传统Transformer架构的核心瓶颈在于注意力机制的计算复杂度 (全注意力为O(n2)O(n^2)O(n2),nnn为序列长度),导致长序列处理(如万字文档、小时级视频)和大模型训练时,计算成本与内存占用急剧上升。为解决这一问题,研究方向从"注意力机制本身优化""模型整体架构设计""工程实现细节打磨"三个维度展开,形成了一套完整的高效化技术体系。
4.1 注意力机制优化
注意力机制的核心是"计算序列中每个token与其他所有token的关联权重",传统全注意力因需遍历所有token对导致复杂度高。优化思路可概括为两类:"稀疏化"(仅计算部分token对的关联)和**"线性化"**(用低复杂度函数替代遍历计算),此外还衍生出"记忆增强"和"状态空间替代"两种创新方向。
4.1.1 全注意力(Full-attention):传统Transformer的"基石与瓶颈"
定义
Transformer原生的注意力机制,要求序列中每个token都与其他所有token计算注意力权重,是模型捕捉全局语义关联的核心,但也是效率瓶颈的根源。
核心原理
- 对输入序列的查询(Q)、键(K)、值(V)矩阵进行计算,每个token的Q与所有token的K做内积,得到注意力得分(表示token间的关联强度)
- 通过Softmax归一化得分,再与V矩阵加权求和,得到每个token的注意力输出
- 计算复杂度:自注意力层的时间复杂度为O(n×dk+n2+n×dv)O(n \times d_k + n^2 + n \times d_v)O(n×dk+n2+n×dv),其中dkd_kdk(K的维度)和dvd_vdv(V的维度)为固定值,因此主导复杂度为**O(n2)O(n^2)O(n2)**(序列长度的平方)
公式示意
注意力权重:
Attention(Q,K,V)=Softmax(QKTdk)V Attention(Q,K,V) = Softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dk QKT)V
其中QKTQK^TQKT的结果是n×nn \times nn×n的矩阵,直接决定了O(n2)O(n^2)O(n2)的复杂度。
关键特点
- 优势 :能捕捉序列的全局语义关联(如文档开头与结尾的逻辑呼应),是Transformer在自然语言理解(NLU)和生成(NLG)任务中表现优异的核心原因
- 局限性 :
- 长序列不可行:当n=10000n=10000n=10000时,n2=108n^2=10^8n2=108,计算量和内存占用远超硬件承载能力(如单张GPU显存无法存储10810^8108规模的矩阵)
- 计算冗余:序列中多数token间的关联较弱(如"今天天气很好"中,"今天"与"很好"的关联远强于"今天"与"天气"的关联),全遍历计算存在大量无效操作
适用场景
仅适用于短序列场景(如n≤512n \leq 512n≤512),如句子级情感分析、短文本翻译
4.1.2 稀疏注意力(Sparse Attention):"只算有用的关联"
定义
通过限制注意力计算的范围 (仅让每个token与部分token关联),将复杂度从O(n2)O(n^2)O(n2)降为O(n×k)O(n \times k)O(n×k)(kkk为每个token的关联数量,通常k≪nk \ll nk≪n),是长序列处理的主流优化方向之一。
核心设计思路
基于"序列中token的关联具有局部性或稀疏性"的假设(如文本中相邻词的关联更强,或仅少数关键词与全局相关),通过规则或模型动态选择需计算的token对。
主流稀疏策略与代表模型
| 稀疏策略 | 核心逻辑 | 代表模型 | 复杂度 | 优势 | 局限性 |
|---|---|---|---|---|---|
| 滑动窗口注意力 | 每个token仅与左右固定窗口内的token计算关联(如窗口大小为5,只看前后5个token) | Longformer | O(nk)O(nk)O(nk) | 计算简单,适合处理连续语义(如文本、语音) | 无法捕捉非相邻的长程关联(如文档首尾) |
| 随机注意力 | 每个token除窗口内token外,额外随机选择少量全局token计算关联 | BigBird | O(nk)O(nk)O(nk) | 兼顾局部关联和全局关联,精度接近全注意力 | 随机选择可能导致关键关联遗漏 |
| 全局稀疏注意力 | 手动指定部分"全局token"(如文档标题、句子主语),所有token均与全局token关联 | Transformer-XL | O(nk)O(nk)O(nk) | 确保关键信息的全局传递,适合结构化数据 | 依赖人工设计全局token,通用性较差 |
| 动态稀疏注意力 | 通过小型预测网络动态判断"哪些token需要计算关联" | Linformer | O(nk)O(nk)O(nk) | 自适应选择关联token,冗余计算最少 | 需额外训练预测网络,增加模型复杂度 |
典型案例:Longformer的滑动窗口+全局token设计
- 针对文本处理场景,Longformer采用"滑动窗口+特殊全局token"的混合策略:
- 普通token:仅与左右32个token计算关联(窗口大小32),处理局部语义
- 全局token(如CLS、文档标题token):与所有token计算关联,负责传递全局信息
- 效果:在n=4096n=4096n=4096的长文本分类任务中,计算量仅为全注意力的1/128,精度损失小于1%
适用场景
长序列处理(如n=1000−10000n=1000-10000n=1000−10000),如文档摘要、法律合同分析、基因组序列处理
4.1.3 线性注意力(Linear Attention):"用数学变换替代遍历"
定义
通过核函数变换 或低秩近似 ,将注意力计算中的QKTQK^TQKT(n×nn \times nn×n矩阵)转化为线性复杂度的计算,直接将时间复杂度从O(n2)O(n^2)O(n2)降为**O(n)O(n)O(n)**,是复杂度优化最彻底的方向之一。
核心原理:突破"Softmax+内积"的固有形式
传统全注意力的瓶颈在于QKTQK^TQKT的遍历计算,线性注意力通过修改注意力权重的计算方式绕开这一步:
- 传统注意力:Attention(Q,K,V)=Softmax(QKTdk)VAttention(Q,K,V) = Softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=Softmax(dk QKT)V(需计算所有Q与K的内积)
- 线性注意力(以Performer为例):引入正定性核函数ϕ\phiϕ (如ReLU、高斯核),将Q和K分别映射到高维特征空间,再通过"核技巧"简化计算:
Attention(Q,K,V)=ϕ(Q)(ϕ(K)TV)ϕ(Q)ϕ(K)T1 Attention(Q,K,V) = \frac{\phi(Q) \left( \phi(K)^T V \right)}{\phi(Q) \phi(K)^T \mathbf{1}} Attention(Q,K,V)=ϕ(Q)ϕ(K)T1ϕ(Q)(ϕ(K)TV)
其中ϕ(Q)\phi(Q)ϕ(Q)和ϕ(K)\phi(K)ϕ(K)是Q和K的核映射,ϕ(K)TV\phi(K)^T Vϕ(K)TV和ϕ(Q)ϕ(K)T1\phi(Q) \phi(K)^T \mathbf{1}ϕ(Q)ϕ(K)T1均可通过矩阵乘法在O(n)O(n)O(n)复杂度内完成
代表模型:Performer
- 2020年提出的线性注意力标杆模型,通过"随机特征映射"近似核函数,避免直接计算高维映射(降低计算成本)
- 关键创新:"正交随机特征(Orthogonal Random Features)"确保核映射的近似精度,同时保持线性复杂度
- 效果:在n=8192n=8192n=8192的长序列任务中,训练速度是全注意力的30倍,精度达到全注意力的98%
优势与局限性
- 优势 :
- 复杂度最低:O(n)O(n)O(n)复杂度支持超长篇序列(如n=105n=10^5n=105以上)
- 并行计算友好:线性操作可通过GPU并行加速,推理延迟低
- 局限性 :
- 精度损失:核函数近似会导致部分语义关联捕捉不精准,在需要强全局关联的任务(如逻辑推理)中表现略逊于全注意力
- 核函数选择敏感:不同任务需适配不同核函数(如文本用ReLU核,图像用高斯核),通用性不如稀疏注意力
适用场景
超长篇序列处理(如n>10000n>10000n>10000),如书籍级文本理解、DNA序列分析、长视频帧处理
4.1.4 记忆增强注意力(Memory-based Attention):"用外部缓存存长程信息"
定义
通过引入外部记忆模块(如记忆缓存、记忆网络),将序列中已处理的长程信息存储起来,后续token可直接从记忆模块中读取关联信息,无需重复计算历史token对,从而降低长序列处理的复杂度。
核心原理
- 传统Transformer处理长序列时,会将序列截断为固定长度的片段(如512token),导致片段间的长程关联丢失(如片段1的"小明"与片段2的"他"无法关联)
- 记忆增强注意力在模型中增加一个"记忆缓存区",每次处理新片段时,将前一片段的关键信息(如隐藏状态)存入缓存,新片段的token可直接与缓存中的信息计算关联,实现跨片段的长程依赖捕捉
代表模型:Transformer-XL
- 2019年提出的记忆增强注意力标杆模型,专为长文本处理设计:
- 记忆缓存(Memory Cache):存储前mmm个片段的隐藏状态(如m=3m=3m=3,缓存前3个片段的信息)
- 相对位置编码:传统Transformer用绝对位置编码(如token在序列中的索引),截断后片段内的位置编码重复(如片段2的第1个token与片段1的第1个token位置编码相同);Transformer-XL改用相对位置编码,计算token间的相对距离(如"片段2的第1个token"与"片段1的第512个token"的距离为512),确保跨片段位置信息准确
- 效果:在n=8192n=8192n=8192的长文本语言建模任务中,困惑度(Perplexity)比传统Transformer低40%,且推理速度提升180%
优势与局限性
- 优势 :
- 高效捕捉长程依赖:无需重复计算历史token对,跨片段关联处理更高效
- 无长度限制:理论上可通过扩展记忆缓存处理无限长序列(受硬件内存限制)
- 局限性 :
- 记忆缓存占用内存:缓存的历史隐藏状态会占用额外GPU显存,需平衡缓存大小与性能
- 推理延迟累积:处理越长的序列,缓存的信息越多,单次推理的内存访问延迟会逐渐增加
适用场景
长程依赖敏感的任务,如长文本语言建模、多轮对话(需记忆历史对话内容)、语音识别(需关联前后音素)
4.1.5 状态空间模型(SSM):"用线性递归替代注意力"
定义
一种完全脱离注意力机制 的序列建模方法,通过线性递归方程 (状态空间方程)捕捉序列的动态依赖,时间复杂度为O(n)O(n)O(n),同时支持并行计算,是近年来长序列处理的突破性方向。
核心原理:从"注意力关联"到"状态演化"
- 传统注意力通过"token间的关联权重"建模序列依赖,SSM则将序列视为"状态的动态演化过程":
- 每个token的输入会更新模型的"隐藏状态"(类似RNN,但用线性变换替代非线性递归)
- 隐藏状态的更新遵循状态空间方程:st=Ast−1+Bxts_t = A s_{t-1} + B x_tst=Ast−1+Bxt(sts_tst为ttt时刻的隐藏状态,AAA和BBB为可学习参数,xtx_txt为ttt时刻的输入token)
- 输出通过状态投影得到:yt=Cst+Dxty_t = C s_t + D x_tyt=Cst+Dxt(CCC和DDD为投影参数)
- 关键创新:通过"快速傅里叶变换(FFT)"将线性递归的串行计算转化为并行计算,解决了RNN串行处理的效率瓶颈
代表模型:Mamba
- 2023年提出的SSM标杆模型,凭借"长序列处理能力+高推理速度"成为Transformer的有力竞争者:
- 选择性状态空间(Selective SSM):在状态更新时,动态选择哪些输入信息需要保留到下一时刻(类似注意力的"权重选择",但通过线性变换实现),提升长程依赖捕捉能力
- 并行化实现:通过FFT和分段线性递归,将O(n)O(n)O(n)的串行计算转化为O(nlogn)O(n \log n)O(nlogn)的并行计算,推理速度比Transformer快5倍以上
- 效果:在n=16384n=16384n=16384的长序列语言建模任务中,困惑度低于GPT-3,且推理速度是同等参数量Transformer的4倍
优势与局限性
- 优势 :
- 长序列性能优异:O(n)O(n)O(n)复杂度支持超长篇序列(如n=105n=10^5n=105),且长程依赖捕捉能力强于稀疏注意力
- 推理速度快:并行化实现让推理延迟远低于注意力机制,适合实时处理场景
- 局限性 :
- 语义理解精度:在短序列NLU任务(如情感分析)中,精度略逊于全注意力Transformer
- 多模态适配性:目前主要针对文本任务优化,在图像、音频等多模态场景的适配仍需探索
适用场景
超长篇序列处理(如n>10000n>10000n>10000)、实时推理场景(如语音实时转写、直播字幕生成)、资源受限设备(如手机端长文本处理)
4.1.6 注意力机制优化方向对比
| 优化方向 | 核心思路 | 复杂度 | 长程依赖能力 | 推理速度 | 典型应用场景 |
|---|---|---|---|---|---|
| 全注意力 | 全局关联计算 | O(n2)O(n^2)O(n2) | 强 | 慢 | 短序列NLU(如情感分析) |
| 稀疏注意力 | 局部/部分关联计算 | O(nk)O(nk)O(nk) | 中 | 中 | 中长序列(如文档摘要) |
| 线性注意力 | 核函数线性化计算 | O(n)O(n)O(n) | 中 | 快 | 超长篇序列(如DNA分析) |
| 记忆增强注意力 | 外部缓存存储长程信息 | O(nk)O(nk)O(nk) | 强 | 中 | 多轮对话、长文本建模 |
| SSM(如Mamba) | 线性递归替代注意力 | O(n)O(n)O(n) | 强 | 极快 | 超长篇实时处理(如直播字幕) |
4.2 高效模型架构设计
除了优化注意力机制本身,从模型整体架构层面进行稀疏化、模块化设计,也是提升效率的关键方向。核心思路是"在保持模型参数量和能力的同时,减少实际训练和推理时的计算量",主流方案包括混合专家模型(MoE)和稀疏结构化设计(SSD)。
4.2.1 混合专家模型(MoE:Mixture of Experts)
定义
一种"模块化+动态路由"的模型架构,将大模型拆分为多个独立的"专家网络(Expert)"和一个"门控网络(Gating Network)",训练和推理时仅激活部分专家网络,实现"大参数量+低计算量"的平衡。
核心背景
大模型的性能提升依赖参数量增加(Scaling Law),但全量参数训练和推理成本过高。MoE通过"稀疏激活"(仅用部分参数),在参数量达千亿/万亿级时,仍能保持计算量可控。
核心结构与原理
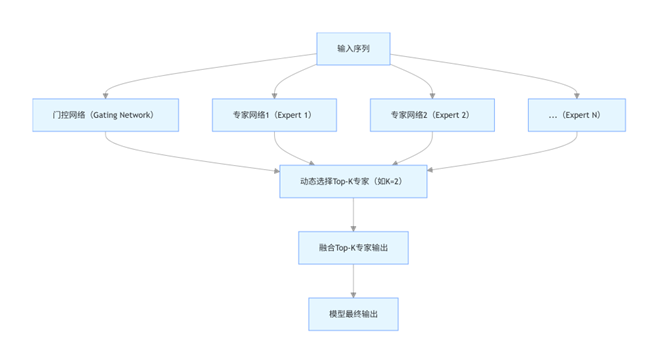
- 专家网络(Expert):多个结构相同的小型Transformer模块(如每个专家是一个6层Transformer块),各自负责处理不同类型的任务或数据(如专家1擅长处理语法,专家2擅长处理语义)
- 门控网络(Gating Network):轻量级网络(如单层全连接),根据输入token的特征,计算每个专家的"激活概率",选择概率最高的Top-K个专家(通常K=1或2)参与计算
- 动态路由与融合:输入token仅传递给Top-K专家,专家输出通过门控网络的概率加权融合,得到最终结果
关键创新:稀疏激活与负载均衡
- 稀疏激活:参数量虽大(如100个专家,每个专家1亿参数,总参数量100亿),但每次仅激活2个专家(实际计算量仅2亿参数),计算成本与2亿参数量的普通模型相当
- 负载均衡:门控网络易倾向于选择少数"表现好"的专家(导致负载不均),需通过"负载均衡损失(Load Balancing Loss)"优化,确保所有专家被均匀激活
代表模型:GPT-4(MoE版本)、PaLM-E
- GPT-4的MoE版本采用16个专家网络,每个专家负责不同的语义理解或生成任务,推理时激活2个专家,参数量达1.8万亿但计算量仅为全量模型的1/8
- PaLM-E(多模态MoE模型)将文本专家、图像专家、音频专家整合,门控网络根据输入模态动态选择对应专家,实现跨模态高效处理
优势与局限性
- 优势 :
- 参数量与计算量解耦:可通过增加专家数量提升模型能力,同时保持计算量可控
- 多任务适配性强:不同专家可针对性优化不同任务,门控网络动态匹配任务需求
- 局限性 :
- 内存占用高:所有专家的参数需同时存储在GPU显存中(如100亿参数量的MoE模型需约400GB显存),对硬件要求高
- 训练不稳定:门控网络的动态选择可能导致训练过程波动,需复杂的损失函数调控
适用场景
超大模型训练与推理(如千亿/万亿参数量模型)、多任务学习(如同时处理翻译、问答、摘要)、多模态融合(如文本+图像+音频)
4.2.2 稀疏结构化设计(SSD:Sparse Structured Design)
定义
通过固定的稀疏结构(如局部-全局模块组合、层间稀疏连接)设计模型,让模型在架构层面天然具备低复杂度特性,区别于MoE的"动态稀疏",SSD是"静态稀疏"的代表。
核心原理
基于"不同任务对模型结构的需求具有稀疏性"的假设,在模型设计时就剔除冗余的模块或连接,仅保留核心结构:
- 模块级稀疏:模型由"局部模块"和"全局模块"组成,局部模块处理短程依赖,全局模块处理长程依赖,两者按固定比例组合(如每4个局部模块配1个全局模块)
- 层间稀疏:不同层之间仅保留关键连接(如低层与高层的跨层连接),减少层间信息传递的冗余计算
代表模型:Sparse Transformer、Switch Transformer(MoE与SSD结合)
- Sparse Transformer:采用"局部注意力模块+全局注意力模块"的层间稀疏组合,每6个局部层插入1个全局层,在长序列任务中计算量比全注意力Transformer降低70%
- Switch Transformer:将MoE的动态专家与SSD的静态稀疏层结合,底层用局部稀疏层处理基础语义,高层用MoE专家处理复杂推理,实现"静态结构+动态激活"的双重高效
与MoE的区别
| 维度 | 稀疏结构化设计(SSD) | 混合专家模型(MoE) |
|---|---|---|
| 稀疏类型 | 静态稀疏(架构固定) | 动态稀疏(门控网络选择) |
| 计算量控制 | 架构设计时固定计算量 | 推理时动态调整计算量 |
| 硬件依赖 | 内存占用低(无冗余参数) | 内存占用高(需存储所有专家) |
| 适用场景 | 中大规模模型、特定任务优化 | 超大规模模型、多任务学习 |
优势与局限性
- 优势 :
- 训练推理稳定:静态结构无需动态选择,训练过程波动小,推理延迟可控
- 硬件适配性好:无冗余参数,内存占用低,适合部署在资源受限设备(如边缘计算设备)
- 局限性 :
- 灵活性差:稀疏结构固定,难以适配不同任务的动态需求(如同一模型处理短序列和长序列时,结构无法调整)
- 设计成本高:需通过大量实验验证稀疏结构的有效性,缺乏通用设计准则
适用场景
中大规模模型的高效部署(如BERT-base的稀疏版用于手机端)、特定长序列任务优化(如法律文档分析的专用稀疏模型)
4.3 工程优化方向
上述注意力机制和架构设计的优化,最终需要通过工程实现落地。工程优化的核心目标是"在现有硬件(GPU/TPU)和软件框架(PyTorch/TensorFlow)下,最大化模型的计算效率和内存利用率",无需改变模型核心原理,而是通过底层优化提升性能。其中,"上下文长度外推"是长序列处理场景中最关键的工程技术。
4.3.1 高效实现(Efficient Implementation)核心方向
工程优化涵盖内存访问、计算并行、数值精度等多个维度,常见方向包括:
- 内存优化:通过张量分片(Tensor Sharding)、混合精度训练(FP16/BF16)减少内存占用
- 计算并行:采用数据并行、模型并行、管道并行(Pipeline Parallelism)提升GPU利用率
- 算子优化:对核心算子(如Attention、Softmax)进行CUDA内核优化(如FlashAttention),减少内存带宽瓶颈
- 上下文长度外推:在不重新训练模型的前提下,扩展模型可处理的序列长度(如从512token扩展到4096token),是长序列工程优化的核心
4.3.2 上下文长度外推(Context Length Extrapolation)
定义
指模型在仅用短序列数据训练 (如n=512n=512n=512)的情况下,通过工程优化技术,在推理时能够处理更长的序列 (如n=4096n=4096n=4096),且性能无显著下降的技术。
核心背景
- 传统Transformer训练时的序列长度固定(如512token),若推理时输入更长序列(如1024token),会导致位置编码失效(如绝对位置编码超过训练范围)和注意力计算异常
- 重新用长序列训练模型成本极高(如训练n=4096n=4096n=4096的模型,计算量是n=512n=512n=512的64倍),上下文长度外推技术可大幅降低长序列适配成本
主流技术方案与原理
| 技术方案 | 核心原理 | 代表模型/工具 | 效果(训练n=512n=512n=512→推理n=4096n=4096n=4096) | 局限性 |
|---|---|---|---|---|
| ALiBi(Attention with Linear Biases) | 用"线性偏置"替代传统位置编码,偏置值与token间的相对距离成正比(距离越远,偏置越小),无需预定义位置编码 | ALiBi-BERT | 精度损失<5%,推理无额外成本 | 长程依赖捕捉能力随距离增加略有下降 |
| FlashAttention | 优化注意力计算的内存访问模式,将QKTQK^TQKT的中间结果分块存储在GPU高速缓存(SRAM)中,减少显存访问延迟 | FlashAttention-v2 | 内存占用降低50%,推理速度提升2-3倍 | 需修改底层CUDA算子,框架适配成本高 |
| RoPE(Rotary Position Embedding) | 通过"旋转矩阵"将位置信息编码到Q和K中,旋转角度与token的绝对位置相关,支持任意长度外推 | LLaMA、GPT-NeoX | 精度损失<3%,适配任意长序列 | 对极长序列(如n>105n>10^5n>105)的旋转计算略耗时 |
| NTK-Aware Scaling | 对RoPE的旋转频率进行缩放,让模型在长序列推理时,将未训练的长位置映射到训练过的短位置频率空间 | LLaMA-2(优化版) | 推理n=16384n=16384n=16384时精度损失<2% | 需针对不同模型调整缩放系数,通用性一般 |
典型案例:FlashAttention的内存优化逻辑
- 传统注意力计算的瓶颈在于"内存带宽":QKTQK^TQKT的中间结果(n×nn \times nn×n矩阵)需频繁在GPU显存(HBM)和计算单元(CUDA Core)之间传输,而显存带宽远低于计算速度
- FlashAttention通过"分块计算+SRAM缓存"优化:
- 将Q、K、V矩阵分割为多个小块(如128×128128 \times 128128×128),每次仅将一个块载入SRAM(高速缓存,带宽是显存的10倍以上)
- 在SRAM内完成该块的注意力计算(Softmax、加权求和),再将结果写回显存,避免大规模数据传输
- 效果:在n=4096n=4096n=4096的序列上,BERT的训练速度提升3倍,内存占用降低60%
适用场景
- 已有模型的长序列适配(如将预训练好的n=512n=512n=512的LLaMA扩展到n=8192n=8192n=8192)
- 长序列任务的推理加速(如文档问答、法律合同分析)
- 资源受限场景的模型部署(如用FlashAttention让大模型在普通GPU上运行)