在 CDH 6.3.2(Hadoop 3.0.0)集群环境下,通过外挂方式部署 Spark 3.5.7 客户端,并配置 Apache Paimon 1.1.1 支持的全过程。涵盖源码编译、环境配置、脚本封装及功能验证。
环境信息:
-
OS: CentOS 7.x
-
Cluster: CDH 6.3.2(5节点)
-
Target Spark: Spark 3.5.7
-
Target Paimon: Paimon 1.1.1
-
Scala: 2.12.18
-
Maven: 3.8.4
1. 编译环境准备
在CDH集群的进程少的节点机器上执行。这里我选择的是10.x.xx.202,也就是我配置nd2。
1.1 软件下载
下载编译所需的组件,建议统一放置在 /opt 目录下。
bash
cd /opt
# 1. 下载 Scala 2.12.18 (Spark 3.5 推荐版本)
wget https://downloads.lightbend.com/scala/2.12.18/scala-2.12.18.tgz
# 2. 下载 Maven 3.8.4
wget https://archive.apache.org/dist/maven/maven-3/3.8.4/binaries/apache-maven-3.8.4-bin.tar.gz
# 3. 下载 Spark 3.5.7 源码
wget https://archive.apache.org/dist/spark/spark-3.5.7/spark-3.5.7.tgz也可以使用下述网址下载并上传。
Scala 2.12.18 (Spark 3.5 推荐版本):https://downloads.lightbend.com/scala/2.12.18/scala-2.12.18.tgz
Maven 3.8.4:https://archive.apache.org/dist/maven/maven-3/3.8.4/binaries/apache-maven-3.8.4-bin.tar.gz
Spark 3.5.7 源码:https://archive.apache.org/dist/spark/spark-3.5.7/spark-3.5.7.tgz
1.2 解压与权限配置
bash
# 解压
sudo tar -zxvf scala-2.12.18.tgz -C /opt
sudo tar -zxvf apache-maven-3.8.4-bin.tar.gz -C /opt
sudo tar -zxvf spark-3.5.7.tgz -C /opt
# 授权 (这里我的当前用户为 bigdata)
sudo chown -R bigdata:bigdata /opt/apache-maven-3.8.4
sudo chown -R bigdata:bigdata /opt/scala-2.12.18
sudo chown -R bigdata:bigdata /opt/spark-3.5.7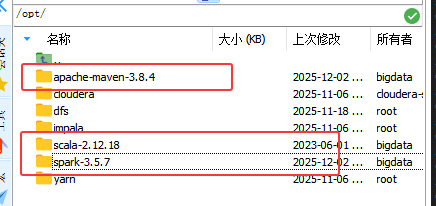
1.3 环境变量配置
编辑 /etc/profile 配置 Java, Maven, Scala 环境。
bash
sudo vi /etc/profile追加内容:
bash
# 请根据实际 JDK 路径调整
# ls -lrt /etc/alternatives/java
# 若没有相应的java8的jar包,可使用下述命令进行下载
# yum install -y java-1.8.0-openjdk-devel
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64
export MAVEN_HOME=/opt/apache-maven-3.8.4
export SCALA_HOME=/opt/scala-2.12.18
export PATH=$JAVA_HOME/bin:$MAVEN_HOME/bin:$SCALA_HOME/bin:$PATH
生效并验证:
bash
source /etc/profile
java -version
mvn -version
scala -version


2. Spark 3.5.7 源码编译
由于 CDH 官方 Maven 仓库限制及版本兼容性问题,本步骤采用Apache Hadoop 依赖借壳编译方案:即编译时使用 Apache Hadoop 3.3.4 依赖,运行时作为客户端连接 CDH 6.3.2 集群。
2.1 修改 Maven 配置
为了确保依赖下载顺畅,需配置阿里云镜像。
步骤 1:修改源码级 pom.xml 编辑 /opt/spark-3.5.7/pom.xml:
在 <repositories> 标签中添加阿里云仓库。
XML
<repository>
<id>aliyun</id>
<url>https://maven.aliyun.com/nexus/content/groups/public</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>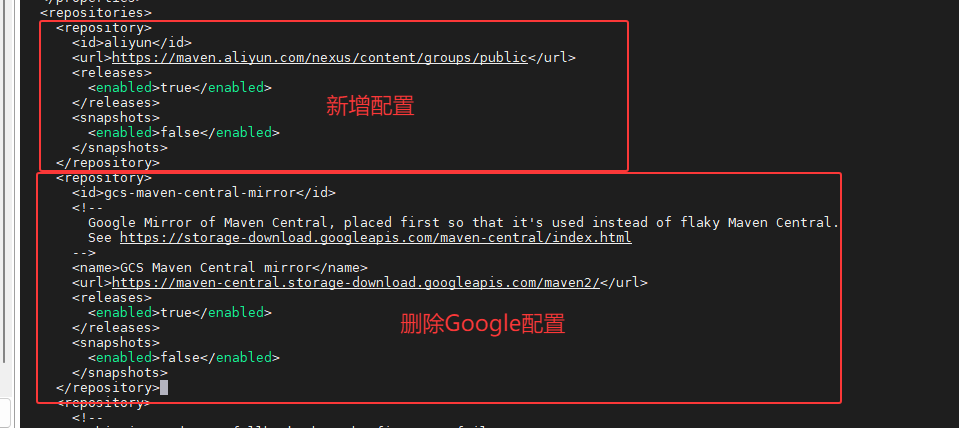
注释或删除 <pluginRepository> 下 Google 相关的镜像配置。
XML
<pluginRepository>
<id>gcs-maven-central-mirror</id>
<!--
Google Mirror of Maven Central, placed first so that it's used instead of flaky Maven Central.
See https://storage-download.googleapis.com/maven-central/index.html
-->
<name>GCS Maven Central mirror</name>
<url>https://maven-central.storage-download.googleapis.com/maven2/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>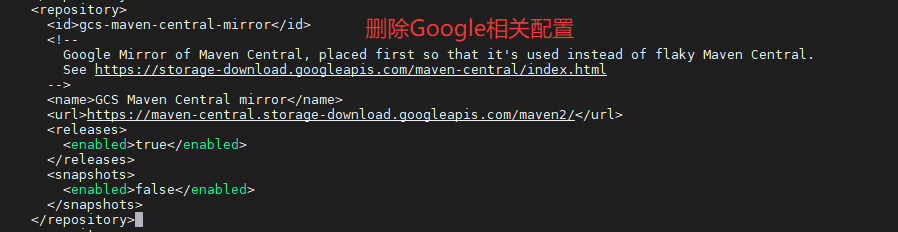
注意 :这里我修改 <hadoop.version> 为 3.0.0-cdh6.3.2 版本,相应的结果如下:

核心提示 :3.0.0-cdh6.3.2 是 Cloudera Distribution (CDH) 的特定版本,而非 Apache 官方原生版本。Maven 默认仓库中不存在该版本的依赖包。
解决方案:
方案一:默认源码级 pom.xml的<hadoop.version> 的设置,相应的执行命令为6.1所写的编译命令2:

方案二:使用命令行进行指定,参照2.3所写的命令进行执行。
步骤 2:配置全局 settings.xml (强制覆盖) 为防止插件硬编码访问中央仓库,直接修改 Maven 全局配置。
bash
mkdir -p ~/.m2
vi ~/.m2/settings.xml
XML
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
http://maven.apache.org/xsd/settings-1.0.0.xsd">
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
</mirrors>
</settings>2.2 修改编译脚本
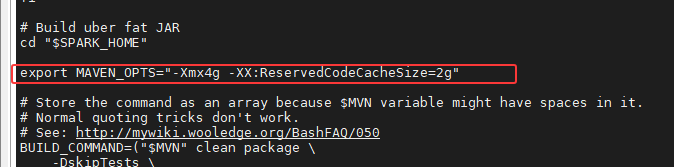
编辑 /opt/spark-3.5.7/dev/make-distribution.sh,在文件头部(#!/usr/bin/env bash 之后)添加内存配置和 Maven 路径也可修改相关配置:
bash
export MAVEN_OPTS="-Xmx4g -XX:ReservedCodeCacheSize=2g"
# 建议将'MVN="/opt/apache-maven-3.8.4/bin/mvn"'放在`#!/usr/bin/env bash`文件之后
MVN="/opt/apache-maven-3.8.4/bin/mvn"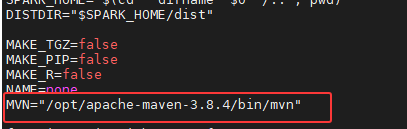
2.3 执行编译
切换到 Spark 源码目录并执行编译。
预处理:切换 Scala 版本
bash
cd /opt/spark-3.5.7
# 强制使用 Maven 3.8.4 切换 Scala 版本为 2.12
# 这一步也可以不验证
# 直接使用如下命令查看版本
# grep "<scala.binary.version>" pom.xml
sudo MVN="/opt/apache-maven-3.8.4/bin/mvn" ./dev/change-scala-version.sh 2.12执行编译命令:
参数说明:
-Dhadoop.version=3.3.4: 使用高版本 Hadoop 客户端依赖,兼容低版本服务端。
-Denforcer.skip=true: 跳过 Maven 版本检查(Spark 3.5 要求 Maven 3.9+,此处强制使用 3.8.4)。
bash
./dev/make-distribution.sh \
--name 3.5.7-apache-hadoop3 \
--tgz \
--mvn /opt/apache-maven-3.8.4/bin/mvn \
-Pyarn \
-Phadoop-3 \
-Phive \
-Phive-thriftserver \
-Dhadoop.version=3.3.4 \ #这一行可以不指定,若使用默认hadoop版本3.3.4
-DskipTests \
-Denforcer.skip=true编译结果 : 成功后在当前目录下生成 spark-3.5.7-bin-3.5.7-apache-hadoop3.tgz。

3. Spark 3.5.7 客户端部署与集成
基于现有的CDH集群一个节点进行外部挂在Spark3.5.7,在CDH 集群节点(Gateway 或 Master)上执行。这里我选择的是10.x.xx.202节点。
3.1 单节点安装包分发
bash
# 将编译好的包放置于 CDH 库目录
cd /opt/cloudera/parcels/CDH/lib
sudo tar -zxvf /opt/spark-3.5.7/spark-3.5.7-bin-3.5.7-apache-hadoop3.tgz
sudo mv spark-3.5.7-bin-3.5.7-apache-hadoop3 spark33.2 基础配置初始化
复制 CDH 现有的配置文件作为模板。
bash
cd /opt/cloudera/parcels/CDH/lib/spark3/conf
# 复制 Hadoop/Hive 关联配置
cp /etc/spark/conf/spark-env.sh .
cp /etc/hive/conf/hive-site.xml .
# 初始化 Spark 自身配置
cp spark-defaults.conf.template spark-defaults.conf
cp log4j2.properties.template log4j2.properties
3.3 配置 spark-env.sh (关键)
解决 Classpath 冲突的核心步骤。
bash
sudo vi spark-env.sh修改内容如下(可直接替换):
bash
#!/bin/bash
# 1. 定义 Paimon Jar 路径
PAIMON_CP="/opt/paimon-jars/paimon-spark-3.5-1.1.1.jar:/opt/paimon-jars/paimon-hive-connector-2.1-1.1.1.jar"
# 2. Spark 基础变量
export SPARK_HOME=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3
export SPARK_CONF_DIR=$SPARK_HOME/conf
# 3. 清洗 Hadoop Classpath (移除旧版 spark/pig 等干扰)
HADOOP_CP=$(hadoop classpath)
CLEANED_HADOOP_CP=$(echo $HADOOP_CP | tr ':' '\n' | grep -v "spark" | grep -v "pig" | tr '\n' ':')
# 4. 【核心】设置 Classpath 优先级:Paimon > Cleaned Hadoop
export SPARK_DIST_CLASSPATH="$PAIMON_CP:$CLEANED_HADOOP_CP"
# 5. 指向 Hadoop 配置
export HADOOP_CONF_DIR=/etc/hadoop/conf
export YARN_CONF_DIR=/etc/hadoop/conf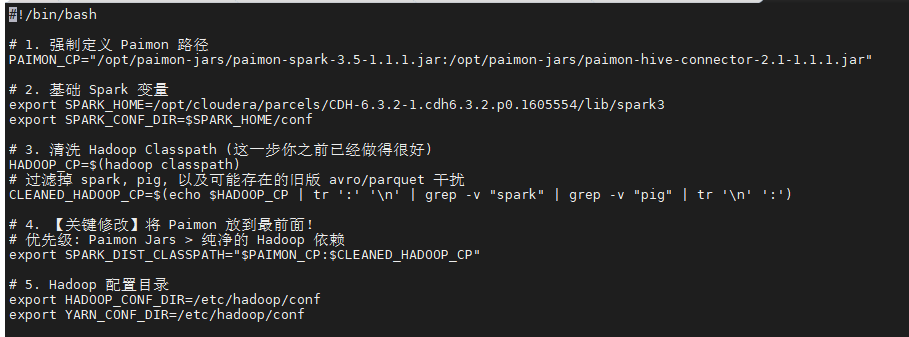
3.4 配置 spark-defaults.conf
配置 Paimon Catalog 及 CDH 兼容性参数。
步骤1:准备 HDFS 目录:
bash
hadoop fs -mkdir -p /spark/3.5.7/jars
hadoop fs -put /opt/cloudera/parcels/CDH/lib/spark3/jars/*.jar /spark/3.5.7/jars/
# 确保 Paimon jar 也上传到了 HDFS (路径需与配置文件一致)步骤2:修改配置文件:
bash
sudo vi /opt/cloudera/parcels/CDH/lib/spark3/conf/spark-defaults.conf修改内容如下(可直接替换):
bash
# ==================== 基础配置 ====================
spark.master=yarn
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs:///user/spark/applicationHistory
# ==================== Jar 包分发 (Paimon 支持) ====================
# YARN 容器侧加载
spark.jars=hdfs:///spark/3.5.7/jars/paimon-spark-3.5-1.1.1.jar,\
hdfs:///spark/3.5.7/jars/paimon-hive-connector-2.1-1.1.1.jar
# ==================== CDH 6.3.2 兼容性配置 ====================
# 使用旧版 Shuffle 协议以兼容 Hadoop 3.0
spark.shuffle.useOldFetchProtocol=true
# 指向 CDH Native 库
spark.driver.extraLibraryPath=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/lib/native
spark.executor.extraLibraryPath=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/lib/native
# SQL 兼容模式
spark.sql.legacy.timeParserPolicy=LEGACY
spark.sql.legacy.parquet.datetimeRebaseModeInRead=LEGACY
# ==================== 动态资源分配 ====================
spark.dynamicAllocation.enabled=true
# 必须禁用外部 Shuffle Service (因为版本不匹配),改用 Shuffle Tracking
spark.shuffle.service.enabled=false
spark.dynamicAllocation.shuffleTracking.enabled=true
# ==================== Paimon Catalog 配置 ====================
spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions
spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog
spark.sql.catalog.paimon.metastore=hive
spark.sql.catalog.paimon.hadoop.conf.dir=/etc/hadoop/conf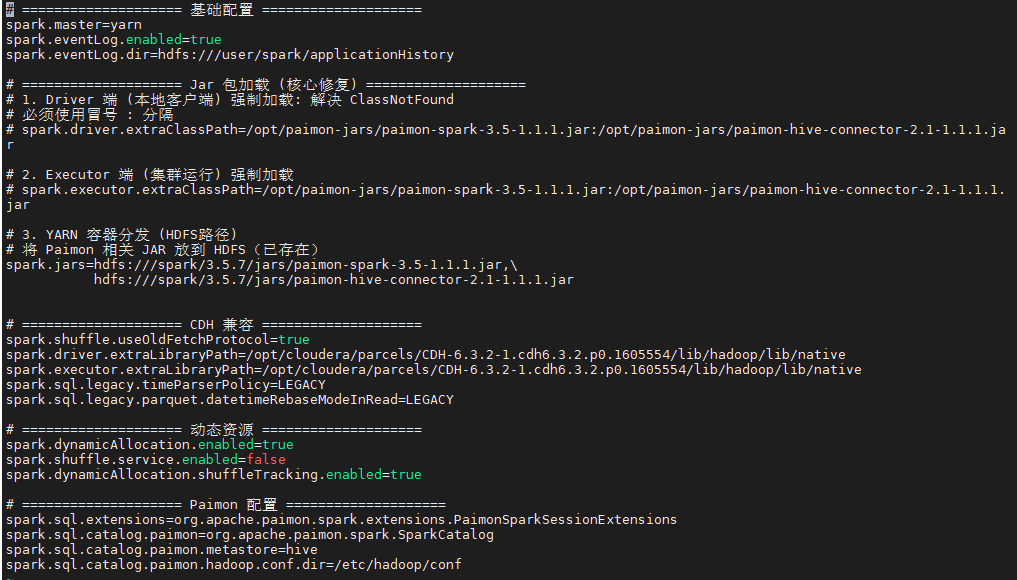
4. 脚本封装
为了方便使用并与系统自带 Spark 隔离,创建专用启动脚本。
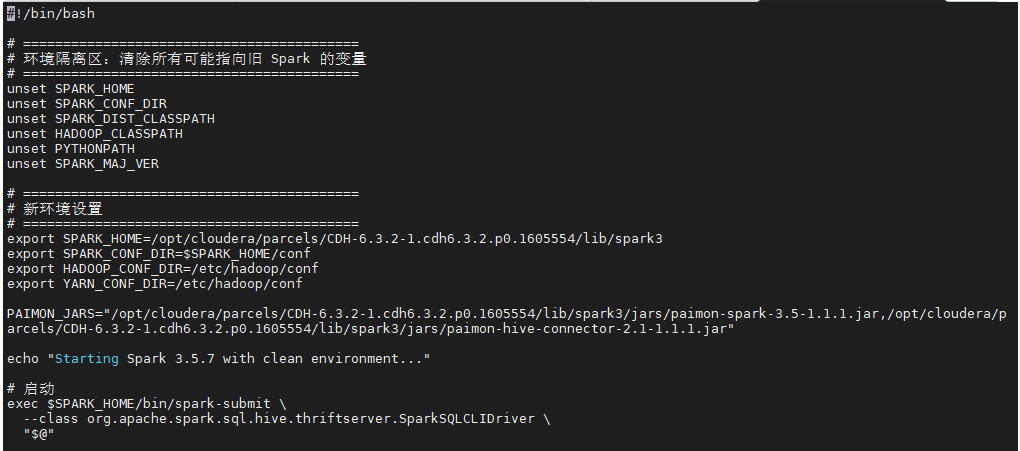
4.1 创建 spark-sql-3.5
bash
sudo vi /opt/cloudera/parcels/CDH/bin/spark-sql-3.5修改内容如下(可直接替换):
bash
#!/bin/bash
# 清理旧环境变量,防止污染
unset SPARK_HOME SPARK_CONF_DIR SPARK_DIST_CLASSPATH HADOOP_CLASSPATH PYTHONPATH SPARK_MAJ_VER
# 设置新环境
export SPARK_HOME=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3
export SPARK_CONF_DIR=$SPARK_HOME/conf
export HADOOP_CONF_DIR=/etc/hadoop/conf
export YARN_CONF_DIR=/etc/hadoop/conf
# Paimon Jars 路径定义 (本地)
PAIMON_JARS="/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/jars/paimon-spark-3.5-1.1.1.jar,/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/jars/paimon-hive-connector-2.1-1.1.1.jar"
echo "Starting Spark 3.5.7 SQL Client..."
exec $SPARK_HOME/bin/spark-submit \
--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver \
"$@"
4.2 创建 spark3-submit
bash
sudo vi /opt/cloudera/parcels/CDH/bin/spark3-submit修改内容如下(可直接替换):
bash
#!/bin/bash
export HADOOP_CONF_DIR=/etc/hadoop/conf
export YARN_CONF_DIR=/etc/hadoop/conf
export SPARK_HOME=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3
# 固定 Python Hash 种子,防止 PySpark 校验错误
export PYTHONHASHSEED=0
exec $SPARK_HOME/bin/spark-submit "$@"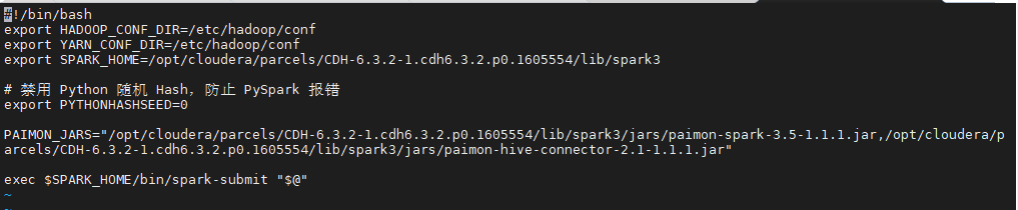
4.3 赋权与注册
bash
sudo chmod +x /opt/cloudera/parcels/CDH/bin/spark-sql-3.5
sudo chmod +x /opt/cloudera/parcels/CDH/bin/spark3-submit
# 可选:注册到系统命令,建议赋权
sudo alternatives --install /usr/bin/spark3-submit spark3-submit /opt/cloudera/parcels/CDH/bin/spark3-submit 1
sudo alternatives --install /usr/bin/spark-sql-3.5 spark-sql-3.5 /opt/cloudera/parcels/CDH/bin/spark-sql-3.5 15. 功能验证
5.1 Spark Pi 测试 (验证 YARN 调度)
bash
spark3-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 2g \
--executor-cores 1 \
/opt/cloudera/parcels/CDH/lib/spark3/examples/jars/spark-examples_2.12-3.5.7.jar 10

5.2 SQL 与 Hive 互通测试
bash
spark-sql-3.5
sql
-- 验证 Hive 数据库访问
show databases;
use default;
select count(*) from your_hive_table;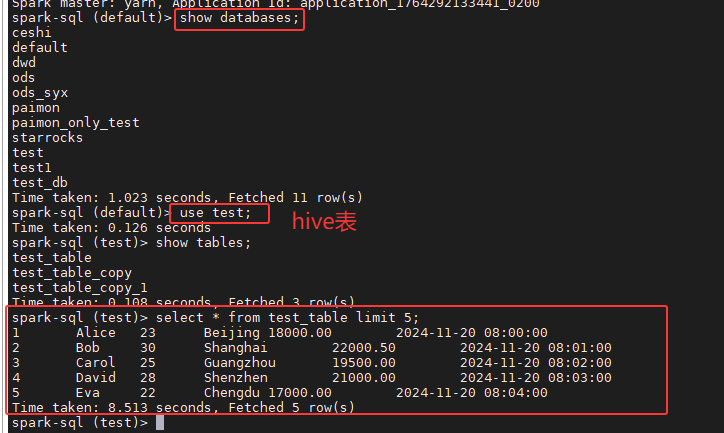
5.3 Paimon 读写测试
sql
-- 切换到 Paimon Catalog
use paimon;
use ods; -- 假设已存在数据库
-- 查看表
show tables;
-- 数据查询
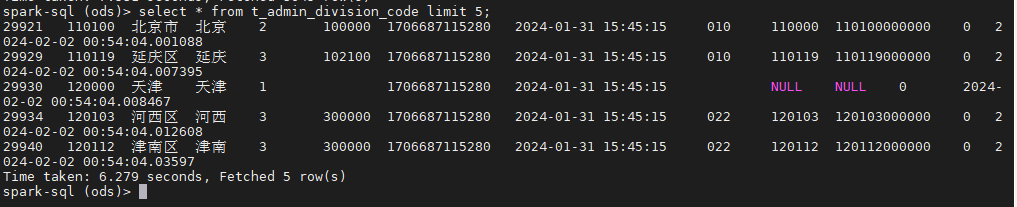
select * from t_admin_division_code limit 5;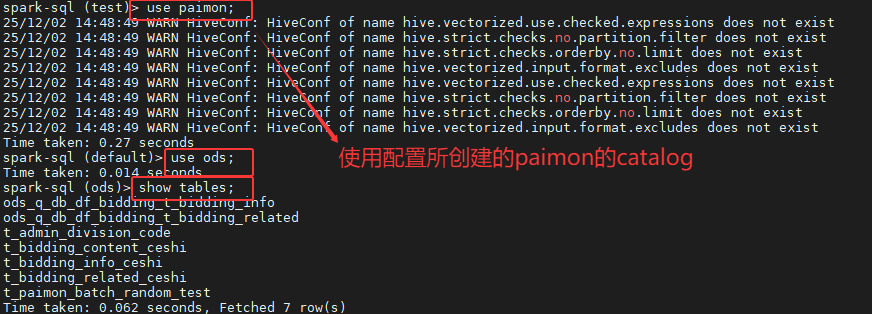
5.4 Hive sql on spark对Paimon表的操作
5.4.1 更新数据
因在文档的最开始就创建的测试数据库以及表,这里我直接在hue上面查看原始数据。
bash
use paimon;
use paimon_test;
select * from paimon_test1;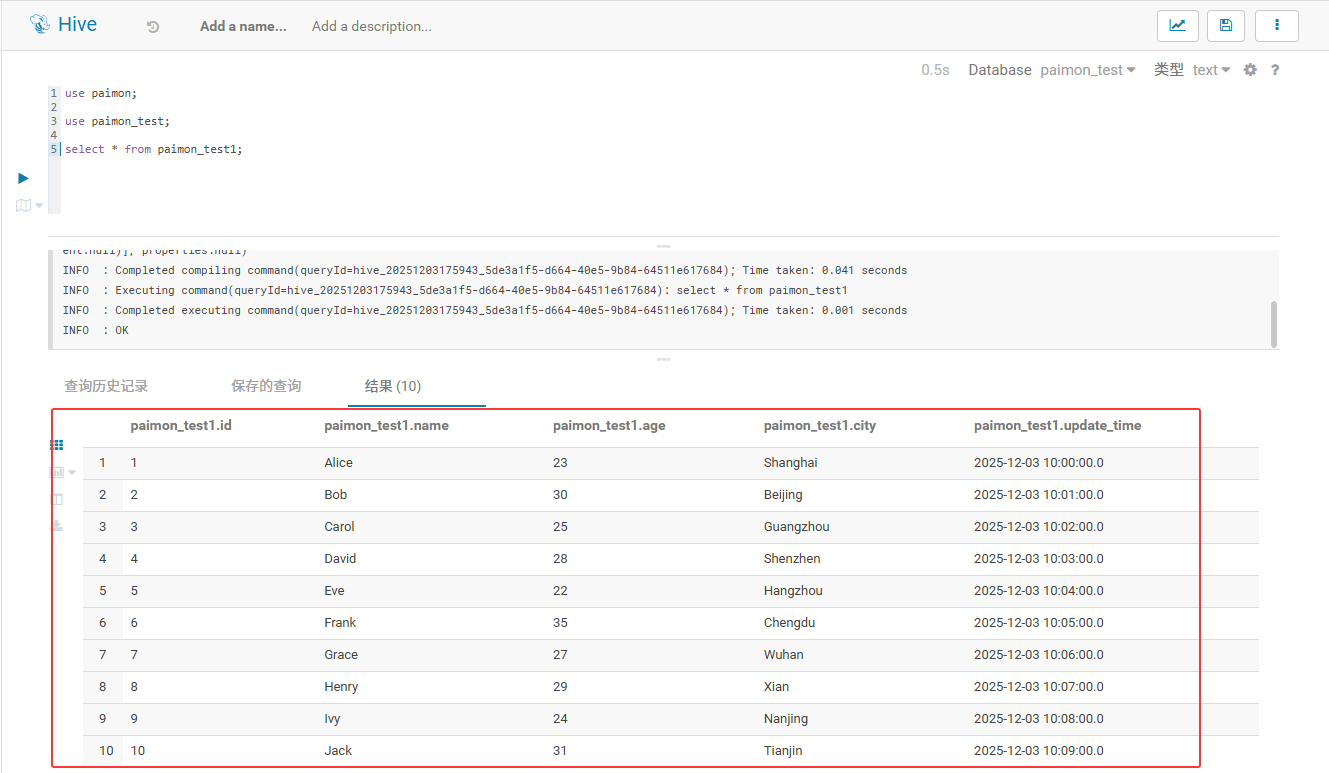
在Spark3的客户端执行hive sql on spark对paimon表的更新操作。
方式一:
bash
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline \
-u "jdbc:hive2://10.x.xx.202:10001/default" \
-n hive \
-e "INSERT INTO TABLE paimon.paimon_test.paimon_test1 VALUES
(1, 'Alice', 24, 'Shanghai', TIMESTAMP '2025-12-03 11:00:00'),
(5, 'Eve', 23, 'Suzhou', TIMESTAMP '2025-12-03 11:01:00');"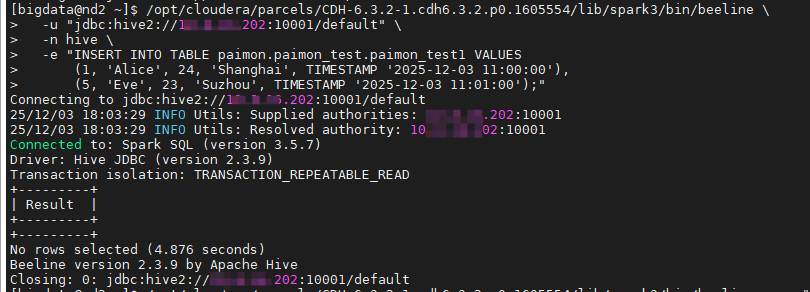
使用命令进行查询,结果如下:
bash
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline \
-u "jdbc:hive2://10.8.16.202:10001/default" \
-n hive \
-e "SELECT * FROM paimon.paimon_test.paimon_test1;"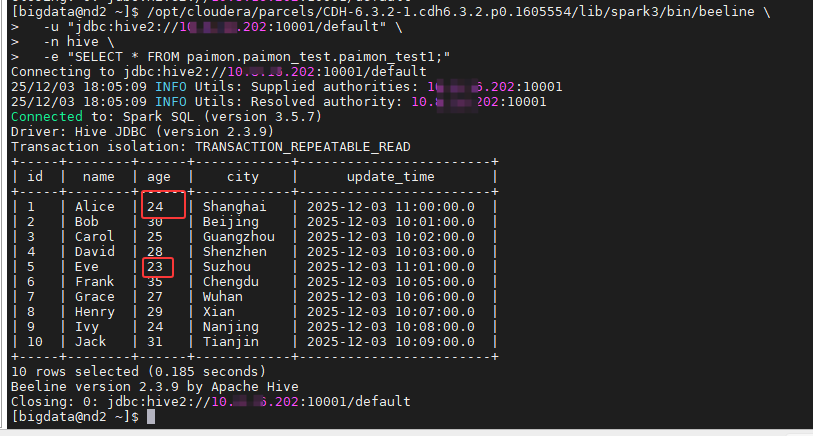
方式二:
bash
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline \
-u "jdbc:hive2://10.8.16.202:10001/default" \
-n hive \
-e "USE paimon;
USE paimon_test;
INSERT INTO TABLE paimon_test1 VALUES
(1, 'Alice', 25, 'Shanghai', TIMESTAMP '2025-12-03 11:00:00'),
(5, 'Eve', 24, 'Suzhou', TIMESTAMP '2025-12-03 11:01:00');"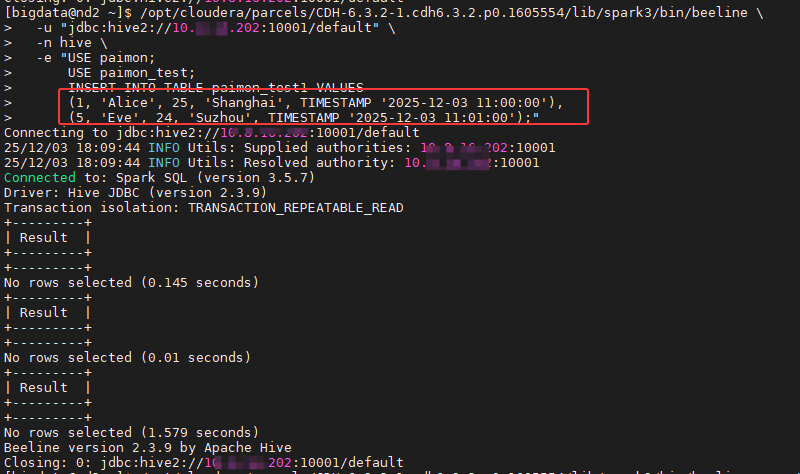
使用之前的命令进行查看结果,如下图所示:
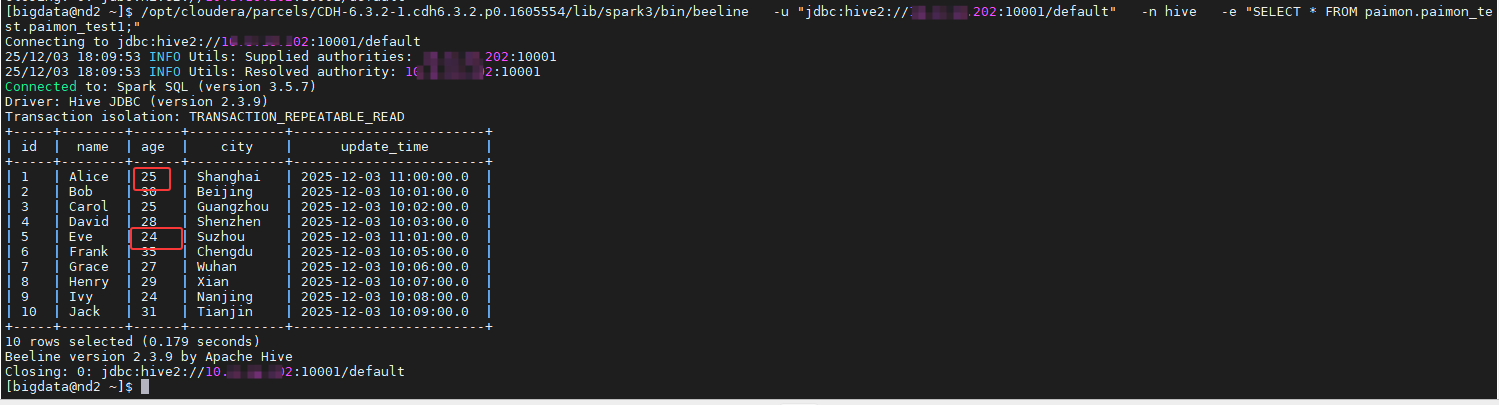
方式三:
bash
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline \
-u "jdbc:hive2://10.8.16.202:10001/default" \
-n hive \
--verbose=true \
<<EOF
-- 1. 切换到 Paimon Catalog
USE paimon;
-- 2. 切换到具体的数据库
USE paimon_test;
-- 3. 执行写入 (这里必须用 TIMESTAMP 强转)
INSERT INTO TABLE paimon_test1 VALUES
(1, 'Alice', 26, 'Shanghai', TIMESTAMP '2025-12-03 11:00:00'),
(5, 'Eve', 25, 'Suzhou', TIMESTAMP '2025-12-03 11:01:00');
EOF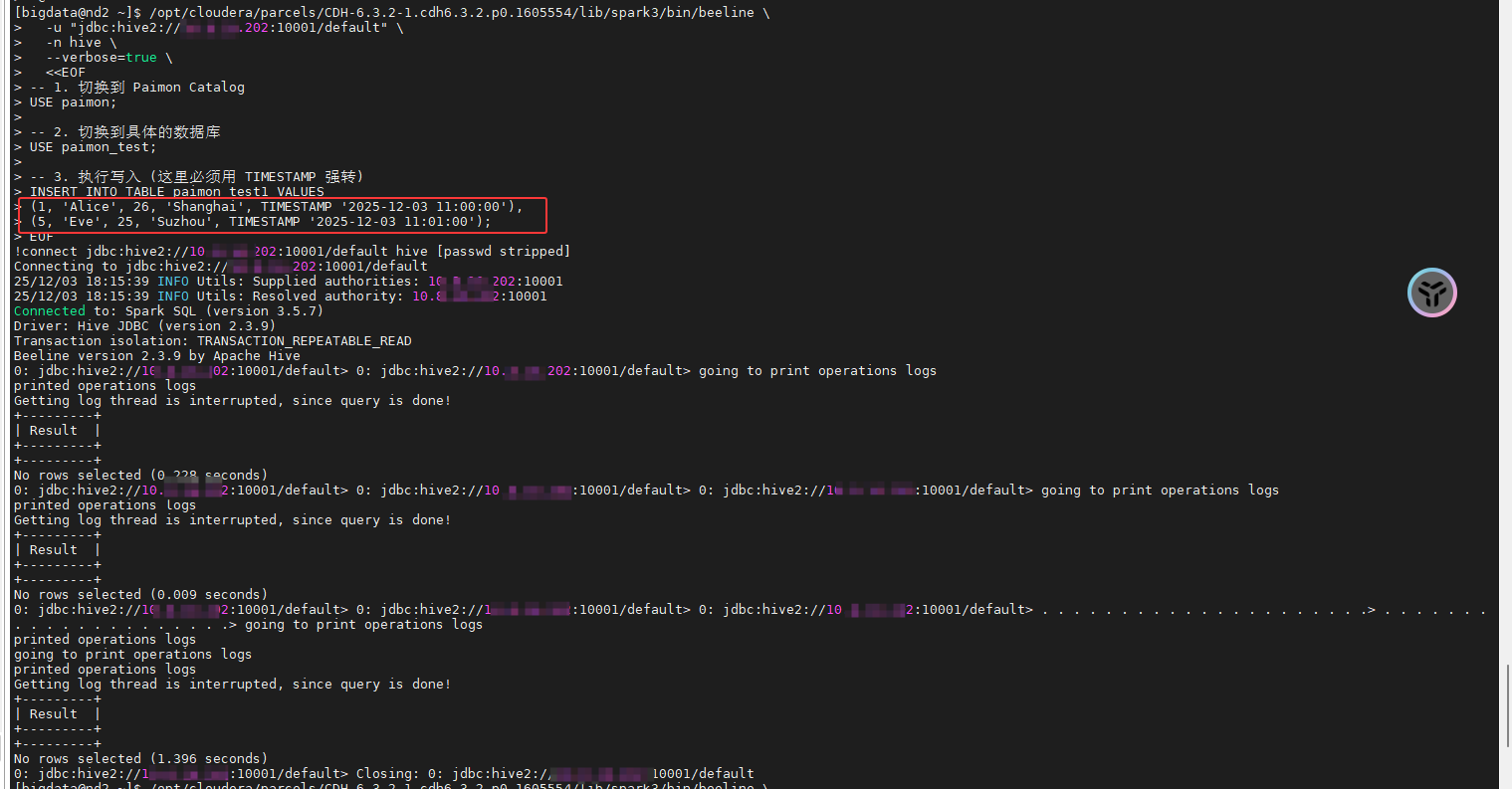
使用之前的命令进行查看结果,如下图所示:
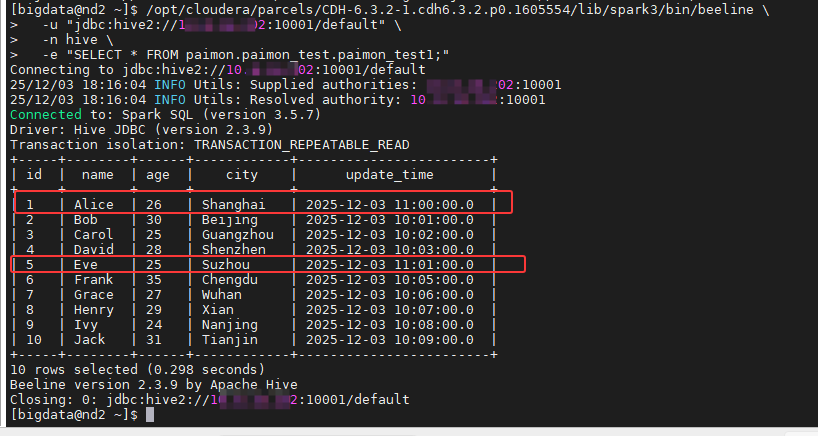
5.4.2 删除数据
**场景一:**删除刚才插入的那两条特定数据
bash
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline \
-u "jdbc:hive2://10.8.16.202:10001/default" \
-n hive \
-e "DELETE FROM paimon.paimon_test.paimon_test1 WHERE id IN (1, 5);"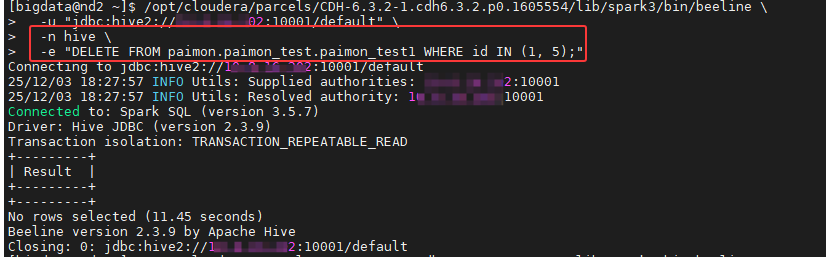
使用之前的命令进行查看结果,就没有之前修改的数据,如下图所示:
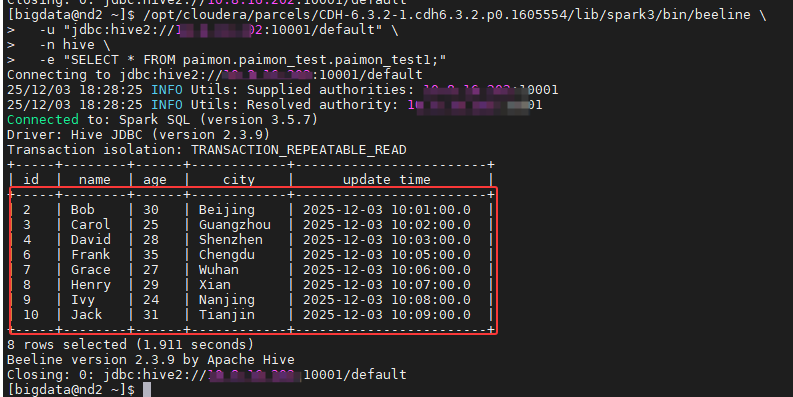
**场景二:**清空整张表的数据
bash
# 方式 A:使用 DELETE (通用)
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline \
-u "jdbc:hive2://10.8.16.202:10001/default" \
-n hive \
-e "DELETE FROM paimon.paimon_test.paimon_test1;"
# 方式 B:使用 TRUNCATE (通常更快)
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline \
-u "jdbc:hive2://10.8.16.202:10001/default" \
-n hive \
-e "DELETE FROM paimon.paimon_test.paimon_test1;"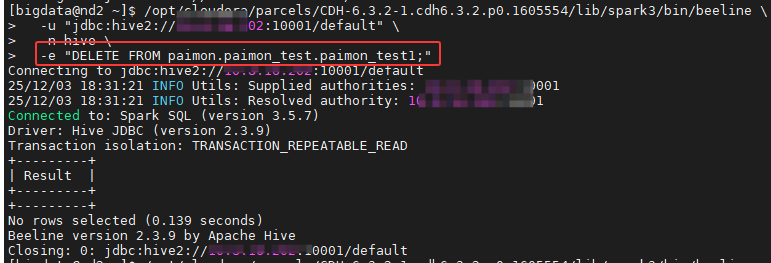
使用之前的命令进行查看结果,就没有之前修改的数据,如下图所示:

5.4.3 插入数据
在终端使用hive sql on spark对paimon表进行数据插入:
bash
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline \
-u "jdbc:hive2://10.8.16.202:10001/default" \
-n hive \
-e "INSERT INTO TABLE paimon.paimon_test.paimon_test1 VALUES
(10, 'John', 30, 'Beijing', TIMESTAMP '2025-12-03 12:00:00'),
(11, 'Mike', 28, 'Shenzhen', CAST('2025-12-03 12:05:00' AS TIMESTAMP));"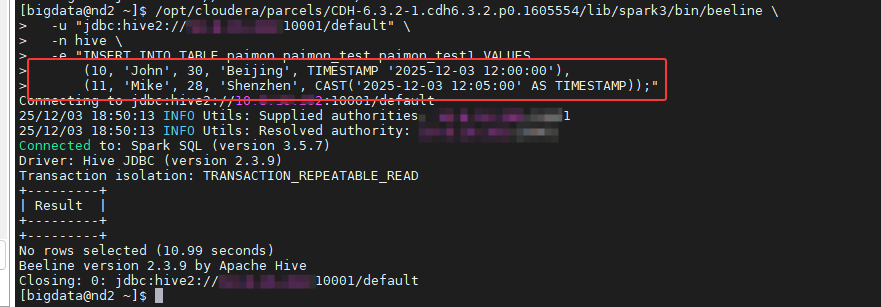
使用之前的命令进行查看结果,就没有之前修改的数据,如下图所示:
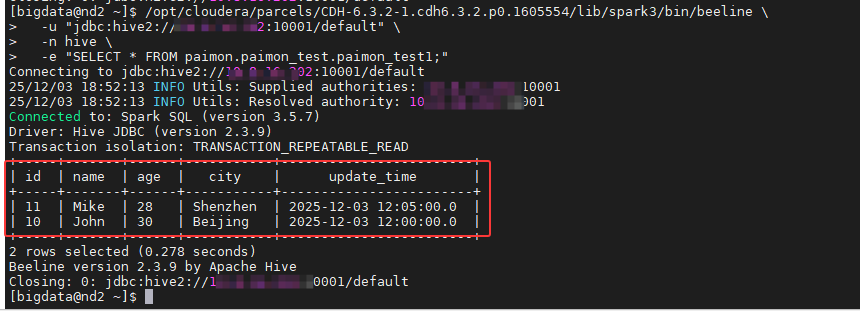
5.4.4 查看表结构
bash
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline \
-u "jdbc:hive2://10.8.16.202:10001/default" \
-n hive \
-e "DESCRIBE EXTENDED paimon.paimon_test.paimon_test1;"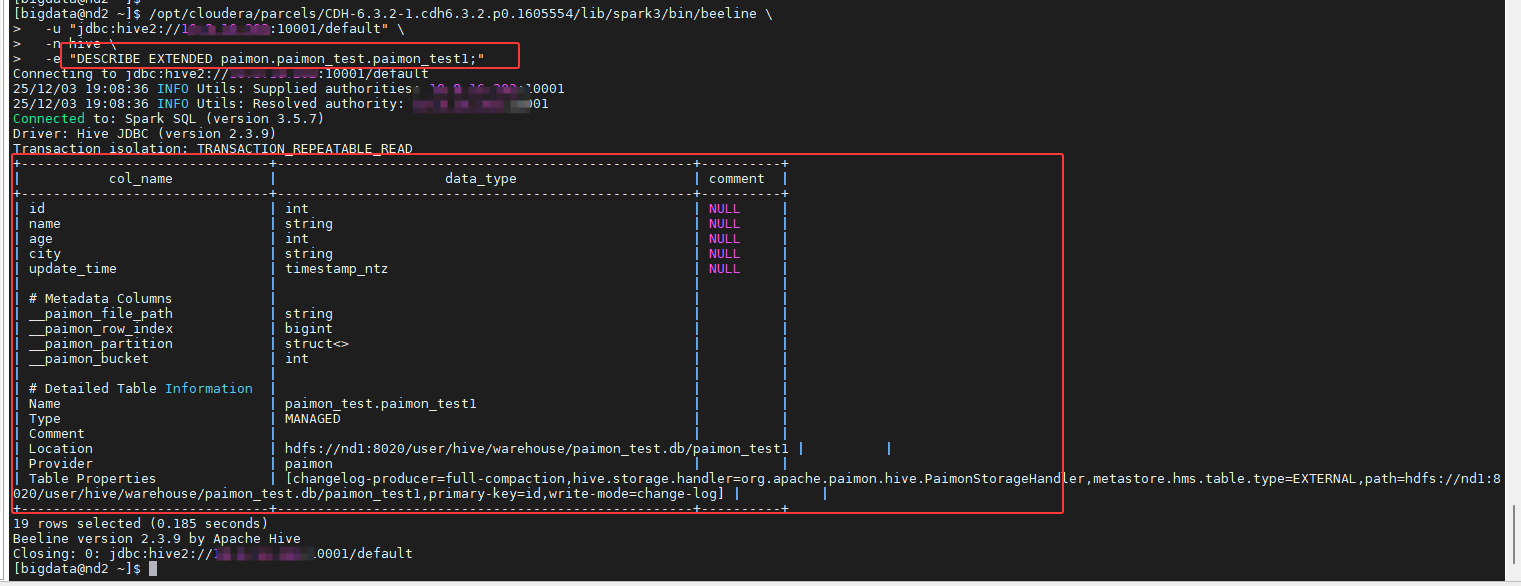
5.5 spark sql 对paimon表的操作
5.5.1 插入数据
使用spark-sql-3.5启动spark会话,执行下述命令:
sql
-- 推荐使用全限定名:Catalog.Database.Table
INSERT INTO paimon.paimon_test.paimon_test1 VALUES
(20, 'Tom', 30, 'Beijing', TIMESTAMP '2025-12-03 14:00:00'),
(21, 'Jerry', 25, 'Shanghai', CAST('2025-12-03 14:05:00' AS TIMESTAMP));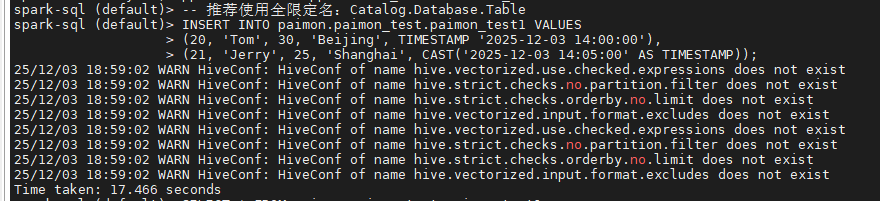
查看表里面的数据
sql
SELECT * FROM paimon.paimon_test.paimon_test1
5.5.2 更新数据
sql
-- 将 id 为 20 的用户城市改为 Nanjing
UPDATE paimon.paimon_test.paimon_test1
SET city = 'Nanjing', update_time = TIMESTAMP '2025-12-03 15:00:00'
WHERE id = 20;
查看表里面的数据,结果如下:

5.5.3 删除数据
sql
-- 删除 id 为 21 的数据
DELETE FROM paimon.paimon_test.paimon_test1 WHERE id = 21;
5.5.4 查看表结构
sql
DESCRIBE EXTENDED paimon.paimon_test.paimon_test1;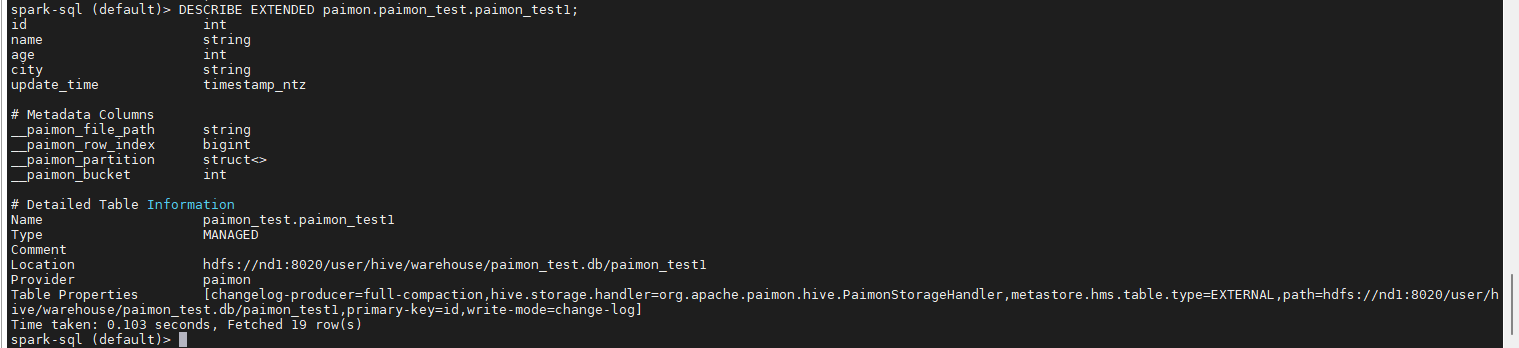
6. 所遇问题及解决方案
6.1 问题1:执行编译命令报错
编译命令1:
bash
# 编译命令
# 注意:Spark 3.5 默认 Profiles 可能有所变化,建议如下:
./dev/make-distribution.sh \
--name 3.5.7-cdh6.3.2 \
--tgz \
--mvn /opt/apache-maven-3.8.4/bin/mvn \
-Pyarn \
-Phadoop-3 \
-Phive \
-Phive-thriftserver \
-DskipTests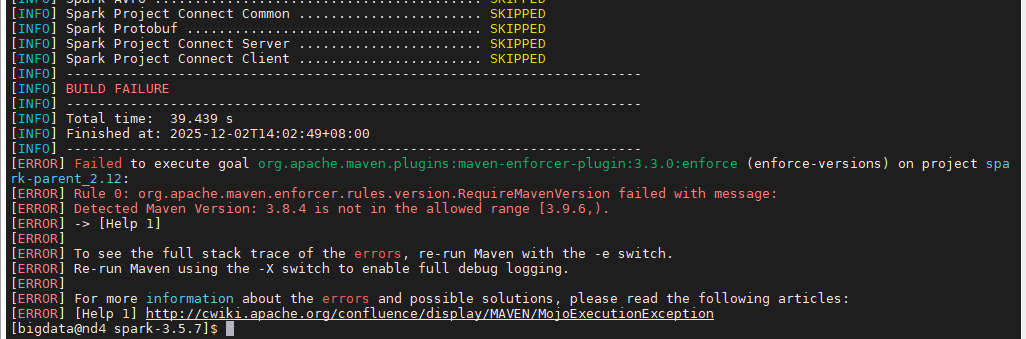
Spark 3.5.7 的 pom.xml 中配置了强制检查 Maven 版本,要求 Maven ≥ 3.9.6 。而当前使用的是 Maven 3.8.4 ,不满足要求,所以被拦截了。这里不需要重装 Maven,也不需要改代码。最简单 的解决办法是:在命令中添加参数,强制跳过版本检查。
编译命令2:
bash
./dev/make-distribution.sh \
--name 3.5.7-cdh6.3.2 \
--tgz \
--mvn /opt/apache-maven-3.8.4/bin/mvn \
-Pyarn \
-Phadoop-3 \
-Phive \
-Phive-thriftserver \
-DskipTests \
-Denforcer.skip=true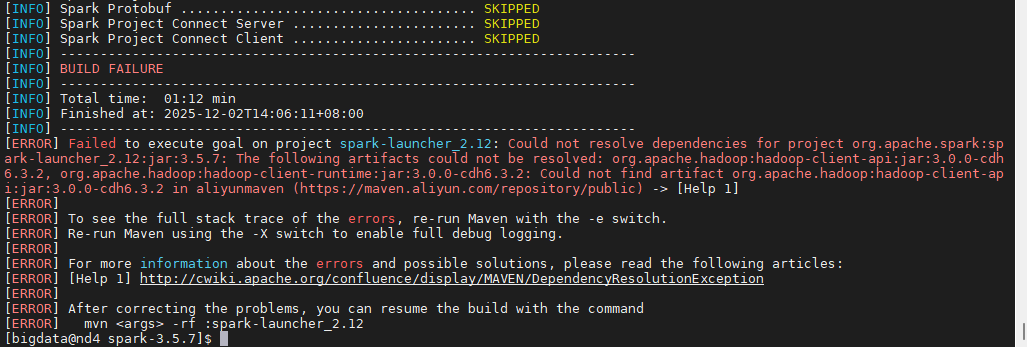
又因之前设置了Maven 去阿里云镜像下载 3.0.0-cdh6.3.2 版本的 Hadoop 包。阿里云没有(也不会有)CDH 的包 。CDH 的包都在 Cloudera 官方仓库,而那个仓库现在需要付费账号才能访问。
因此需要使用 Apache 官方版本进行"借壳编译"而是编译一个 "携带了 Apache Hadoop 3.3.4 类库的通用版 Spark"。
-
编译时:使用阿里云里有的 Apache Hadoop 3.3.4(Spark 3.5.7 的默认依赖)。
-
运行时:Spark 作为一个客户端,完全可以带着高版本(3.3)的 jar 包去连接低版本(CDH 6.3 / Hadoop 3.0)的集群。YARN 和 HDFS 的通信协议是向下兼容的。
相应的执行语句参照 2.3 所写进行命令行指定
6.2 问题2:连接Paimon报错
执行spark-sql-3.5这个命令的时候,发现出现如下报错Cannot use org.apache.paimon.spark.extensions.PaimonSparkSessionExtension to configure session extensions.:
bash
[bigdata@nd2 conf]$ spark-sql-3.5
Starting Spark 3.5.7 with clean environment...
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
25/12/02 10:59:16 WARN HiveConf: HiveConf of name hive.vectorized.use.checked.expressions does not exist
25/12/02 10:59:16 WARN HiveConf: HiveConf of name hive.strict.checks.no.partition.filter does not exist
25/12/02 10:59:16 WARN HiveConf: HiveConf of name hive.strict.checks.orderby.no.limit does not exist
25/12/02 10:59:16 WARN HiveConf: HiveConf of name hive.vectorized.input.format.excludes does not exist
25/12/02 10:59:21 WARN SparkSession: Cannot use org.apache.paimon.spark.extensions.PaimonSparkSessionExtension to configure session extensions.
java.lang.ClassNotFoundException: org.apache.paimon.spark.extensions.PaimonSparkSessionExtension
......
25/12/02 10:59:21 WARN SQLConf: The SQL config 'spark.sql.legacy.parquet.datetimeRebaseModeInRead' has been de precated in Spark v3.2 and may be removed in the future. Use 'spark.sql.parquet.datetimeRebaseModeInRead' inst ead.
25/12/02 10:59:21 WARN SQLConf: The SQL config 'spark.sql.legacy.parquet.datetimeRebaseModeInRead' has been de precated in Spark v3.2 and may be removed in the future. Use 'spark.sql.parquet.datetimeRebaseModeInRead' inst ead.
25/12/02 10:59:21 WARN SQLConf: The SQL config 'spark.sql.legacy.parquet.datetimeRebaseModeInRead' has been de precated in Spark v3.2 and may be removed in the future. Use 'spark.sql.parquet.datetimeRebaseModeInRead' inst ead.
25/12/02 10:59:21 WARN SQLConf: The SQL config 'spark.sql.legacy.parquet.datetimeRebaseModeInRead' has been de precated in Spark v3.2 and may be removed in the future. Use 'spark.sql.parquet.datetimeRebaseModeInRead' inst ead.
Spark Web UI available at http://nd2:4040
Spark master: yarn, Application Id: application_1764292133441_0190从报错信息可以看出 Spark 在启动时没有找到 org.apache.paimon.spark.extensions.PaimonSparkSessionExtension(单数)对应的类,而 Paimon 官方文档中要求的扩展类名是 org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions(复数)。因此 Spark 在检查 spark.sql.extensions 配置时认为缺少必要的扩展,直接抛出 ClassNotFoundException。
修改spark-defaults.conf这个文件的spark.sql.extensions这个参数将单数变成复数形式。
6.3 hive sql on spark对paimon进行数据更新,数据未修改
bash
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline \
-u "jdbc:hive2://10.8.16.202:10001/default" \
-n hive \
-e "
-- 1. 切换到 Paimon Catalog (这是最关键的一步)
USE paimon;
-- 2. 切换到具体的数据库
USE paimon_test;
-- 3. 执行写入 (此时使用的是 Paimon 原生 Writer)
INSERT INTO TABLE paimon_test1 VALUES
(1, 'Alice', 24, 'Shanghai', TIMESTAMP '2025-12-03 11:00:00'),
(5, 'Eve', 23, 'Suzhou', TIMESTAMP '2025-12-03 11:01:00');"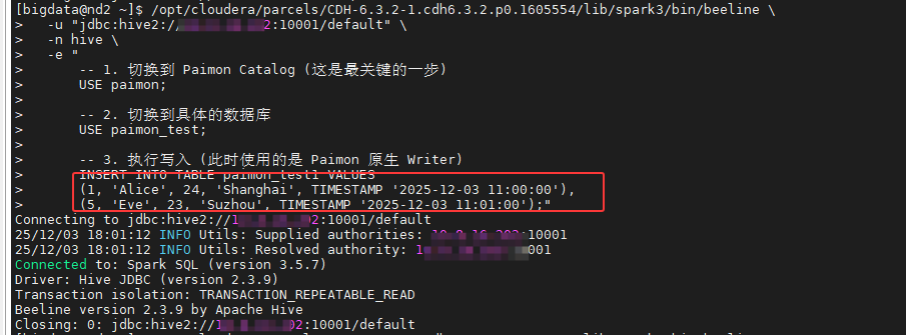
结果显示成功了,但是查询并没有修改成功。
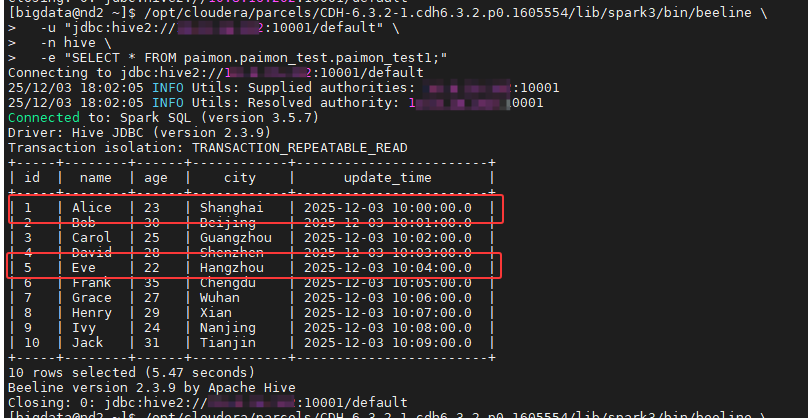
根据之前执行插入数据的终端打印结果如下:
bash
Connected to: Spark SQL (version 3.5.7)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 2.3.9 by Apache Hive <-- 直接结束了
Closing: 0: jdbc:hive2://10.x.xx.202:10001/default关键问题 :Beeline 完全没有执行 SQL。正常的执行应该会显示 INFO : Executing command... 以及进度条或 Job ID。
根本原因 :使用的 beeline -e "..." 语法中,第一行是注释 (-- ...) 。 某些版本的 Beeline(特别是 CDH 里的旧版客户端连接新版 Server 时)在解析 -e 传入的字符串时,如果首行是注释,可能会导致整个字符串被解析器忽略,或者因为换行符处理不当导致后续语句未被提交。
**解决方法:**可以使用前面5.4所写的3种方式进行数据的更新。