Python编程之常用模块
一、Time模块
1.时间戳
bash
time_stamp = time.time()
print(time_stamp, type(time_stamp))2.格式化时间
bash
format_time = time.strftime("%Y-%m-%d %X")
print(format_time, type(format_time))
2024-10-29 16:05:25 <class 'str'>3.结构化时间
bash
print('本地时区的struct_time:\n{}'.format(time.localtime()))
print('UTC时区的struct_time:\n{}'.format(time.gmtime()))
#本地时区的struct_time:
time.struct_time(tm_year=2022, tm_mon=8, tm_mday=31, tm_hour=16, tm_min=14, tm_sec=41, tm_wday=2, tm_yday=243, tm_isdst=0)
#UTC时区的struct_time:
time.struct_time(tm_year=2022, tm_mon=8, tm_mday=31, tm_hour=8, tm_min=14, tm_sec=41, tm_wday=2, tm_yday=243, tm_isdst=0)4.常见用法:计算程序执行的时间
bash
# 推迟指定的时间运行,单位为秒start = ti# 推迟指定的时间运行,单位为秒
start = time.time()
time.sleep(3)
end = time.time()
#print(end-start)me.time()time.sleep(3)end = time.time()
print(end-start)二、datetime模块
该模块可以看成时间的加减模块
bash
# 返回当前时间
print(datetime.datetime.now())
# 当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(3))
# 当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(-3))
# 当前时间+30分钟
print(datetime.datetime.now() + datetime.timedelta(minutes=30))
# 时间替换
c_time = datetime.datetime.now()
print(c_time.replace(minute=20, hour=5, second=13))
print(datetime.date.fromtimestamp(time.time())) #换算成年月日
2019-03-07三、random模块
bash
# 大于0且小于1之间的小数
print(random.random())
# 大于等于1且小于等于3之间的整数
print(random.randint(1, 3))
# 大于1小于3的小数,如1.927109612082716
print(random.uniform(1, 3))
# 列表内的任意一个元素,即1或者'23'或者[4,5]
print(random.choice([1, '23', [4, 5]]))
1
#------------smaple-------比较常用在数据导入的时候像随机选择数据
# random.sample([], n),列表元素任意n个元素的组合,示例n=2
print(random.sample([1, '23', [4, 5]], 2))
[[4, 5], '23']
lis = [1, 3, 5, 7, 9]
# 打乱l的顺序,相当于"洗牌"
random.shuffle(lis)
print(lis)
[1, 3, 9, 7, 5]四、os模块
1.os模块负责程序与操作系统交互
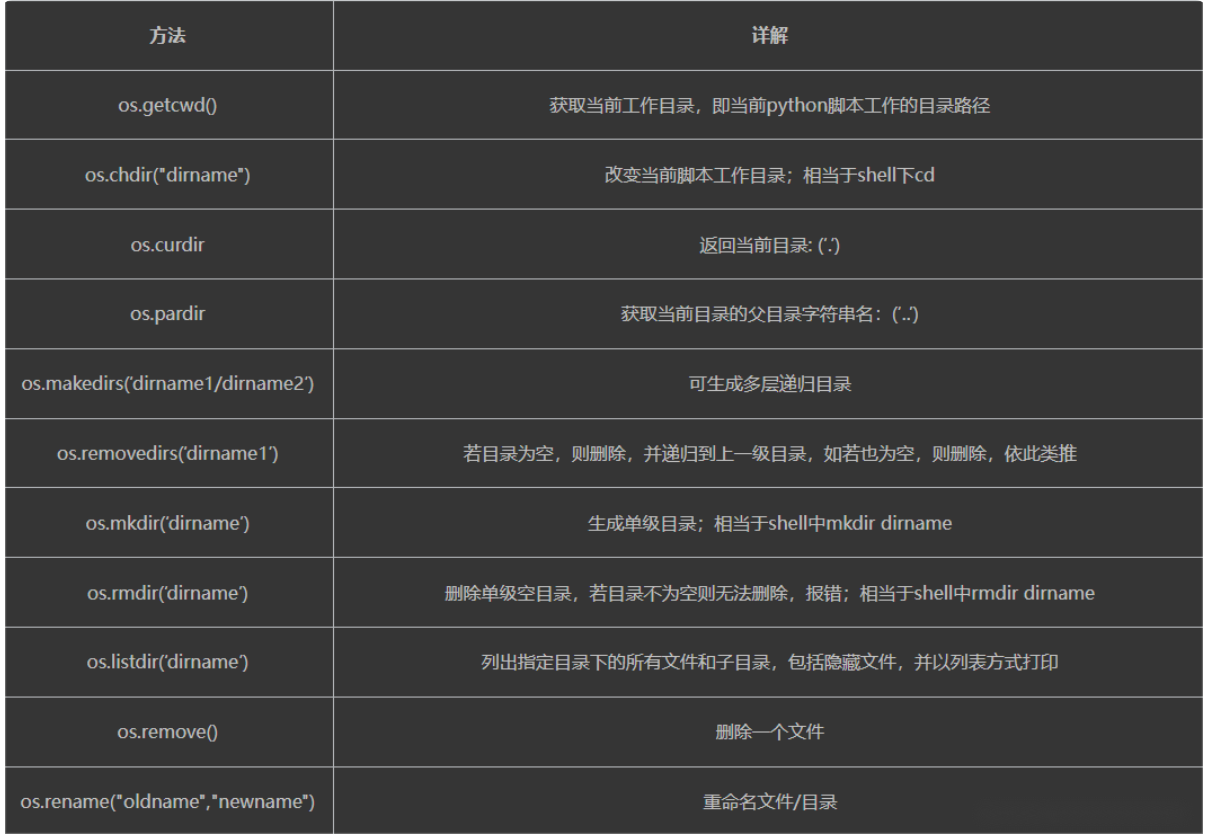
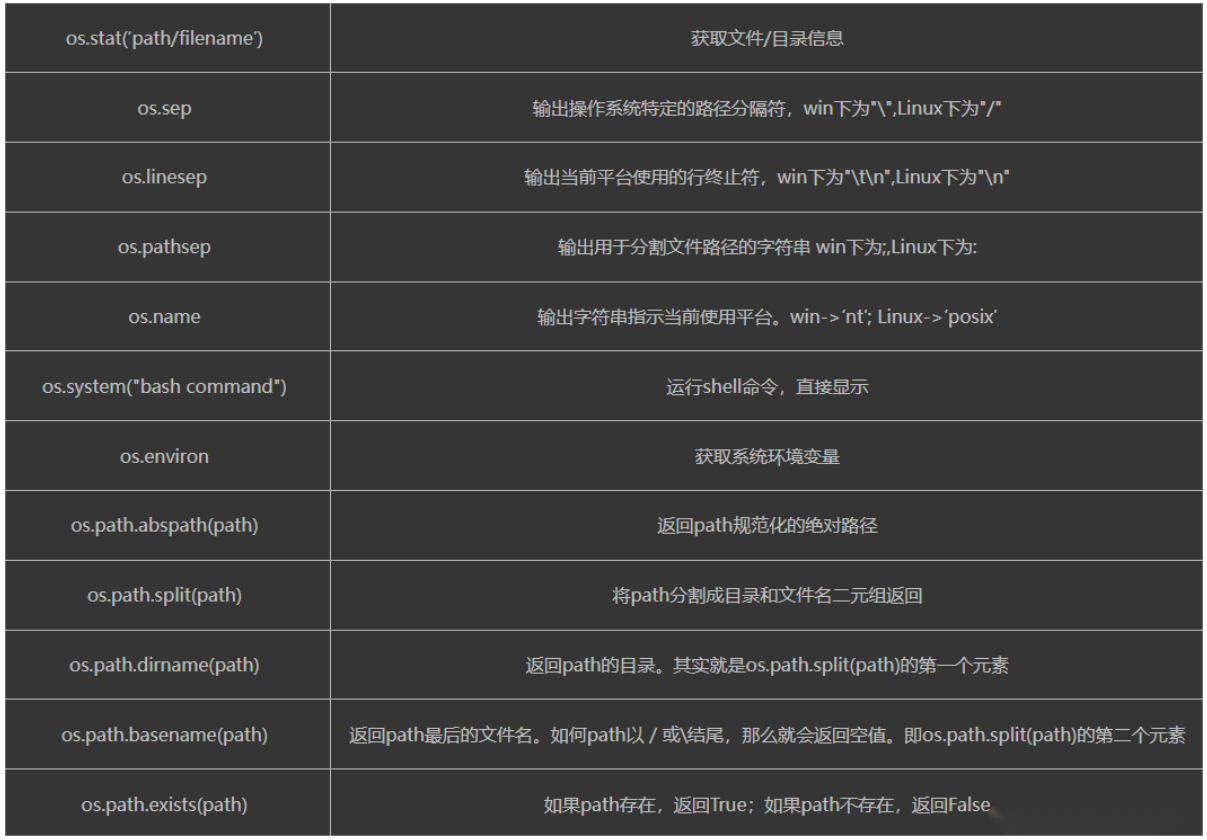

2.os的重点模块:
os.getcwd()
os.path.abspath('D:\python_base')\
os.path.split('C:\\WINDOWS\\system32\\cmd.exe')
os.path.join('C:\\WINDOWS\\system32\\cmd.exe','hello')
os.path.getsize('C:\\WINDOWS\\system32\\cmd.exe')
3.os常见操作:获取当前路劲的绝对路劲,获取当前路劲的父路径、父父路劲等
bash
# -*- coding: utf-8 -*-
'''
@Time : 2022/09/01 10:25
@Author : Rice
@CSDN : C_小米同学
@FileName: test.py
'''
import os
print(os.path.abspath(__file__)) #返回当前文件的绝对路劲(路径+文件名)
print(os.path.dirname(os.path.abspath(__file__))) #返回当前文件的父路径
print(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))#返回当前文件的父路径的父路径
print(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))五、sys模块
1.sys模块负责程序与python解释器进行交互
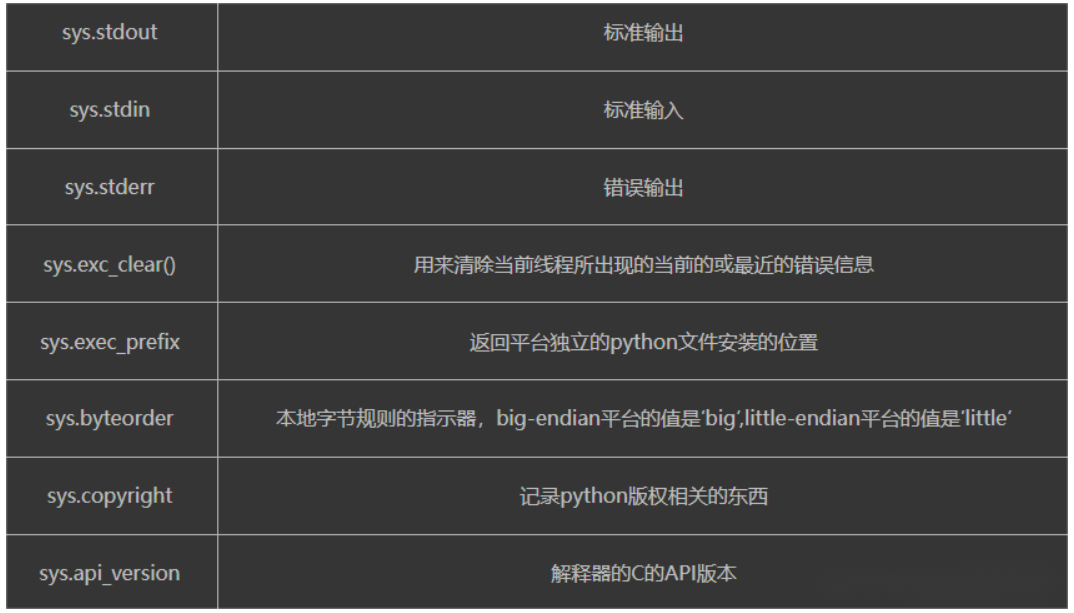
2.sys重点模块
sys.path:返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.version:获取Python解释程序的版本信息
sys.exit(n):退出程序,正常退出时exit(0)
3.案例:实现进度条的打印
bash
#=========知识储备==========
#进度条的效果
[# ]
[## ]
[### ]
[#### ]
#指定宽度
print('[%-15s]' %'#')
print('[%-15s]' %'##')
print('[%-15s]' %'###')
print('[%-15s]' %'####')
#打印%
print('%s%%' %(100)) #第二个%号代表取消第一个%的特殊意义
#可传参来控制宽度
print('[%%-%ds]' %50) #[%-50s]
print(('[%%-%ds]' %50) %'#')
print(('[%%-%ds]' %50) %'##')
print(('[%%-%ds]' %50) %'###')
#=========实现打印进度条函数==========
def progress(percent,width=100):
if percent >= 1:
percent=1
for i in range(width + 1):
show_str=('[%%-%ds]' %i) %(int(i * percent) * '#')
print('\r%s %d%%' %(show_str,int(i * percent)),file=sys.stdout,flush=True,end='')
time.sleep(0.1)
progress(1)
#=========应用==========
data_size=1025
recv_size=0
while recv_size < data_size:
time.sleep(0.1) #模拟数据的传输延迟
recv_size+=1024 #每次收1024
percent=recv_size/data_size #接收的比例
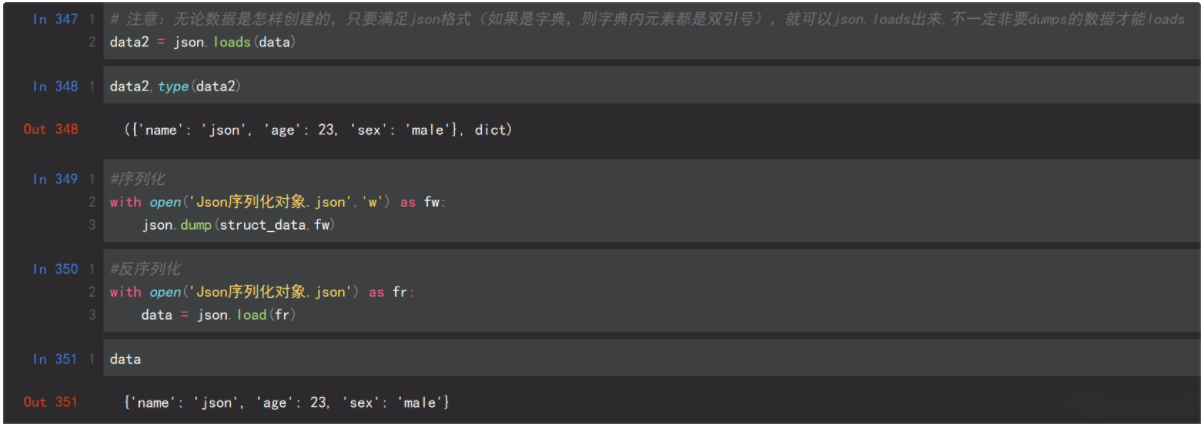
progress(percent,width=70) #进度条的宽度70六、json和pickle模块
1.序列化
把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization, marshalling, flattening.
2.序列化的优点:
1.持久保存状态:内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。但是在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
2.跨平台数据交互:序列化时不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
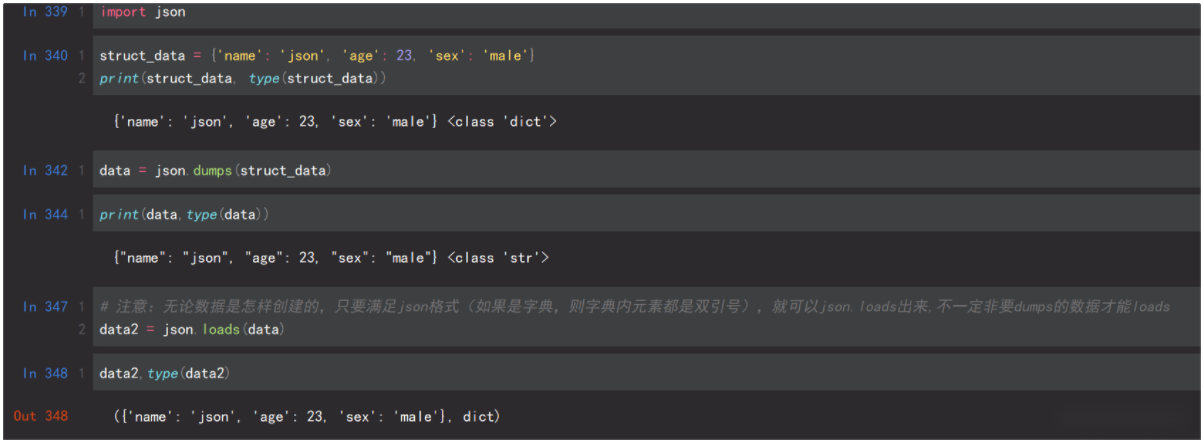
3.json格式
Json序列化并不是python独有的,json序列化在java等语言中也会涉及到,因此使用json序列化能够达到跨平台传输数据的目的。ison数据举型和python数据举型对应关系表
| Json类型 | Python类型 |
|---|---|
| {} | dict |
| \[\] | list |
| string" | str |
| 520.13 | int或float |
| true/false | True/False |
| null | None |

七、pickle格式
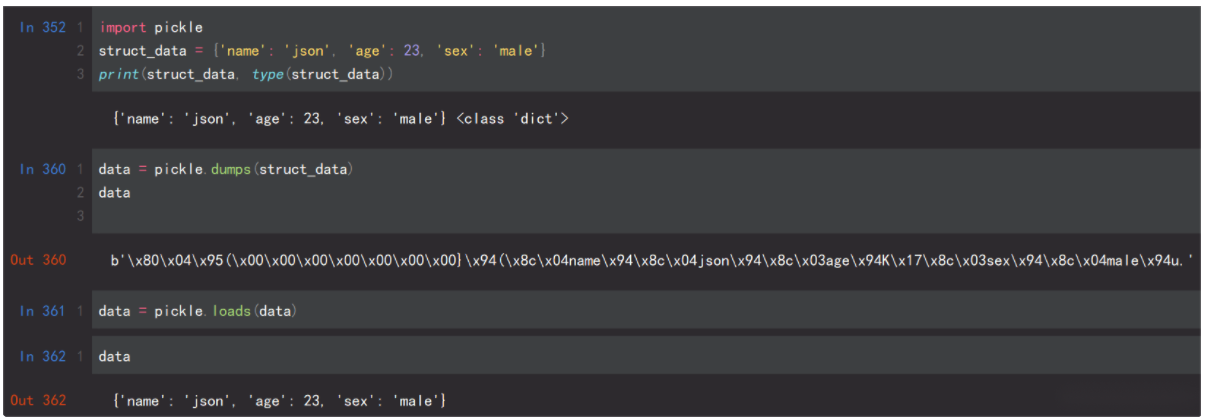
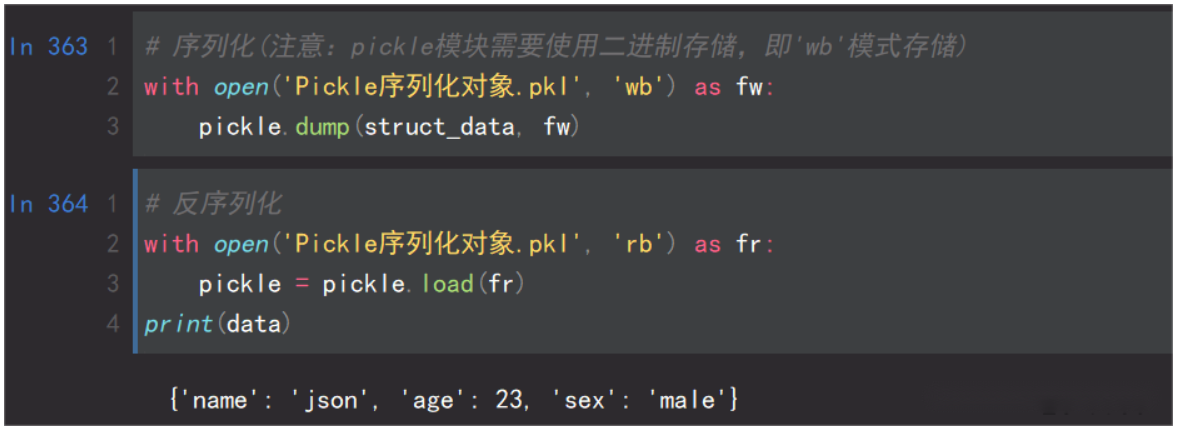
1.pickle简介
Pickle序列化和所有其他编程语言特有的序列化问题 样,它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,即不能成功地反序列化也没关系。但是pickle的好处是可以存储Python中的所有的数据类型,包括对象,而json不可以。pickle模块序列化和反序列化的过程如下图所示
2.pickle操作
八、hashlib模块
1.hashlib简介
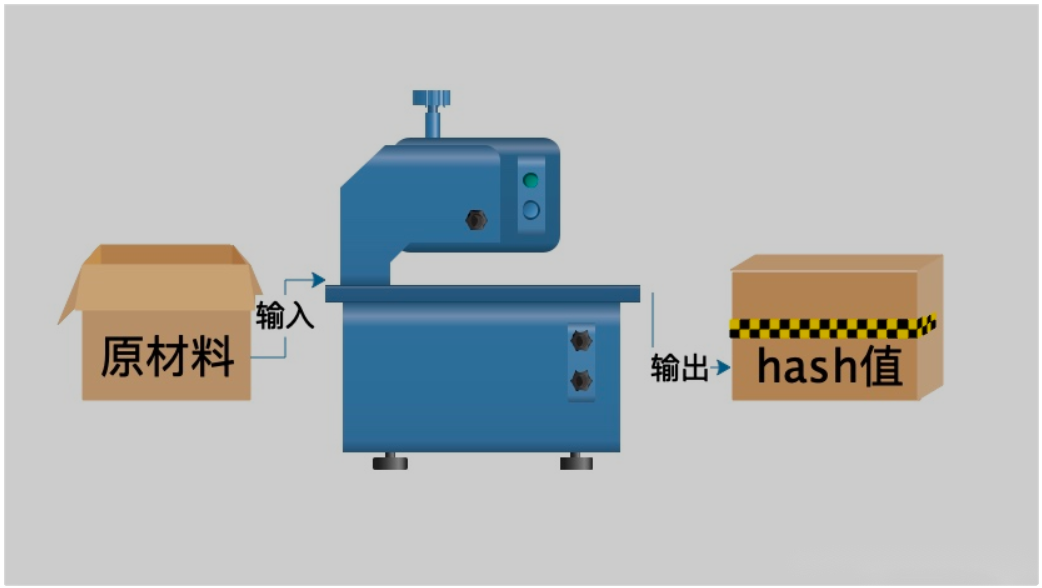
hash是种算法(Python3.版本里使用hashlib模块代替了md5模块和sha模块,主要提供SHA1, SHA224, SHA256, SHA384, SHA512, MD5算法),该算法接受传入的内容,经过运算得到一串hash值。
2.hash值的特点:
1.只要传入的内容一样,得到的hash值一样,可用于非明文密码传输时密码校验
2.不能由hash值返解成内容,即可以保证非明文密码的安全性
3.只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的,可以用于对文本的哈希处理hash算法其实可以看成如下图所示的一座工厂,工厂接收你送来的原材料,经过加工返回的产品就是hash值
3.hash基本操作(以md5为例)
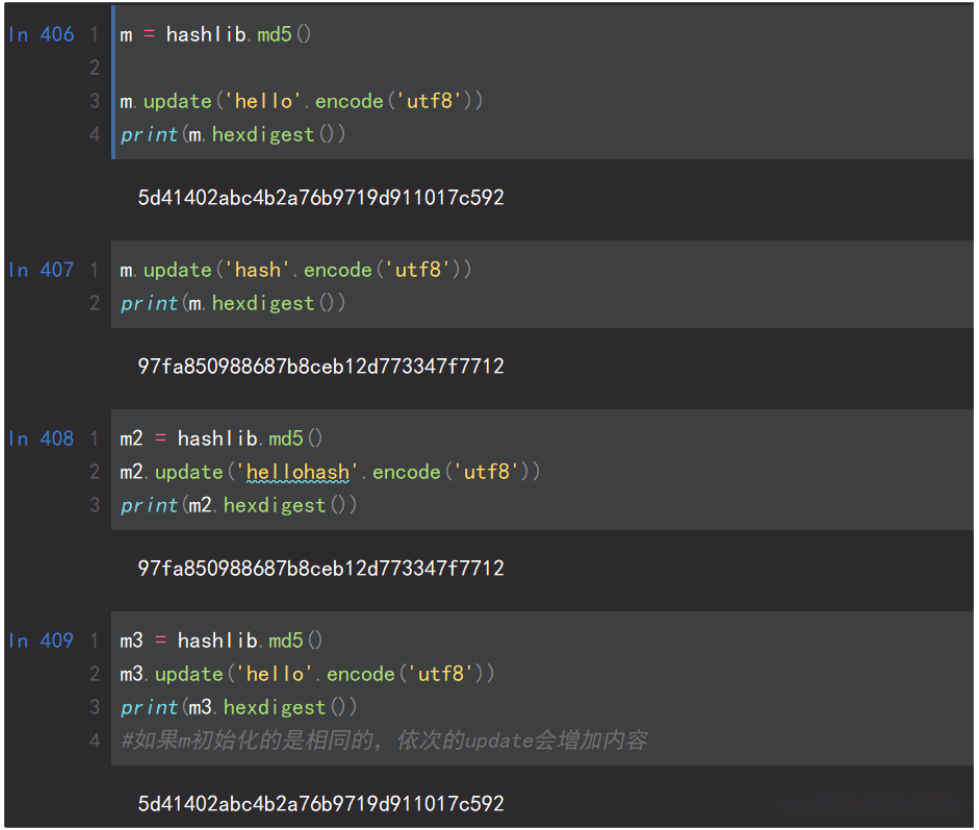
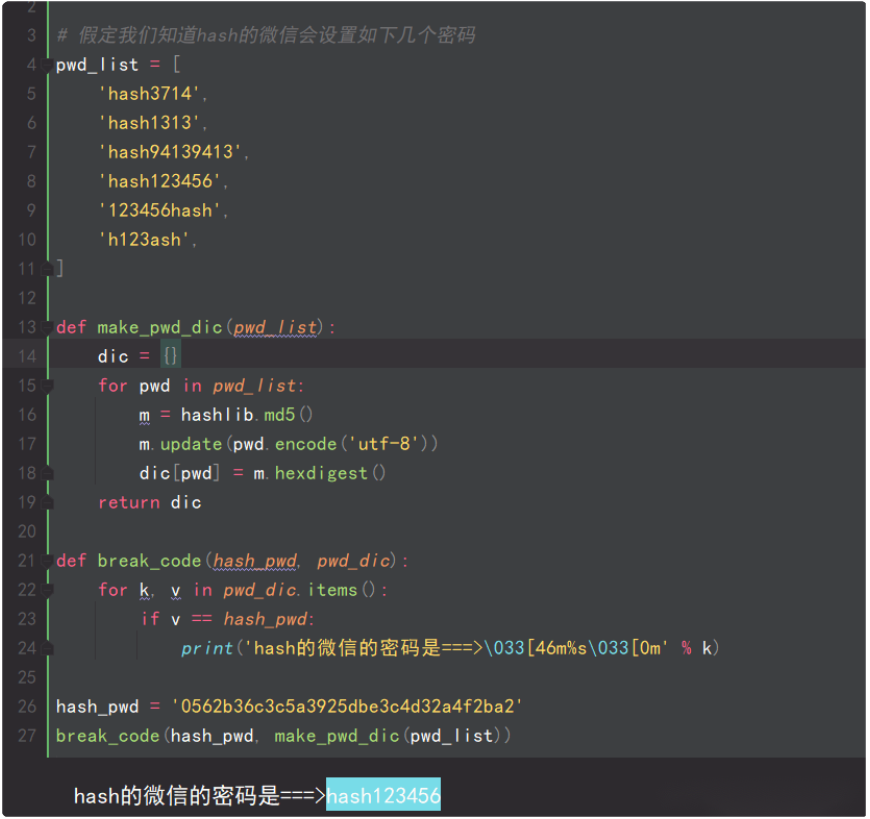
4.撞库破解hash算法加密
hash加密算法虽然看起来很厉害,但是他是存在一定缺陷的,即可以通过撞库可以反解,如下代码所示。
九、shutil模块
1.shutil简介
相比os模块,shutil模块用于文件和目录的高级处理,提供了支持文件赋值、移动、删除、压缩和解压等功能。
2.复制文件
shutil模块的主要作用是复制文件,七种实现方式:
1.shutil.copyfileobj(file1,file2)覆盖复制
将file1的内容覆盖file2,file1、file2表示打开的文件对象。
import shutil
f1 = open('f1', 'rb')
f2 = open('f2', 'wb')
shutil.copyfileobj(f1,f2)
f1.close
f2.close2.shutil.copyfile(file1,file2)覆盖复制
也是覆盖,但是无须打开文件,直接用文件名进行覆盖(其源码还是调用的copyfileobj)。
3.shutil.copymode(file1,file2)权限复制
仅复制文件权限,不更改文件内容、组和用户,无返回对象。
4.shutil.copystart(file1,file2)状态复制
复制文件的所有状态信息,包括权限、组、用户和时间等,无返回对象。
5.shutil.copy(file1,file2)内容和权限复制
复制文件的内容和权限,相当于先执行了copyfile再执行了copysmode。
- shutil.copy2(file1,file2)内容和权限复制
复制文件的内容及所有状态信息,相当于先执行了copyfile再执行了copystart。
- shutil.copytree()递归复制
递归地复制文件内容及状态信息
3.移动文件
使用函数shutil.move()函数可以递归地移动文件或重命名,并返回目标,若目标是现有目录则src再当前目录移动;若目标已经存在且不是目录,则可能会被覆盖。
4.读取压缩及归档压缩文件
使用函数shutil.make_archive()创建归档文件,并返回归档后的名称。
语法如下:
shutil.make_archive(base_name,format,root_dir\[,base_dir\[,verbose\[,dry_run\[,owner\[,group\[,logger]]]]]])
1.base_name为需要创建的文件名,包括路径
2.format表示压缩格式,可选zip、tar或bztar等
3.root_dir为归档的目录
5.解压文件
使用函数shutil.unpack_archive(filename[,extract_dir[,format]])分析拆档。
1.filename是归档的完整路径
2.extract_dir是解压归档的目标目录名称
3.format是解压文件的格式
十、subsprocess模块
1.subsprocess模块简介
subprocess是python内置的模块,这个模块中的Popen可以查看用户输入的命令行是否存在
1.如果存在,把内容写入到stdout管道中
2.如果不存在,把信息写入到stderr管道
需要注意的是,这个模块的返回结果只能让开发者看一次,如果想多次查看,需要在第一次输出的时候,把所有信息写入到变量中。
2.subsprocess基本操作
Popen基本格式:subprocess.Popen('命令', shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
-
shell=True 表示要在终端中运行的命令
-
stdout=sbuprocess.PIPE 表示当命令存在的时候,把结果写入到stdout管道
-
stderr=sbuprocess.PIPE 表示当命令不存在的时候,把结果吸入到stderr管道
bash
import subprocess
r = subprocess.Popen('wget -q -o xxx', shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print(r.stdout.read().decode('utf8'))
print(r.stderr.read().decode('utf8'))