目录
[1.1 create](#1.1 create)
[1.2 全列插入](#1.2 全列插入)
[1.3 指定列插入](#1.3 指定列插入)
[1.4 插入否则更新(duplicate)](#1.4 插入否则更新(duplicate))
[1.5 替换(replace)](#1.5 替换(replace))
[1.7 deplicate和replace的区别](#1.7 deplicate和replace的区别)
[1.7.1 核心操作逻辑不同](#1.7.1 核心操作逻辑不同)
[1.7.2 对自增主键的影响不同](#1.7.2 对自增主键的影响不同)
[1.7.3 对未指定字段的处理不同](#1.7.3 对未指定字段的处理不同)
[1.7.4 示例对比](#1.7.4 示例对比)
[1.7.5 适用场景](#1.7.5 适用场景)
[2. 删](#2. 删)
[2.1 删除表(delete)](#2.1 删除表(delete))
[2.2 截断表(truncate)](#2.2 截断表(truncate))
[2.3 删除的注意点](#2.3 删除的注意点)
今天我们来聊一下表的增删。对于数据表来说,数据是非常重要的,所以关于数据的增删也是肥城重要的。
1.增
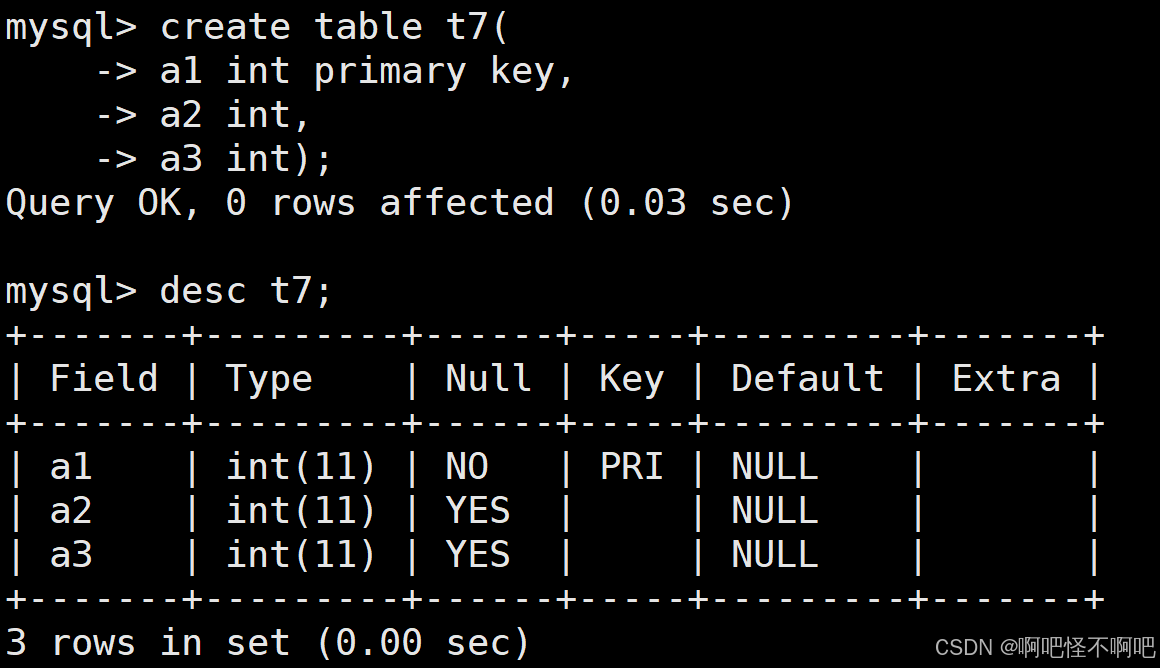
1.1 create
下面这张图就是create的使用方式。
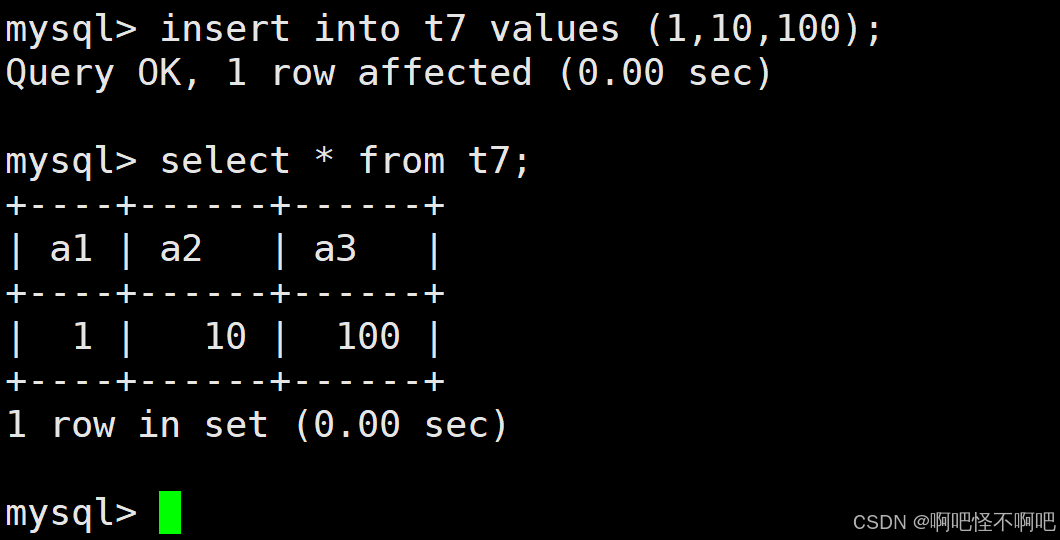
1.2 全列插入
下面这张图就是全列插入,意思就是说给这张表里面的每一个数据都插入值。
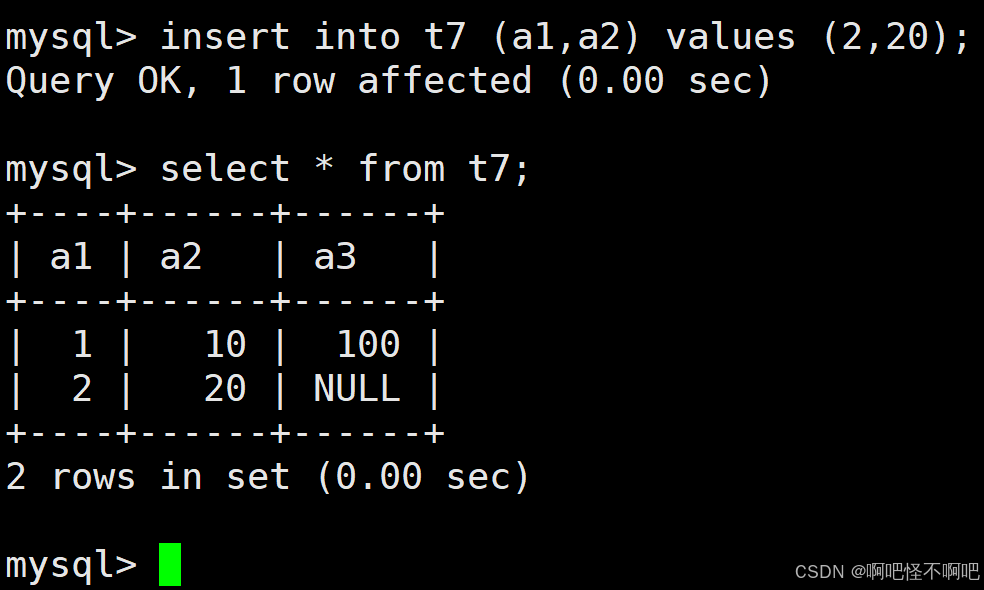
1.3 指定列插入
下面这张图就是指定列插入,我们在这里给a1和a2插入了值。那么我们在查看的时候就会发现在这张表的第二行的a3位置就是NULL。
1.4 插入否则更新(duplicate)
具体语法:
sql
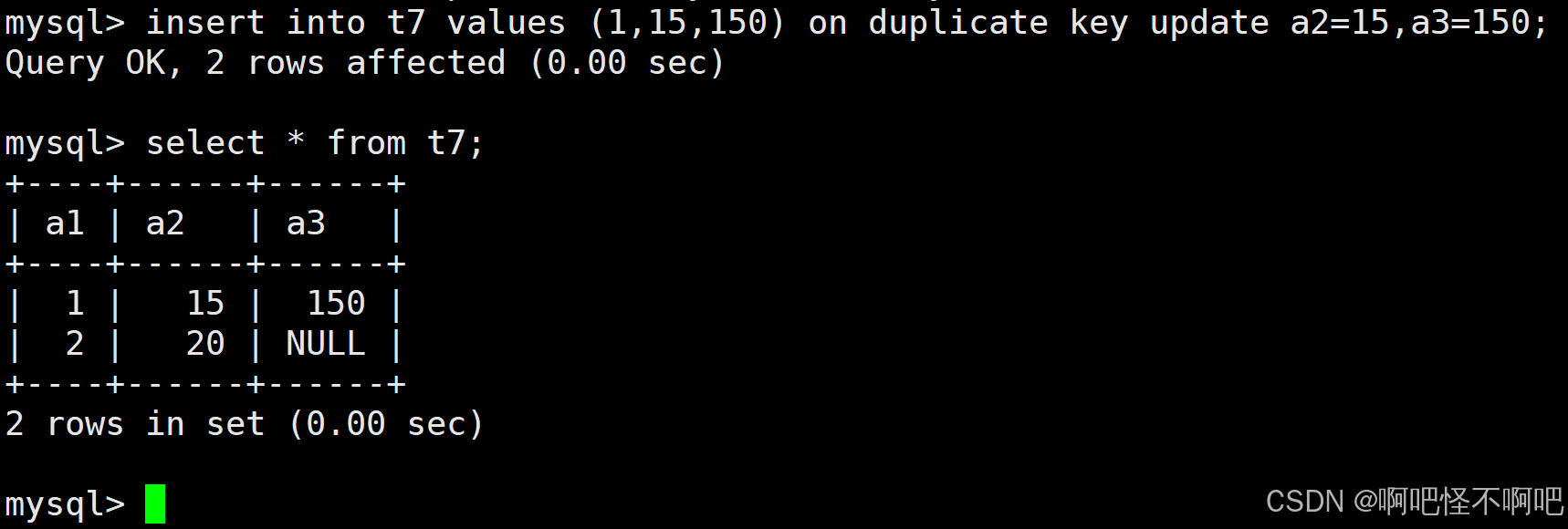
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ...我们在插入值的时候如果给主键或唯一键插入了一样的值那么就会报错。就像下面这样。

这个时候我们就可以使用这个指令在发生冲突的时候来进行更新,通过额外添加的 on duplicate key update a2=15,a3=150;我们就可以实现修改其已被主键占用的那一行值。
1.5 替换(replace)
主键 或者 唯一键 没有冲突,则直接插入;
主键 或者 唯一键 如果冲突,则删除后再插入
当主键或者唯一键没用冲突的时候它就会直接插入数据。
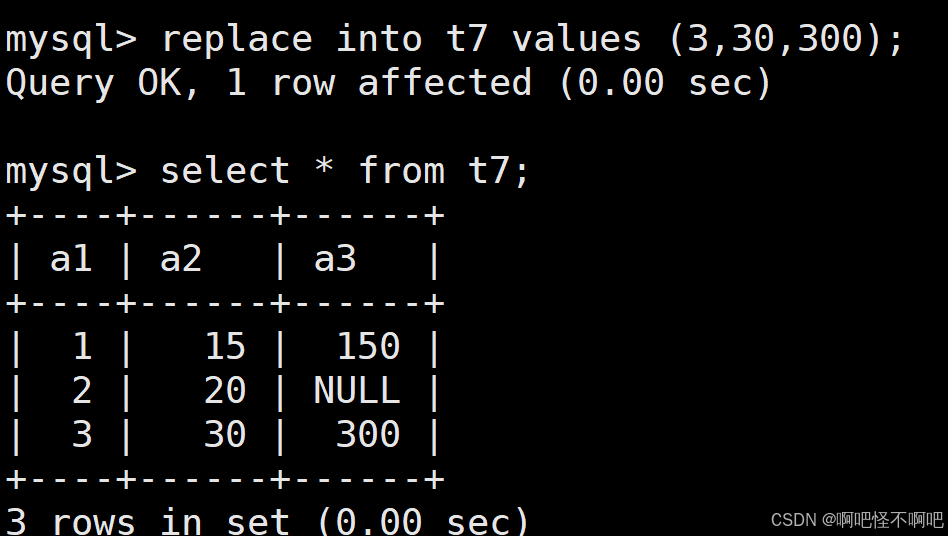
我们看下面这张图,我们使用replace那么就可以直接更改主键的那一行值。
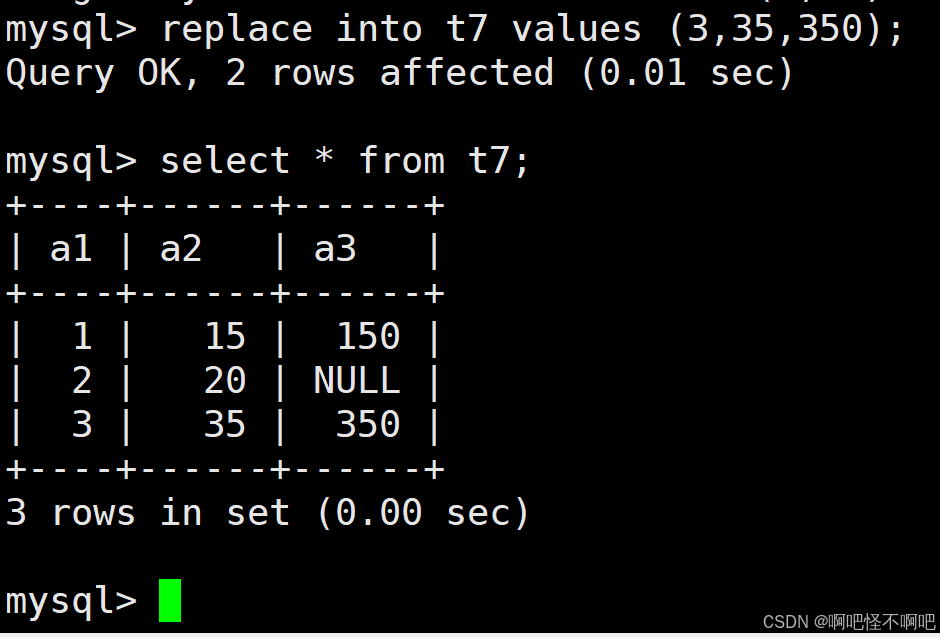
我们也可以根据指令执行完后的那一行语句来确定是直接插入还是删除后插入。
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,删除后重新插入
1.7 deplicate和replace的区别
1.7.1 核心操作逻辑不同
-
REPLACE:当插入的数据与表中现有数据发生唯一键冲突时,会先删除表中已存在的冲突行 ,然后插入新行 。本质上等价于执行了DELETE+INSERT两个操作。 -
ON DUPLICATE KEY UPDATE:当插入的数据发生唯一键冲突时,不会删除原有行 ,而是直接更新原有行中指定的字段 。本质上等价于执行了UPDATE操作(仅针对冲突行)。
1.7.2 对自增主键的影响不同
-
REPLACE:由于会先删除冲突行再插入新行,若表使用自增主键,新插入的行会生成新的自增 ID (原有 ID 被废弃,不会重复使用)。例如:原有行id=1冲突,REPLACE后新行可能是id=2(自增 ID 递增)。 -
ON DUPLICATE KEY UPDATE:仅更新原有行,不会删除数据,因此自增主键的值保持不变 。例如:原有行id=1冲突,更新后仍为id=1。
1.7.3 对未指定字段的处理不同
-
REPLACE:插入新行时,若新数据中未明确指定某些字段,这些字段会使用表定义的默认值 (或NULL),覆盖原有行的值。例如:原有行有age=20,但REPLACE语句未指定age,则新行的age会变为默认值(如NULL)。 -
ON DUPLICATE KEY UPDATE:仅更新UPDATE子句中明确指定的字段,未指定的字段保持原有值不变 。例如:原有行age=20,UPDATE仅指定更新name,则age仍为 20。
1.7.4 示例对比
假设有表 student 结构如下:
sql
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) UNIQUE, -- 唯一索引,可能冲突
score INT
);已有数据:(id=1, name='Tom', score=80)
场景:插入 name='Tom' 的新数据(冲突)
-
使用
REPLACE:sqlREPLACE INTO student (name, score) VALUES ('Tom', 90);执行后结果:
-
原有行
(1, 'Tom', 80)被删除。 -
插入新行
(2, 'Tom', 90)(id 变为 2,自增 ID 递增)。
-
-
使用
ON DUPLICATE KEY UPDATE:sqlINSERT INTO student (name, score) VALUES ('Tom', 90) ON DUPLICATE KEY UPDATE score = VALUES(score);执行后结果:
- 原有行
(1, 'Tom', 80)被更新为(1, 'Tom', 90)(id 保持 1,仅更新score)。
- 原有行
1.7.5 适用场景
-
REPLACE:适合需要完全替换冲突行(包括未指定字段使用默认值)的场景,但需注意自增 ID 变化的影响(可能导致 ID 不连续)。 -
ON DUPLICATE KEY UPDATE:适合仅更新部分字段、保留其他原有数据的场景,效率更高(无需删除操作),且不会改变自增 ID。
总结
两者的核心区别在于:REPLACE 是 "删旧插新",会改变行的存在性和自增 ID;ON DUPLICATE KEY UPDATE 是 "原地更新",仅修改指定字段,保留原有行的其他属性。选择时需根据是否需要保留原有数据、自增 ID 是否需不变等需求决定。
2. 删
2.1 删除表(delete)
语法:
sql
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]我们来看下面这行代码,我们可以通过delete这个指令来删除表中的一行。
如果我们把WHERE name = '孙悟空';这句话去掉的话,那么delete就会直接删除掉整张表。
sql
-- 查看原数据 SELECT * FROM exam_result WHERE name = '孙悟空';
+----+-----------+-------+--------+--------+
| id | name | chinese | math | english |
+----+-----------+-------+--------+--------+
| 2 | 孙悟空 | 174 | 80 | 77 | +
----+-----------+-------+--------+--------+
1 row in set (0.00 sec)
-- 删除数据
DELETE FROM exam_result WHERE name = '孙悟空';
Query OK, 1 row affected (0.17 sec)
-- 查看删除结果
SELECT * FROM exam_result WHERE name = '孙悟空';
Empty set (0.00 sec)PS:delete是不会让那个auto_increment重新开始计算的,也就是说我们删除一张表之后如果再往里面插入数据的话,
2.2 截断表(truncate)
语法:
sql
TRUNCATE [TABLE] table_name注意:这个操作慎用
-
只能对整表操作,不能像 DELETE 一样针对部分数据操作;
-
实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
-
会重置 AUTO_INCREMENT 项
所以说这个的话就仅做了解即可,因为他不支持数据回滚就意味着无法通过一些常规手段来对数据表进行复原。但是他删除数据的速度很快,在一些已经确定要删除且数据很大的表中很好用。
2.3 删除的注意点
DELETE 和 TRUNCATE 都只删除表中的数据 ,而表的结构(包括列定义、数据类型、索引、约束、主键等)会被完整保留,不会被删除。
具体来说:
delete:仅删除表中符合条件的行(或全表行),表的结构、索引、约束等元数据完全不变。- truncate:同样只删除数据,表的结构、索引、约束等依然保留(相当于 "清空内容但保留容器")。