大模型微调---LlamaFactory自定义微调数据集
本文内容如下:
LLaMA-Factory微调数据集制作
Lora模型合并与量化导出使用
open-webui部署模型
一、LLaMA-Factory微调数据集制作
我们后面不管是微调什么模型、用什么框架,那么每一个框架对于自己的数据集是有一套格式要求的。
llama factory 有对数据集格式的要求,参考官方文档:https://llamafactory.readthedocs.io/zh-cn/latest/
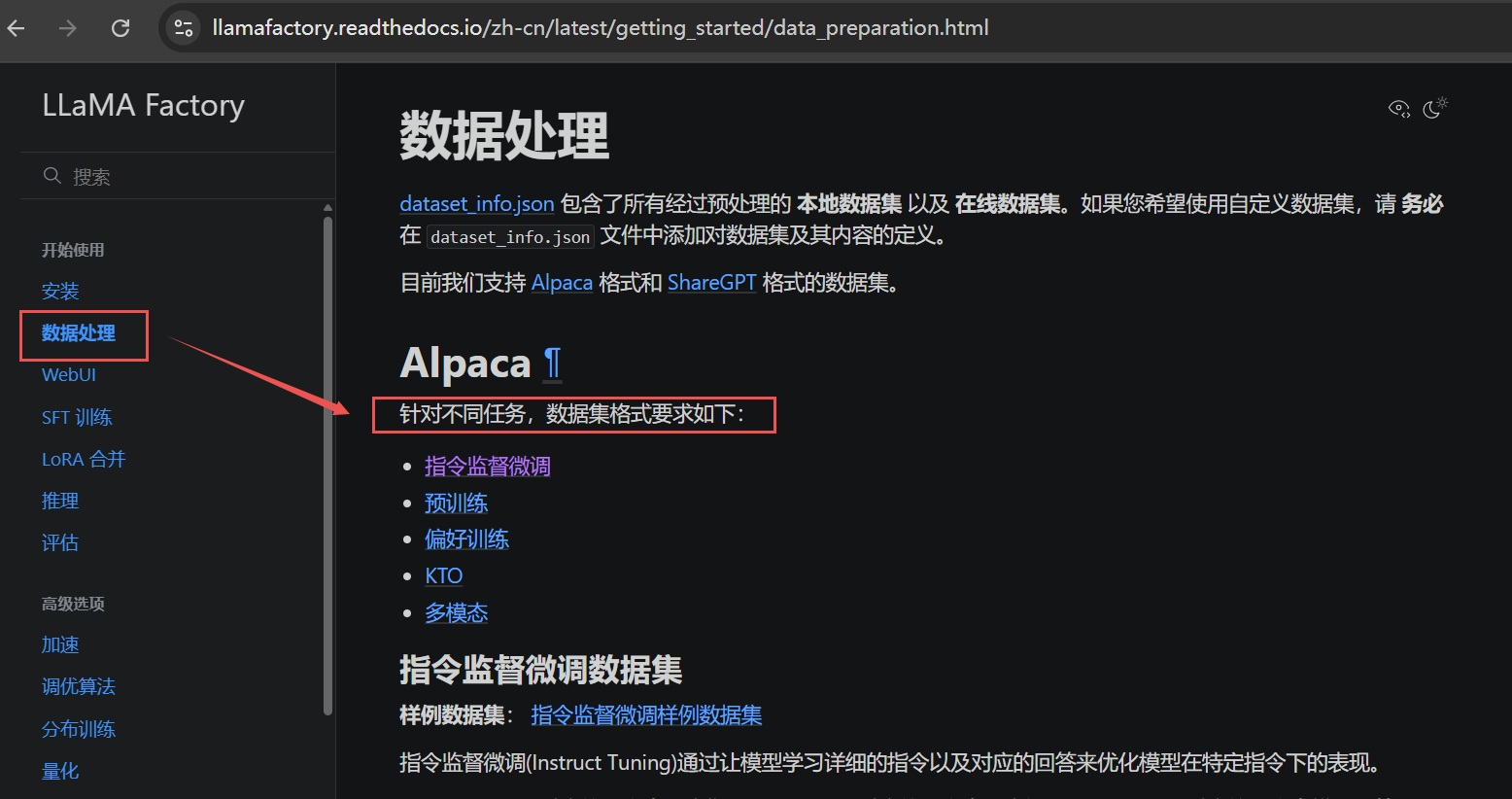
打开数据处理 ---> 指令监督微调,可以看到框架对于数据集有一个格式要求,我们数据集的格式必须转成它的固定格式,数据集不是通用的。不同的框架对数据集的读取的方法是不一样的,所以说每一个框架对数据格式要求不太一样,会有一些区别。
1.1 指令监督微调数据集
指令监督微调(Instruct Tuning)通过让模型学习详细的指令以及对应的回答来优化模型在特定指令下的表现。目前所支持的数据集格式有两种:
- 单轮对话
- 多轮对话
1.1.1 单轮对话
单轮对话就是简单的问答,就是模型仅针对当前的问题存在,它不存在历史的消息记录。
数据要求是这样的:首先数据格式是 json 文件(如果我们自己的数据集需要转成 json格式,然后每一个单轮对话就是一个 json object),其中的问答任务分为两个部分,一个是问题部分,我们把它称之为是输入部分 ,另一个是模型的回答的部分。
样例数据集: 指令监督微调样例数据集
json
"alpaca_zh_demo.json"
{
"instruction": "计算这些物品的总费用。 ",
"input": "输入:汽车 - $3000,衣服 - $100,书 - $20。",
"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
},-
instruction:是我们人类给模型提的问题 -
input:对instruction的一个补充,它可以为空,不是一个必须的选项 -
output:就是我们的标签,即我们希望模型给我们的回答
在上面的例子中,人类的最终输入是:
bash
计算这些物品的总费用。
输入:汽车 - $3000,衣服 - $100,书 - $20。模型的回答是:
bash
汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。1.1.2 多轮对话
多轮对话的指令监督微调数据集 格式要求 如下:
json
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]-
指定
system列对应的内容将被作为系统提示词。一般系统提示它主要起的作用:比如说第一次我们在启动某一个大模型的时候向我做一个介绍。 -
history列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
json
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}它只支持这两种数据格,接下来就带着大家来实操一下。
1.2 制作微调数据集
从魔塔社区上找一个开源数据集,搜索弱智吧的问答数据集,其中:
query就是问题response就是问题对应的答案
在魔塔社区上面下载数据有两种方式:
- 第一种就是通过SDK来进行下载;
- 第二种是通过下载按钮直接下载到本地;
当然弱智吧的原始数据没有办法直接放到
Llama Factor里面直接训练,虽然它提供的原始数据也是个json文件,但需要转换定对应格式的json文件。我们要做的第一件事就是数据集的格式转换。
转换代码如下:
python
import json
# 读取原始JSON文件
input_file = "data/ruozhiba_qaswift.json" # 你的JSON文件名
output_file = "data/ruozhiba_qaswift_train.json" # 输出的JSON文件名
with open(input_file, "r", encoding="utf-8") as f:
data = json.load(f)
# 转换后的数据
converted_data = []
for item in data:
converted_item = {
"instruction": item["query"],
"input": "",
"output": item["response"]
}
converted_data.append(converted_item)
# 保存为JSON文件(最外层是列表)
with open(output_file, "w", encoding="utf-8") as f:
json.dump(converted_data, f, ensure_ascii=False, indent=4)
print(f"转换完成,数据已保存为 {output_file}")1.3 使用自定义数据集微调模型
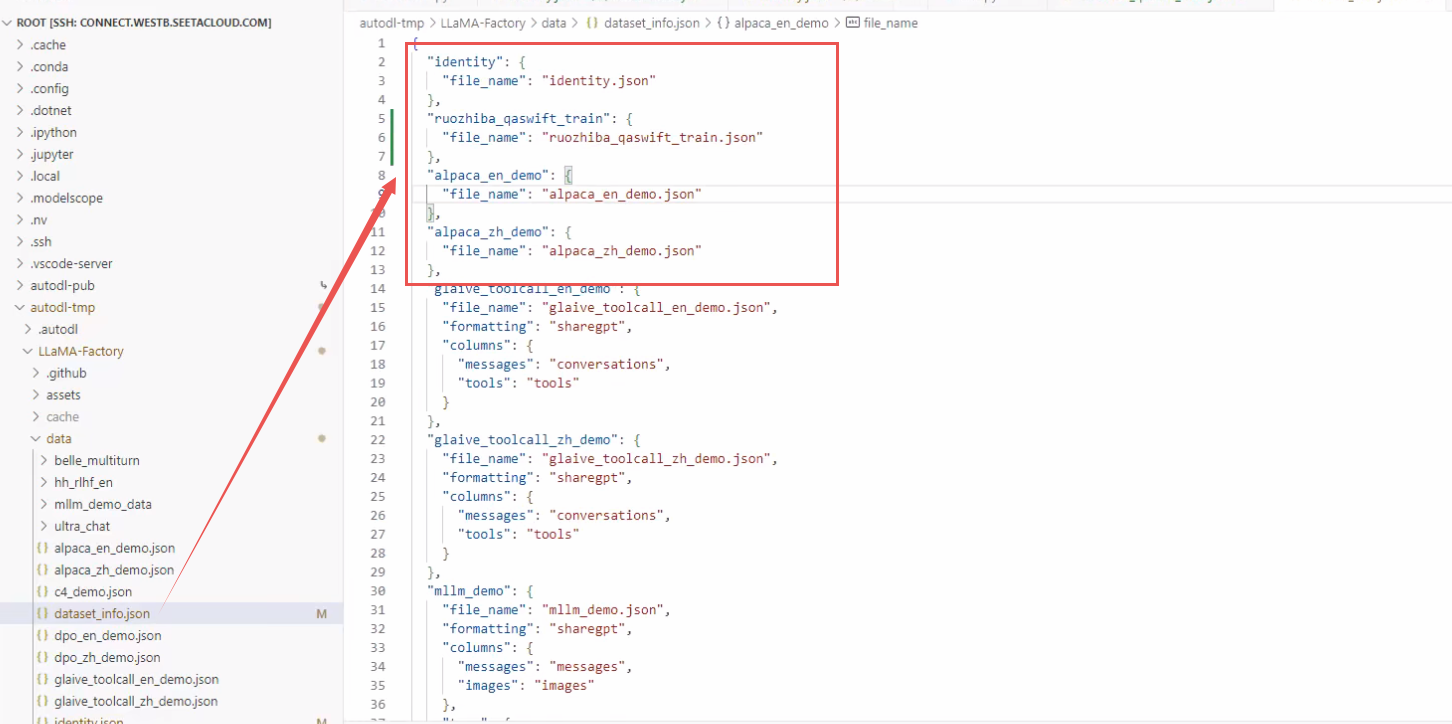
接下来使用弱智吧的数据集微调我自己的模型,首先得给它做个配置:找到 data 目录里面有一个dataset_info,然后我们就模仿人家配数据的方式,把我们自己的数据给它配进去:
-
我们把
identity东西我们拷贝一份儿。拷贝一份儿,然后给它粘过来 -
找到弱智吧数据路径,给它把填到
file_name里面
进入到 Llama Factory 根目录,启动 Llama factory:
bash
> llamafactory-cli webui在启动页面我们就可以看到刚才的数据集了。
Llama factory支持增加多套数据同时做训练。比如说可以选两个数据集进来。
-
比如弱吧数据集其实就是作为一款这种娱乐性的问答对;
-
比如
identity数据集对模型的一个自我认知的训练;

对于生成模型来讲,模型训练到什么时候可以把它停下来了呢?主要看模型有没有收敛(收敛就是下降的趋势已经不明显了,处于一个比相对来讲比较平缓的状态,你就可以把它停了)。
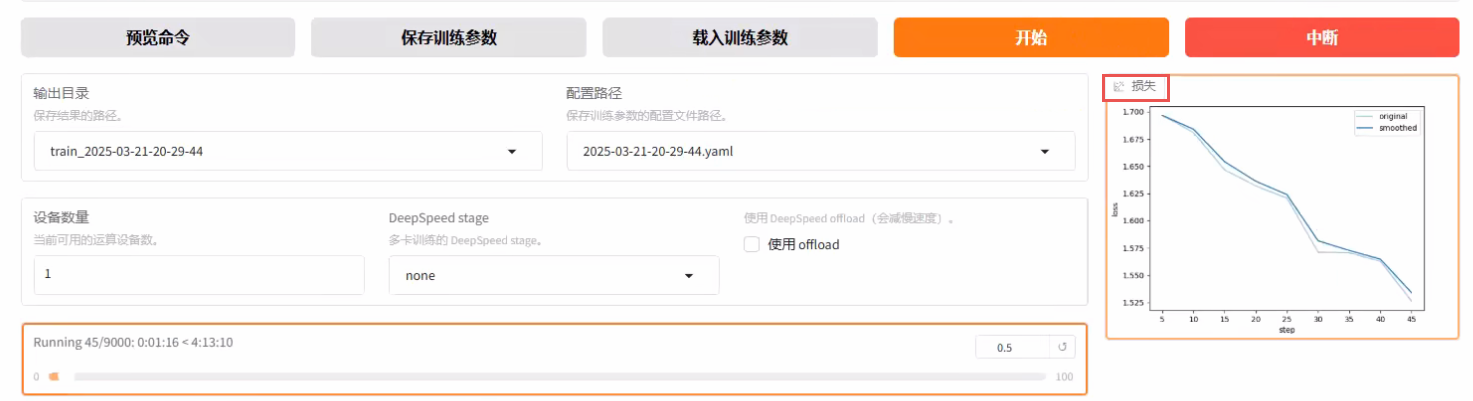
- 颜色浅的线叫
original,就是原始数据,它是真实的损失线 - 颜色深的线叫
smoothed,是平滑之后的损失线,方便我们去寻找损失的一个趋势
我们目前这种训练方案,它其实还不是最优的。
上节课我们已经训练过了一个版本,训练的内容在 training 目录里面,比如说 checkpoint 200它是不是个模型?他不是一个模型,它仅仅是 Qwen 的 Lora 模型(通过 Qwen 模型所分解出来的一个低质的矩阵模型啊,所以模型要比原来的模型要小的多),并且 Lora 模型是不能单独拿来使用的,因为它只是 Qwen 模型其中的一部分参数,它要基于原有的 base 模型来用。
一般情况下,如果我们把一个模型训练好以后,经过一定的评估测试,觉得它的达到我的目标了,我们必须要把模型进行合并打包 。合并打包完成之后,它就会变成一个跟原有 Qwen 一样的模型,并且它可以单独拿出来部署使用。
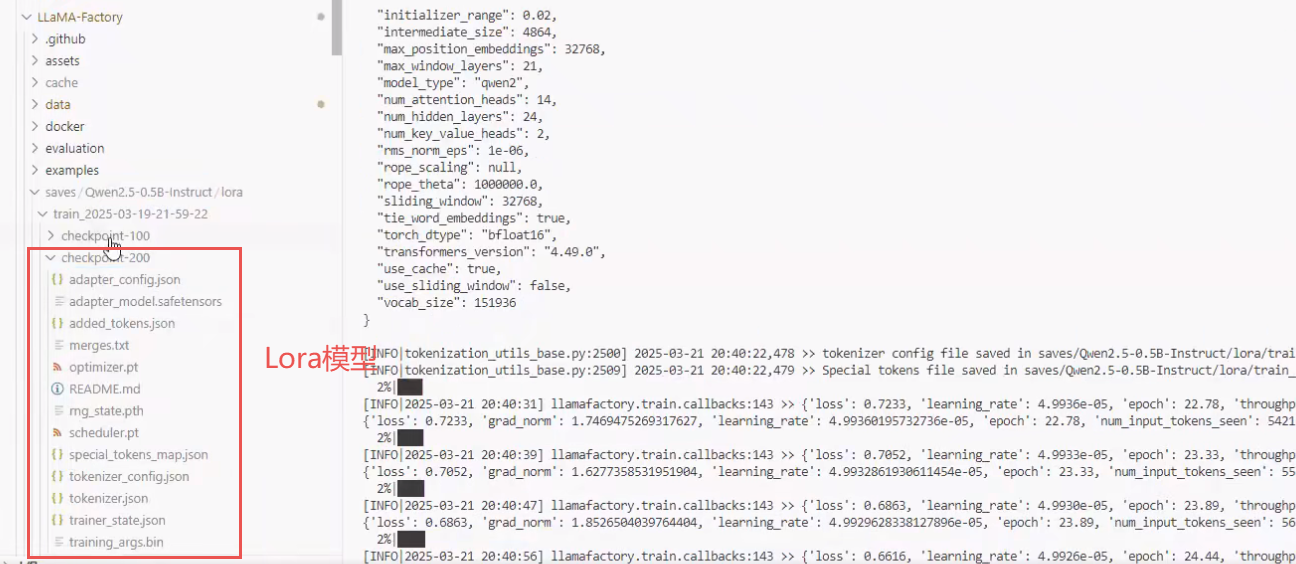
从结构上来讲,微调产生的 checkpoint 模型其实跟 base 模型没有太大的区别,都是有一些配置文件和一些参数。在 adapter_config.json 文件里面的 base_model_name_or_path 参数说的非常清楚,它是我们做微调训练的本地模型路径,是不能改的。
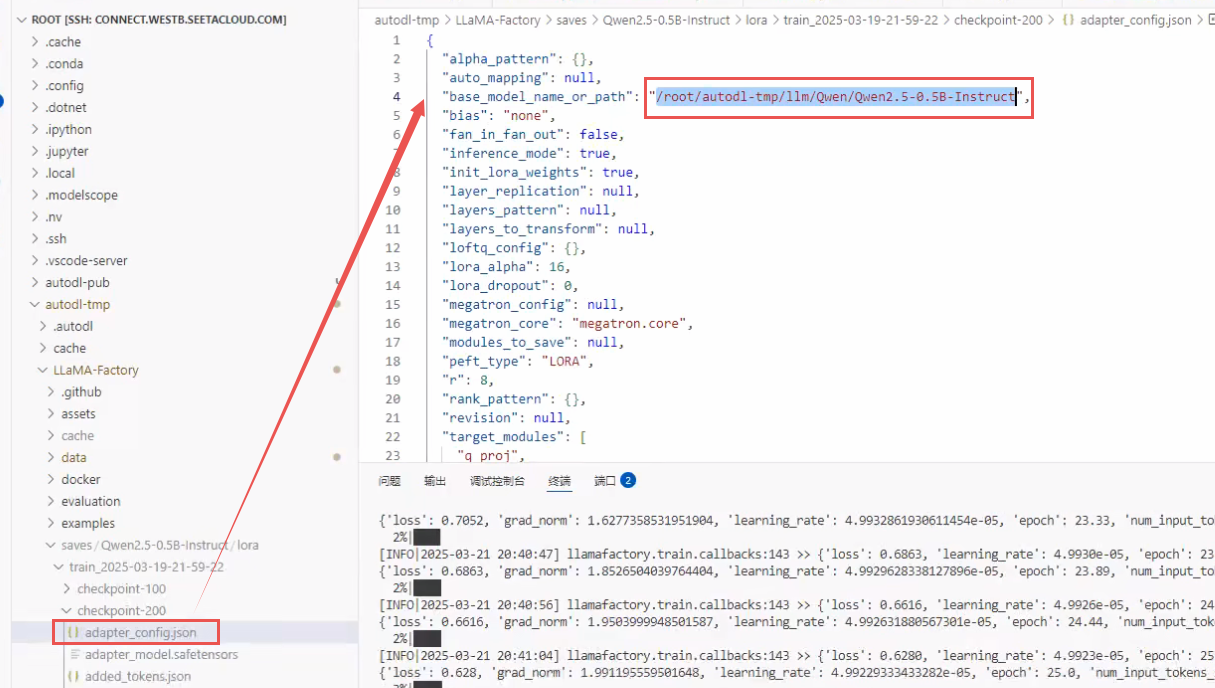
有这么几个参数要注意一下:
-
peft_type:就我们指令微调的类型。现在常用的就只有两种,Lora和QLora,如果是QLara模型,它后面还有一个量化参数。 -
r:就是你当前矩阵的质,矩阵的质一般不会自己手动去动。因为你一旦把里面参数改了之后,Lora模型就不可用了。
1.4 模型评估
模型评估分为主观评估和客观评估两种情况,客观评估对应 Llama Factory 中的 Evaluate & Predict模块,主观评估对应 Llama Factory 中的 Chat模块。
1.4.1 客观评估
客观评估:通过一些具体的评估指标,来判定模型输出的内容与标准答案的相似度(一般作为辅助参考)
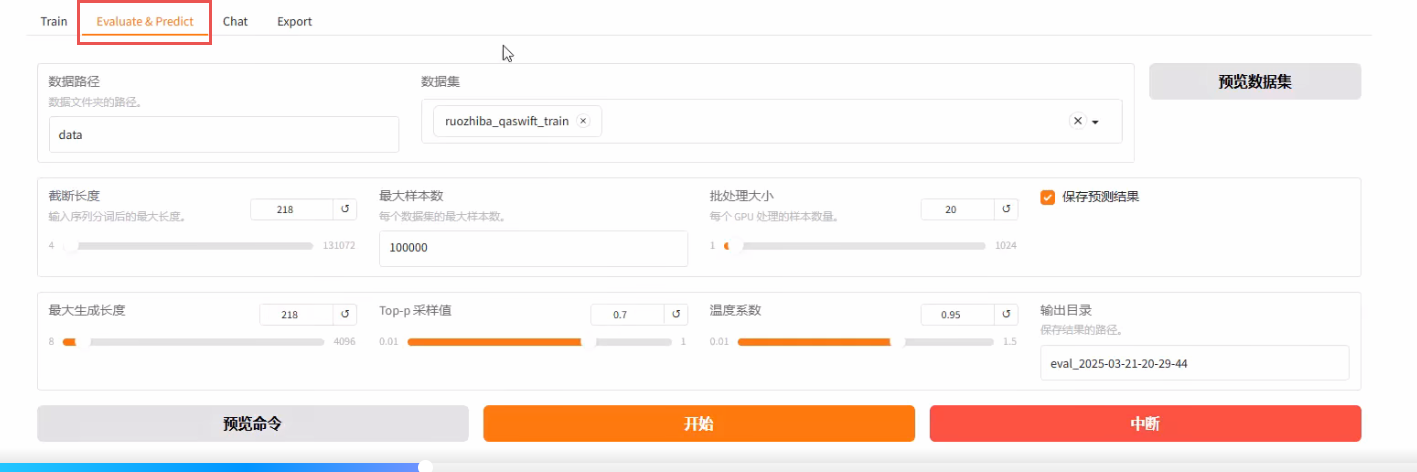
如果觉得模型训练的效果差不多了,需要给一个客观的指标来证明一下模型的效果,那我们就可以使用模型评估。做模型评估就得把数据集分成 train 训练集和 test 测试集。
- 评估的时候要注意一个细节:截断的长度必须得和训练保持一致,比如我们训练时是218,那评估时也要给到218。
评估的话不需要跑那么多轮,只需要就一轮即可。评估完之后平台会给一个评估的结果指标,但指标在生成模型上面的意义不大,因为生成模型一般不以客观评估作为最终的评估指标。
目前先知道客观评估只能作为参考,而不能作为决定性的条件。这是第一种评估方法,可以作为一个参考指标。
评估结果如下:
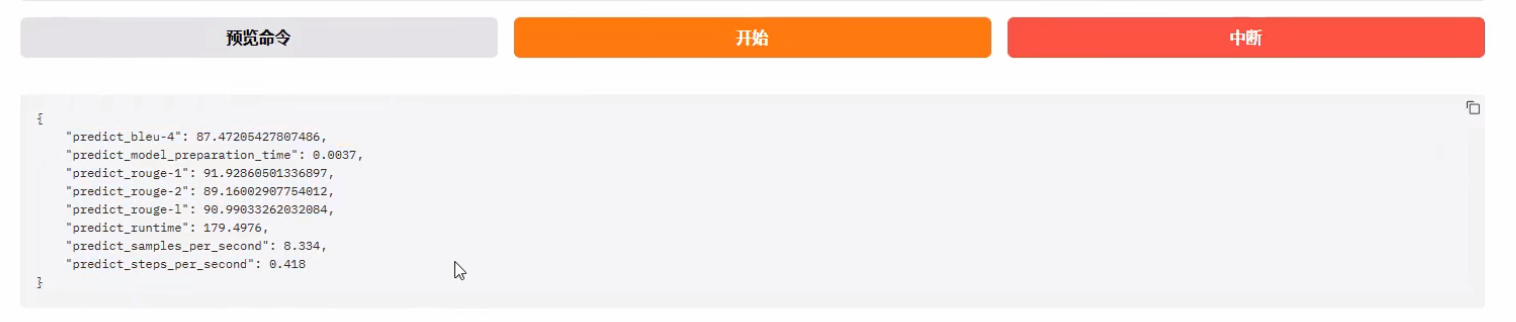
predict_bleu-4:就是拿模型输出的结果和 label 对比相似度(准确度)
predict_blue后面可以跟 1、2、3、4等数值,我们在进行评价的时候,会先把语句按照token进行n等拆分,然后对每组进行相似度对比;
predict_rouge-1:主要是根据召回率来设计的
predict_rouge后面可以跟 1、2、3、4等数值
predict_module_preparation:模型准备的时间
predict_runtime:模型执行的总的时间
1.4.2 主观评估
主观评估:通过一些核心的问题对模型进行提问,认为判定模型回复的质量(主要评估手段)
评价模型的训练情况,我们用的最多的其实还是用 chat 模块。
生成模型的评估方法主要是用主观评估,客观评估用的相对少一些。如果我们需要让模型生成的结果必须要严格遵守
label,我们就会拿客观指标去做评估,但这种场景一般来说不应该用微调去做,它应该用后面要讲的第二个板块的知识。
一般做主观评价的时候,会挑一些特定的问题去做一些测试,如果模型把几个核心问题回答没出错,基本上来讲就没有什么太大的问题。
举例如下:
拿自我认知训练进行验证:你是谁?
拿弱智吧里面几个问题:人只剩一个心脏了,还可以活吗?
在前端页面连续问几个问题发现模型跑偏了:
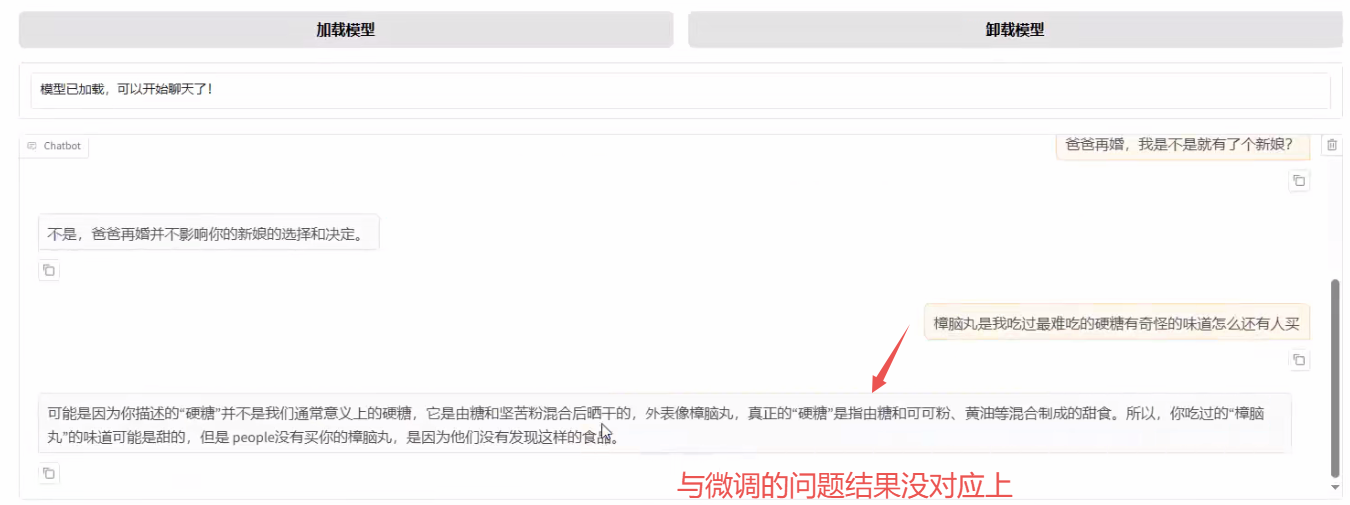
在微调训练的数据是单轮对话,但是前端页面窗口的一问一答是带有历史信息,所以现在的模式是多轮对话的模式,它应该回答的时候是不带有 history的,那么把它历史清空了再去问这些问题就可以了。
不能将单轮对话强制转化成多轮对话,多轮本质上来讲是有语义的相关性的,它得是真正意义上的多轮对话,才能够做成多轮对话。不然模型搞出来是是有问题的。
二、Lora 模型合并与量化导出
微调后的模型分为 base 模型和 Lora 模型,我们后续肯定要把这模型打包成一个大模型后进行使用。
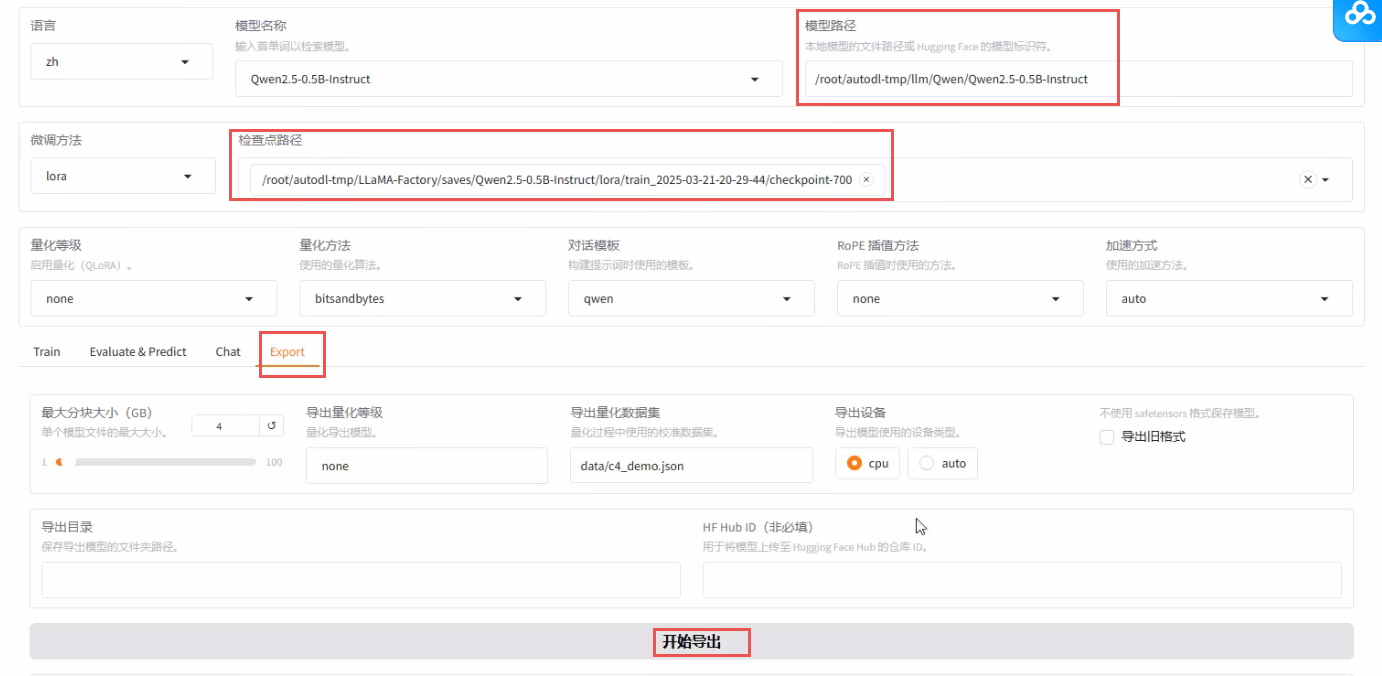
我们说下模型的导出,切换到 export 部分看几个参数:
-
最大分块大小:对于稍微大点的模型,由于它的参数量比较大会分开打包。我们一般的建议就是对大模型分块,不要让它超过
4GB;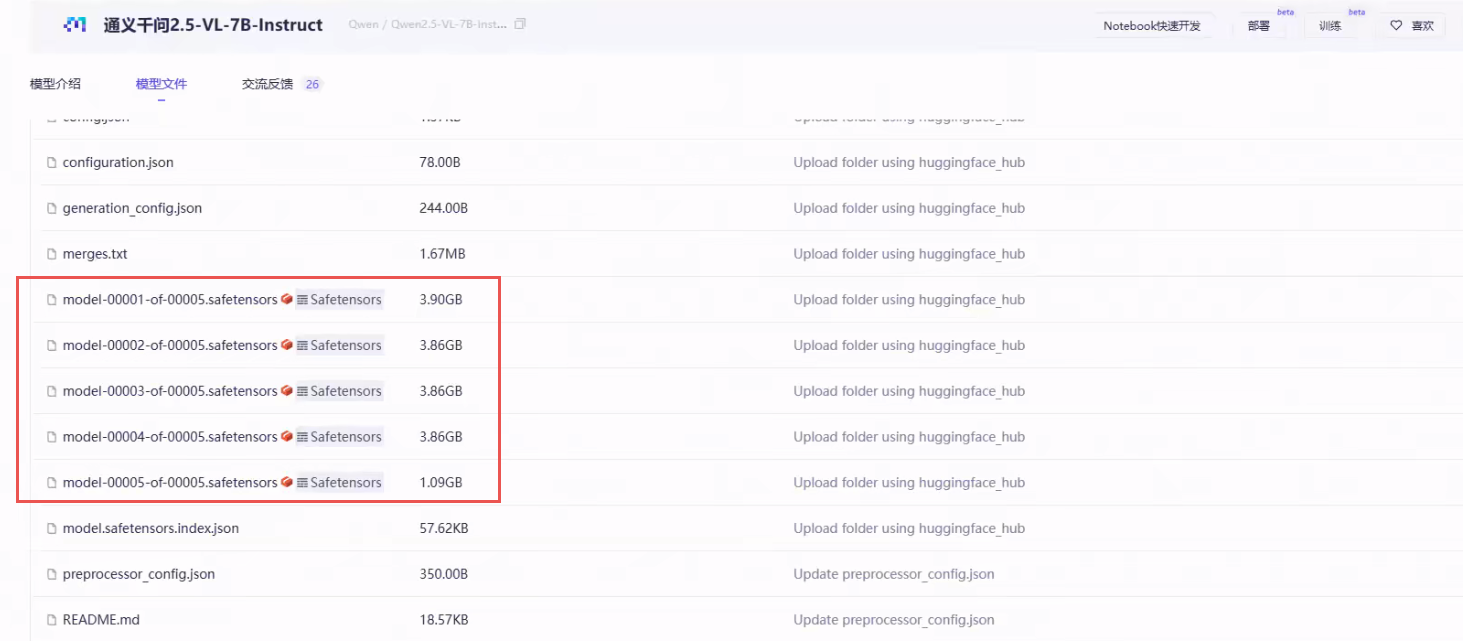
-
safetensors格式:现在我们大模型格式都用都用safetensors,因为它的格式更加高效一些,所以就不要用老的格式。 -
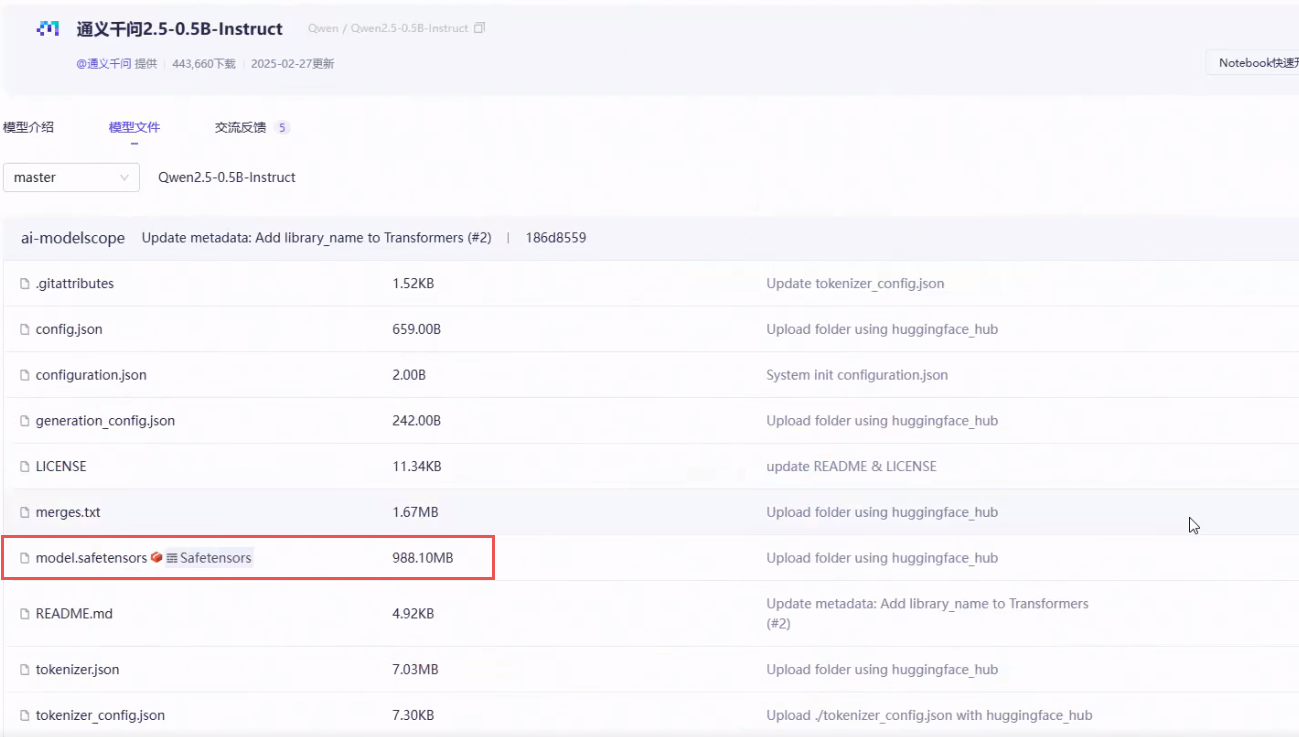
导出量化等级:量化导出量化导出的目的是为了加速性能。一般量化等级成8位或4位就可以了,再量化成2位时就能用了。
如果说我们现在的部署的设备算力较低,或者人家甲方就是明确有要求把模型打包成8位或4位,再进行量化导出。量化的本质其实是在阉割模型,它是以精度为代价去提升性能的,所以量化一定会导致模型的效果会变差。
量化导出必须是合并模型后再去做导出。
比如说我们把它模型先量化到8位来对比看一下,由于模型本身就很小(0.5B),所以量化后的模型答非所问。模型越大它量化之后的表现呢会更好一些。
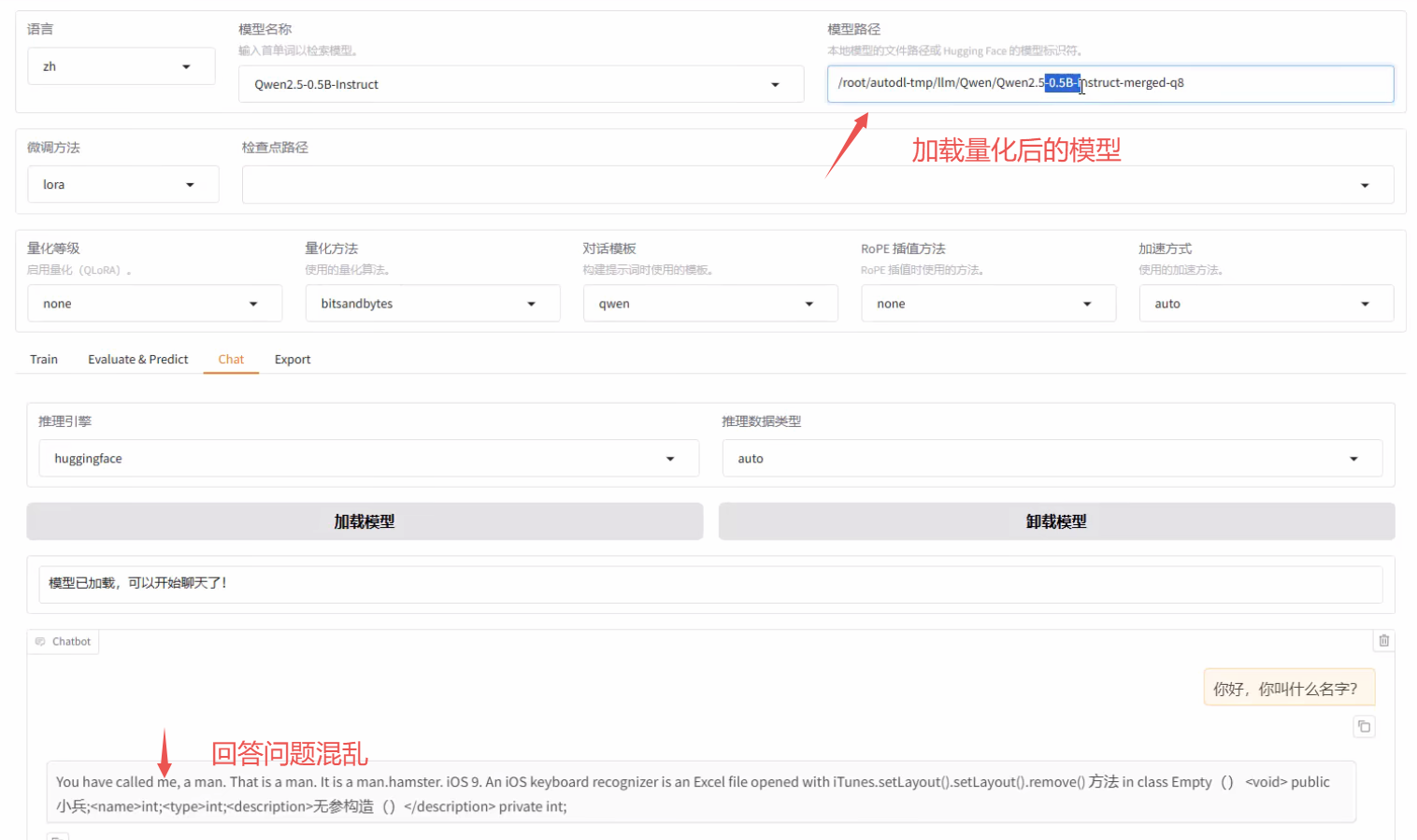
Qwen-0.5B 模型原始大小为 900多MB,经8位量化导出后变为400多MB。
记住量化时的两句话:
-
如果没有必要的这种情况,一般都不推荐做量化,因为量化它一定会导致结果会变差的;
-
如果你的模型本身很小(比如说像我们用的
0.5B),一般量化完之后模型就不能用了;
量化不是没有意义,其实量化针对的是低算力的设备,低算力带来的影响一定是低精度的,但不是说低精度就不能用了,比如 ollma 部署的模型都是量化后的模型。量化的目的在于降低模型对算力的依赖,不是为了节约磁盘。主要针对一些个人用户或者对模型精度要求不高的场景,我们就会用 ollma 做部署,所以一般企业不用 ollma 。
补充:微调量化与导出量化的区别
微调量化 :
QLora参数量化后,由于模型正在参与训练,此时参数依然在动态变化,因此对模型精度的影响是非常小的(量化丢失的精度可以通过模型学习弥补回来),比较推荐使用。
导出量化:该行为是发生在模型已经训练完成后,并测试通过后要对模型打包部署时。一般来讲,导出量化是牺牲模型的精度来换取模型的推理性能。
注意:微调量化
QLora只发生在模型训练过程中,对权重保存的类型是不产生影响的。一般来讲,导出量化为了保证量化的误差不要太大,会在量化之后通过一个数据集对量化前后的参数进行"校准"。
三、open-webui 部署前端
参考:https://blog.csdn.net/xianfianpan/article/details/143441456
仓库:https://github.com/open-webui/open-webui
文档:https://docs.openwebui.com/
Open WebUI(前身为 Ollama WebUI)是一个可扩展的、功能丰富的、用户友好的自托管Web界面,设计用于完全离线运行。它支持各种LLM(大型语言模型)运行,包括 Ollama 和兼容 OpenAI 的 API。
Open-webui现已支持python3.11与python3.12。
企业一般是自己做 web 做前端,如果自己私人来玩的情况下,我们就可以直接借助于 open-webui。因为 open-webui 做了一整套管理的东西,前端界面的什么问答和各种配置都做完了。它是一个开源的前端界面,但问题是第一次搭的时候可能会麻烦一些。
安装 open-webui
- 创建虚拟环境后安装:
python
> conda create -n open-webui python==3.11
> conda activate open-webui
> pip install open-webui- 配置环境变量
properties
### 配置环境变量 ###
# open-webui在启动后会访问huggingface网站,配置国内的hf网站
export HF_ENDPOINT=https://hf-mirror.com
# open-webui默认对接ollma,由于推理框架是vllm,所以关闭ollma
export ENABLE_OLLAMA_API=False
# 配置后端vllm的地址
export OPENAI_API_BASE_URL=http://127.0.0.1:8000/v1
- 启动
open-webui
python
> open-webui serve一切运行正常后,可以通过浏览器输入 http://127.0.0.1:8080 打开 open-webui 面板进行使用。
关于后台持续运行服务,可以使用 tmux/screen/systemd 工具等方法,网上教程非常多,本文在此不叙述。
对话窗口如下:
目前 AI 的训练服务器架构这一块还是英伟达比较强,AMD 最近在显卡的游戏性能追上来了,但在AI这一块儿还有所欠缺。
选显卡的时候,我们要看两个参数:一个是显存 ,最低显存是跟模型的体积有关系的;另一个是算力,如果你的算力达不到的情况,模型也可以用,但是它会比较慢。