原文:The best RAG's technique yet? Anthropic's Contextual Retrieval and Hybrid Search
作者:Lan Chu
小声 BB
本文在翻译过程中确保意思传达准确的前提下,会加入很多本人的个人解释和一些知识补充(使用引用块&&括号标注) ,像这样
(我是一个平平无奇的知识补充块)
🎊如果觉得文章内容有用,交个朋友,点个赞再走~ 🎊
文章在原地址发布的时间是 24 年的 10 月份,所以并不是最新的资讯。文章中出现很多技术名词译者也不知道是什么东西,但是能通过 ai 工具去学习一个大概,有必要会做一个知识链接或者简单补充。
前置知识补充,理解 TF-IDF算法和 BM25 算法: # RAG优化: Retrieval --- BM25算法
正文
如何将上下文 BM25 与上下文嵌入相结合,从而大幅提升你的 RAG 系统。
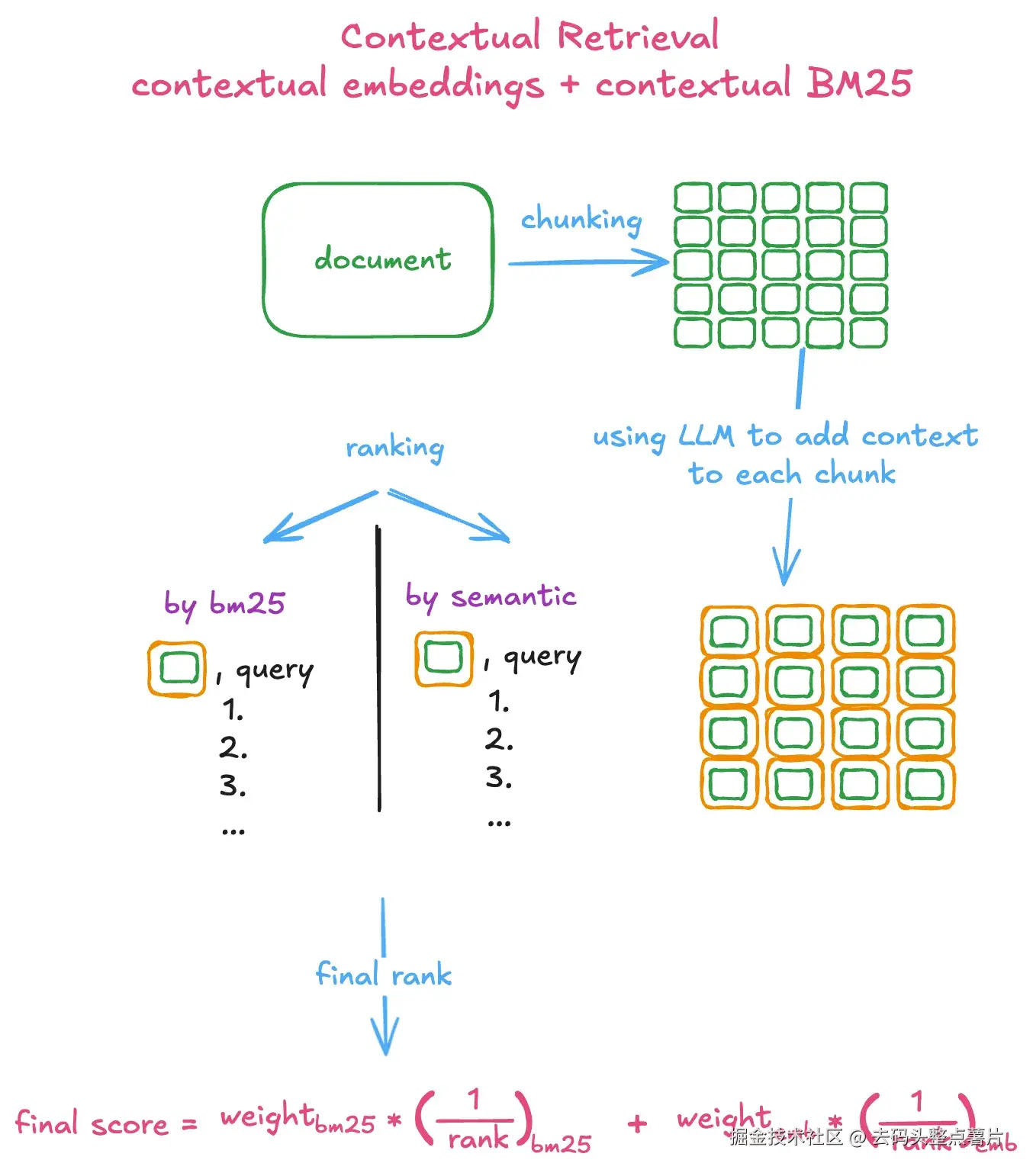 图 1:使用上下文嵌入与上下文 BM25 的混合搜索示意图(Image by author)
图 1:使用上下文嵌入与上下文 BM25 的混合搜索示意图(Image by author)
RAG-老瓶装新酒
RAG(检索增强生成)似乎是当下最热门的话题,这也不难理解。它通过让大语言模型(例如 Claude 3.5)访问外部知识源,为用户查询提供额外的上下文,从而减少幻觉现象。此外,它还被设计用来克服语言模型的上下文长度限制。 但如果我们简单点看,其实它并没有什么特别之处。
想问大模型"奥巴马的生日是什么时候"?那为什么不先找到奥巴马的维基百科页面(检索),把它加进提示词中(增强),然后让模型回答问题(生成)?就这样!我们就构建了第一个 RAG 系统。
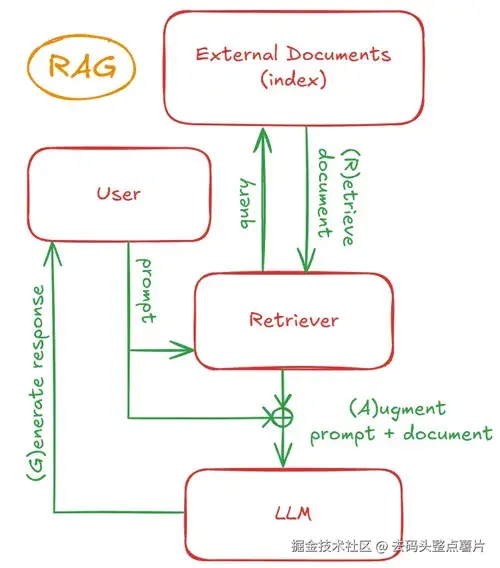
从本质上讲,一个 RAG 系统有两个核心组成部分:
- 检索器(Retriever) :从外部文档源中检索信息;
- 生成器(Generator) :利用检索到的信息生成回答。
随着 RAG 的流行,人们似乎常常把它等同于基于语义搜索或向量嵌入(embeddings)构建索引的系统。
然而,检索并不仅仅是语义搜索或使用嵌入 ,RAG 也不是发明这一概念的技术。信息检索(Information Retrieval)其实已经有上百年的历史了。早期我们是如何检索相关文档的?没错,就是老朋友 BM25。它简单、快速且高效。像 BM25 这样的基于词项的检索方法,也成功支撑了许多搜索引擎的核心能力。
尽管 RAG 在减少幻觉方面表现出潜力,但它也存在挑战。传统 RAG 系统的一个主要问题是:当文档被切分成更小的块进行检索时,上下文可能会丢失 。这时,Anthropic 提出了一个简单而强大的概念------ "上下文检索(Contextual Retrieval)" ,为在 RAG 框架中保持更广泛的语境提供了解决方案。
上下文检索
传统的 RAG 通常会将文档拆分成较小的片段以便于高效检索,但这种方式可能导致上下文丢失。
Anthropic 在最近的论文中提出了一个新概念------ "上下文嵌入(Contextual Embedding)" 。它通过在对每个片段进行嵌入前,先为其添加相关上下文,从而解决了上下文缺失的问题。
你可以利用 大语言模型(LLM)来实现上下文检索。具体做法是:为 LLM 设计一个提示词(prompt),让模型基于整篇文档,为每个片段生成简洁的、与该片段相关的上下文信息,从而为每个片段补充必要的语境。
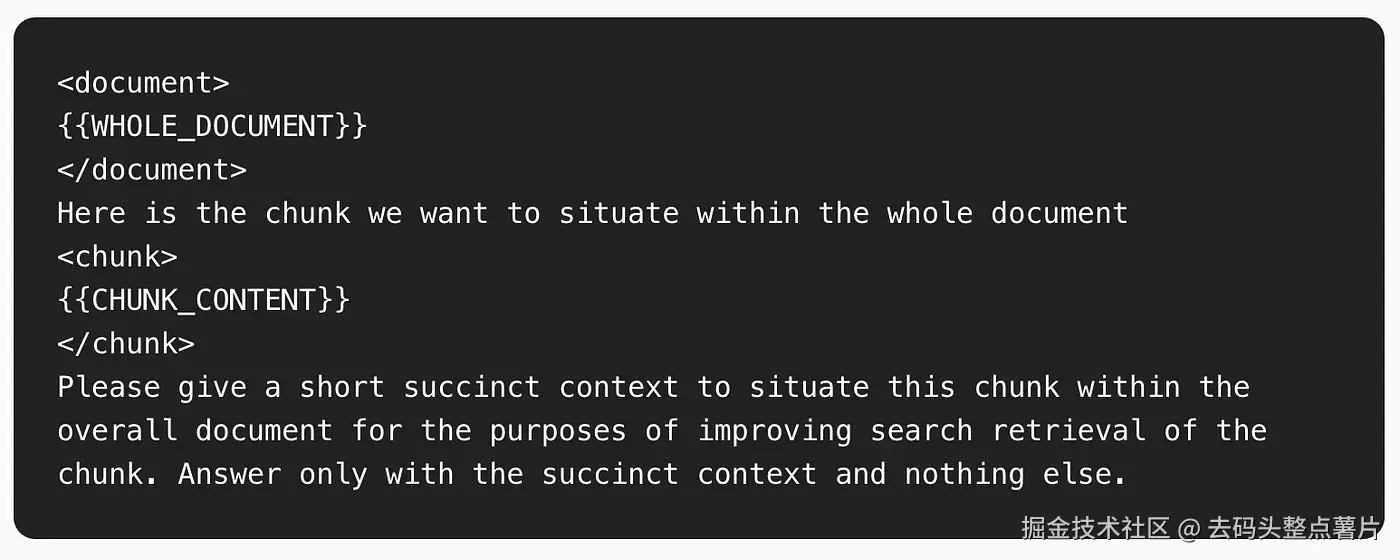 示例:通过添加更多上下文,一个文本片段(chunk)如何被转换。
示例:通过添加更多上下文,一个文本片段(chunk)如何被转换。
举个例子,假设查询与某家公司季度收入增长有关。一个相关片段可能是:
"该公司本季度收入较上一季度增长了 3%。"
这个片段虽然包含增长百分比,但缺少诸如公司名称或时间周期等关键信息。这种上下文缺失会导致检索结果不准确。
通过将整篇文档和每个片段一并发送给 LLM,我们可以得到一个"上下文化的片段(contextualized_chunk) ",例如:
 展示一个文本片段(chunk)在添加上下文后是如何被转换的。
展示一个文本片段(chunk)在添加上下文后是如何被转换的。
"在 2024 年第二季度,Apple 公司收入较第一季度增长了 3%。"
然后再将这个 contextualized_chunk 送入嵌入模型(embedding model)生成向量嵌入,从而显著提升检索的准确性。
混合搜索方法(Hybrid Search Approach)
虽然"上下文嵌入(Contextual Embeddings)"已被证明能改进传统语义搜索式的 RAG,但如果再结合 BM25,可以获得更优的结果。
相同的片段级上下文(chunk-specific context)也可以用于 BM25 搜索,从而进一步提升检索性能。
Okapi BM25
BM25 是一种改进版的文本检索算法,用于克服传统 TF-IDF 的一些缺陷,主要涉及两个问题:词频饱和(Term Saturation) 与 文档长度(Document Length) 。
🧩 1. 词频饱和与边际收益递减(Term Saturation and Diminishing Return)
假设一篇文档中出现了 100 次 "computer" 这个词,它真的比另一篇出现 50 次的文档更相关两倍吗?
显然不是。当一个词在文档中出现足够多次时,我们几乎可以确定这篇文档与该词高度相关,继续增加出现次数并不会显著提升相关性。
因此,我们希望在词频过高时,能控制其贡献度。
BM25 通过引入参数 k1 来控制这种"饱和曲线"的形状。
-
当 k1 较小时,词频的增长很快趋于饱和;
-
当 k1 较大时,词频对得分的影响更线性。
可通过调节 k1 的值来找到最优平衡点,使得当词频增加到一定程度后,BM25 得分趋于饱和,不再显著提升。
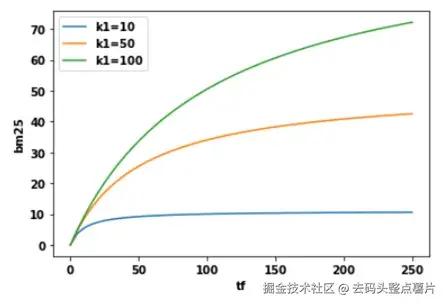
使用参数 k1 展示 TF 与 BM25 的饱和曲线。
📏 2. 文档长度(Document Length)
TF-IDF 通常忽略文档长度的影响。
例如:
-
如果一篇很短的文档中出现一次 "computer",那可能已经很有意义;
-
但如果一篇很长的文档只出现一次 "computer",那很可能这篇文档并不是讲"计算机"的。
因此,我们希望奖励短文档 的匹配,惩罚长文档。
但也不能惩罚过度,因为有些长文档确实包含大量有用的信息。
BM25 为此引入参数 b,用于平衡文档长度的影响:
-
b 值越高 → 对长文档的惩罚越强;
-
b 值越低 → 惩罚减弱,甚至偏向奖励长文档。
BM25 会以语料库的平均文档长度作为参考:
- 比平均长度更长的文档会被适度惩罚;
- 比平均长度更短的文档则获得一定加分。
通过同时考虑 词频饱和(k1) 和 文档长度平衡(b) ,BM25 在信息检索中能提供比 TF-IDF 更稳健、更符合实际语义的结果。
而将它与上下文嵌入结合的混合搜索(Hybrid Search),则能兼顾 语义理解 与 精确匹配,在 RAG 系统中表现尤为出色。
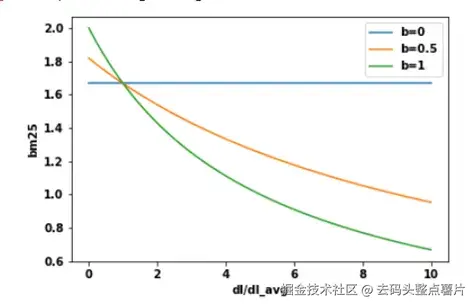
使用参数 k1 展示 TF 与 BM25 的饱和曲线
虽然 BM25 是一种强大的基于词项的检索方法,但它无法捕捉文档的语义信息 ,因此可能会错过一些相关结果。这正是 基于嵌入的检索(embedding-based retrieval) 发挥作用的地方。
基于嵌入的检索(Dense Retrieval)
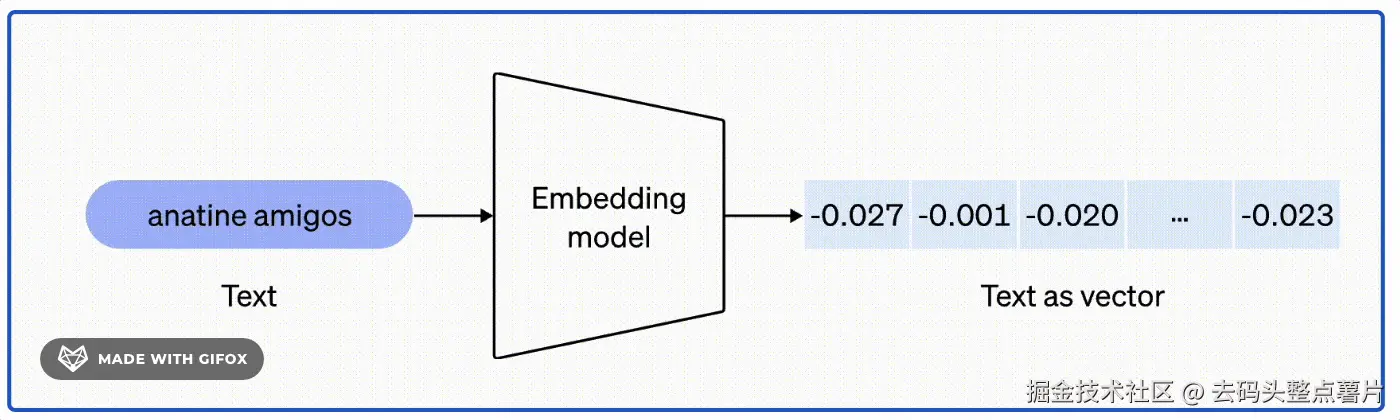
密集检索技术(Dense Retrieval)会将文本转换为向量嵌入(embeddings) ------这其实就是用一组数字来表示文本(或图像、音频等)。
一个向量嵌入(embeddings)通常是一个高维向量,旨在保留原始数据的语义特征。
在搜索阶段,查询(query)同样会被转换为向量表示,然后与文档(或片段)的向量进行比较,通过计算这些向量之间的相似度来找到最接近的结果。
 余弦相似度是密集检索中最常用的度量方法,它通过向量夹角的余弦值来衡量相似程度。
余弦相似度是密集检索中最常用的度量方法,它通过向量夹角的余弦值来衡量相似程度。
-
角度越小(余弦值越大) → 表示语义越接近;
-
角度越大(余弦值越小) → 表示语义差异更大。
例如:
"The cat sits on a mat"(猫坐在垫子上)
与
"The dog plays on the grass"(狗在草地上玩耍)
的语义相似度要高于
"AI research is super fun"(AI 研究很有趣),
因为前两句共享更多语义元素。
在实际应用中,向量搜索通常通过**最近邻搜索(Nearest Neighbor Search)**来实现。
给定一个查询(query),目标是找到与之最相似的 k 个向量。
典型做法是使用 k-最近邻算法(k-NN) :
- 计算查询向量与所有文档向量之间的相似度(常用余弦相似度);
- 按相似度得分对所有向量排序;
- 选择得分最高的前 k 个向量作为检索结果。
混合搜索:上下文 BM25 + 上下文嵌入(Hybrid Search: Contextual BM25 and Contextual Embeddings)
Anthropic 采用了一种 混合搜索策略(Hybrid Search) ,将
-
上下文嵌入检索(Contextual Embedding Search)****
与
-
上下文 BM25 检索(Contextual BM25 Search)****
的结果进行融合。
两种检索的结果会通过一种称为 倒数排名融合(Reciprocal Rank Fusion, RRF) 的方法进行合并,以生成最终的排名得分。
这种融合方式兼顾了 BM25 的词项精确匹配能力 与 嵌入模型的语义理解能力,从而在 RAG 系统中实现更高的检索准确率与更稳定的语义相关性。
使用上下文嵌入(Contextual Embeddings)与上下文 BM25(Contextual BM25)的混合搜索示意图。最终的相关性得分按图中方式计算
这种混合搜索方法(Hybrid Search)的有效性,还取决于在 倒数排名融合(Reciprocal Rank Fusion, RRF) 过程中,语义搜索与 BM25 搜索结果之间的权重分配。
这些相对权重让你能够控制两种检索方式对最终排序结果的影响程度。
如果你为语义搜索设置更高的权重,而为 BM25 设置较低的权重,那么在语义搜索中表现更好的片段(chunk)将在最终结果中获得更高排名。
例如:
若将 BM25 的权重设为 0.2 ,而 嵌入搜索(embedding)设为 0.8,
那么在嵌入搜索中排名 第 20 位 的项,其总得分与在 BM25 中排名 第 5 位 的项大致相当。
此外,那些在 BM25 搜索 中也表现良好的片段,还会获得额外加权提升。
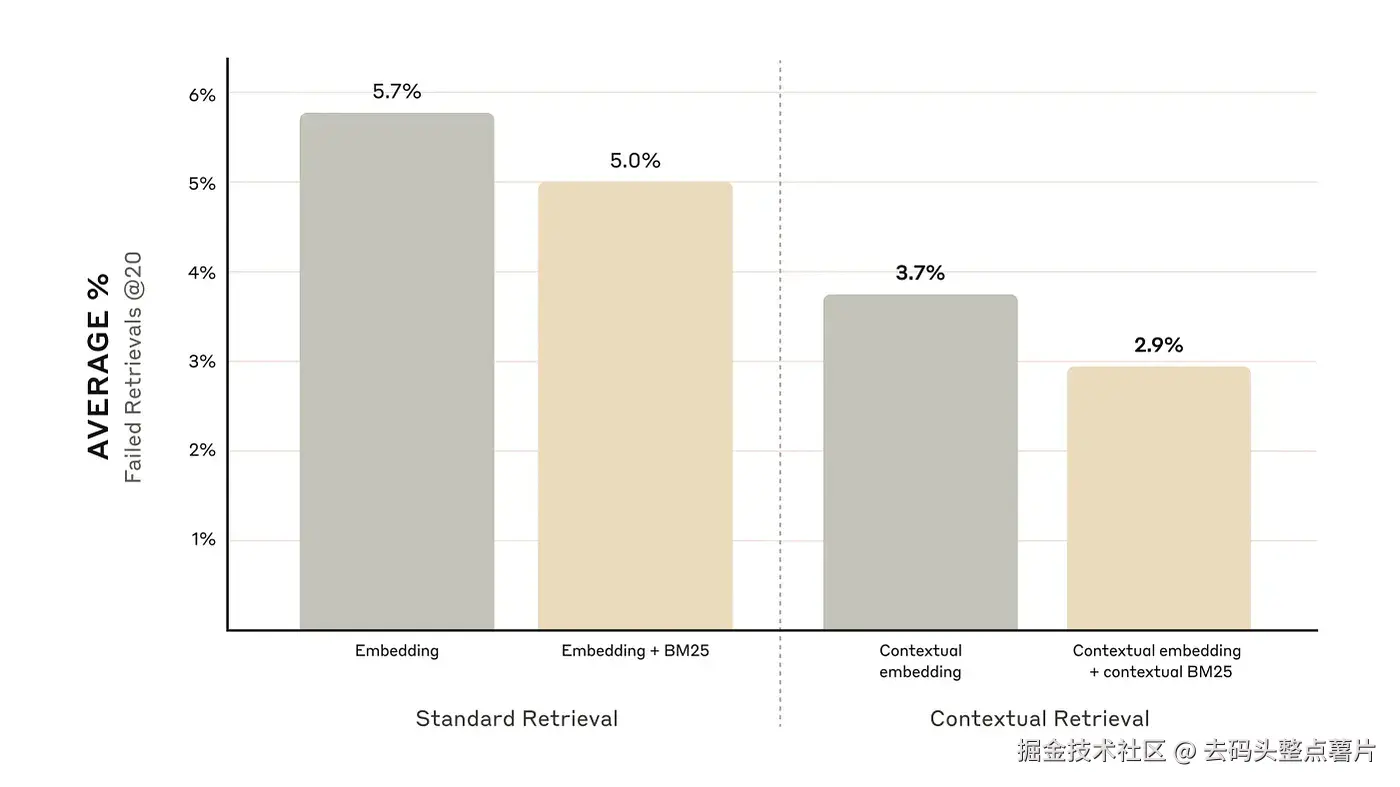
Anthropic 的实验表明,将 上下文嵌入(Contextual Embeddings) 与 上下文 BM25(Contextual BM25) 结合后,
Top-20 片段检索失败率降低了 49%(从 5.7% 降至 2.9%) 。
## 🧠 RAG 评估(RAG Evaluation)
尽管 RAG 功能强大,但如果使用不当,也可能**"反噬"**你。
无论你的 LLM(大语言模型) 有多优秀,如果检索效果不好、无法找到相关片段,那就很难得到正确答案。
而且,往上下文窗口中塞入更多内容,并不一定提升结果质量。
过多的无关内容反而可能导致模型产生幻觉或遗忘关键信息(参见 "Lost in the Middle" 效应)。
这也是为什么------评估你的检索质量与评估 LLM 本身一样重要。
Ragas 是一个帮助你评估 RAG 流程效果的框架。其中两个指标(Faithfulness 和 Answer Relevance)用于评估生成质量,而接下来的两个指标用于评估检索质量。
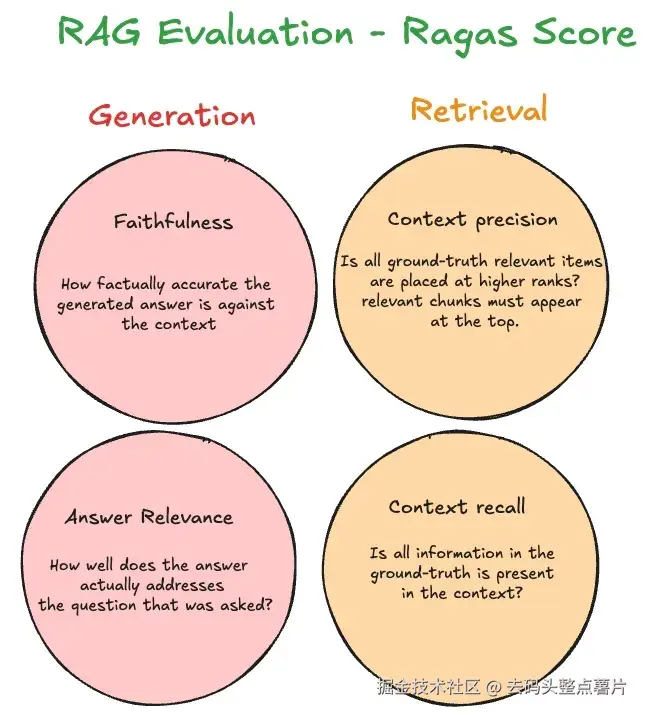
- Context precision:在所有被检索到的文档中,有多少比例与查询真正相关?
该指标评估的是检索内容中有多少真正被用于生成答案。它会比较上下文与答案之间的关系,判断答案是否确实来自检索到的内容。它实际上告诉你,添加更多上下文是否真的有助于获取正确答案。例如,如果你的模型准确率是 95%,但上下文精度只有 10%,那么增加更多上下文可能并不会提升答案质量。目标是提供最精准、最相关的内容片段。
- Context recall:在所有与查询真正相关的文档中,有多少被成功检索到?
该指标衡量回答问题所需的全部相关信息,是否都包含在检索结果中。上下文召回率较低意味着需要改进检索算法。
更多关于 RAG 评估的内容可在此处了解。
结论
结合上下文检索 + 混合搜索(BM25 + 语义嵌入)
能让 RAG 系统既"懂语义"又"找得准"。
如果想实践,可以去看 Anthropic 的 Contextual Retrieval Cookbook。
这套方法简单、实用,能显著提升你构建 RAG 系统的效果。