结构化并发(Structured Concurrency) 最初由 JEP 428 提出,并在 JDK 19 中作为孵化 API 发布,接着又在 JDK 20 中通过 JEP 437 再次孵化,现在该特性进入预览版本了。结构化并发是一种多线程编程方法,它将在不同线程中运行的相关任务组视为单个工作单元,从而简化错误处理和取消操作,提高程序的可靠性和可观察性。
结构化并发和虚拟线程、作用域值一样,都是由 Loom 项目发展而来。
那么到底什么是结构化并发呢?我们不妨从结构化编程的概念开始聊起。
结构化编程(Structured Programming)
计算机发展的早期,程序员必须使用很低级的编程语言去写程序,比如汇编语言,通过一条条的硬件指令去操作计算机,这种编程方式非常痛苦;于是一些计算机界大佬便开始着手重新设计编程语言,使用类似英语的语句来表达操作,这就诞生了一批比汇编语言稍微高级一点的编程语言,如 FORTRAN、FLOW-MATIC、COBOL 等。
这些语言和现在我们所使用的 Java 或者 C 等高级语言还是有一些差距的,没有函数代码块,没有条件或循环控制语句,这些现在看来稀松平常的特性当时还没有被发明出来。设想一下如果程序只能从上往下顺序执行,那么我们就不能复用之前已经编写过的逻辑,想要重新执行一遍之前的逻辑,就得把前面的代码重写一遍,很显然这是非常麻烦的,所以一些设计者在语言中加入了 GOTO 语句,可以让程序在执行时跳转到指定位置,从而实现代码复用。
GOTO 语句的发明使得编程语言变得更加强大,但是这种跳转执行的逻辑使得程序充满了不确定性,一旦程序中大量使用了 GOTO 语句,整个代码就会变得一团糟:

这种代码如同面条一般,所以被形象地戏称为 面条式代码(Spaghetti Code)。
1968 年 3 月,荷兰计算机科学家 Edsger W. Dijkstra 发表了一篇文章 Goto Statement Considered Harmful,提出了著名的 GOTO 有害论;后来,他又编写了一部札记 Notes on Structured Programming,通过大量的篇幅详细阐述了他理想中的编程范式,首次提出了 结构化编程(Structured Programming) 的概念。
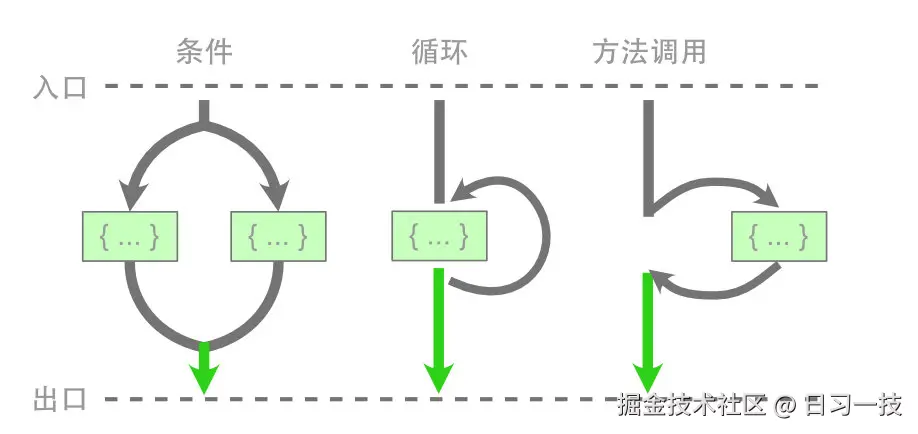
结构化编程的核心思想是 基于块语句,实现代码逻辑的抽象与封装,从而保证控制流拥有单一的入口与出口,现代编程语言中的条件语句、循环语句、方法调用都是结构化编程的体现,我们基于现代编程语言所编写的程序,基本上都是结构化的。
相比 GOTO 语句,结构化编程使代码逻辑变得更加清晰,思维模型变得更加简单;如今,大部分现代编程语言都已经禁用 GOTO 语句,尽管 break 和 continue 语句仍然可以实现跳转逻辑,但是他们还是遵循结构化的基本原则:控制流拥有单一的入口与出口。
少部分编程语言仍然支持
GOTO,但是它们大都遵循高德纳所提出的前进分支和后退分支不得交叉的原则。
结构化并发(Structured Concurrency)
了解了结构化编程的历史后,我们再来看看什么是结构化并发。假设我们有两个独立的任务 task1 和 task2 需要执行,由于它们之间互不影响,我们可以使用 ExecutorService 来并发执行:
java
private static void testExecutorService() throws Exception {
System.out.println("main thread start");
ExecutorService executor = Executors.newCachedThreadPool();
Future<Integer> f1 = executor.submit(() -> task1(0));
Future<Integer> f2 = executor.submit(() -> task2(0));
System.out.println(f1.get());
System.out.println(f2.get());
System.out.println("main thread end");
executor.shutdown();
}通过 submit 提交任务,并通过 get 等待任务执行结束,代码非常简单,整个流程也非常顺利。然而,真实情况却未必如此,由于子任务并发执行,每个子任务都可能成功或失败,当某个子任务失败时,我们要考虑的事情可能会变得出乎意料地复杂:
- 如果
task1运行失败,那么在调用f1.get()时会抛出异常,但task2将继续在其自己的线程中运行,这是一种线程泄漏,不仅浪费资源,而且可能会干扰其他任务; - 如果
task2运行失败,由于先执行f1.get(),会阻塞等待task1运行结束才会执行f2.get()抛出异常,task1可能会执行很久,这是一种不必要的等待; - 如果主线程被中断,该中断不会传播到子任务中,
task1和task2线程都会泄漏; - 另一种场景中,如果我们只需要
task1和task2中的任意一个结果,这又该如何实现?
其实以上这些场景都可以实现,但需要极其复杂、难以维护的代码,比如 这里 使用 CompletableFuture 演示了三个子任务之间互相取消的场景,其代码的复杂程度应该会吓坏不少人。
此外,这类代码也不好调试,通过线程转储,我们会得到一堆名为 "pool-X-thread-Y" 的线程,我们无法知道哪个子线程属于哪个主线程,每个子线程的运行就像非结构化编程中的 GOTO 一样,不知道会跳转到哪里。这种情况被称为 非结构化并发(Unstructured Concurrency)。我们的任务在一张错综复杂的线程网中运行,其开始与结束在代码中难以察觉,缺乏清晰的错误处理机制,当主线程结束时,常常会出现孤立线程的情况。
结构化并发(Structured Concurrency) 正是为解决这些问题而提出的,它的核心思想和结构化编程一样:在并发模型下,也要保证控制流拥有单一的入口与出口。程序可以产生多个子线程来实现并发,但是所有子线程最终都要在统一的出口处完成合并:
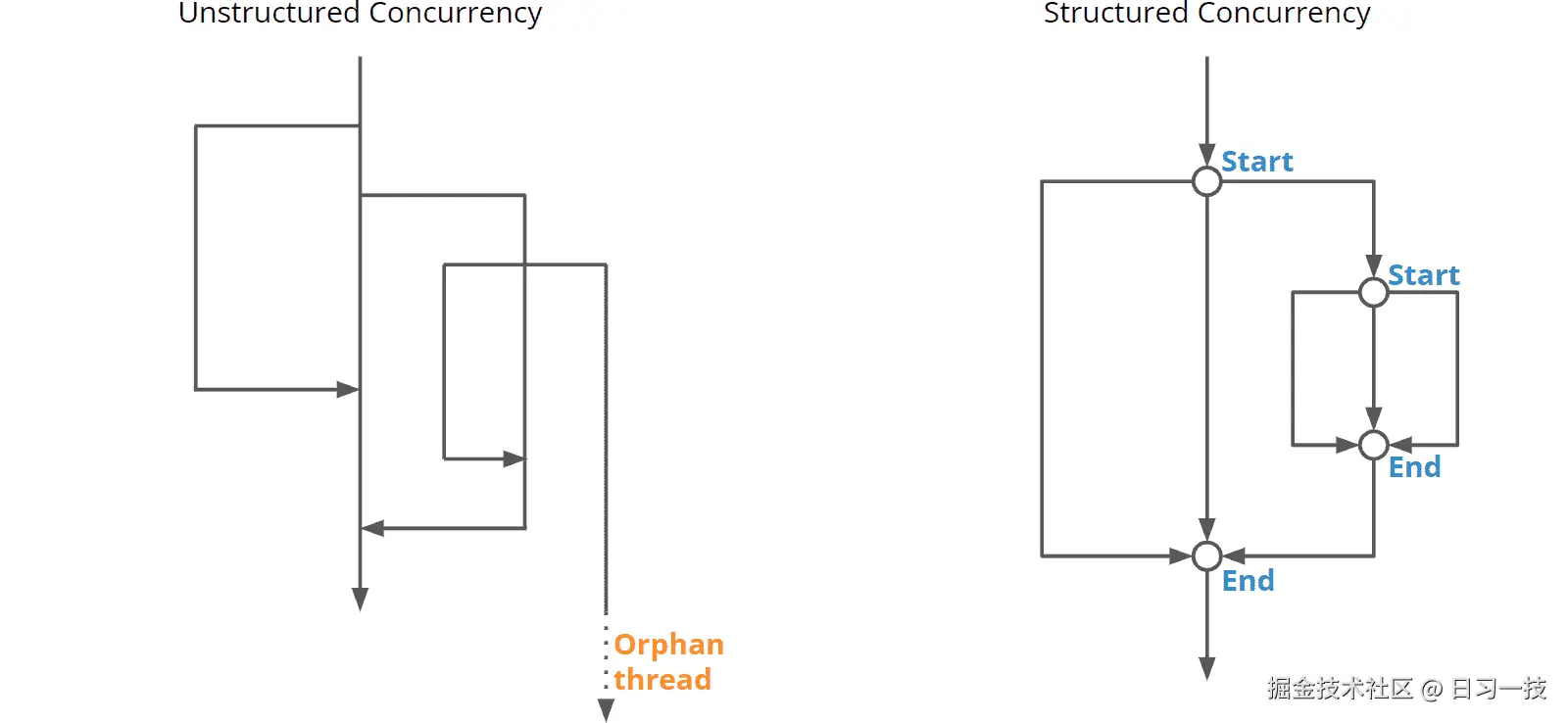
使用结构化并发有着诸多好处:
- 在出口处,所有子线程都应该处于完成或取消状态,所以子线程的开始和结束变得清晰可见,这使得代码更易于阅读和维护;
- 子线程发生的错误能传播到父线程中,父线程的取消也能传播到子线程中,从而简化了线程之间的错误处理和状态控制;
- 另外,线程转储还可以保持父线程与子线程之间的调用层次结构,增强了可观察性,有助于程序调试。
使用 StructuredTaskScope 实现结构化并发
在 Java 中,实现结构化并发的基本 API 是 StructuredTaskScope,它的基本用法如下:
java
private static void testStructuredTaskScope() throws Exception {
System.out.println("main thread start");
try (var scope = new StructuredTaskScope<Object>()) {
Subtask<Integer> t1 = scope.fork(() -> task1(0));
Subtask<Integer> t2 = scope.fork(() -> task2(0));
scope.join();
System.out.println(t1.get());
System.out.println(t2.get());
}
System.out.println("main thread end");
}这里实现了和之前代码同样的逻辑,只是写法上略有区分,我们将 ExecutorService 替换为 StructuredTaskScope,并将 executor.submit() 替换为 scope.fork(),然后使用 scope.join() 等待所有任务完成。之后,我们可以通过 Subtask.get() 读取子任务的结果,如果某个子任务发生异常,Subtask.get() 会抛出 IllegalStateException 异常。因此,在调用 get() 之前,最好先用 state() 查询子任务的状态:
java
if (t1.state() == Subtask.State.SUCCESS) {
System.out.println(t1.get());
} else {
System.out.println("task1 error: " + t1.exception().getMessage());
}StructuredTaskScope 的关闭策略
scope.join() 可以保证所有子线程全部处于完成或取消状态,这样可以消除孤儿线程的风险。但是在有些场景下,如果某个子线程异常,等待其他子任务的结果就没有了意义,这时我们可以取消其他子任务,避免无谓的等待;还有些情况是,只要有一个子任务运行成功即可,无需等待所有任务都运行结束。这就引出了 StructuredTaskScope 的 关闭策略(Shutdown policies) ,StructuredTaskScope 定义了两种关闭策略,分别处理这两种情况:
ShutdownOnFailure 策略
使用 ShutdownOnFailure 策略,当某个子任务中发生异常时,将导致所有其他子任务终止。它的使用方法如下所示:
java
private static void testStructuredTaskScopeShutdownOnFailure() throws Exception {
System.out.println("main thread start");
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Subtask<Integer> t1 = scope.fork(() -> task1(1));
Subtask<Integer> t2 = scope.fork(() -> task2(0));
scope.join().throwIfFailed();
System.out.println(t1.get());
System.out.println(t2.get());
}
System.out.println("main thread end");
}首先,我们使用 new StructuredTaskScope.ShutdownOnFailure() 创建一个 ShutdownOnFailure 策略的 StructuredTaskScope,然后在 scope.join() 的时候,通过 throwIfFailed() 让其在子任务失败时抛出异常。假设 task1 异常,运行结果如下:
php
main thread start
task1 start
task2 start
java.lang.InterruptedException
at java.base/java.lang.VirtualThread.sleepNanos(VirtualThread.java:805)
at java.base/java.lang.Thread.sleep(Thread.java:507)
at StructuredConcurrencyDemo.task2(StructuredConcurrencyDemo.java:91)
at StructuredConcurrencyDemo.lambda$9(StructuredConcurrencyDemo.java:130)
at java.base/java.util.concurrent.StructuredTaskScope$SubtaskImpl.run(StructuredTaskScope.java:889)
at java.base/java.lang.VirtualThread.run(VirtualThread.java:311)
task2 end
Exception in thread "main" java.util.concurrent.ExecutionException: java.lang.RuntimeException: code is illegal
at java.base/java.util.concurrent.StructuredTaskScope$ShutdownOnFailure.throwIfFailed(StructuredTaskScope.java:1318)
at java.base/java.util.concurrent.StructuredTaskScope$ShutdownOnFailure.throwIfFailed(StructuredTaskScope.java:1295)
at StructuredConcurrencyDemo.testStructuredTaskScopeShutdownOnFailure(StructuredConcurrencyDemo.java:131)
at StructuredConcurrencyDemo.main(StructuredConcurrencyDemo.java:14)
Caused by: java.lang.RuntimeException: code is illegal
at StructuredConcurrencyDemo.task1(StructuredConcurrencyDemo.java:74)
at StructuredConcurrencyDemo.lambda$8(StructuredConcurrencyDemo.java:129)
at java.base/java.util.concurrent.StructuredTaskScope$SubtaskImpl.run(StructuredTaskScope.java:889)
at java.base/java.lang.VirtualThread.run(VirtualThread.java:311)可以看到当 task1 异常时,task2 出现了 InterruptedException,说明 task2 被中断了,从而避免了无谓的等待。
ShutdownOnSuccess 策略
使用 ShutdownOnSuccess 策略,只要某个子任务中成功,将导致所有其他子任务终止。它的使用方法如下所示:
java
private static void testStructuredTaskScopeShutdownOnSuccess() throws Exception {
System.out.println("main thread start");
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<Object>()) {
scope.fork(() -> task1(0));
scope.fork(() -> task2(0));
scope.join();
System.out.println(scope.result());
}
System.out.println("main thread end");
}首先,我们使用 new StructuredTaskScope.ShutdownOnSuccess<Object>() 创建一个 ShutdownOnSuccess 策略的 StructuredTaskScope,然后通过 scope.join() 等待子任务结束,任意一个子任务结束,整个 StructuredTaskScope 都会结束,并保证其他子任务被取消,最后通过 scope.result() 获取第一个运行成功的子任务结果。运行结果如下:
less
main thread start
task1 start
task2 start
task2 end
2
java.lang.InterruptedException
at java.base/java.lang.VirtualThread.sleepNanos(VirtualThread.java:805)
at java.base/java.lang.Thread.sleep(Thread.java:507)
at StructuredConcurrencyDemo.task1(StructuredConcurrencyDemo.java:78)
at StructuredConcurrencyDemo.lambda$10(StructuredConcurrencyDemo.java:142)
at java.base/java.util.concurrent.StructuredTaskScope$SubtaskImpl.run(StructuredTaskScope.java:889)
at java.base/java.lang.VirtualThread.run(VirtualThread.java:311)
task1 end
main thread end可以看到当 task2 最先运行结束,所以输出了 task2 的结果,同时 task1 出现了 InterruptedException,说明 task1 被中断了,避免了线程泄露。
自定义关闭策略
如果这两个标准策略都不满足你的需求,我们还可以编写自定义的策略,通过继承 StructuredTaskScope 类,并重写其 handleComplete(...) 方法,从而实现不同于 ShutdownOnSuccess 和 ShutdownOnFailure 的策略。这里 有一个自定义关闭策略的示例可供参考。
可观察性
使用结构化并发的另一个好处是,线程是有层次结构的,我们可以从线程转储中看到某个主线程都派生了哪些子线程,也可以看出某个子线程来自于哪个主线程,从而方便问题排查。使用下面的命令以 JSON 格式进行线程转储:
ini
$ jcmd <pid> Thread.dump_to_file -format=json threads.json从转储结果中可以清晰的看到线程之间的层次结构:
json
{
"container": "java.util.concurrent.StructuredTaskScope$ShutdownOnSuccess@58644d46",
"parent": "<root>",
"owner": "1",
"threads": [
{
"tid": "19",
"name": "",
"stack": [
"java.base\/java.lang.VirtualThread.parkNanos(VirtualThread.java:631)",
"java.base\/java.lang.VirtualThread.sleepNanos(VirtualThread.java:803)",
"java.base\/java.lang.Thread.sleep(Thread.java:507)",
"StructuredConcurrencyDemo.task1(StructuredConcurrencyDemo.java:78)",
"StructuredConcurrencyDemo.lambda$10(StructuredConcurrencyDemo.java:142)",
"java.base\/java.util.concurrent.StructuredTaskScope$SubtaskImpl.run(StructuredTaskScope.java:889)",
"java.base\/java.lang.VirtualThread.run(VirtualThread.java:311)"
]
},
{
"tid": "21",
"name": "",
"stack": [
"java.base\/java.lang.VirtualThread.parkNanos(VirtualThread.java:631)",
"java.base\/java.lang.VirtualThread.sleepNanos(VirtualThread.java:803)",
"java.base\/java.lang.Thread.sleep(Thread.java:507)",
"StructuredConcurrencyDemo.task2(StructuredConcurrencyDemo.java:92)",
"StructuredConcurrencyDemo.lambda$11(StructuredConcurrencyDemo.java:143)",
"java.base\/java.util.concurrent.StructuredTaskScope$SubtaskImpl.run(StructuredTaskScope.java:889)",
"java.base\/java.lang.VirtualThread.run(VirtualThread.java:311)"
]
}
],
"threadCount": "2"
}小结
今天我们学习了 Java 21 中的 结构化并发(Structured Concurrency) 特性,这是 Loom 项目的重要成果,它借鉴了结构化编程的核心思想,将并发编程中的多个子任务视为单个工作单元进行统一管理。主要内容包括:
- 核心思想 - 结构化并发将结构化编程的原则引入并发编程,保证控制流拥有单一的入口与出口。所有子线程在统一的出口处完成合并,使得任务的开始与结束变得清晰可见,代码逻辑更易于理解和维护,这一设计有效解决了传统非结构化并发中的线程泄漏、错误处理复杂、可观察性差等问题;
StructuredTaskScopeAPI - Java 提供了StructuredTaskScope作为实现结构化并发的基础 API,它通过fork()提交任务,通过join()等待任务完成,为子任务的生命周期管理提供了清晰的语义。同时通过关闭策略(如ShutdownOnFailure和ShutdownOnSuccess)来满足不同的并发场景需求,还支持自定义关闭策略以应对复杂的业务逻辑;- 增强的可观察性 - 结构化并发带来的一个重要好处是线程之间拥有清晰的层次结构。通过
jcmd工具生成的线程转储能够直观地展示父线程与子线程的关系,这对于问题排查和性能分析提供了极大的便利,使得高并发应用的调试与维护变得更加高效。
结构化并发与虚拟线程、作用域值等特性共同构成了 Java 高性能并发编程的新范式,有望为 Java 应用程序的构建方式带来深刻的变革。当这些特性结合使用时,开发者将能够编写更加清晰、可靠、易于维护的高吞吐量并发应用程序,这对 Java 在云计算、微服务和高并发场景中的应用具有重要意义。
欢迎关注
如果这篇文章对您有所帮助,欢迎关注我的同名公众号:日习一技,每天学一点新技术。
我会每天花一个小时,记录下我学习的点点滴滴。内容包括但不限于:
- 某个产品的使用小窍门
- 开源项目的实践和心得
- 技术点的简单解读
目标是让大家用5分钟读完就能有所收获,不需要太费劲,但却可以轻松获取一些干货。不管你是技术新手还是老鸟,欢迎给我提建议,如果有想学习的技术,也欢迎交流!