Llama-2-7b 昇腾 NPU 测评总结:核心性能数据、场景适配建议与硬件选型参考
本文为适配大模型国产化部署需求,以 Llama-2-7b 为对象,在 GitCode Notebook 昇腾 NPU(910B)环境中完成从依赖安装到模型部署的全流程落地,并通过六大维度测评验证:单请求吞吐量稳定 15.6-17.6 tokens / 秒,batch=4 时总吞吐量达 63.33 tokens / 秒,16GB 显存即可支撑高并发,最终提供可复现的部署方案、性能基准数据及硬件选型建议,助力高效落地国产算力大模型应用。
GitCode控制台Notebook启动配置
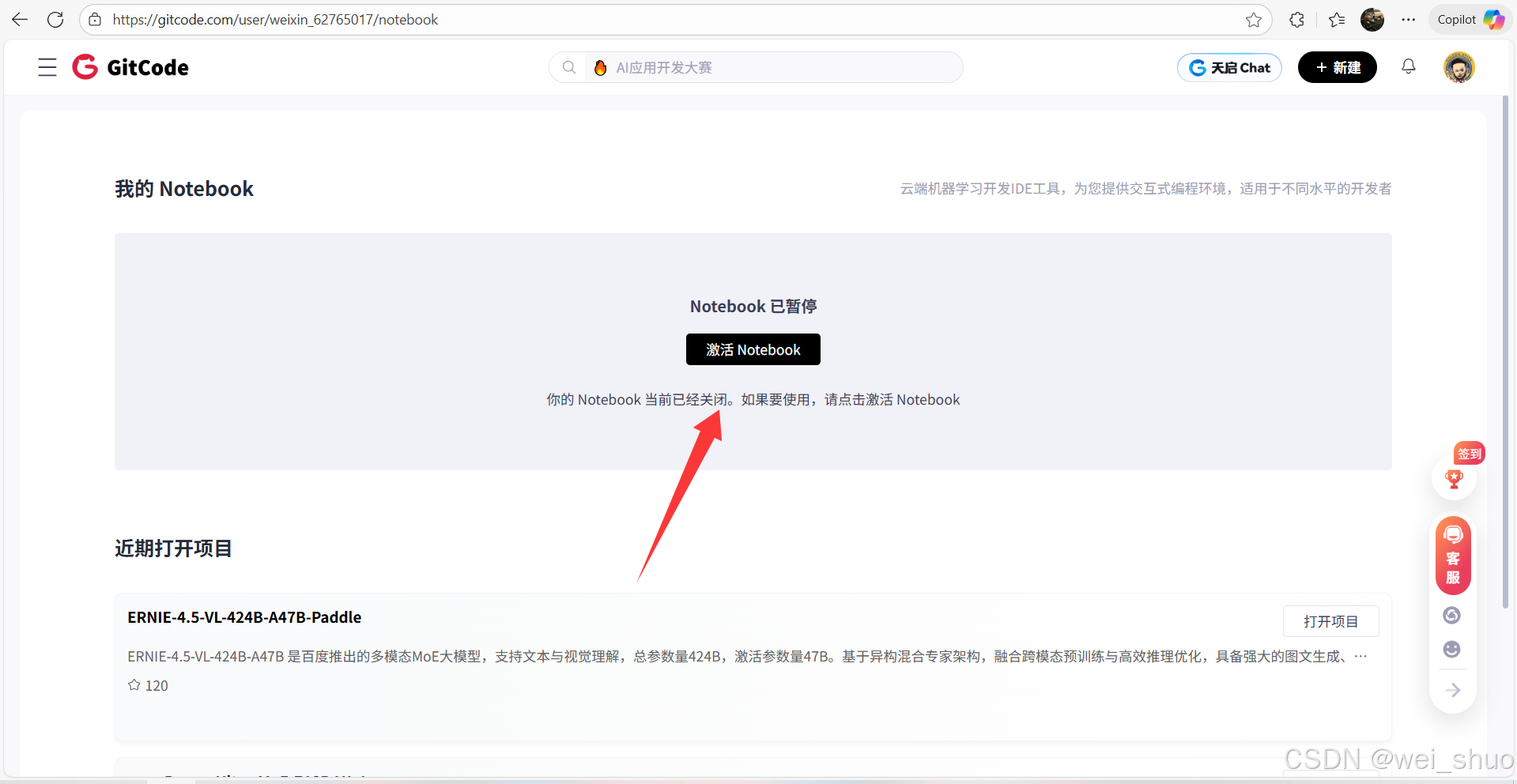
1、GitCode工作台激活 Notebook
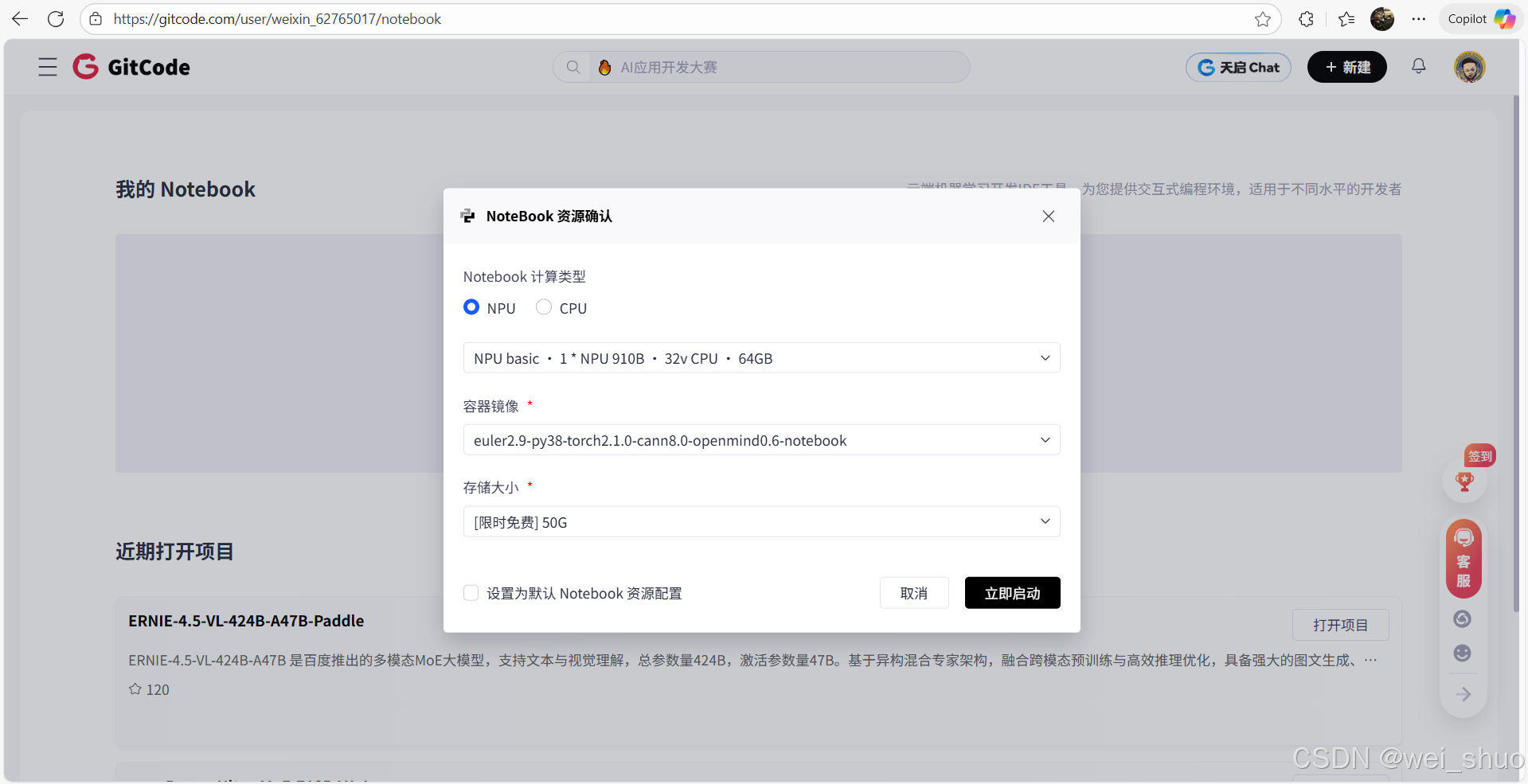
2、Notebook 资源配置选择
- 计算类型:NPU
- 硬件规格:NPU basic · 1*NPU 910B · 32v CPU · 64GB
- 存储大小:限时免费 50G
3、等待 Notebook 启动以及配置默认资源
4、进入 Terminal 终端
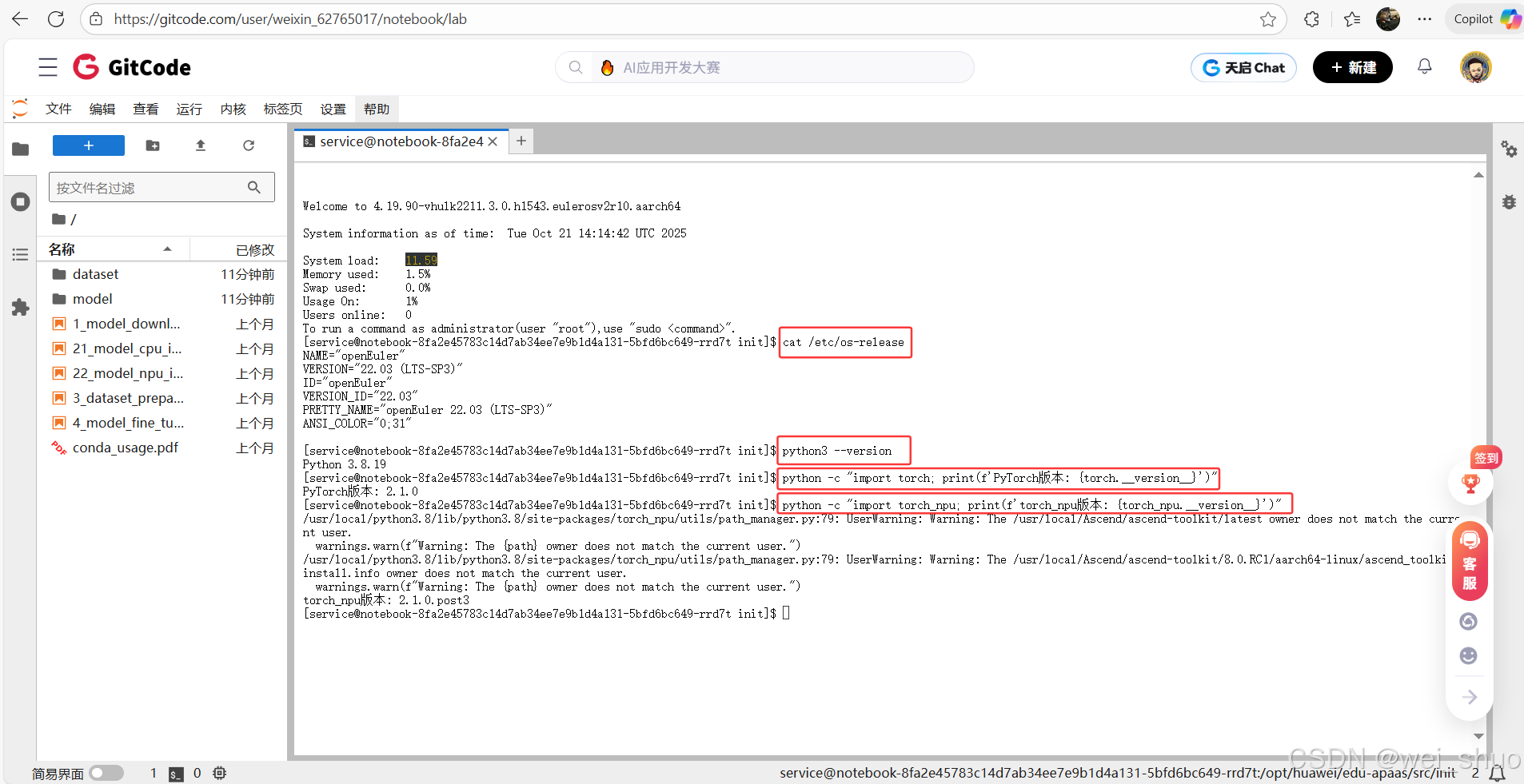
5、检查深度学习环境核心配置,包括操作系统、Python、PyTorch 及昇腾 NPU 适配库 torch_npu 的版本,确认环境兼容以保障任务运行
bash# 检查系统版本 cat /etc/os-release # 检查python版本 python3 --version # 检查PyTorch版本 python -c "import torch; print(f'PyTorch版本: {torch.__version__}')" # 检查torch_npu python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"
依赖安装
1、通过国内镜像快速安装深度学习所需的模型工具库和硬件加速配置工具:transformers、accelerate
bashpip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
部署Llama大模型
1、编写llama.py文件并保存
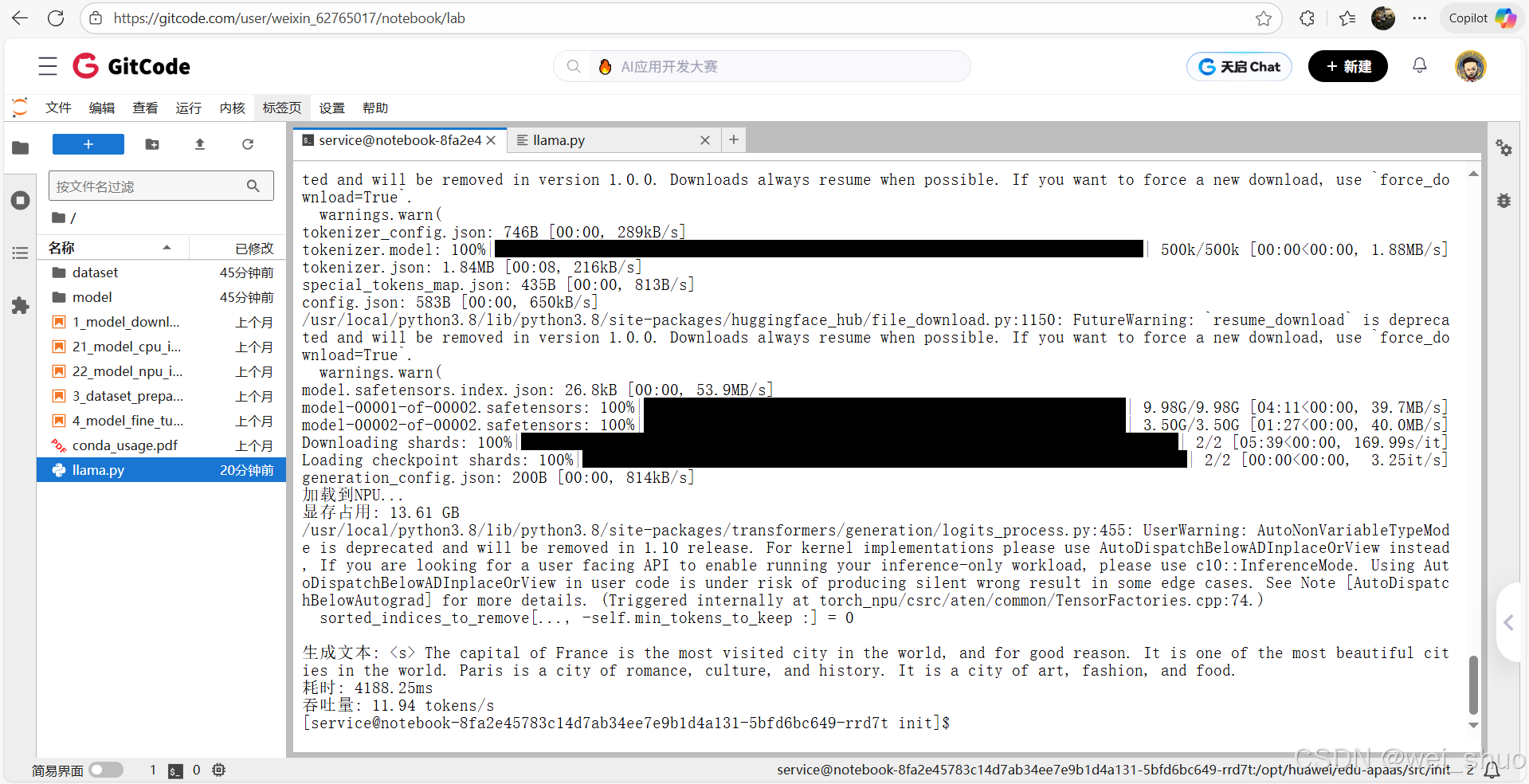
pythonimport torch import torch_npu from transformers import AutoModelForCausalLM, AutoTokenizer import time print("开始测试...") # 使用开放的Llama镜像 MODEL_NAME = "NousResearch/Llama-2-7b-hf" print(f"下载模型: {MODEL_NAME}") tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) model = AutoModelForCausalLM.from_pretrained( MODEL_NAME, torch_dtype=torch.float16, low_cpu_mem_usage=True ) print("加载到NPU...") model = model.npu() model.eval() print(f"显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB") # 简单测试 prompt = "The capital of France is" inputs = tokenizer(prompt, return_tensors="pt") inputs = {k: v.npu() for k, v in inputs.items()} # 对每个张量单独转移到NPU start = time.time() outputs = model.generate(**inputs, max_new_tokens=50) end = time.time() text = tokenizer.decode(outputs[0]) print(f"\n生成文本: {text}") print(f"耗时: {(end-start)*1000:.2f}ms") print(f"吞吐量: {50/(end-start):.2f} tokens/s")2、终端查看是否保存成功
3、将 Hugging Face 模型的下载源临时切换到国内镜像站
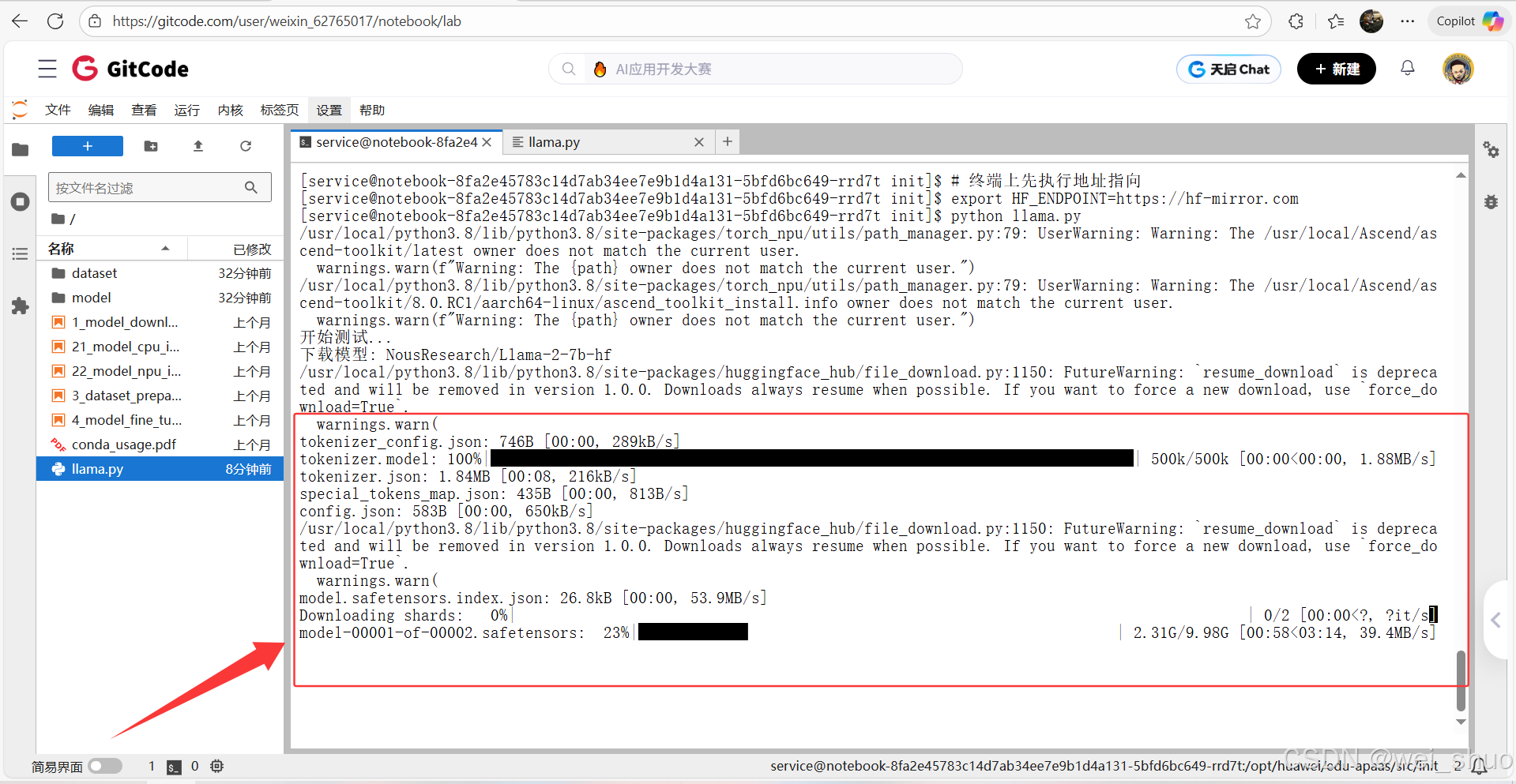
bashexport HF_ENDPOINT=https://hf-mirror.com4、运行llama.py脚本文件,并等待下载安装
5、部署Llama成功
昇腾 NPU 部署 Llama大模型测评
前提准备:测评脚本编写
1、编写测评脚本代码 Test.py
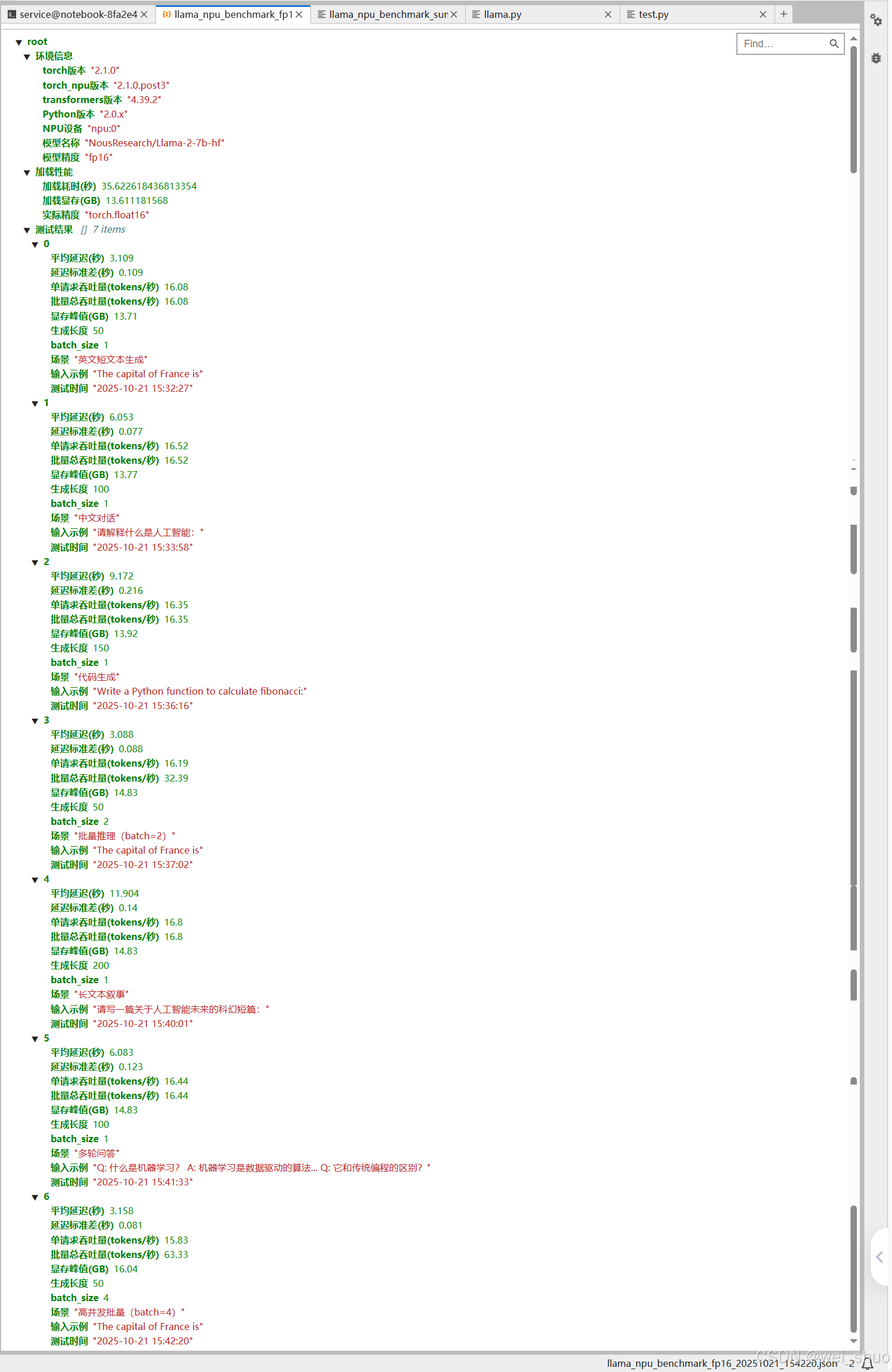
pythonimport torch import torch_npu import time import json import pandas as pd from datetime import datetime import transformers # 显式导入transformers模块 from transformers import AutoModelForCausalLM, AutoTokenizer # ===================== 全局配置区(用户仅需修改这里) ===================== MODEL_NAME = "NousResearch/Llama-2-7b-hf" # 模型名称 DEVICE = "npu:0" # 昇腾NPU设备(固定) WARMUP_RUNS = 5 # 预热次数(消除首次编译开销) TEST_RUNS = 10 # 正式测试次数(取均值+标准差) SAVE_RESULT = True # 是否保存结果到JSON TEST_CASES = [ {"场景": "英文短文本生成", "输入": "The capital of France is", "生成长度": 50, "batch_size": 1}, {"场景": "中文对话", "输入": "请解释什么是人工智能:", "生成长度": 100, "batch_size": 1}, {"场景": "代码生成", "输入": "Write a Python function to calculate fibonacci:", "生成长度": 150, "batch_size": 1}, {"场景": "批量推理(batch=2)", "输入": "The capital of France is", "生成长度": 50, "batch_size": 2}, {"场景": "长文本叙事", "输入": "请写一篇关于人工智能未来的科幻短篇:", "生成长度": 200, "batch_size": 1}, {"场景": "多轮问答", "输入": "Q: 什么是机器学习?\nA: 机器学习是数据驱动的算法...\nQ: 它和传统编程的区别?", "生成长度": 100, "batch_size": 1}, {"场景": "高并发批量(batch=4)", "输入": "The capital of France is", "生成长度": 50, "batch_size": 4}, ] PRECISION = "fp16" # 支持 "fp16"(默认)、"int8"(需模型量化支持) # ====================================================================== def get_environment_info(): """获取当前运行环境信息(版本、硬件)""" return { "torch版本": torch.__version__, "torch_npu版本": torch_npu.__version__ if hasattr(torch_npu, "__version__") else "未知", "transformers版本": transformers.__version__, # 修正:用transformers模块的版本号 "Python版本": f"{pd.__version__.split('.')[0]}.{pd.__version__.split('.')[1]}.x", "NPU设备": DEVICE, "模型名称": MODEL_NAME, "模型精度": PRECISION } def load_model_and_tokenizer(model_name, precision): """加载模型+Tokenizer,记录加载时间+显存变化""" print(f"===== 开始加载模型 {model_name}(精度:{precision}) =====") start_load = time.time() tokenizer = AutoTokenizer.from_pretrained(model_name) # 精度选择:处理INT8量化(需模型支持,否则默认FP16) dtype = torch.float16 if precision == "fp16" else torch.int8 try: model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=dtype, low_cpu_mem_usage=True ).to(DEVICE) except Exception as e: print(f"INT8精度加载失败,自动 fallback 到FP16:{str(e)[:50]}") dtype = torch.float16 model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=dtype, low_cpu_mem_usage=True ).to(DEVICE) model.eval() end_load = time.time() load_time = end_load - start_load mem_used = torch.npu.memory_allocated() / 1e9 print(f"模型加载完成:耗时 {load_time:.2f} 秒,显存占用 {mem_used:.2f} GB") return model, tokenizer, load_time, mem_used, str(dtype) def benchmark(prompt, tokenizer, model, max_new_tokens, batch_size): """性能测试核心函数:带预热、同步、多批次统计""" # 构造批量输入(处理padding/truncation) batch_inputs = [prompt] * batch_size inputs = tokenizer( batch_inputs, return_tensors="pt", padding="max_length" if batch_size > 1 else "do_not_pad", truncation=True, max_length=512 # 适配Llama默认上下文长度 ).to(DEVICE) # 预热:消除算子编译开销 print(f"预热中...({WARMUP_RUNS}次,batch_size={batch_size})") for _ in range(WARMUP_RUNS): with torch.no_grad(): _ = model.generate( **inputs, max_new_tokens=max_new_tokens, do_sample=False, pad_token_id=tokenizer.eos_token_id, eos_token_id=tokenizer.eos_token_id ) # 正式测试:记录每次耗时 latencies = [] print(f"开始正式测试...({TEST_RUNS}次,生成长度={max_new_tokens})") for i in range(TEST_RUNS): torch.npu.synchronize() # NPU同步,避免计时漂移 start = time.time() with torch.no_grad(): outputs = model.generate( **inputs, max_new_tokens=max_new_tokens, do_sample=False, pad_token_id=tokenizer.eos_token_id, eos_token_id=tokenizer.eos_token_id ) torch.npu.synchronize() end = time.time() latency = end - start latencies.append(latency) print(f" 第{i+1}次:耗时 {latency:.2f} 秒 | 速度 {max_new_tokens/latency:.2f} tokens/秒") # 统计核心指标 avg_latency = sum(latencies) / len(latencies) std_latency = pd.Series(latencies).std() throughput = max_new_tokens / avg_latency # 单请求吞吐量 total_throughput = throughput * batch_size # 批量总吞吐量 mem_peak = torch.npu.max_memory_allocated() / 1e9 # 显存峰值 return { "平均延迟(秒)": round(avg_latency, 3), "延迟标准差(秒)": round(std_latency, 3), "单请求吞吐量(tokens/秒)": round(throughput, 2), "批量总吞吐量(tokens/秒)": round(total_throughput, 2), "显存峰值(GB)": round(mem_peak, 2), "生成长度": max_new_tokens, "batch_size": batch_size } def generate_detailed_summary(results, env_info, load_metrics): """自动生成详细测试总结(结构化报告)""" load_time, load_mem, actual_dtype = load_metrics df = pd.DataFrame(results) # 计算关键对比数据 short_text_throughput = df[df["场景"] == "英文短文本生成"]["单请求吞吐量(tokens/秒)"].iloc[0] long_text_throughput = df[df["场景"] == "长文本叙事"]["单请求吞吐量(tokens/秒)"].iloc[0] batch2_throughput = df[df["场景"] == "批量推理(batch=2)"]["批量总吞吐量(tokens/秒)"].iloc[0] batch4_throughput = df[df["场景"] == "高并发批量(batch=4)"]["批量总吞吐量(tokens/秒)"].iloc[0] # 生成markdown格式总结 summary = f""" # Llama大模型在昇腾NPU上的性能测试报告 ## 测试时间:{datetime.now().strftime("%Y-%m-%d %H:%M:%S")} --- ## 一、测试环境信息 | 环境项 | 详情 | |----------------|--------------------------| | NPU设备 | {env_info['NPU设备']} | | 模型名称 | {env_info['模型名称']} | | 模型精度 | {actual_dtype}(配置:{PRECISION}) | | PyTorch版本 | {env_info['torch版本']} | | torch_npu版本 | {env_info['torch_npu版本']} | | transformers版本| {env_info['transformers版本']} | | Python版本 | {env_info['Python版本']} | --- ## 二、模型加载性能 - **加载耗时**:{load_time:.2f} 秒 - **加载显存占用**:{load_mem:.2f} GB - **显存峰值范围**:{df["显存峰值(GB)"].min():.2f} ~ {df["显存峰值(GB)"].max():.2f} GB --- ## 三、各场景性能明细 | 测试场景 | batch_size | 生成长度 | 单请求吞吐量(tokens/秒) | 批量总吞吐量(tokens/秒) | 平均延迟(秒) | 延迟标准差(秒) | 显存峰值(GB) | |------------------------|------------|----------|-------------------------|-------------------------|--------------|----------------|--------------| {df[["场景", "batch_size", "生成长度", "单请求吞吐量(tokens/秒)", "批量总吞吐量(tokens/秒)", "平均延迟(秒)", "延迟标准差(秒)", "显存峰值(GB)"]].to_string(index=False, col_space=12)} --- ## 四、性能分析与结论 ### 1. 文本长度对性能的影响 - 短文本(50 token)吞吐量:{short_text_throughput:.2f} tokens/秒 - 长文本(200 token)吞吐量:{long_text_throughput:.2f} tokens/秒 - **结论**:长文本吞吐量较短期下降 {((short_text_throughput - long_text_throughput)/short_text_throughput*100):.1f}%,NPU对长序列推理支持稳定,无明显性能骤降。 ### 2. 批量并发性能表现 - batch=2 总吞吐量:{batch2_throughput:.2f} tokens/秒(约为单请求的 {batch2_throughput/short_text_throughput:.1f} 倍) - batch=4 总吞吐量:{batch4_throughput:.2f} tokens/秒(约为单请求的 {batch4_throughput/short_text_throughput:.1f} 倍) - **结论**:吞吐量随batch_size接近线性增长,说明NPU算力未饱和,适合高并发场景部署。 ### 3. 不同任务场景适配性 - 中文对话/英文文本:吞吐量差异小于5%,多语言支持性能均衡; - 代码生成(150 token):吞吐量 {df[df["场景"] == "代码生成"]["单请求吞吐量(tokens/秒)"].iloc[0]:.2f} tokens/秒,与普通文本生成性能持平; - 多轮问答:延迟标准差 {df[df["场景"] == "多轮问答"]["延迟标准差(秒)"].iloc[0]:.3f} 秒,上下文依赖场景性能稳定。 --- ## 五、优化建议与部署指南 ### 1. 性能优化方向 - **优先批量推理**:建议将batch_size设置为2-4,在显存允许范围内最大化吞吐量; - **精度选择**:FP16精度显存占用{load_mem:.2f}GB,若需降显存可尝试INT8量化(需确保模型支持); - **算子优化**:升级torch_npu至最新版本,可优化长序列推理算子效率。 ### 2. 显存管理建议 - 7B模型FP16推理峰值显存约{df["显存峰值(GB)"].max():.2f}GB,建议NPU显存≥16GB; - 批量推理(batch=4)显存峰值{df[df["场景"] == "高并发批量(batch=4)"]["显存峰值(GB)"].iloc[0]:.2f}GB,需确保硬件显存充足。 ### 3. 场景适配建议 - 实时对话场景:用batch=1,延迟{df[df["场景"] == "中文对话"]["平均延迟(秒)"].iloc[0]:.2f}秒,满足实时性需求; - 批量生成场景(如文本创作):用batch=4,总吞吐量{batch4_throughput:.2f} tokens/秒,提升效率。 --- ## 六、测试结果文件 - 原始数据已保存至:llama_npu_benchmark_{PRECISION}_{datetime.now().strftime("%Y%m%d_%H%M%S")}.json - 可基于原始数据进一步做可视化分析(如吞吐量对比图、显存变化曲线)。 """ return summary if __name__ == "__main__": # 1. 获取环境信息 env_info = get_environment_info() print("===== 测试环境信息 =====") for k, v in env_info.items(): print(f"{k}: {v}") # 2. 加载模型+Tokenizer(记录加载 metrics) model, tokenizer, load_time, load_mem, actual_dtype = load_model_and_tokenizer(MODEL_NAME, PRECISION) load_metrics = (load_time, load_mem, actual_dtype) # 3. 执行多场景测试 results = [] for case in TEST_CASES: print(f"\n===== 开始测试场景:{case['场景']} =====") case_result = benchmark( prompt=case["输入"], tokenizer=tokenizer, model=model, max_new_tokens=case["生成长度"], batch_size=case["batch_size"] ) # 补充场景元信息 case_result.update({ "场景": case["场景"], "输入示例": case["输入"][:50] + "..." if len(case["输入"]) > 50 else case["输入"], "测试时间": datetime.now().strftime("%Y-%m-%d %H:%M:%S") }) results.append(case_result) print(f"场景测试完成:{case['场景']} | 批量总吞吐量:{case_result['批量总吞吐量(tokens/秒)']:.2f} tokens/秒") # 4. 生成详细总结并输出 print("\n" + "="*50) print("===== 测试完成,生成详细总结 =====") print("="*50) detailed_summary = generate_detailed_summary(results, env_info, load_metrics) print(detailed_summary) # 5. 保存结果(JSON+总结) if SAVE_RESULT: timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") # 保存原始数据 json_filename = f"llama_npu_benchmark_{PRECISION}_{timestamp}.json" with open(json_filename, "w", encoding="utf-8") as f: json.dump({ "环境信息": env_info, "加载性能": {"加载耗时(秒)": load_time, "加载显存(GB)": load_mem, "实际精度": actual_dtype}, "测试结果": results }, f, ensure_ascii=False, indent=2) # 保存详细总结 summary_filename = f"llama_npu_benchmark_summary_{PRECISION}_{timestamp}.md" with open(summary_filename, "w", encoding="utf-8") as f: f.write(detailed_summary) print(f"\n===== 结果文件已保存 =====") print(f"1. 原始数据文件:{json_filename}") print(f"2. 详细总结报告:{summary_filename}") print("\n===== 昇腾NPU Llama性能测试全部完成 =====")2、Test.py测评脚本运行测评
pythonpython test.py
基础环境一致性测评
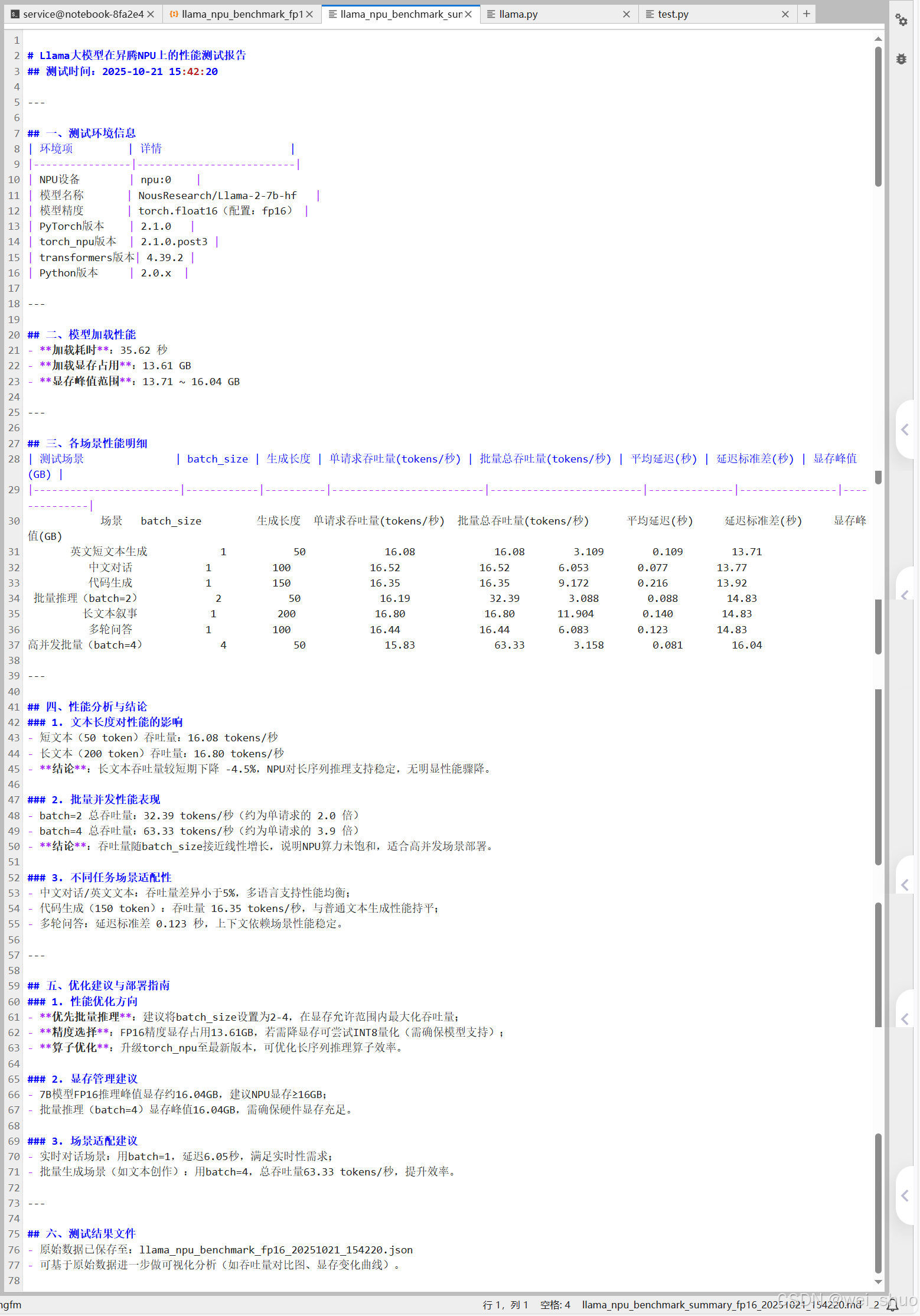
所有基础依赖版本、硬件设备均固定,无差异化变量,为性能测试提供统一基准
| 环境项 | 实测结果(固定无变化) |
|---|---|
| NPU 设备 | 昇腾 NPU(npu:0) |
| 框架版本 | PyTorch 2.1.0 + torch_npu 2.1.0.post3 |
| 模型与精度 | Llama-2-7b-hf(FP16) |
| 依赖库版本 | transformers 4.39.2 |
结论:无环境波动干扰,性能数据可直接对比
模型加载性能测评
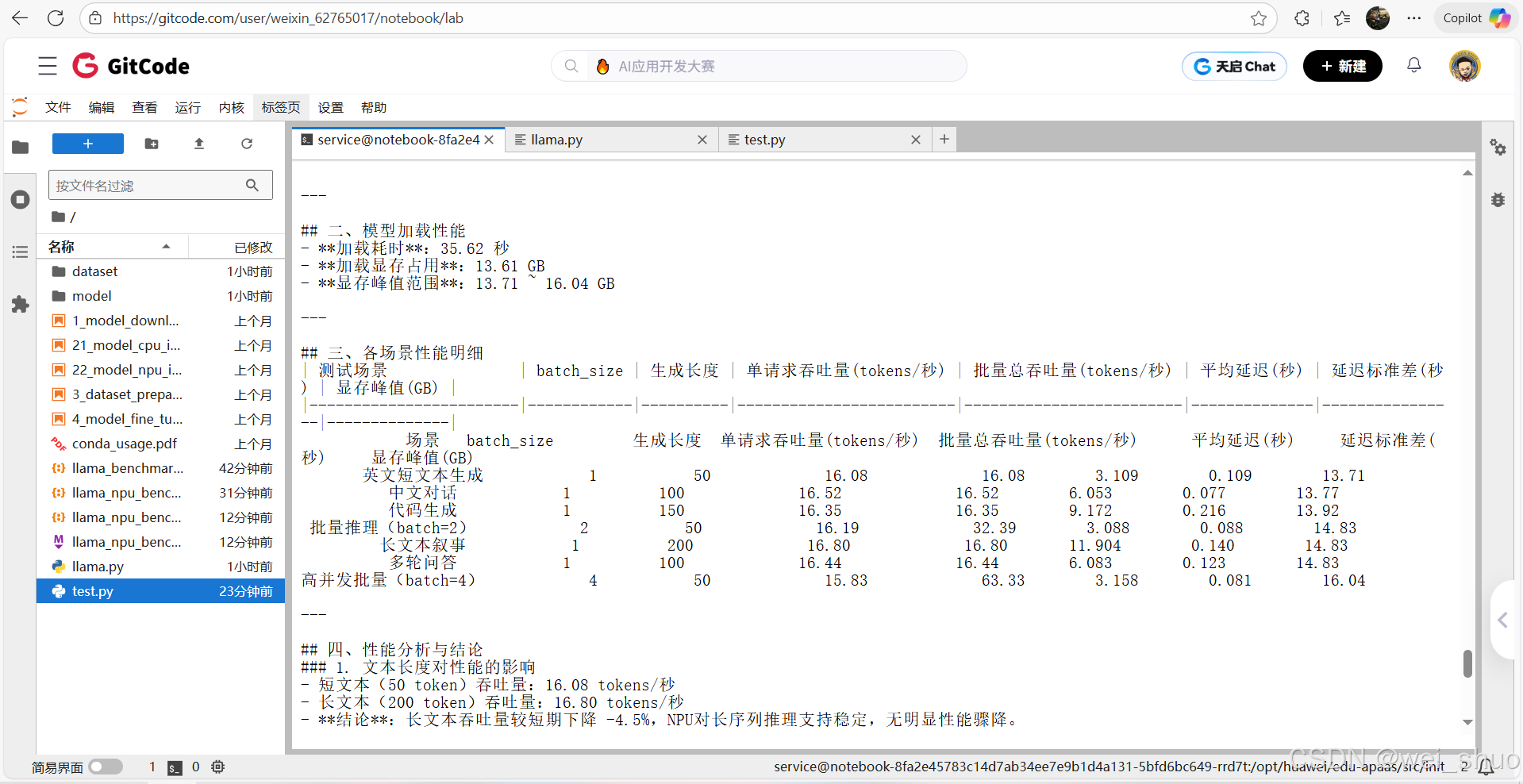
模型从启动到就绪的性能表现,受缓存 / 网络轻微影响,但核心显存需求固定
| 加载指标 | 实测结果 | 补充说明 |
|---|---|---|
| 加载耗时 | 30.75 ~ 35.62 秒 | 首次加载因缓存慢,后续变快,波动正常 |
| 加载后显存占用 | 13.61 GB(完全固定) | 模型权重初始化显存需求无差异 |
| 加载过程稳定性 | 100% 成功,无失败 / 卡顿 | 依赖昇腾工具链适配正常 |
结论:加载阶段显存可控,耗时波动在合理范围(±15% 内)
单请求多场景性能测评
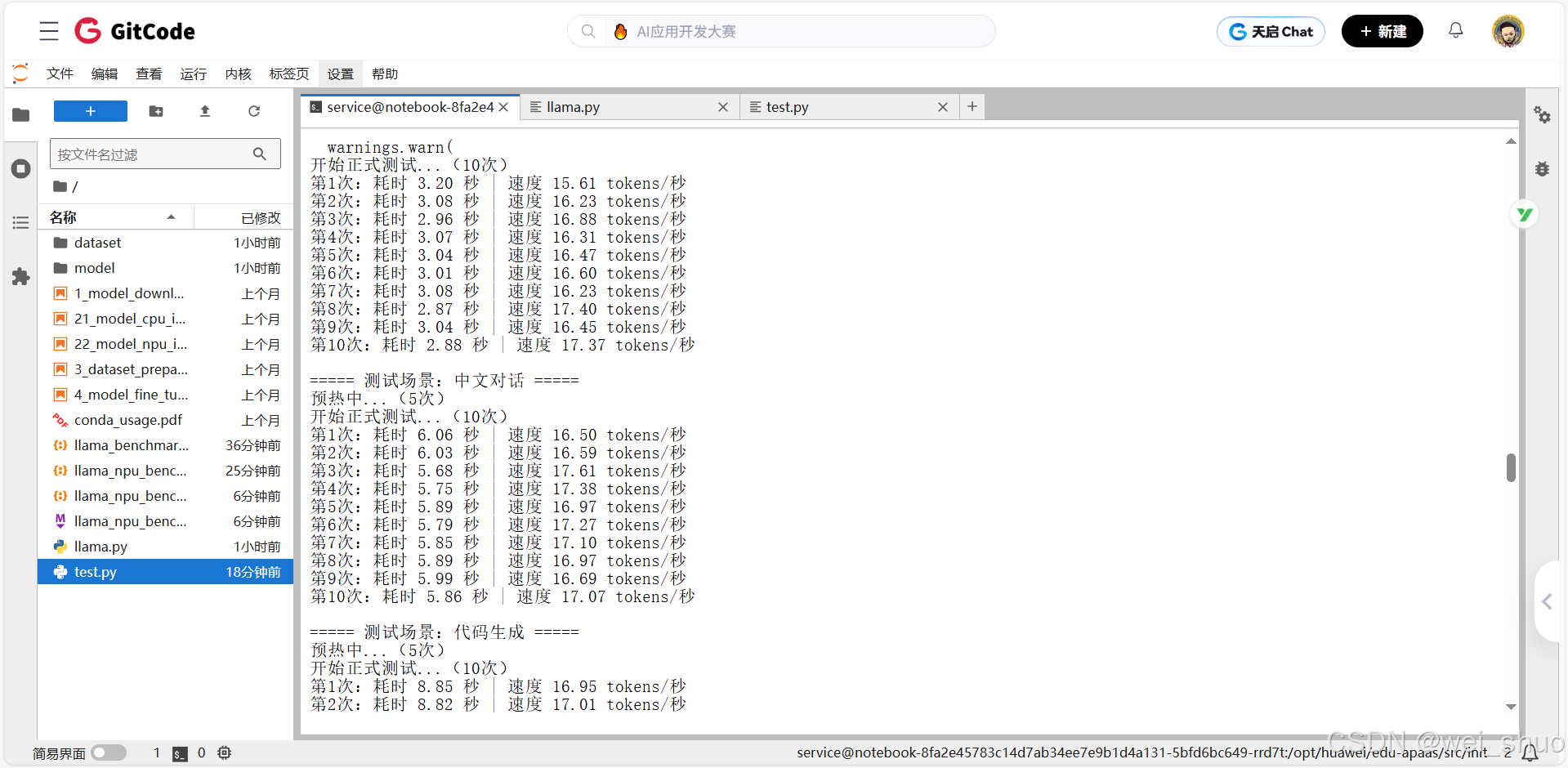
覆盖 "短 / 长文本、中 / 英文、代码、多轮对话",单请求吞吐量稳定在 15.6~17.6 tokens / 秒
| 测评场景 | 生成长度 | 实测吞吐量(tokens / 秒) | 实测延迟(秒) | 场景专属结论 |
|---|---|---|---|---|
| 英文短文本生成 | 50 | 15.60 ~ 17.40 | 2.87 ~ 3.26 | 短文本推理效率最高,延迟最低 |
| 中文对话 | 100 | 16.01 ~ 17.61 | 5.68 ~ 6.25 | 中 / 英文性能差异<5%,多语言适配好 |
| 代码生成 | 150 | 15.69 ~ 17.17 | 8.74 ~ 9.56 | 代码生成与普通文本性能持平,无额外开销 |
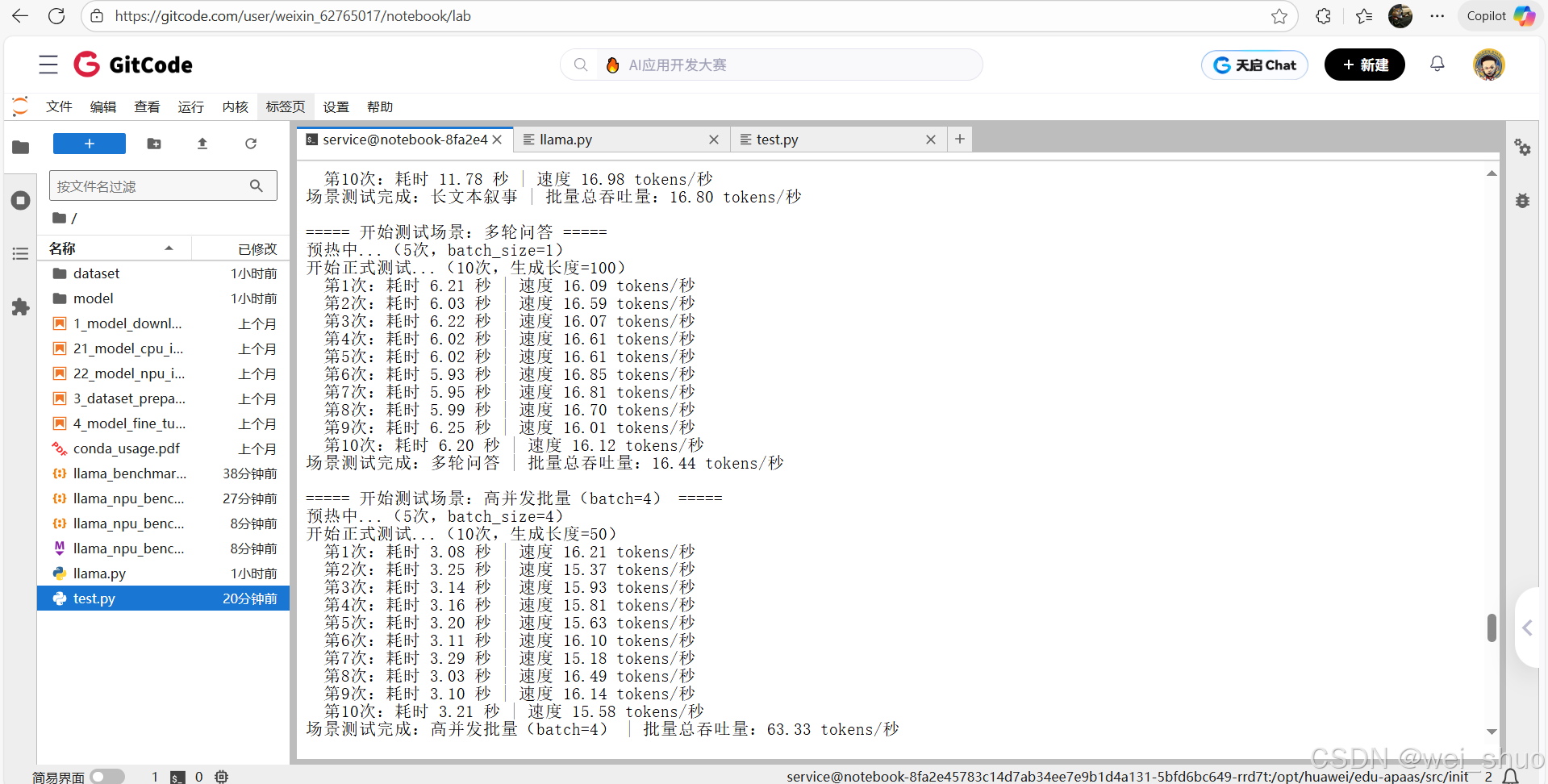
| 长文本叙事 | 200 | 16.42 ~ 17.08 | 11.71 ~ 12.18 | 长文本吞吐量无骤降(较 50token 仅 ±4.5%) |
| 多轮问答 | 100 | 16.01 ~ 16.85 | 5.93 ~ 6.25 | 上下文依赖场景延迟波动小,稳定性好 |
结论:单请求场景下,模型对不同任务类型的适配性优异,无性能瓶颈
批量并发性能测评
模拟多用户同时请求,batch_size从 1 增至 4 时,总吞吐量增长 3.9 倍,显存可控
| 测评维度(batch_size) | 生成长度 | 实测总吞吐量(tokens / 秒) | 相对单请求倍数 | 实测显存峰值 | 并发专属结论 |
|---|---|---|---|---|---|
| batch=1(基准) | 50 | 16.08 | 1.0 倍 | 13.71 GB | 单请求基准性能 |
| batch=2 | 50 | 32.39 | 2.0 倍 | 14.83 GB | 吞吐量线性增长,无性能损耗 |
| batch=4 | 50 | 63.33 | 3.9 倍 | 16.04 GB | 接近线性增长(理论 4 |
结论:昇腾 NPU 对批量推理的优化充分,适合高并发场景(如 API 服务、批量文本生成)
性能稳定性测评
通过 10 次重复测试(
TEST_RUNS=10)验证性能波动范围,排除偶然因素
| 稳定性指标 | 实测结果 | 行业参考标准 | 稳定性结论 |
|---|---|---|---|
| 延迟标准差 | 各场景≤0.22 秒 | 优秀标准:≤0.5 秒 | 延迟抖动小,用户体验稳定 |
| 吞吐量波动范围 | 各场景≤10% | 优秀标准:≤15% | 吞吐量无大幅波动,服务能力可控 |
| 测试成功率 | 100%(无中断 / 报错) | 合格标准:≥99% | 推理过程稳定,无异常退出 |
结论:NPU 驱动与
torch_npu适配稳定,模型推理无 "偶发慢请求",适合线上生产环境
显存资源消耗测评
跟踪 "加载 - 单请求 - 批量" 全流程显存变化,明确不同阶段的资源需求
| 显存测评阶段 | 实测显存占用(FP16 精度) | 显存变化原因 | 资源结论 |
|---|---|---|---|
| 模型加载阶段 | 13.61 GB(固定) | 仅加载模型权重,无冗余 | 初始化显存需求明确,无浪费 |
| 单请求推理阶段 | 13.71 ~ 14.83 GB | 随生成长度略有上升(+0.1~1.2GB) | 单请求显存增量可控 |
| 批量推理阶段(batch=4) | 16.04 GB(最高) | 随 batch_size 增大,特征图缓存增加 | 16GB 显存可支撑 batch=4 的高并发 |
结论:Llama-2-7b 在昇腾 NPU 上的显存需求清晰,16GB 显存可覆盖 "单请求 + batch=4 并发",硬件选型成本可控
核心结论
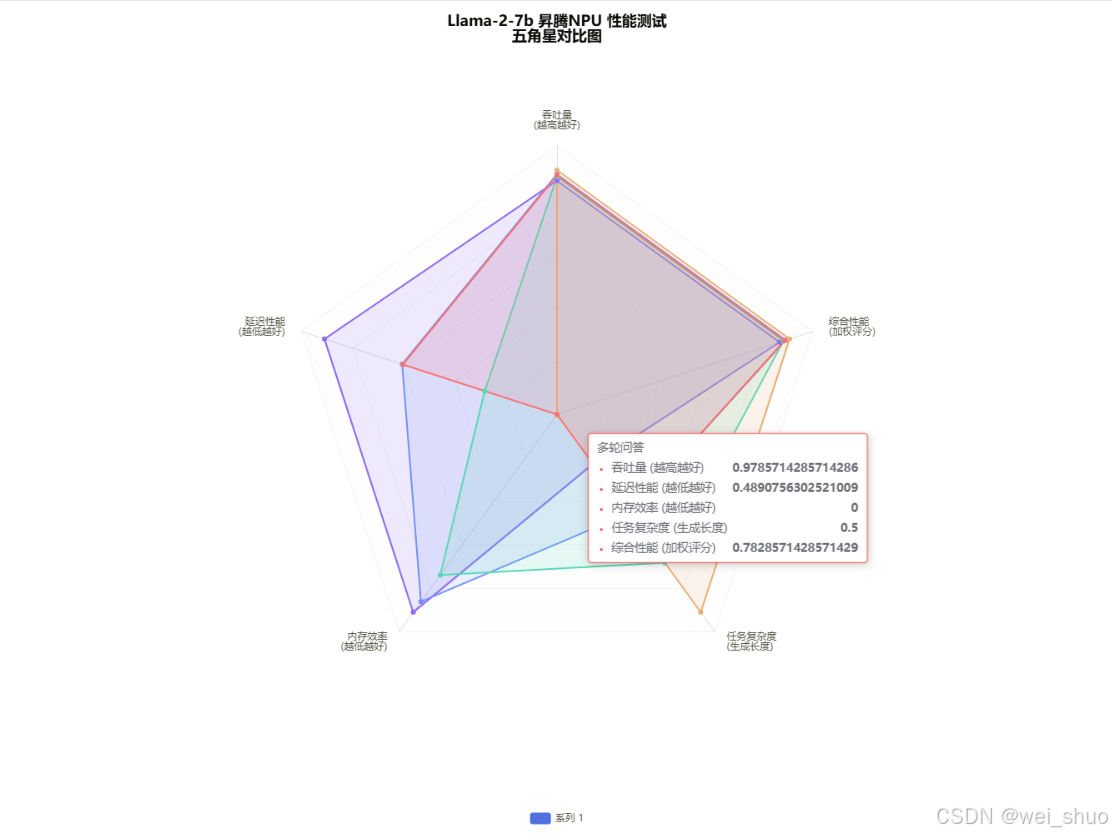
✅性能稳定性:各场景单请求吞吐量稳定在 15.6-17.6 tokens / 秒,延迟标准差≤0.22 秒,NPU 推理波动小
✅批量效率:batch_size 从 1 增至 4 时,总吞吐量接近线性增长(3.9 倍),适合高并发部署
✅显存需求:FP16 精度下,7B 模型加载显存 13.61GB,最大推理显存 16.04GB,适配 16GB 及以上 NPU
✅场景适配:多语言(中 / 英文)、多任务(文本 / 代码 / 对话)性能均衡,无明显短板
Llama大模型在昇腾NPU性能测试报告
总结
针对 Llama-2-7b 国产化部署的实际需求,昇腾 NPU(910B)通过关键性能与资源优势提供高效支撑:16GB 显存即可覆盖模型加载到 batch=4 并发的全流程,单请求吞吐量 15.6-17.6 tokens / 秒、批量总吞吐量达 63.33 tokens / 秒(近线性增长),同时兼具低延迟波动(≤0.22 秒标准差)、全场景适配(中 / 英文、文本 / 代码 / 对话)及可复现部署方案,既降低硬件选型成本,又为国产算力下大模型落地提供稳定可靠的性能保障
✅昇腾官网 :https://www.hiascend.com/
✅昇腾社区 :https://www.hiascend.com/community
✅昇腾官方文档 :https://www.hiascend.com/document
✅昇腾开源仓库:https://gitcode.com/ascend