摘要
知识图谱(KGs)长期以来一直是结构化知识表示和推理的基础设施。随着大型语言模型(LLMs)的出现,知识图谱的构建进入了一个新范式------从基于规则和统计的流程转向由语言驱动和生成性框架。本综述全面概述了LLM驱动的知识图谱构建的最新进展,系统性地分析了LLMs如何重塑经典的三层本体工程、知识提取和知识融合流程。
原文可在 https://t.zsxq.com/karhV 获取
我们首先重新审视传统的知识图谱方法,以建立概念基础,然后从两个互补的视角回顾新兴的LLM驱动方法:强调结构、规范化和一致性的基于模式的范式;以及强调灵活性、适应性和开放发现的非模式范式。在每个阶段,我们综合代表性框架,分析它们的技术机制,并识别它们的局限性。
最后,该综述概述了关键趋势和未来研究方向,包括LLMs的基于知识图谱的推理、代理系统的动态知识记忆和多模态知识图谱构建。通过这项系统性的综述,我们旨在阐明大型语言模型(LLMs)与知识图谱之间不断发展的相互作用,将符号化知识工程与神经语义理解相结合,以发展自适应、可解释和智能的知识系统。
核心速览
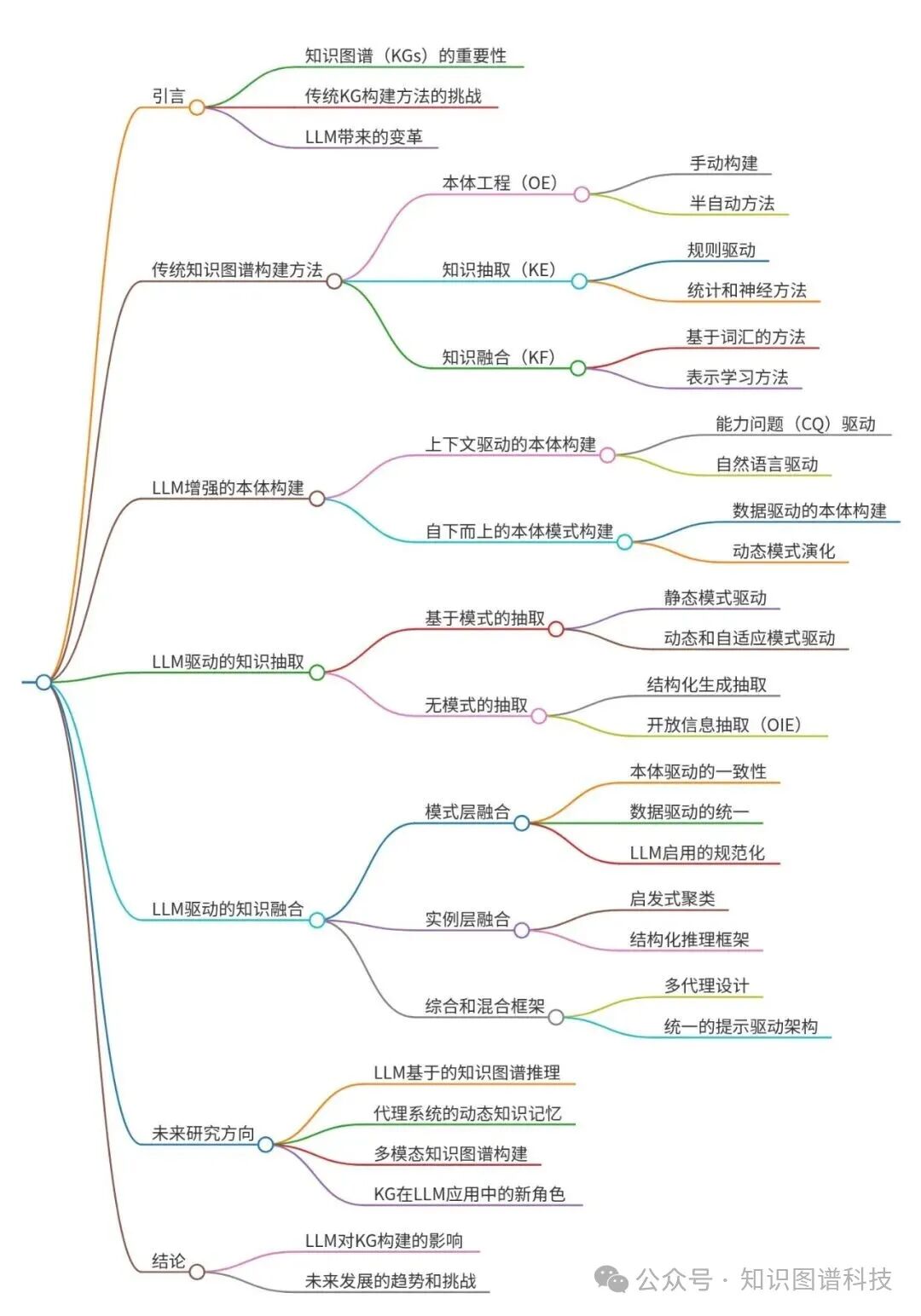
研究背景
- 研究问题:这篇文章要解决的问题是如何利用大型语言模型(LLMs)来增强知识图谱(KGs)的构建,从而克服传统方法在可扩展性、专家依赖性和管道碎片化方面的挑战。
- 研究难点:该问题的研究难点包括:如何在不依赖预定义模式的情况下从非结构化文本中提取知识,如何动态地整合异构知识源,以及如何在LLMs和知识表示之间建立协同作用。
- 相关工作:该问题的研究相关工作包括传统的知识图谱构建方法、基于规则的提取方法、统计方法和神经网络方法,以及最近利用LLMs进行知识图谱构建的研究。
研究方法
这篇论文提出了利用大型语言模型(LLMs)来增强知识图谱(KGs)构建的方法。具体来说,
-
本体工程 :传统的本体工程依赖于领域专家的手动构建,而LLMs可以通过自然语言处理技术辅助本体建模。论文介绍了两种方法:
- 能力问题(CQ)驱动的本体构建:LLMs解析能力问题或用户故事,识别、分类和形式化领域特定的概念、属性和关系。
- 自然语言驱动的本体构建:直接从非结构化文本中诱导语义模式,消除对明确问题的依赖。
-
知识提取 :知识提取的目标是从非结构化或半结构化数据中识别实体、关系和属性。论文介绍了两种主要方法:
- 结构化生成提取:通过引导推理、模块化提示和交互式细化,内部化潜在的关系结构。
- 开放信息提取(OIE):发现文本中所有可能的实体-关系-对象三元组,优先覆盖和发现而非结构规则性。
- 静态模式驱动的提取:使用预定义的本体结构确保精度和可解释性。
- 动态和自适应的模式驱动提取:将模式视为提取过程中的动态、演化组件。
- 基于模式的提取:依赖于显式的知识模式,强调规范化、结构一致性和语义对齐。
- 无模式的提取:直接从非结构化文本中获取结构化知识,不依赖于任何预定义的本体或关系模式。
-
知识融合 :知识融合的重点在于整合异构知识源,解决重复、冲突和异质性问题。论文介绍了三种主要方法:
- 模式层融合:统一知识图的结构骨干,确保所有知识遵循统一的概念规范。
- 实例层融合:通过实体对齐、消歧、去重和冲突解决,整合具体的知识实例。
- 综合和混合框架:将模式层和实例层融合整合到一个端到端的流程中,超越传统的模块化管道,转向集成的、提示驱动的架构。
结果与分析
- 本体工程:LLMs在能力问题驱动的本体构建中表现出色,能够自动识别和形式化领域特定的概念和关系。自然语言驱动的本体构建也显示出巨大的潜力,能够直接从文本中诱导出高质量的本体结构。
- 知识提取:基于模式的提取方法在初期阶段表现良好,但缺乏灵活性。动态和自适应的模式驱动提取方法显著提高了提取的灵活性和适应性。无模式的提取方法在开放信息提取中表现出色,能够发现文本中的所有可能三元组。
- 知识融合:模式层融合从基于本体的对齐转向数据驱动的对齐,最终实现LLMs启用的规范化。实例层融合通过结构化和推理方法显著提高了对齐的精度。综合和混合框架展示了集成、自适应和生成融合系统的潜力。
总体结论
这篇论文全面概述了LLMs在知识图谱构建中的应用,展示了从规则驱动和模块化管道向统一、自适应和生成框架的转变。尽管取得了显著进展,但在可扩展性、可靠性和持续适应方面仍存在挑战。未来的研究将集中在提示设计、多模态集成和基于知识的推理上,以实现自主和可解释的知识中心AI系统。
论文评价
优点与创新
- 全面的综述:论文系统地回顾了近年来LLM(大型语言模型)在知识图谱(KG)构建中的应用,涵盖了本体工程、知识提取和知识融合三个阶段。
- 多种方法对比:详细分析了基于模式的抽取方法和无模式的抽取方法,展示了不同方法的优缺点。
- 未来研究方向:提出了未来研究的几个关键方向,包括基于KG的推理、动态知识记忆和多模态KG构建。
- 技术机制分析:对代表性框架的技术机制进行了详细分析,揭示了其局限性和优势。
- 系统化的研究框架:论文通过系统化的研究框架,清晰地展示了LLM与知识图谱之间的演变关系,促进了符号化知识工程与神经语义理解之间的融合。
不足与反思
- 可扩展性和可靠性:尽管取得了显著进展,但论文指出当前方法在可扩展性、可靠性和持续适应方面仍存在挑战。
- 提示设计:未来的研究需要进一步改进提示设计,以提高模型的性能和适应性。
- 多模态集成:需要更好地整合多模态数据,以应对模态异质性、对齐噪声、可扩展性和在缺失或不平衡模态下的鲁棒性问题。
- 知识驱动的推理:未来的研究应更加注重知识驱动的推理,以实现更强大和自动化的知识图谱构建,形成一个自我改进的良性循环
关键问题及回答
问题1:在知识提取方面,LLM-driven的方法在处理静态模式和动态模式时有哪些具体的技术改进?
-
静态模式驱动的提取:早期方法使用完全预定义的本体结构来确保精度和可解释性。例如,Kommineni等人在2024年提出的框架使用预定义的本体结构来指导LLM生成Competency Questions (CQs),并在明确的模式监督下进行ABox填充。这种方法虽然确保了高精度,但缺乏灵活性。
-
动态和自适应的模式驱动提取:最近的方法重新构思了模式作为提取过程中的动态、演化组件。例如,AutoSchemaKG在2025年提出通过无监督聚类和关系发现从大规模语料库中诱导模式,并使用多阶段提示来使模式与提取内容一起迭代演化,从而提高开放域的可扩展性。AdaKGC在2023年通过Schema-Enriched Prefix Instruction (SPI) 和 Schema-Constrained Dynamic Decoding (SDD) 机制解决了模式漂移问题,允许模型在不重新训练的情况下纳入新关系和实体类型。
这些改进使得LLM能够在提取过程中动态调整模式,从而提高提取的灵活性和适应性。
问题2:在知识融合方面,模式层融合、实例层融合和综合框架各自解决了哪些具体问题?
- 模式层融合:模式层融合统一了知识图的结构骨干,确保所有知识遵循统一的概念规范。其发展历程包括:
- 本体驱动的一致性:早期工作依赖于显式的本体作为全局约束,如Kommineni等人在2024年提出的框架通过将提取的三元组与预定义的本体定义对齐来实现高语义一致性,但跨域灵活性有限。
- 数据驱动的统一:为了克服这种刚性问题,LKD-KGC在2025年引入了自适应的、基于嵌入的模式集成,通过向量聚类和LLM驱动的去重自动提取和合并等效的实体类型,使模式对齐能够从数据中动态演变。
- LLM启用的规范化:最近的方法如EDC在2024年通过提示LLM生成模式组件的自然语言定义,并通过向量相似性比较支持自对齐和跨模式映射,从而提高了自动化和语义精度。
- 实例层融合:实例层融合通过实体对齐、消歧、去重和冲突解决,整合具体的知识实例。其发展历程包括:
- 启发式聚类:早期工作如KGGEN在2025年使用迭代LLM引导的聚类来合并等效的实体和关系,通过逐步三元组提取和语义分组揭示语义相关的实体。
- 结构化和推理方法:后来的工作如LLM-Align在2024年将对齐重构为上下文推理任务,使用多步提示增强语义区分,将对齐视为受限制的多种选择问题,而EntGPT在2025年引入了两阶段改进管道,首先生成候选实体,然后应用目标推理进行最终选择,显著提高了对齐精度。
- 结构和检索线索:最近的工作如Pons等人在2025年利用RAG融合来利用类-子类层次结构和实体描述进行零样本消歧,通过图拓扑结合结构和信息检索线索实现更稳健的推理。
- 综合和混合框架:综合和混合框架将模式层和实例层融合整合到一个端到端的流程中,超越传统的模块化管道,转向集成的、提示驱动的架构。例如,KARMA在2025年展示了多代理设计,专门处理模式对齐、冲突解决和质量评估,实现可扩展性和全局一致性。ODKE+在2025年通过本体引导的工作流程将模式监督和实例级验证耦合在一起,提高了语义保真度。Graphusion在2024年引入了一个统一的、提示驱动范式,在单个生成周期内执行所有融合子任务------对齐、巩固和推理。
这些方法分别解决了知识融合中的结构统一、实例整合和综合处理问题,推动了知识图谱构建向自主、自演变的方向发展。
问题3:未来在LLM和知识图谱的集成方面,有哪些有前景的研究方向?
-
基于知识图谱的推理:未来工作预计将进一步将结构化知识图谱集成到LLMs的推理机制中,增强其逻辑一致性、因果推理和可解释性。高质量、结构良好的知识图谱将为可解释和可验证的模型推理提供基础。现有研究如KG-based Random-Walk Reasoning和KG-RAR展示了这一范式的潜力,但如何增强推理能力以支持更稳健和自动化的知识图谱构建仍然是一个关键挑战。
-
动态知识记忆:实现LLMs驱动的智能体自主性需要克服有限上下文窗口的限制,通过持久、结构化的记忆实现。最近的架构如A-MEM和Zep将知识图谱视为动态内存基底,随着代理互动不断演变,而不是存储静态历史记录。未来的研究将集中在提高可扩展性、时间一致性和多模态集成上,以实现完全自主、知识驱动的智能体。
-
多模态知识图谱构建:多模态知识图谱(MMKG)构建旨在将文本、图像、音频和视频等异构模态整合为统一的结构化表示,从而实现更丰富的推理和跨模态对齐。代表性工作如VaLiK通过预训练的Vision-Language Models(VLMs)将视觉特征转换为文本形式,然后通过跨模态验证模块过滤噪声并组装MMKGs。未来的研究将解决模态异质性、对齐噪声、可扩展性和在缺失或不平衡模态下的鲁棒性等关键挑战