LLMs之Deployment:guidellm的简介、安装和使用方法、案例应用之详细攻略
目录
[T1、通过 pip 安装最新版:](#T1、通过 pip 安装最新版:)
[T2、使用容器方式(例如 Podman 或 Docker)运行:](#T2、使用容器方式(例如 Podman 或 Docker)运行:)
[部署前基准测试(Pre-deployment benchmarking):](#部署前基准测试(Pre-deployment benchmarking):)
[回归测试(Regression testing):](#回归测试(Regression testing):)
[硬件评估(Hardware evaluation):](#硬件评估(Hardware evaluation):)
[容量规划(Capacity planning):](#容量规划(Capacity planning):)
guidellm的简介
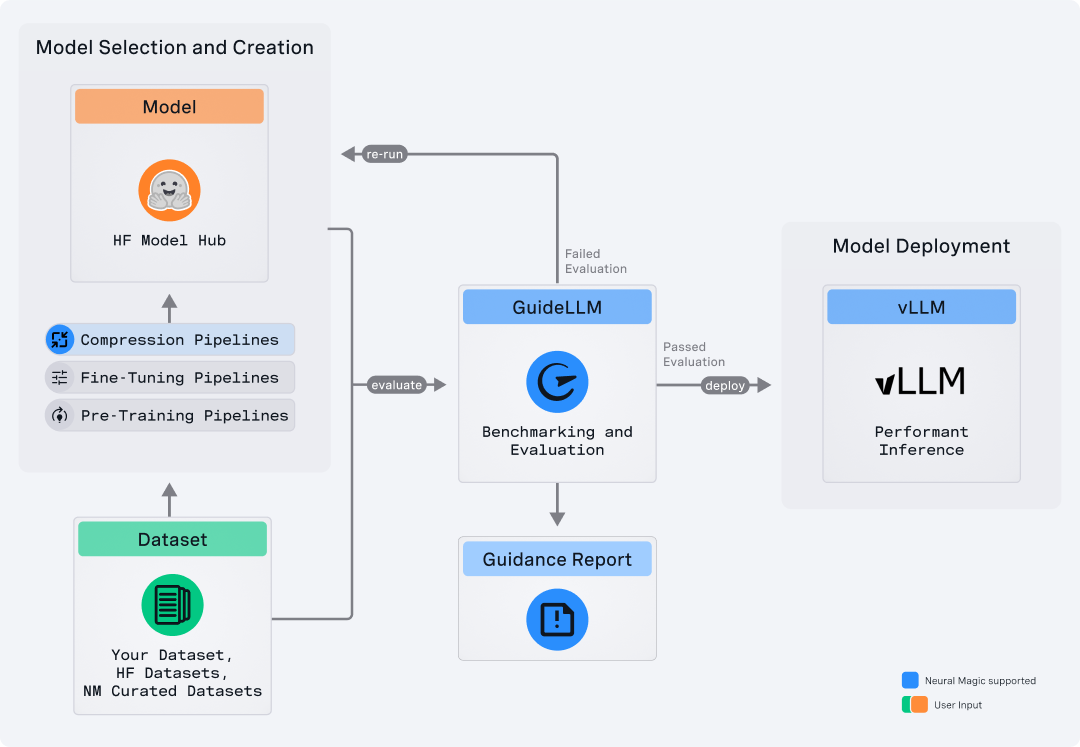
GuideLLM 是一个用于评估和优化大型语言模型(LLM)部署的开源平台。其目标是通过模拟真实世界的推理(inference)负载,帮助用户评估在不同硬件配置、不同模型、不同部署策略下的性能、资源需求与成本。
通过这种方式,GuideLLM 支持用户在生产环境将模型上线前,预先验证是否能够满足服务水平目标(SLO),以及在规模扩展(例如高并发情况)时系统的表现。
Github地址 :https://github.com/vllm-project/guidellm
1、特点
>> 性能评估(Performance Evaluation):能够分析 LLM 在不同负载场景下的推理表现,包括吞吐率、延迟、并发能力。
>> 资源优化(Resource Optimization):帮助确定不同硬件(GPU、CPU、集群) 或模型大小在部署时的资源需求,从而选择更合适的配置。
>> 成本估算(Cost Estimation):通过模拟不同部署策略和硬件方案,估算其财务成本影响,从而辅助做出最具成本效益的部署决策。
>> 可扩展性测试(Scalability Testing):支持模拟大规模并发用户访问,检验系统在高负载下是否仍能维持性能、避免性能退化。
>> 模块化架构(Modular Architecture):其设计适配多种模型、后端、硬件,用户可以定制数据、流量模式、硬件配置,以更贴近真实生产环境。
guidellm的安装和使用方法
1、安装
在 README 中有以下安装步骤:
系统要求:操作系统为 Linux 或 macOS。Python 版本为 3.9 至 3.13。
T1、通过 pip 安装最新版:
pip install guidellm或者从源码安装:
pip install git+https://github.com/vllm-project/guidellm.gitT2、使用容器方式(例如 Podman 或 Docker)运行:
podman run \
--rm -it \
-v "./results:/results:rw" \
-e GUIDELLM_TARGET=http://localhost:8000 \
-e GUIDELLM_RATE_TYPE=sweep \
-e GUIDELLM_MAX_SECONDS=30 \
-e GUIDELLM_DATA="prompt_tokens=256,output_tokens=128" \
ghcr.io/vllm-project/guidellm:latest2、使用方法
使用时典型流程包括:
安装并启动 GuideLLM:指定目标部署 (例如 HTTP 服务 URL)作为 GUIDELLM_TARGET。例如 http://localhost:8000。
设置负载参数/模拟流量方式:例如 GUIDELLM_RATE_TYPE=sweep、GUIDELLM_MAX_SECONDS=30、GUIDELL_DATA="prompt_tokens=256,output_tokens=128" 等。
运行基准(benchmark)任务:系统将模拟不同的并发场景、输入长度、输出长度、模型响应延迟等,并生成结果用于分析。
分析输出结果:用于评估模型部署是否满足吞吐率(RPS)、延迟、资源使用、成本等要求。
guidellm的案例应用
以下为 GuideLLM 在实际生产或部署场景中的典型应用案例):
部署前基准测试(Pre-deployment benchmarking):
想知道在上线前,某模型在某硬件配置下能否满足性能指标。例如:使用 GuideLLM 模拟「某 8 GPU 系统同时支持多少请求/秒(RPS)」并维持某延迟。
回归测试(Regression testing):
在模型或服务更新后,希望验证新版本是否在性能上退化。例如:步入生产前,使用 GuideLLM 模拟旧版与新版模型在同样负载下的表现差别。
硬件评估(Hardware evaluation):
比较不同硬件平台(不同 GPU、CPU、集群节点)运行同一模型时的吞吐和延迟差别。帮助选择性价比最高的硬件。
容量规划(Capacity planning):
在预测未来用户增长或负载增加时,使用 GuideLLM 模拟更高并发/更大输入长度/更严格延迟要求的场景,从而确定所需服务器数量、扩展方式。