论文题目:Super-Pixel Guided Low-Light Images Enhancement with Features Restoration(超像素引导低光图像增强与特征恢复)
期刊:Sensor
摘要:弱光图像的处理是图像处理领域的一个难题。成熟的弱光增强技术不仅有利于人类的视觉感知,而且为后续的目标检测、图像分类等高级任务奠定坚实的基础。为了平衡图像的视觉效果和后续任务的贡献,本文提出利用浅卷积神经网络(cnn)作为先验图像处理,恢复必要的图像特征信息;然后对图像进行超像素分割,得到颜色和亮度相近的图像区域,最后利用细心神经过程(attention Neural Processes, ANPs)网络在每个超像素上寻找其局部增强函数,进一步还原特征和细节。通过对合成的弱光图像和真实的弱光图像进行大量实验,我们的算法在峰值信噪比(PSNR)、结构相似度(SSIM)和自然图像质量评估器(NIQE)上的实验结果分别达到23.402、0.920和2.2490。通过对图像尺度不变特征变换(ScaleInvariant Feature Transform, SIFT)特征检测和后续目标检测的实验表明,我们的方法在视觉效果和图像特征方面都取得了很好的效果。
超像素引导的特征恢复的低照度图像增强
引言
你有没有在夜晚或暗光环境下拍照,结果照片一片漆黑,看不清任何细节?或者拍出的照片虽然能看清,但后续用于人脸识别或物体检测时效果很差?这就是低光图像增强技术要解决的问题。
今天给大家介绍一篇发表在Sensors 2022上的论文《Super-Pixel Guided Low-Light Images Enhancement with Features Restoration》,它提出了一种创新的方法,不仅能让暗光照片变得明亮好看,还能保留和恢复图像的关键特征信息,为后续的AI视觉任务(如目标检测)打下坚实基础。
注意:由于图像很大,在博客中因为被压缩处理过所以看起来比较模糊。
一、问题的由来:为什么低光图像增强这么难?
1.1 视觉vs特征:鱼和熊掌难兼得
想象一下,你在昏暗的房间里拍了一张照片。现有的图像增强算法可能会做两件事:
- 让照片看起来很亮、很漂亮(视觉效果好)
- 但是丢失了很多细节信息(特征丢失)
为什么特征重要?
从论文的Figure 1可以看到,研究者用SIFT(Scale-Invariant Feature Transform,尺度不变特征变换)算法提取了低光图像和明亮图像的特征点:
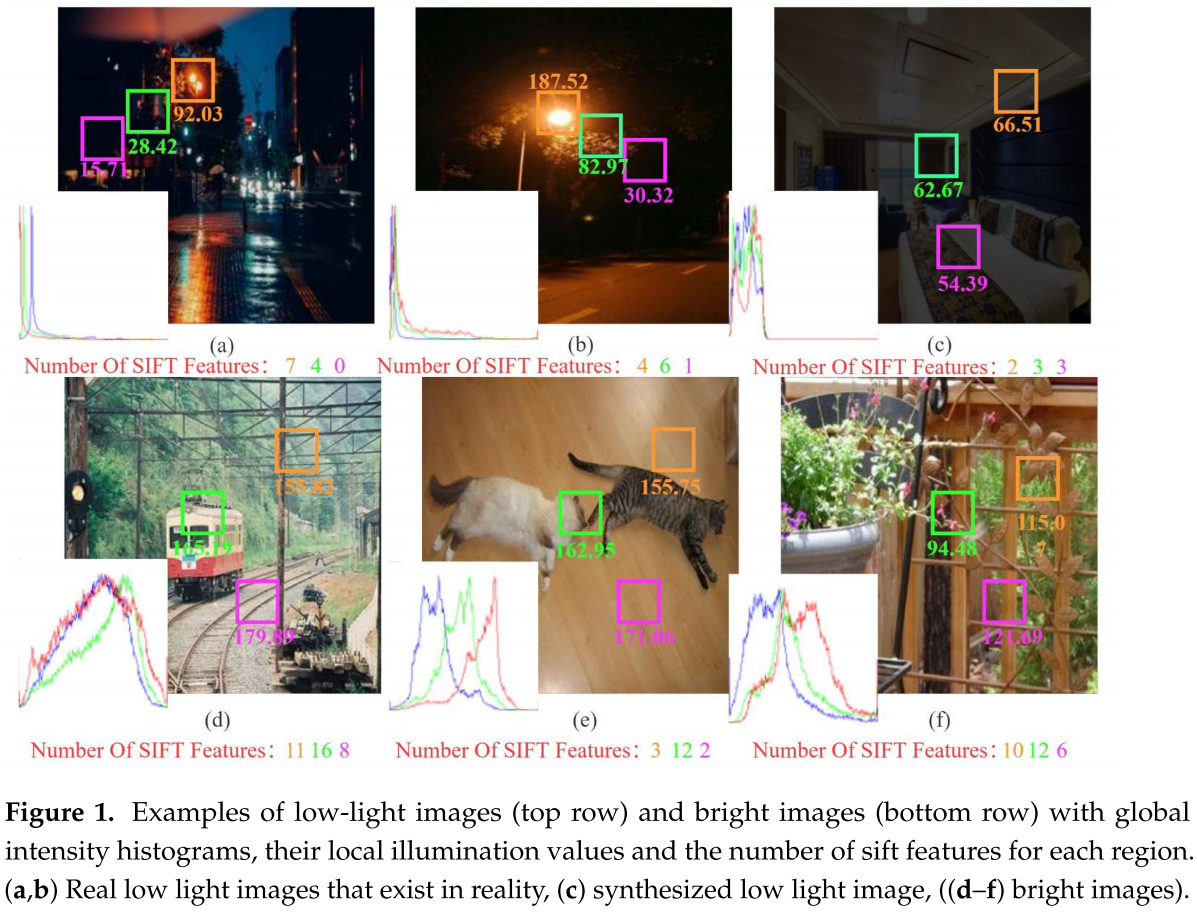
- 低光真实图像:只有7、4、0个特征点
- 明亮图像:有1116、8个特征点
特征点代表了图像的关键信息(如角点、边缘、纹理等),这些信息对于:
- 图像匹配
- 目标检测
- 场景分析
都至关重要。如果增强后的图像特征丢失,后续的AI任务就会大打折扣。
1.2 全局增强的局限性
再看Figure 1的另一个发现:
- 在低光图像中,靠近光源的区域更清晰,特征更多
- 远离光源的区域则很暗,特征很少
如果对整张图像使用相同的增强策略(全局增强),会出现什么问题?
- 过度曝光:本来就亮的区域变得更亮,细节丢失
- 仍然偏暗:暗的区域增强不够,看不清
- 忽略局部信息:不同区域需要不同的增强策略
这就是为什么我们需要局部增强方法。
二、论文的核心创新:两阶段框架
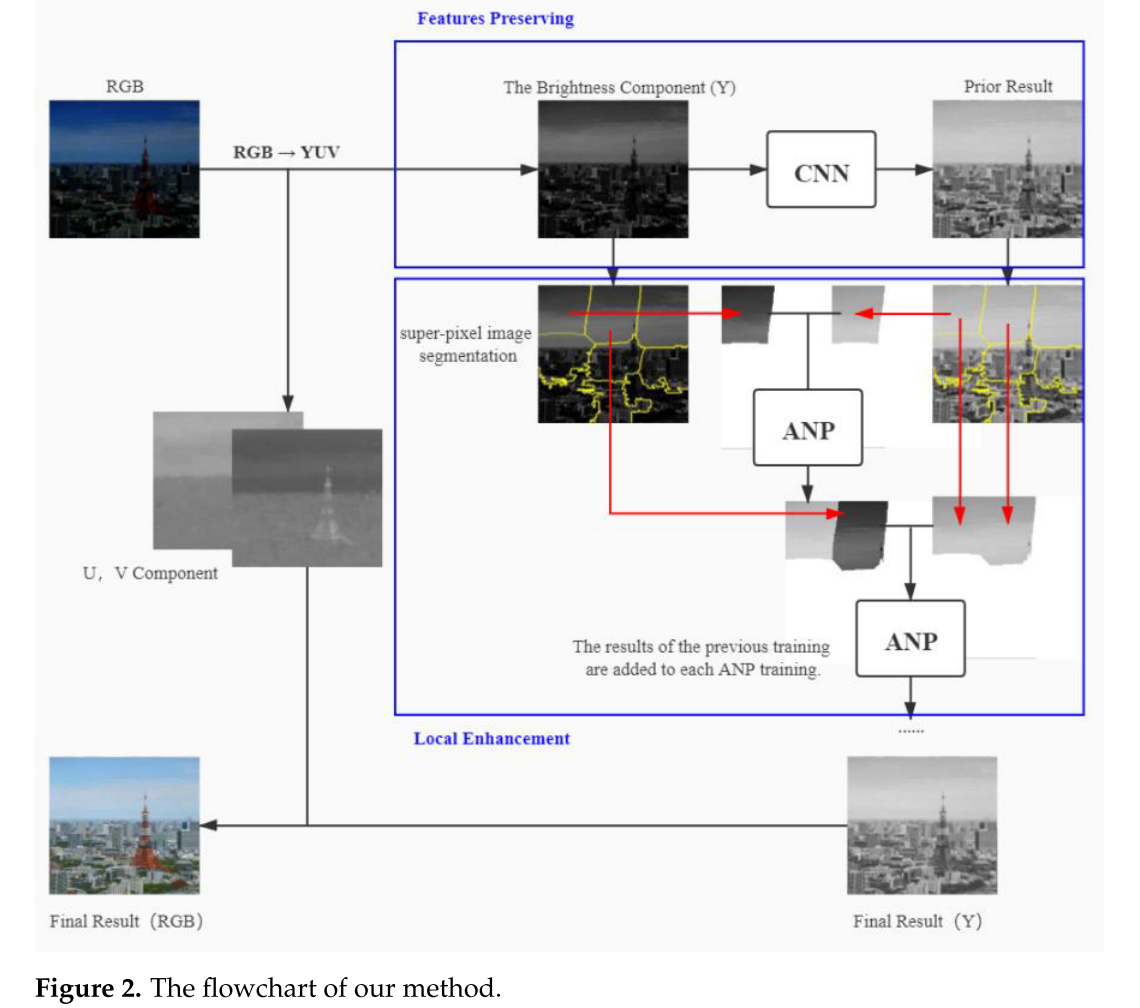
这篇论文提出了一个巧妙的两阶段框架:
第一阶段:全局初步增强(CNN)
↓
第二阶段:局部精细增强(超像素分割 + ANP)让我们逐一解析。
2.1 第一阶段:CNN特征恢复
核心思想:明亮的图像包含丰富的特征信息,如果我们能训练一个网络从低光图像恢复到明亮图像,就能间接恢复特征。
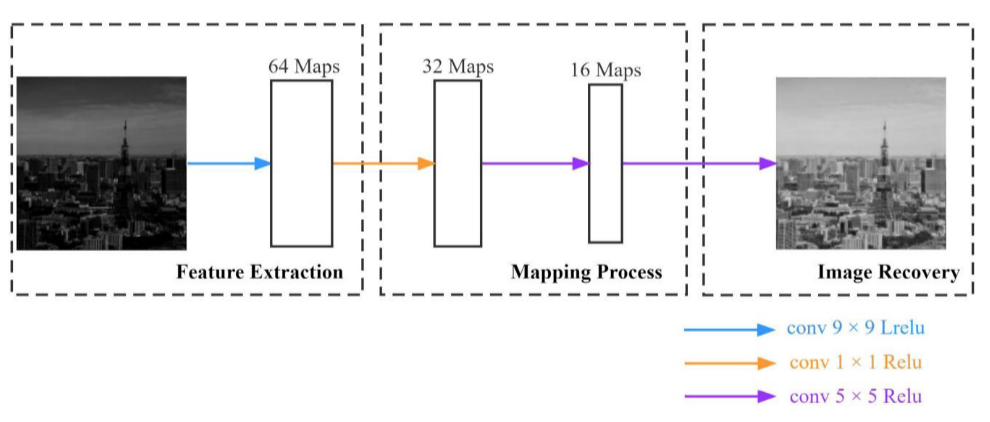
怎么训练?
-
合成训练数据:
- 从Pascal VOC数据集选择300张正常明亮图像
- 使用gamma校正公式人工"变暗":
V_out = V_in^γ - γ取值2, 4, 8, 16,生成不同暗度的图像
- 最终得到1600张训练图像

-
网络结构:
- 4层卷积神经网络
- 卷积核大小:9×9, 1×1, 5×5, 5×5
- 激活函数:ReLu + Leaky ReLu(缓解梯度消失,保留细节)
- 损失函数:MSE(均方误差),建立像素级对应关系
-
在YUV色彩空间工作:
- 只处理Y通道(亮度)
- 保持U、V通道(色度、饱和度)不变
- 避免色彩失真
效果如何?
从Table 1可以看到:
- CNN Stage1的PSNR = 22.170,SSIM = 0.902
- 已经超过了大多数传统方法
- 但还有提升空间
2.2 第二阶段:超像素引导的局部增强
这是论文的核心创新!
2.2.1 为什么用超像素分割?
超像素(Superpixel)是什么?
- 把相邻位置、相似颜色、亮度、纹理的像素组合成一个"超像素"
- 每个超像素是一个具有视觉意义的区域
好处:
- 大大降低处理复杂度(用少量超像素代替大量像素)
- 每次处理专注于特定区域,实现局部增强
- 保留图像的自然边界
技术细节:
- 使用SLIC(Simple Linear Iterative Clustering)算法
- 在CNN初步增强的图像上进行分割
- 将分割结果复制到对应的低光图像上
为什么要在CNN增强后的图像上分割?
这是一个巧妙的设计!
- 真实低光图像很暗,特征不清晰,直接分割效果不好
- CNN初步增强后,暗区特征得到恢复,分割更准确
- 这体现了两阶段的协同作用
2.2.2 ANP:注意力神经过程
什么是ANP?
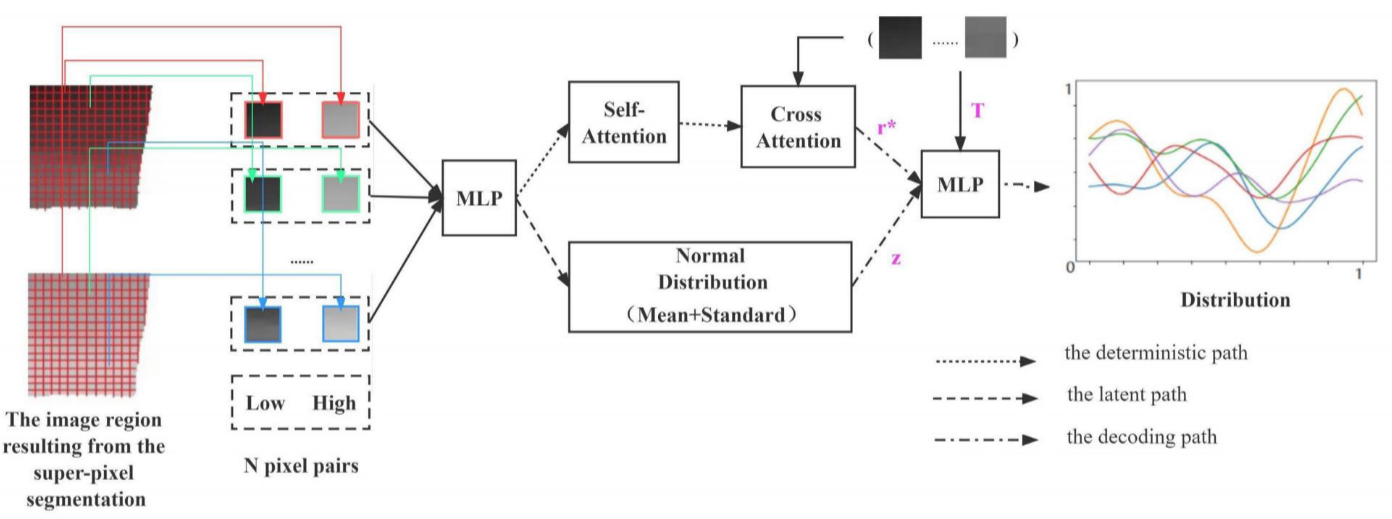
ANP(Attentive Neural Processes)是DeepMind提出的一个模型,结合了:
- 神经网络的训练效率
- 高斯过程的推理灵活性
- 注意力机制的关系建模能力
为什么选ANP而不是GP?
论文受到Liang 7使用高斯过程(GP)的启发,但:
- GP基于均匀分块,效果不理想
- ANP引入注意力机制,能更有效观察图像区域间的关系
- 从Figure 8可以看到,ANP的结果比GP更自然,噪声更少

ANP的工作原理:
ANP有三条路径(见Figure 5):
-
确定性路径(Deterministic Path):
- 输入:从初步增强图像和低光图像的相同位置随机选N个像素对
- 处理:通过MLP(多层感知机)和多头注意力机制
- 输出:数据表达r*
多头注意力的作用:
- 类似于Transformer中的注意力机制
- 让模型关注输入的子集或特定特征
- 更有效地选择图像信息进行增强
-
潜在路径(Latent Path):
- 计算数据表示的均值和标准差
- 获得正态分布表达Z
- 捕捉目标预测的边际分布相关性
-
解码路径(Decoding Path):
- 结合r*, T(目标像素序列), Z
- 预测最大后验概率
- 通过最大化ELBO(证据下界)学习参数
数学公式(简化版):
多头注意力:
MultiHead(Q, K, V) = concat(head₁, ..., headₕ)W
head_h = DotProduct(QWₕQ, KWₕK, VWₕV)其中:
- Q:给定低光强度的数值矩阵
- K:训练时提取的数据矩阵
- V:通过MLP获得的训练数据的数据表示
- H = 8:子空间数量
ELBO最大化:
log p(yT|xT, xc, yc) ≥ E_q(z|sT)[log p(yT|xT,rc, z)] - DKL(q(z|sT)||q(z|sc))2.2.3 渐进式增强策略
这是另一个巧妙的设计!
步骤:
- ANP增强第一个超像素区域
- 将结果与第二个超像素区域结合
- 一起送入ANP进行增强
- 重复直到所有区域处理完毕
好处:
- 每次ANP训练都包含前一次的结果
- 消除区域拼接时的不自然接缝
- 更强的局部特征,更自然的融合
三、实验结果
3.1 定量评估
合成低光图像
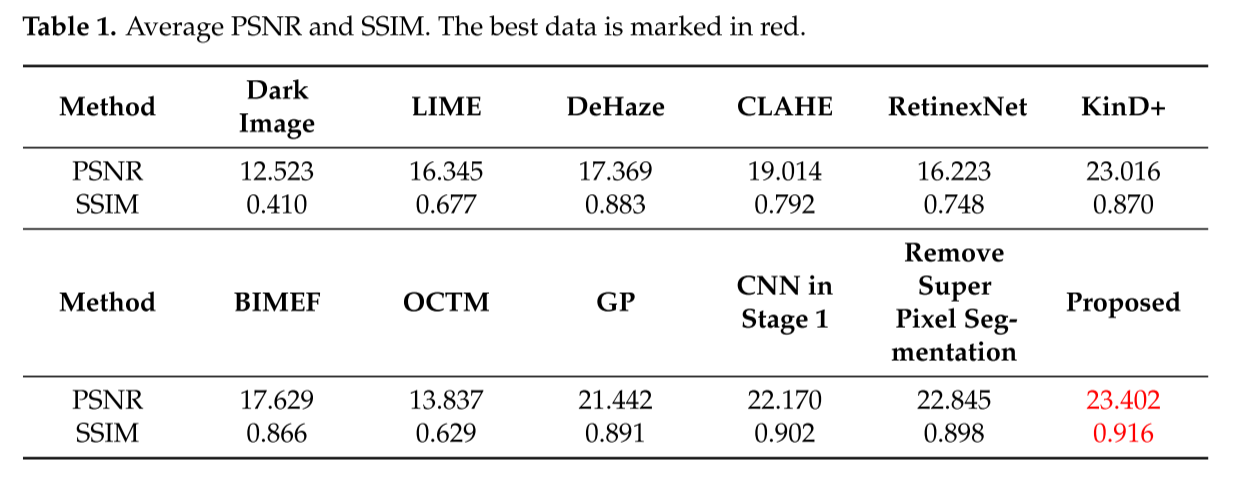
| 指标 | 本文方法 | 第二名 | 提升 |
|---|---|---|---|
| PSNR | 23.402 | 23.016 (KinD+) | +0.386 |
| SSIM | 0.916 | 0.902 (CNN Stage1) | +0.014 |
解读:
- PSNR越高越好,表示信噪比高
- SSIM范围0,1,越接近1表示结构相似性越高
- 本文方法在两个指标上都是最佳
消融实验:
- 移除超像素分割:PSNR = 22.845, SSIM = 0.898
- 完整方法:PSNR = 23.402, SSIM = 0.916
- 证明超像素分割很重要!
真实低光图像

| 方法 | NIQE ↓ |
|---|---|
| 本文方法 | 2.2490 |
| GP | 2.4387 |
| KinD+ | 2.5186 |
| BIMEF | 2.5294 |
解读:
- NIQE(自然图像质量评估器)越小越好
- 不需要参考图像,评估更客观
- 本文方法获得最低值,表示图像质量最好
3.2 特征恢复:核心优势
SIFT特征匹配结果(Figure 9):

示例1(玩具场景):
- 原始图像:51个匹配特征
- LIME:127个
- GP:184个
- CNN Stage1:149个
- 本文方法:192个 ✓
示例2(店铺场景):
- 原始图像:23个匹配特征
- LIME:66个
- GP:206个
- CNN Stage1:163个
- 本文方法:279个 ✓
特征数量统计(Figure 12):
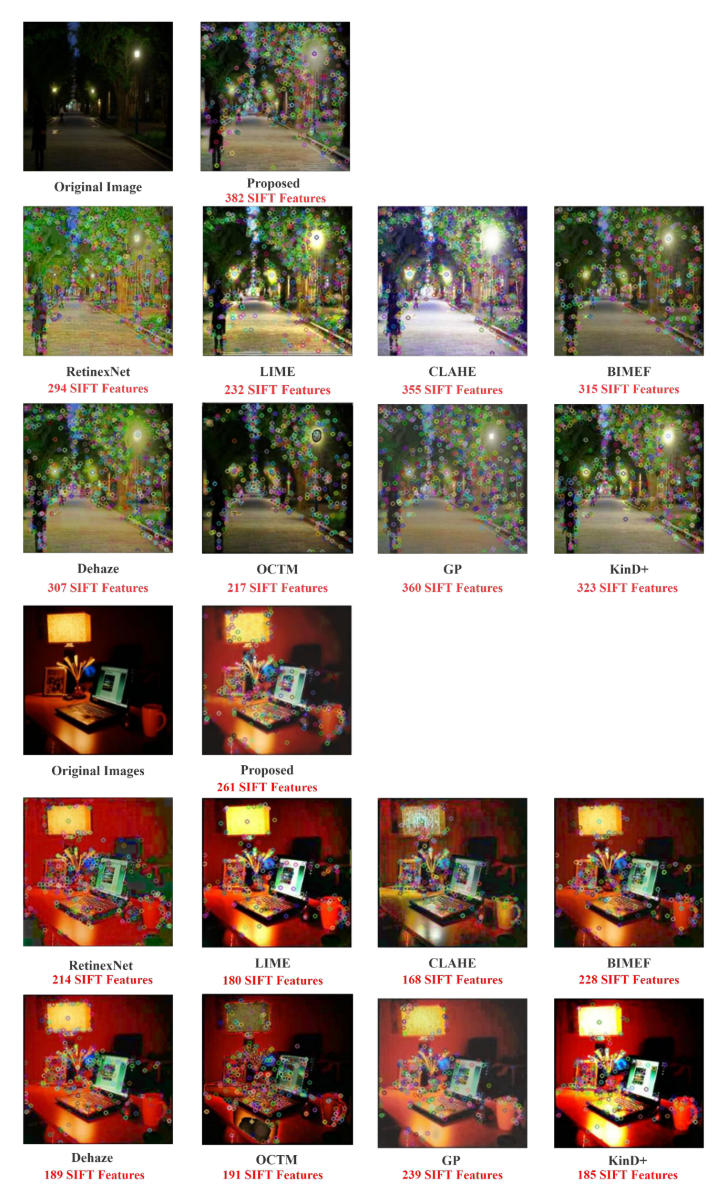
场景1(街道夜景):
- 原始:少量特征
- RetinexNet:294个
- LIME:232个
- GP:360个
- 本文方法:382个 ✓
场景2(桌面场景):
- 原始:少量特征
- RetinexNet:214个
- LIME:180个
- GP:239个
- 本文方法:261个 ✓
结论:本文方法恢复了最多的特征点,证明了特征恢复能力最强!
3.3 主观评价:最受欢迎
实验设计(Figure 10):
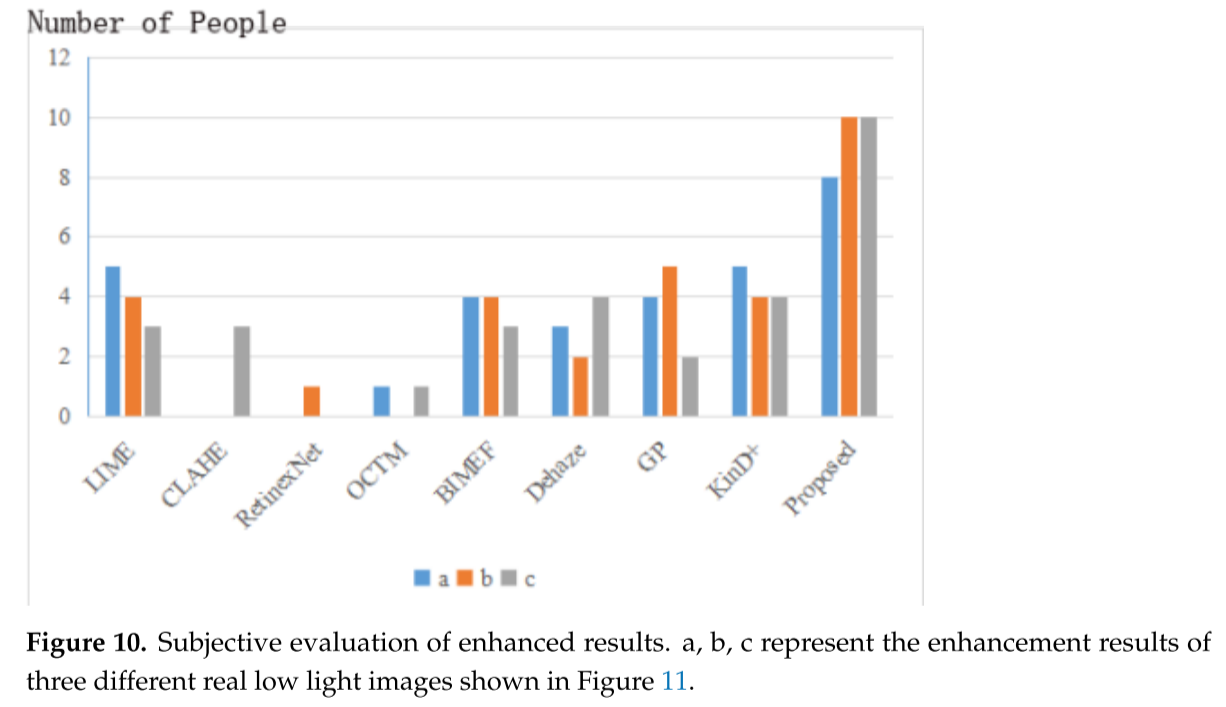
- 30个评价者
- 随机选择ExDark数据集的图像
- 选择最佳增强结果
结果统计(3张图像):
- 图像a:本文方法10票(第一)
- 图像b:本文方法8票(第一)
- 图像c:本文方法10票(第一)
用户反馈:
- LIME:过度曝光
- BIMEF和DeHaze:增强不够,仍偏暗
- KinD+:对比度过高,细节模糊
- 其他方法:颜色失真
- 本文方法:最自然,最符合视觉感知 ✓
3.4 目标检测:实际应用
使用YOLOv3进行测试(Figure 13):

示例1(夜间城市街道):
- 低光原图:检测到 Nightscape, Firework, Architecture, Poster
- LIME:检测到 Fire, Firework, Magma, Car(误判)
- RetinexNet:检测到 Cartoon, Car, Poster, Architecture(误判)
- GP:检测到 Architecture, Car, Firework, Fire(误判)
- 本文方法:检测到 Car, Architecture, Grassland, Excavator ✓
示例2(日间城市街道):
- 低光原图:检测到 City Street, Car, Sky, Nightscape
- LIME:检测到 Car, City Street, Bus, Sidewalk
- RetinexNet:检测到 Train, Car, Bridge, Ship(误判)
- GP:检测到 Bus, Car, Sidewalk, Rainstorm(误判)
- 本文方法:检测到 Bus, City Street, Street light, Parking ✓
关键发现:
- 本文方法正确识别了主要对象(汽车→巴士)
- 本文方法是唯一检测到路灯的
- 其他方法容易将噪声误识别为其他物体
- 证明了方法在实际应用中的优越性
四、深入理解:为什么这个方法有效?
4.1 两阶段协同
CNN全局增强 超像素局部增强
↓ ↓
恢复特征 强化细节
↓ ↓
为分割做准备 自然融合关键点:
- CNN的全局增强为超像素分割创造了条件
- 超像素分割为ANP的局部增强划定了区域
- ANP的渐进增强消除了区域间的接缝
4.2 注意力机制的作用
从Figure 8的对比可以看出:
- 原始图像:叶子特征清晰
- CNN:特征边界突出,但颜色过渡不自然
- GP:有噪声
- 本文方法(ANP):既保留特征,又自然
原因:
- 多头注意力让模型专注于重要特征
- 8个子空间捕捉不同层次的信息
- 权重矩阵W自适应调整各部分重要性
4.3 为什么特征恢复效果好?
理论基础:
- CNN训练使用合成数据(明亮→暗),学习了特征恢复的逆过程
- 超像素保留了图像的自然边界,避免破坏特征结构
- ANP的分布建模能够捕捉局部像素间的相关性
- 渐进式增强保证了全局一致性
实验证明:
- 从Table 1看,CNN Stage1已经恢复了部分特征(SSIM=0.902)
- 加入超像素+ANP后进一步提升(SSIM=0.916)
- 消融实验证明每个模块都不可或缺
五、局限性与未来工作
5.1 主要局限
计算时间:
- 当前:约2分钟/图像
- 其他方法:秒级或毫秒级
- 原因:ANP渐进增强需要多次迭代
颜色鲜明度:
- 颜色不够锐利
- 但视觉效果更自然(这是trade-off)
5.2 未来方向
论文提到的改进方向:
- 优化ANP结构:减少计算复杂度
- 端到端架构:将两阶段整合为一个统一网络
- 智能优化算法:探索如何在保持效果的同时降低时间复杂度
- 更大规模数据集:提升泛化能力
六、实用价值与应用场景
这个方法特别适用于:
6.1 安防监控
- 夜间视频增强
- 保留人脸、车牌等关键特征
- 提高目标检测准确率
6.2 自动驾驶
- 低光环境下的场景理解
- 行人、车辆、交通标志检测
- 特征恢复有助于路径规划
6.3 医学影像
- 低剂量X光片增强
- 保留病灶特征
- 辅助诊断
6.4 手机摄影
- 夜间模式优化
- 既美观又保留细节
- 提升照片质量
七、总结:平衡艺术与科学
这篇论文的核心贡献是:在视觉美观和特征恢复之间找到了平衡。
三个关键数字:
- PSNR: 23.402 (最高)
- SSIM: 0.916 (最高)
- NIQE: 2.2490 (最低=最好)
三个技术创新:
- CNN特征恢复
- 超像素引导
- ANP局部增强
三个实验验证:
- 定量指标最优
- 特征恢复最多
- 实际应用最佳
虽然计算时间较长是个问题,但对于需要高质量结果和特征保留的应用场景(如安防、医疗),这个trade-off是值得的。
随着硬件性能提升和算法优化,相信这类方法会在未来得到更广泛的应用!
希望这篇博客帮助你理解了这个巧妙的低光图像增强方法!如果你在实际应用中遇到低光图像处理的挑战,不妨试试这个思路:先全局恢复特征,再局部精细增强。
有任何问题欢迎讨论!