LangChain RAG 学习笔记:从文档加载到问答服务
我在先前的随笔中分享过用Dify低代码平台来实现问答系统,也有几篇随笔是通过不同的方式来访问大模型。本篇将使用LangChain来做对应的实现。相关代码主要是通过Trae,它可以帮助你快速的了解了基本使用 LangChain 构建 RAG的方法,包括从文档加载、向量存储到问答接口实现,整个过程涉及多个关键环节。
虽然借助大模型以及Trae,给我们提供了另外一种生成代码和学习代码的方式,但其目前还是需要人工来参与的,尤其是版本的变化导致引入的包和接口的调用方式都发生了很多变化,所以这就需要一个根据生成的代码不断的去调试和修正。本文里贴出的代码也是经历过这个过程之后总结下来的。
RAG 系统整体架构
首先回忆一下RAG 系统的核心思想,是将用户查询与知识库中的相关信息进行匹配,再结合大语言模型生成准确回答。
这里我将一套 RAG 系统通分成以下几个模块:
- 文档加载与处理
- 文本分割与嵌入
- 向量存储管理
- 检索功能实现
- 问答生成服务
- 接口部署
这几个模块完成了后端模块的建立。实际项目中会考虑更多的模块,比如大模型的选择和部署,向量数据库的选择,知识库的准备,前端页面的搭建等,这些将不作为本文描述的重点。
本文代码,关于大模型的选择,我们将基于 DashScope 提供的嵌入模型和大语言模型,结合 LangChain 和 Chroma 向量数据库来实现整个系统。
这里我历经过一些莫名其妙的磨难,比如刚开始我选择本地的Ollama部署,包括向量模型都是在本地。但是在测试的过程中,发现召回的结果很离谱。比如我投喂了劳动法和交通法的内容,然后问一个劳动法相关的问题,比如哪些节假日应该安排休假,结果召回的结果中有好多是交通法的内容。刚开始我以为是向量模型的问题,于是在CherryStudio里,构建同样的知识库,使用同样的向量嵌入模型,召回测试的结果很符合预期。后来在LangChain里又尝试过更换向量数据库,以及更改距离算法,召回的结果都达不到预期。直到有一天,本地部署的嵌入模型突然不工作了(真的好奇怪,同样的模型在windows和macos都有部署,突然间就都不能访问了,至今原因不明。),于是尝试更换到在线的Qwen的大模型,召回测试终于复合预期了。
吐槽完毕,接下来进入正题:
1. 文档加载与向量库构建
文档加载是 RAG 系统的基础,需要处理不同格式的文档并将其转换为向量存储。这里我检索的是所有txt和docx文件。
所有的知识库文件都放在knowledge_base文件夹下,向量数据库存储在chroma_db下。
知识库为了测试召回方便,我投喂了法律相关的内容,主要有劳动法和道路安全法,同时也投喂了一些自己造的文档。
向量数据库这里用到的是chroma,其调用方法相对简单,不需要额外安装配置什么。同时也可以选择比如FAISS,Milvus甚至PostgreSQL,但这些向量库需要单独的部署和配置,过程稍微复杂一点。所以这篇文章的向量库选择了Chroma。
核心代码实现
python
def load_documents_to_vectorstore(
document_dir: str = "./RAG/knowledge_base",
vectorstore_dir: str = "./RAG/chroma_db",
embedding_model: str = "text-embedding-v1",
dashscope_api_key: Optional[str] = None,
chunk_size: int = 1000,
chunk_overlap: int = 200,
collection_name: str = "my_collection",
) -> bool:
# 文档目录检查
if not os.path.exists(document_dir):
logger.error(f"文档目录不存在: {document_dir}")
return False
# 加载不同格式文档
documents = []
# 加载 txt
txt_loader = DirectoryLoader(document_dir, glob="**/*.txt", loader_cls=TextLoader)
documents.extend(txt_loader.load())
# 加载 docx
docx_loader = DirectoryLoader(document_dir, glob="**/*.docx", loader_cls=Docx2txtLoader)
documents.extend(docx_loader.load())
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
separators=["\n\n", "\n", " ", ""],
)
splits = text_splitter.split_documents(documents)
# 初始化嵌入模型
embeddings = DashScopeEmbeddings(model=embedding_model, dashscope_api_key=dashscope_api_key)
# 探测嵌入维度,避免维度冲突
probe_vec = embeddings.embed_query("dimension probe")
emb_dim = len(probe_vec)
collection_name = f"{collection_name}_dim{emb_dim}"
# 创建向量存储
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
collection_name=collection_name,
persist_directory=persist_dir,
)
vectorstore.persist()
return True关键技术点解析
1.** 文档加载 **:使用 DirectoryLoader 批量加载目录中的 TXT 和 DOCX 文档,可根据需求扩展支持 PDF 等其他格式
2.** 文本分割 **:采用 RecursiveCharacterTextSplitter 进行文本分割,关键参数:
chunk_size:文本块大小chunk_overlap:文本块重叠部分,确保上下文连贯性separators:分割符列表,优先使用段落分隔
3.** 嵌入处理 **:
- 使用 DashScope 提供的嵌入模型生成文本向量
- 自动探测嵌入维度,避免不同模型间的维度冲突
- 为不同模型创建独立的存储目录,确保向量库兼容性
4.** 数据写入 ** 使用的是from_documents方法。这里如果嵌入模型不可用的话,会卡死在这里。
2. 向量库构建与检索功能
向量库是 RAG 系统的核心组件,负责高效存储和检索文本向量。
向量库构建函数
python
def build_vectorstore(
vectorstore_dir: str = "./RAG/chroma_db",
embedding_model: str = "text-embedding-v4",
dashscope_api_key: Optional[str] = None,
collection_name_base: str = "my_collection",
) -> Tuple[Chroma, DashScopeEmbeddings, int, str]:
# 获取API密钥
if dashscope_api_key is None:
dashscope_api_key = os.getenv("DASHSCOPE_API_KEY")
# 初始化嵌入模型
embeddings = DashScopeEmbeddings(model=embedding_model, dashscope_api_key=dashscope_api_key)
# 探测嵌入维度与持久化目录
probe_vec = embeddings.embed_query("dimension probe")
emb_dim = len(probe_vec)
collection_name = f"{collection_name_base}_dim{emb_dim}"
model_dir_tag = embedding_model.replace(":", "_").replace("/", "_")
persist_dir = os.path.join(vectorstore_dir, model_dir_tag)
# 加载向量库
vs = Chroma(
persist_directory=persist_dir,
embedding_function=embeddings,
collection_name=collection_name,
)
return vs, embeddings, emb_dim, persist_dir检索功能实现
python
def retrieve_context(
question: str,
k: int,
vectorstore: Chroma,
) -> List[str]:
"""使用向量库检索 top-k 文档内容,返回文本片段列表"""
docs = vectorstore.similarity_search(question, k=k)
chunks: List[str] = []
for d in docs:
src = d.metadata.get("source", "<unknown>")
text = d.page_content.strip().replace("\n", " ")
chunks.append(f"[source: {src}]\n{text}")
return chunks技术要点说明
1.** 向量库兼容性处理 **:
- 为不同嵌入模型创建独立目录
- 集合名包含维度信息,避免维度冲突
- 自动探测嵌入维度,确保兼容性
2.** 检索实现 **:
- 使用
similarity_search进行向量相似度检索 - 返回包含来源信息的文本片段
- 可通过调整
k值控制返回结果数量,CherryStudio默认是5,所以在这里我也用这个值。
注:similarity_search不返回相似度信息,如果需要这个信息,需要使用similarity_search_with_relevance_scores。
3. 问答功能实现
问答功能是 RAG 系统的核心应用,大体的流程就是结合检索到的上下文和大语言模型生成回答。如果你已经知道了如何在Dify中进行类似操作,那么这部分代码理解上就会容易些,尤其是在用户提示词部分,思路都是一样的。
问答核心函数
python
def answer_question(
question: str,
top_k: int = 5,
embedding_model: str = "text-embedding-v4",
chat_model: str = os.getenv("CHAT_MODEL", "qwen-turbo"),
dashscope_api_key: Optional[str] = None,
vectorstore_dir: str = "./RAG/chroma_db",
temperature: float = 0.2,
max_tokens: int = 1024,
) -> Tuple[str, List[str]]:
# 构建向量库
vs, embeddings, emb_dim, persist_dir = build_vectorstore(
vectorstore_dir=vectorstore_dir,
embedding_model=embedding_model,
dashscope_api_key=dashscope_api_key,
)
# 检索上下文
context_chunks = retrieve_context(question, k=top_k, vectorstore=vs)
sources = []
for c in context_chunks:
# 提取来源信息
if c.startswith("[source: "):
end = c.find("]\n")
if end != -1:
sources.append(c[len("[source: "):end])
context_str = "\n\n".join(context_chunks)
# 构造提示词
system_prompt = (
"你是一个严谨的问答助手。请基于提供的检索上下文进行回答,"
"不要编造信息,若上下文无答案请回答:我不知道。"
)
user_prompt = (
f"问题: {question}\n\n"
f"检索到的上下文(可能不完整,仅供参考):\n{context_str}\n\n"
"请给出简洁、准确的中文回答,并在需要时引用关键点。"
)
# 调用大语言模型生成答案
dashscope.api_key = dashscope_api_key
gen_kwargs = {
"model": chat_model,
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
"result_format": "message",
"temperature": temperature,
"max_tokens": max_tokens,
}
resp = Generation.call(**gen_kwargs)
answer = _extract_answer_from_generation_response(resp)
return answer.strip(), sources关键技术点
1.** 提示词设计 **:
- 系统提示词明确回答约束(基于上下文、不编造信息)
- 用户提示词包含问题和检索到的上下文
- 明确要求简洁准确的中文回答
2.** 模型调用参数 **:
temperature:控制输出随机性,低温度值生成更确定的结果,对于问答系统这个值推荐接近0。如果是生成诗词类应用则推荐接近1.max_tokens:限制回答长度result_format:指定输出格式,便于解析
3.** 结果处理 **:
- 从模型响应中提取答案文本
- 收集并返回来源信息,提高回答可信度
4. 构建 HTTP 服务接口
为了方便使用,我们可以将问答功能封装为 HTTP 服务,这样更方便将服务集成到其它应用环境中。
HTTP 服务实现
python
class QAHandler(BaseHTTPRequestHandler):
def do_GET(self):
parsed = urllib.parse.urlparse(self.path)
if parsed.path != "/qa":
self.send_response(HTTPStatus.NOT_FOUND)
self.send_header("Content-Type", "application/json")
self.end_headers()
self.wfile.write(json.dumps({"error": "Not Found"}).encode("utf-8"))
return
qs = urllib.parse.parse_qs(parsed.query)
question = (qs.get("question") or [None])[0]
top_k = int((qs.get("top_k") or [5])[0])
embedding_model = (qs.get("embedding_model") or [os.getenv("EMBEDDING_MODEL", "text-embedding-v4")])[0]
chat_model = (qs.get("chat_model") or [os.getenv("CHAT_MODEL", "qwen-turbo")])[0]
if not question:
self.send_response(HTTPStatus.BAD_REQUEST)
self.send_header("Content-Type", "application/json")
self.end_headers()
self.wfile.write(json.dumps({"error": "Missing 'question' parameter"}).encode("utf-8"))
return
try:
answer, sources = answer_question(
question=question,
top_k=top_k,
embedding_model=embedding_model,
chat_model=chat_model,
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"),
vectorstore_dir=os.getenv("VECTORSTORE_DIR", "./RAG/chroma_db"),
)
payload = {
"question": question,
"answer": answer,
"sources": sources,
"top_k": top_k,
"embedding_model": embedding_model,
"chat_model": chat_model,
"status": "ok",
}
self.send_response(HTTPStatus.OK)
self.send_header("Content-Type", "application/json")
self.end_headers()
self.wfile.write(json.dumps(payload, ensure_ascii=False).encode("utf-8"))
except Exception as e:
logger.error(f"请求处理失败: {e}")
self.send_response(HTTPStatus.INTERNAL_SERVER_ERROR)
self.send_header("Content-Type", "application/json")
self.end_headers()
self.wfile.write(json.dumps({"error": "internal_error", "message": str(e)}).encode("utf-8"))
def run_server(host: str = "0.0.0.0", port: int = int(os.getenv("PORT", "8000"))):
httpd = HTTPServer((host, port), QAHandler)
logger.info(f"QA 服务已启动: http://localhost:{port}/qa?question=...")
httpd.serve_forever()通过这个http接口,就可以供其它应用进行调用,比如如下我用Trae生成的前端:
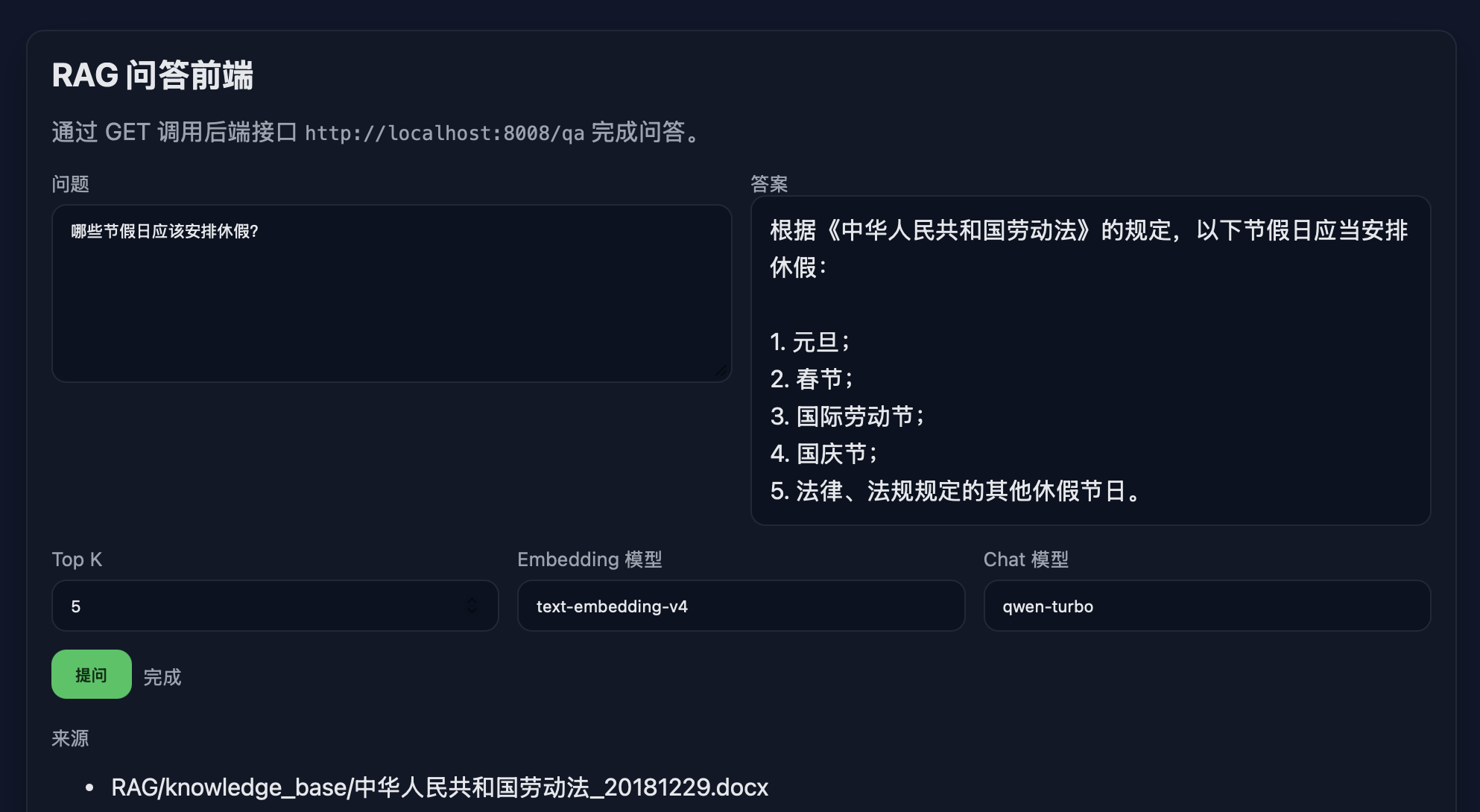
服务特点
1.** 接口设计 :提供 /qa 端点,支持通过 URL 参数指定问题和模型参数
2. 错误处理 :对缺失参数、服务错误等情况返回适当的 HTTP 状态码
3. 灵活性 :支持动态指定 top_k、嵌入模型和聊天模型
4. 易用性 **:返回包含问题、答案、来源和模型信息的 JSON 响应
5. 系统测试与验证
为确保检索的结果复合预期,建议单独实现召回测试功能,验证检索效果:
python
def recall(
query: str,
top_k: int = 5,
vectorstore_dir: str = "./RAG/chroma_db",
embedding_model: str = "text-embedding-v4",
dashscope_api_key: Optional[str] = None,
) -> None:
vs = build_vectorstore(
vectorstore_dir=vectorstore_dir,
embedding_model=embedding_model,
dashscope_api_key=dashscope_api_key,
)
logger.info(f"执行相似度检索: k={top_k}, query='{query}'")
docs = vs.similarity_search(query, k=top_k)
print("\n=== Recall Results ===")
for i, d in enumerate(docs, start=1):
src = d.metadata.get("source", "<unknown>")
snippet = d.page_content.strip().replace("\n", " ")
if len(snippet) > 500:
snippet = snippet[:500] + "..."
print(f"[{i}] source={src}\n {snippet}\n")通过召回测试,可以直观地查看检索到的文本片段,评估检索质量,为调整文本分割参数和检索参数提供依据。
当然召回测试,除了能在调用大模型前提前看到准确度,也能在测试过程中,节省大模型调用的成本消耗。
总结与展望
本文汇总了基于LangChain 构建 RAG 系统的简单实现,从文档加载、向量存储到问答服务实现。后续可以从以下几个方面进行改进:
- 支持更多文档格式(PDF、Markdown 等)
- 实现更高级的检索策略(混合检索、重排序等)
- 替换向量数据库
- 更改相似度算法
- 增加缓存机制,提高服务响应速度
- 实现批量处理和增量更新功能
- 增加用户认证和权限管理
本文所有代码可以在以下地址找到:
https://github.com/microsoftbi/Langchain_DEMO/tree/main/RAG