目录
[1.domain shift](#1.domain shift)
[2.domain adversarial training](#2.domain adversarial training)
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是domain shift问题的概念以及部分解决办法domain adversarial training。
1.domain shift
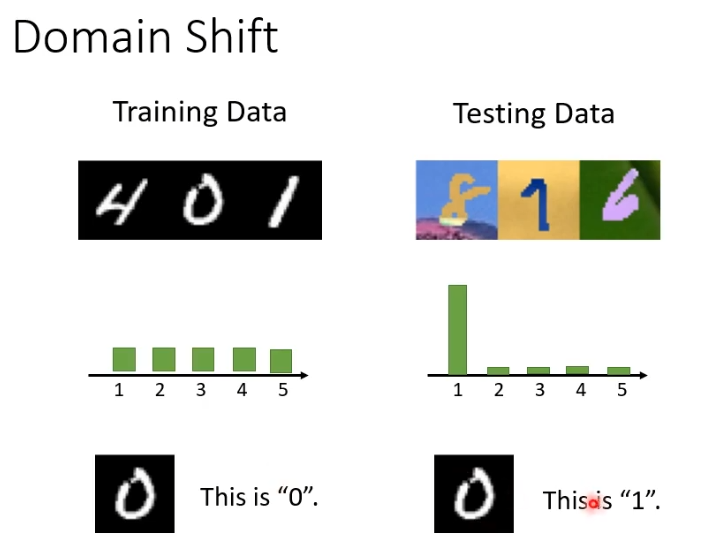
假设训练资料与测试资料分布不同会怎么样呢?举一个例子,假设数字辨识模型训练时是黑白的数字,但测试时是彩色的会发生什么事情?在黑白测试资料上会有很高的正确率,但是在彩色测试资料上就达不到及格分数。所以一旦训练资料与测试资料存在差异,训练出来的模型很可能会"坏掉"。这种问题叫作domain shift。

domain shift其实有很多类型,刚刚提到的是模型输入的资料分布有变化,还有另外一种输出的分布也有变化,举例来说就是,在训练资料上,每个数字的输出可能是一样的,但是在测试资料上某个数字的输出可能性特别大。此外还有一种特别罕见的,输入输出分布虽然一样,但是他们的关系变了。
2.domain adversarial training
训练资料称为source domain,测试资料称为target domain,假设有一些标注过的资料,我们希望可以通过这些资料训练出一个模型,这个模型可以用在不一样的domain上。

想要做到把模型用在不一样的domain上,在训练时就需要对target domain有一定的了解。一种情况是在target domain上有少量标注的资料,这种情况就可以用target domain来微调在source domain上训练出来的模型(类似BERT),但是要注意overfitting的情况。

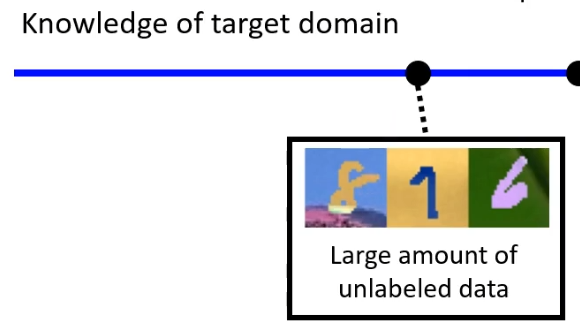
另一种情况是,在target domain上有大量的资料,但是没有标注。例如有很多有颜色的数字图片,但是没有标注。
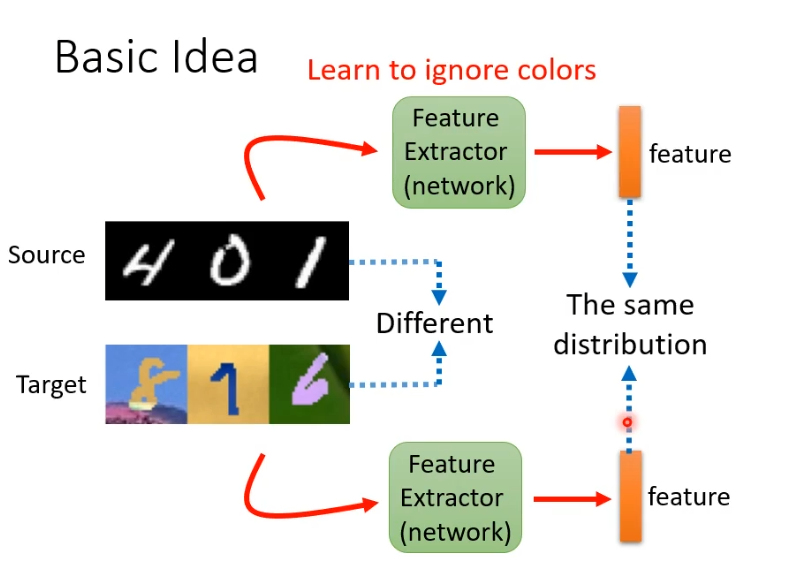
解决这个问题的基本想法是找一个feature extractor(本身是network),它以图片作为输入,输出一个向量。虽然source domain和target domain的图片表面不一样,但是期望feature extractor可以把他们不一样的部分去掉,抽取出共同部分,无视掉颜色的差异。这样就可以用这些feature训练一个模型直接用在target domain上。
如何找出这样的feature extractor?可以把一个一般的classify分为feature extractor和label predictor两个部分。我们将source domain和target domain的图片丢进去把feature extractor的输出拿出来看。要让他们的输出看不出差异,即红色和蓝色的点分不出差异。
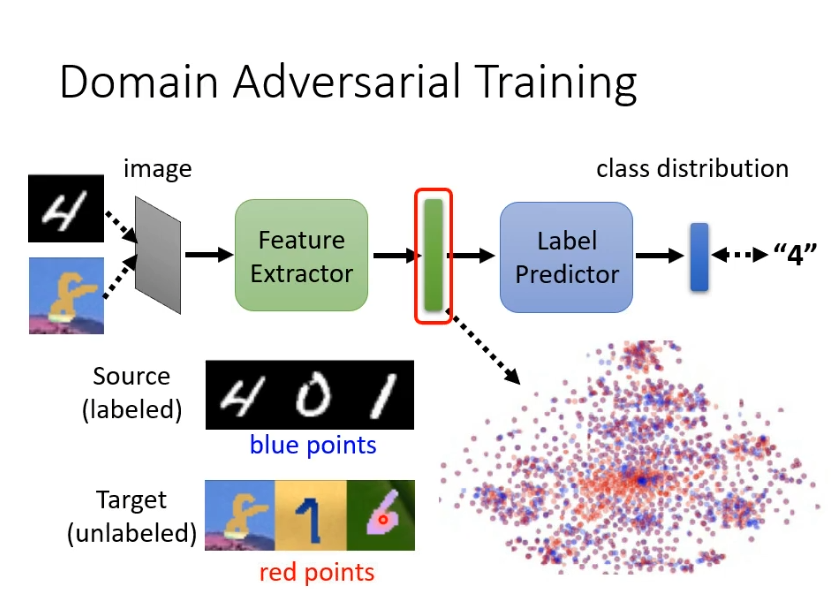
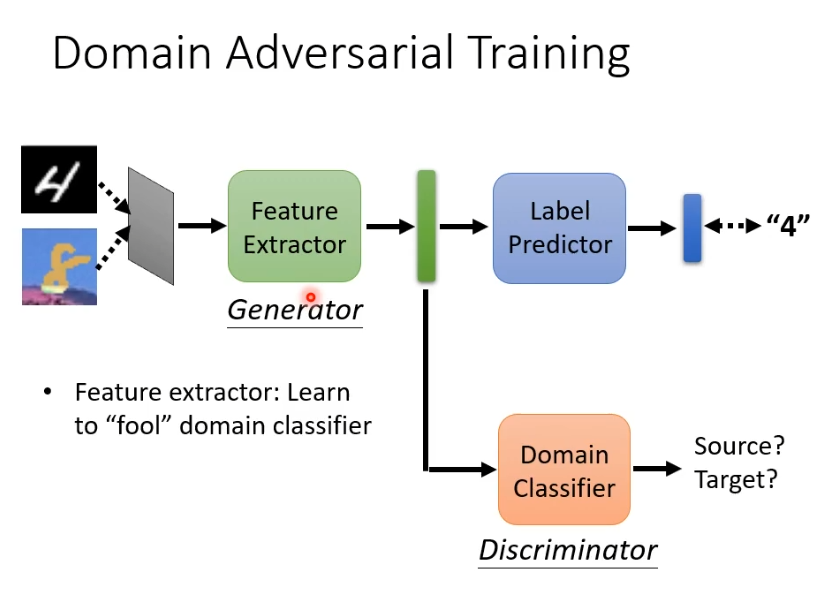
想要红色和蓝色的点分不出差异就需要domain adversarial training技术,要做的是训练一个domain的分类器,即一个二元分类器,判断输入的向量来自于source domain还是target domain。feature extractor的训练目标就是去骗过这个domain的分类器。
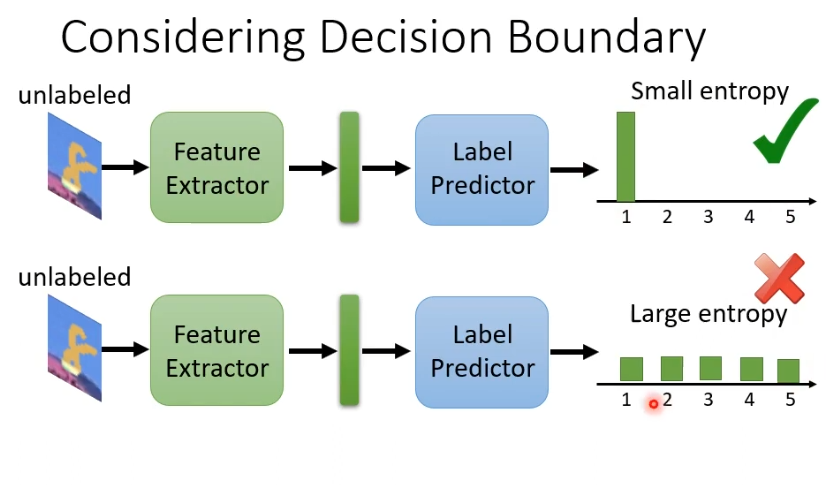
但是这样的方法存在一点问题,我们训练的目标是蓝色与红色的点分布接近,在下图中的两种情况,更希望右侧的情况发生,那么我们需要让红色的点远离分界线。
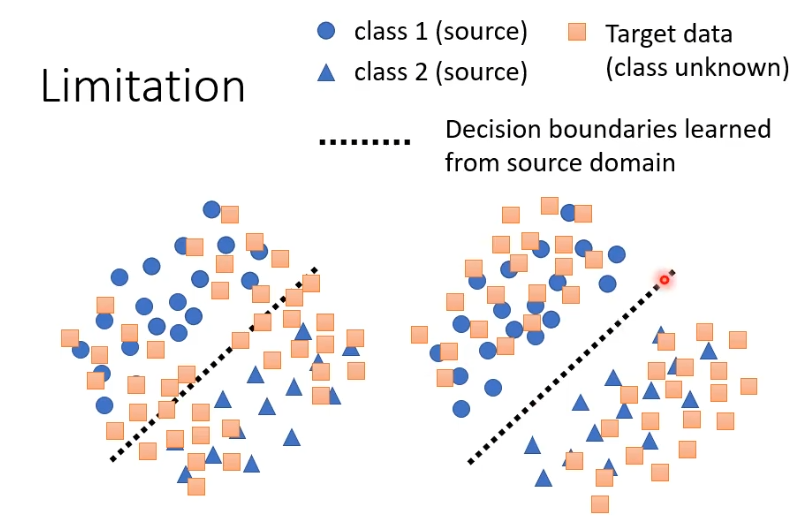
举例来说,一个简单的做法是一张未标注的图片虽然我不知道它属于哪个类别,但是希望它离分界线越远越好。如果输出的结果特别集中,就离分界线远,输出结果每个类别都非常接近,就离分界线近。