在 AI 应用开发中,传统线性流程框架面对多步骤推理、多智能体协作等复杂场景时,往往显得灵活不足。而 LangGraph 作为 LangChain 生态下的重要扩展,以状态图结构为核心,为构建动态、循环且具备状态管理的 AI 系统提供了全新思路。本文将从核心概念拆解到实际案例开发,带你全面掌握 LangGraph 的使用方法。
官⽹地址: https://www.langchain.com/langgraph
官⽅⽂档: https://langchain-ai.github.io/langgraph/
官⽅⽂档(中⽂): https://langgraph.com.cn/index.html
一、LangGraph:不止于 "图" 的 AI 工作流框架
不同于传统线性或树状结构的 AI 框架,LangGraph 的核心是有向循环图(Directed Cyclic Graph, DCG) ,它将 AI 任务的执行过程抽象为节点、边与状态的协同作用。这种结构不仅支持简单的顺序执行,更能轻松实现条件分支、循环迭代和多智能体数据共享,完美适配需要动态调整流程的复杂场景 ------ 比如需要多轮工具调用的自主智能体,或是协调多个专业 AI 助手的项目协作系统。
LangGraph 的官方生态提供了完善的学习资源,开发者可通过官网了解最新动态,或参考中文文档快速上手,降低语言门槛。
二、三大核心组件:理解 LangGraph 的 "骨架"
LangGraph 的所有功能都基于节点、边、状态三大组件展开,三者协同构成可灵活调度的 AI 工作流。
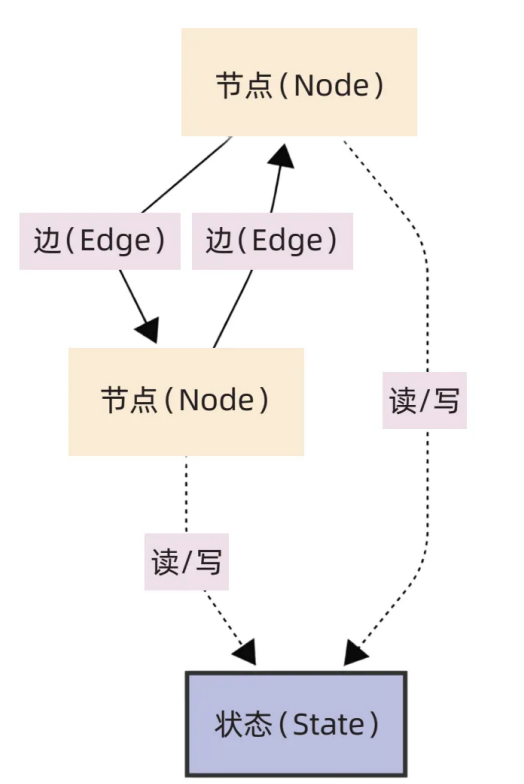
1. 节点(Node):工作流的 "执行单元"
节点是 LangGraph 中最小的功能载体,每个节点封装一个独立的计算逻辑,常见类型分为四类:
- 大语言模型调用节点:负责与 LLM 交互,完成文本生成、语义理解等核心任务,支持自定义模型参数与提示词模板,比如让 GPT-4 生成项目方案初稿。
- 工具调用节点:连接外部工具或 API,扩展 AI 的实际能力,例如调用天气 API 获取实时数据、调用搜索引擎补充知识库、调用数据库查询业务数据等。
- 自定义函数节点:将任意 Python 函数封装为节点,适配个性化业务需求,比如数据格式清洗、规则校验(如判断用户输入是否符合隐私规范)、对接内部系统接口等。
- 子图节点:将一组关联节点与边打包为独立子图,作为主图的一个节点使用。这种模块化设计能大幅提升复杂系统的可维护性,比如将 "用户问题分类 - 意图识别 - 初步应答" 封装为一个 "前置处理子图"。
2. 边(Edge):工作流的 "导航系统"
边定义了节点间的执行顺序与跳转逻辑,通过不同类型的边,可实现灵活的流程控制:
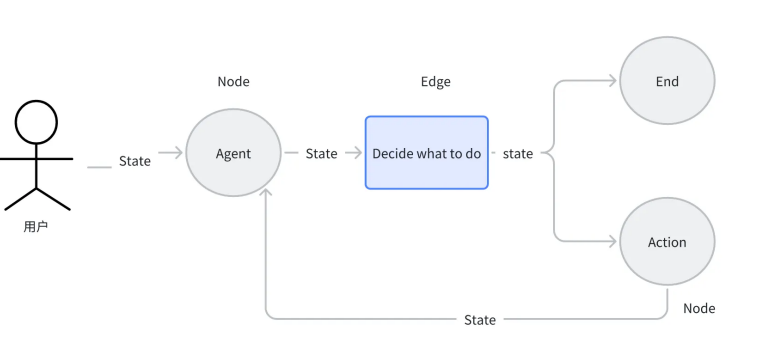
- 普通边:最基础的线性连接,前一个节点执行完毕后,直接触发下一个节点。例如 "LLM 生成回答→回答格式化" 的固定流程,适合无需判断的线性任务。
- 条件边:通过路由函数动态决定下一个节点,是构建决策型 AI 的核心。比如根据 LLM 的输出判断 "是否需要调用工具补充信息"------ 若回答中包含 "不确定",则跳转至工具调用节点;若回答完整,则直接跳转至输出节点。
- 入口点:定义工作流的起始位置,每个图必须至少有一个入口点,通常指向接收用户输入或初始化状态的节点,比如 "用户问题输入节点"。
- 条件入口点:根据初始状态动态选择起始节点。例如用户输入若为 "订单查询",则入口点指向 "订单系统对接节点";若为 "产品咨询",则入口点指向 "产品知识库查询节点"。
3. 状态(State):工作流的 "数据中枢"
状态是 LangGraph 的灵魂,作为全局数据容器,它承担着四大核心作用:
- 上下文存储:记录交互历史、任务进度与中间结果,确保 AI 能理解上下文。比如多轮对话中,状态会保存前几轮的用户提问与 AI 回答,让后续回复更连贯。
- 节点间数据传递:节点的输出会写入状态,后续节点从状态中读取所需数据,实现节点协同。例如工具调用节点将查询结果写入状态,LLM 节点从状态中读取该结果,生成最终回答。
- 状态持久化:支持将状态保存至内存、文件或数据库,不仅能实现 "任务中断后继续执行",还能通过 "时间旅行" 功能回溯历史状态,方便调试与问题定位。
- 多智能体共享:在多智能体系统中,多个智能体可共享同一状态,实现数据互通。比如 "客服智能体" 将用户的订单问题写入状态,"技术支持智能体" 从状态中读取订单信息,无需重复询问用户。
三、LangGraph 与 LangChain:如何选择?
很多开发者会困惑:同样是 LangChain 生态的工具,LangGraph 与 LangChain 该如何取舍?其实两者并非替代关系,而是针对不同场景的互补方案。
核心差异对比
| 对比维度 | LangChain | LangGraph |
|---|---|---|
| 流程结构 | 以线性流程为主,支持简单分支 | 非线性结构,原生支持循环、条件判断、中断 |
| 状态管理 | 基础上下文管理,依赖 Chain 串联 | 强大的全局状态管理,支持状态持久化与共享 |
| 核心优势 | 轻量易用,适合快速搭建简单应用 | 灵活复杂,适合多步骤推理、多智能体协作 |
| 学习成本 | 低,无需理解图论概念 | 中等,需掌握节点、边、状态的协同逻辑 |
| 典型场景 | 基础文档问答、简单聊天机器人、单智能体任务 | 多轮工具调用的自主智能体、多智能体协作系统、有状态对话 |
选择建议
- 若需求是线性、简单任务,比如 "上传文档→生成摘要"、"单轮问题→知识库查询→回答",LangChain 足够满足需求,开发效率更高。
- 若需求涉及复杂流程控制,比如 "根据中间结果动态调整步骤"、"多个智能体协同完成任务"、"需要记忆长周期上下文",则 LangGraph 是更优选择,其灵活性与状态管理能力能显著降低开发难度。
四、底层源码核心:Graph 基类与 StateGraph
要深入理解 LangGraph 的工作原理,需重点关注 Graph 基类与 StateGraph 这两个核心模块。
1. Graph 基类:图结构的 "基础框架"
所有图的构建与管理都基于 Graph 基类,它定义了图的核心属性与方法:
- 核心属性 :
nodes:字典类型,存储所有节点,键为节点名称,值为节点对应的可调用对象。edges:集合类型,存储所有普通边,每个元素是包含 "起始节点 - 目标节点" 的元组。branches:默认字典,存储条件分支逻辑,key 为源节点,value 为路由函数与目标节点的映射。compiled:布尔值,标识图是否已编译(编译后图结构不可修改,可执行)。
- 核心方法 :
add_node():添加节点,支持传入节点名称、可调用对象与元数据。add_edge():添加普通边,指定起始节点与目标节点。add_conditional_edges():添加条件边,传入源节点、路由函数与节点映射关系。set_entry_point()/set_conditional_entry_point():设置入口点与条件入口点。compile():编译图,验证结构合法性(如无孤立节点、入口点存在),生成可执行实例。
2. StateGraph:状态管理的 "实现载体"
StateGraph 继承自 Graph 基类,新增了状态管理能力,是实际开发中最常用的类:
- 核心扩展属性 :
state_schema:状态的数据结构定义,通常使用TypedDict指定字段与类型,确保状态数据的一致性与安全性。input_schema/output_schema:分别定义图的输入与输出数据结构,实现 "输入校验" 与 "输出过滤",避免内部数据泄露。
- 图模式 :
- 默认使用单模式:所有节点共享同一状态通道,读写相同的字段,适合简单场景。
- 支持自定义模式 :通过
state_schema指定不同节点的读写权限,比如内部节点可传递 "临时计算结果",而输出仅包含 "最终回答",适合对数据隐私与输出格式有严格要求的场景。
这里需要特别提到TypedDict------Python 类型注解工具,它能为字典指定字段类型,比如定义OverallState(TypedDict)包含question: str与answer: str字段,确保节点读写状态时不会出现字段缺失或类型错误,大幅提升代码稳定性。
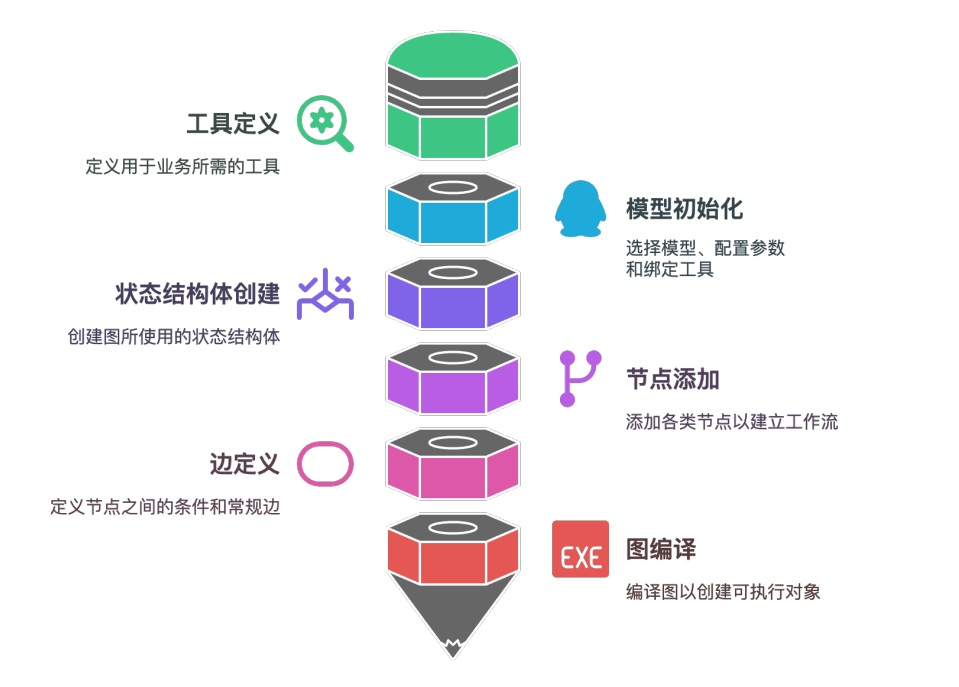
五、快速入门:从 0 搭建一个 "问题解答 - 翻译"AI 系统
理论掌握后,我们通过一个实际案例上手:搭建一个接收用户问题、生成中文回答、再将回答翻译成英文的 AI 系统,完整覆盖 "安装 - 定义状态 - 添加节点 - 连接边 - 编译 - 调用" 全流程。
1. 环境准备
首先安装依赖包,这里使用 LangGraph 与 DeepSeek 大模型(也可替换为 OpenAI、Anthropic 等模型):
bash
# 安装LangGraph与LangChain相关依赖
pip install -U langgraph "langchain[anthropic]"
# 安装DeepSeek模型集成包
pip install -U langchain-deepseek2. 完整代码实现
python
# 导入核心模块
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict, Optional
from langchain_openai import ChatOpenAI
# 1. 定义状态结构:使用TypedDict确保数据类型安全
class InputState(TypedDict):
question: str # 接收用户问题
llm_answer: Optional[str] # 存储LLM生成的中文回答,可选(初始为None)
class OutputState(TypedDict):
answer: str # 最终输出的英文翻译结果
# 合并输入与输出状态,形成全局状态
class OverallState(InputState, OutputState):
pass
# 2. 定义节点函数:每个函数接收状态,处理后返回更新的状态
def llm_node(state: InputState):
"""LLM节点:接收用户问题,生成中文回答"""
# 构建对话消息
messages = [
("system", "你是一位乐于助人的智能小助理,用中文回答用户问题,回答需简洁准确。"),
("human", state["question"])
]
# 初始化DeepSeek模型(可替换为其他模型)
llm = ChatOpenAI(
model="deepseek-chat",
base_url="https://api.deepseek.com/v1",
temperature=0 # 温度设为0,确保回答稳定
api-key="your-api-key"
)
# 调用LLM生成回答
response = llm.invoke(messages)
# 将结果写入状态,返回更新后的状态
return {"llm_answer": response.content}
def translate_node(state: InputState):
"""翻译节点:将LLM生成的中文回答翻译成英文"""
messages = [
("system", "无论接收的文本是什么语言,都请准确翻译成英文,保持语义完整。"),
("human", state["llm_answer"])
]
# 复用LLM实例(实际开发中可优化为全局实例,减少初始化开销)
llm = ChatOpenAI(
model="deepseek-chat",
base_url="https://api.deepseek.com/v1",
temperature=0,
api-key="your-api-key"
)
response = llm.invoke(messages)
# 将英文翻译结果写入状态的output字段
return {"answer": response.content}
# 3. 构建图结构
# 初始化StateGraph,指定全局状态、输入与输出模式
builder = StateGraph(
state_schema=OverallState,
input_schema=InputState,
output_schema=OutputState
)
# 添加节点:指定节点名称与对应的函数
builder.add_node("llm_node", llm_node) # LLM生成中文回答节点
builder.add_node("translate_node", translate_node) # 翻译节点
# 4. 连接边:定义执行流程
builder.add_edge(START, "llm_node") # 入口点→LLM节点
builder.add_edge("llm_node", "translate_node") # LLM节点→翻译节点
builder.add_edge("translate_node", END) # 翻译节点→结束点
# 5. 编译图:验证结构合法性,生成可执行实例
graph = builder.compile()
# 6. 调用图:传入用户问题,获取结果
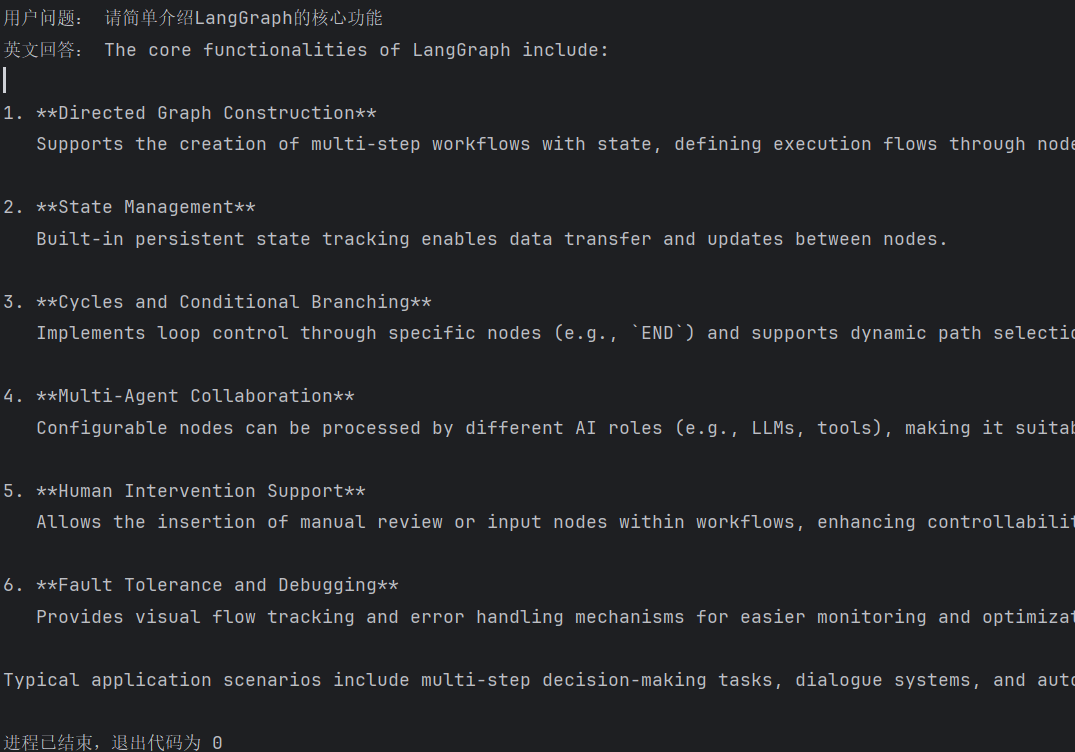
user_question = "请简单介绍LangGraph的核心功能"
result = graph.invoke({"question": user_question})
# 输出最终结果
print("用户问题:", user_question)
print("英文回答:", result["answer"])3. 代码解析与运行效果
- 状态设计 :通过
InputState与OutputState分离输入输出,OverallState整合全局数据,确保节点间数据传递清晰。 - 节点逻辑 :
llm_node负责生成中文回答,translate_node负责翻译,职责单一,便于维护与修改。 - 流程控制:通过普通边实现 "输入→LLM→翻译→输出" 的线性流程,若后续需要添加 "回答质量判断",只需插入条件边即可。
运行后,若用户问题为 "请简单介绍 LangGraph 的核心功能",可能得到如下结果:
六、总结与进阶方向
LangGraph 以其灵活的图结构与强大的状态管理,打破了传统线性框架的局限,为复杂 AI 应用开发提供了全新范式。通过本文的学习,你已掌握 LangGraph 的核心概念与基础实践,接下来可向这些方向进阶:
- 多智能体协作:将不同功能的 AI(如 "客服智能体"、"技术智能体"、"数据智能体")封装为节点,通过条件边与状态共享,实现多智能体协同解决复杂任务。
- 循环流程设计:利用条件边实现 "工具调用→结果校验→重新调用" 的循环,比如 LLM 判断工具返回结果不完整时,重新触发工具调用节点,直至获取满意结果。
- 状态持久化与分布式部署:将状态存储至 Redis、MySQL 等数据库,结合 LangGraph 的分布式能力,实现高可用、可扩展的 AI 系统。
- 复杂路由逻辑:通过自定义路由函数,实现更精细的流程控制,比如基于用户画像、任务优先级动态调整节点执行顺序。
LangGraph 的学习曲线虽比 LangChain 稍陡,但掌握后能应对更多高难度场景。建议结合官方文档与实际需求,从简单案例入手,逐步探索其强大潜力。