C语言复习八(2025.11.18)
快速排序算法
快速排序是一种高效的**分治(Divide and Conquer)**排序算法。它的核心思想是通过选取
一个基准值(pivot),将数组划分为两个子数组:一个子数组的所有元素比基准值小,
另一个子数组的所有元素比基准值大,然后递归地对子数组进行排序。
快速排序的基本步骤
- **选择基准值(**Pivot Selection):
从数组中选择一个元素作为基准值。常见的选择方式包括:
第一个或最后一个元素(简单但可能效率不高,尤其在已排序或接近排序的
数组中)。
随机选择一个元素(减少最坏情况概率)。
三数取中法(如第一个、中间、最后一个元素的中位数,提高分区均衡
性)。
- 分区(Partition):
重新排列数组,使得:
所有比基准值小的元素移到基准值的左侧。
所有比基准值大的元素移到基准值的右侧。
分区完成后,基准值处于其最终排序后的正确位置。
(注:分区是快速排序的关键步骤,常见的实现有Lomuto分区和Hoare分区方
案。)
- **递归排序(**Recursion):
对基准值左侧的子数组和右侧的子数组递归地调用快速排序。
递归的终止条件是子数组的长度为0或1(已有序)。
- **合并结果(**Combine):
由于每次分区后基准值已位于正确位置,且左右子数组通过递归排序完成,因此
无需显式合并操作,整个数组自然有序。
总结
通过一个基准值(pivot)不断拆分数组,直到子数组无法再拆分(即子数组长度为1或
0),此时整个数组就有序了。
代码:
c
#include <stdio.h>
void Qsort(int arr[],int n)
{
if(n <=1)return;
int i = 0,j = n-1;
int pivot =arr[0];
while(i < j)
{
while(i < j && arr[j] > pivot)j--;
while(i < j && arr[i] <= pivot)i++;
if(i < j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
arr[0] = arr[i];
arr[j] = pivot;
Qsort(arr,i);
Qsort(arr+i+1,n-i-1);
}
int main(int argc, char *argv[])
{
int arr[] = {23,45,56,24,78,22,19};
int n = sizeof(arr) /sizeof(arr[0]);
Qsort(arr,n);
for(int i = 0;i < n;i++)
{
printf("%-4d",arr[i]);
}
printf("\n");
return 0;
}数组做函数参数
定义
当使用数组作为函数的实参时,形参应该使用数组形式或者指针变量来接收。需要注意的
是:
-
这种传递方式并不是传递数组中的所有的元素数据,而是传递数组首地址,此时数组降级为指针。
-
形参接收到这个地址后,形参和实参指向同一块内存空间。
-
因此,通过形参对数组元素的修改会直接影响到实参。
这种传递方式称为"地址传递"(或"指针传递"),它与"值传递"的不同:
-
值传递:传递数据的副本,修改形参不影响实参
-
地址传递:传递数据的地址,通过形参可以修改实参。"地址传递"是逻辑上的说法,
强调 传递的是地址,而不是数据本身。数据本质上还是值传递。
当使用数组作为函数的形参时,通常需要额外传递一个参数表示数组的元素个数。这是因
为:
- 数组形参退化为指针 在函数参数传递时,数组名会退化为指向其首元素的指针(即
int arr\[\] 等价于 int *arr ),因此函数内部无法直接获取数组的实际长度。
- 防止越界访问 由于形参仅知道数组的首地址,而不知道数组的实际大小,如果不传递
元素个数,函数内部可能因错误计算或循环导致 数组下标越界(访问非法内存),引
发未定义行为(如程序崩溃、数据损坏)。
- 通用性 即使实参数组的声明长度固定(如 int a10 ),函数仍应接收元素个数参
数,因为函数可能需要处理不同长度的数组(例如动态数组或部分填充的数组)。
案例:
c
#include <stdio.h>
int main(int argc, char *argv[])
{
void fun(int arr[], int len) // 数组传参会被降级为指针,实际传递的是地址值
{
}
void main()
{
int arr[] = {11,22,33,44,55};
int len = sizeof(arr) / sizeof(arr[0]);
fun(arr,len);
}
return 0;
}但有一个例外,如果是用字符数组做形参,且实参数组中存放的是字符串数据(形参是字
符数组,实参是字符串常量)。则不用表示数组个数的形参,原因是字符串本身会添加自
动结束标志 \0 ,举例:
c
#include <stdio.h>
/**
* 定义一个函数,传递一个字符串
*/
void fun(char arr[])
{
char c;
int i = 0;
while((c = arr[i]) != '\0') // arr[i] → arr + i
{
printf("%c",c);
i++;
}
}
void main()
{
fun("hello world");
}为什么sizeof不能用于形参数组?在函数内部,sizeof(arr)返回的是指针的大小(32位系统
返回4字节,64位系统返回8字节)。
案例1
需求:
有两个数组a和b,各有5个元素,将它们对应元素逐个地相比(即a0与b
0比,a1与b1比......)。如果a数组中的元素大于b数组中的相应元素的
数目多于b数组中元素大于a数组中相应元素的数目(例如,ai>b]i]6次,
bi>ai 3次,其中i每次为不同的值),则认为a数组大于b数组,并分别统计出
两个数组相应元素大于、等于、小于的个数。
cint a[10] = {12,12,10,18,5}; int b[10] = {111,112,110,8,5};
代码:
c
#include <stdio.h>
#define LEN 5
int get_large(int x, int y)
{
int flag = 0;
if (x > y) flag = 1;
else if (x < y) flag = -1;
return flag;
}
int main(int argc,char *argv[])
{
// 定义a,b两个测试数组
int a[LEN] = {12,12,10,18,5};
int b[LEN] = {111,112,110,8,5};
int max = 0, min = 0, k = 0;
// 遍历数组,进行比较
for (int i = 0; i < LEN; i++)
{
// 同一位置两个数比较
int res = get_large(a[i], b[i]);
if (res == 1) max++;
else if (res == -1) min++;
else k++;
}
printf("max=%d,min=%d,k=%d\n", max, min, k);
return 0;
}案例2
需求:编写一个函数,用来分别求数组score_1(有5个元素)和数组score_2(有10个
元素)各元素的平均值 。
代码:
c
#include <stdio.h>
float get_avg(float scores[],int len)
{
int i;
float aver,sum = scores[0];
for(i = i; i < len;i++)
{
aver = sum /len;
return aver;
}
}
int main(int argc, char *argv[])
{
float scores1[] = {77,88,99,66,57};
float scores2[] = {67,87,98,78,67,99,88,77,77,67};
int len = sizeof(scores1) / sizeof(scores1[0]);
int len2 = sizeof(scores2) / sizeof(scores2[0]);
printf("%6.2f,%6.2f\n", get_avg(scores1, len),get_avg(scores2, len2));
return 0;
}案例3
需求:编写一个函数,实现类似strcpy的效果 。
代码:
c
#include <stdio.h>
void _strcpy(char source[], const char dest[]) {
for (int i = 0; source[i] != '\0'; i++) {
source[i] = dest[i];
}
}
int main(int argc, char *argv[]) {
char str[] = "hello world!";
printf("%s\n", str);
_strcpy(str,"hi yifan!");
printf("%s\n", str);
_strcpy(str,"娇娇");
printf("%s\n", str);
return 0;
}变量的作用域
引入问题
我们在函数设计的过程中,经常要考虑对于参数的设计,换句话说,我们需要考虑函数需
要几个参数,需要什么类型的参数,但我们并没有考虑函数是否需要提供参数,如果说函
数可以访问到已定义的数据,则就不需要提供函数形参。那么我们到底要不要提供函数形
参,取决于什么?答案就是变量的作用域(如果函数在变量的作用域范围内,则函数可以
直接访问数据,无需提供形参)
变量作用域
**概念:**变量的作用范围,也就是说变量在什么范围有效。
变量的分类
根据变量的作用域不同,变量可以分为:
全局变量
说明:定义在函数之外,也称之为外部变量或者全程变量。
作用域:从全局变量定义到本源文件结束。
初始值:整型和浮点型,默认值是0;字符型,默认值是\0;指针型,默认值NULL
举例:
c
int num1; // 全局变量,num1能被fun1、fun2、main共同访问
void fun1(){}
int num2; // 全局变量,num2能被fun2、main共同访问
void fun2(){}
void main(){}
int num3; // 全局变量,不能被任何函数访问局部变量

举例:
c
// a,b就是形式参数(局部变量)
int add(int a, int b)
{
return a + b;
}
int add2(int a, int b)
{
// z就是函数内定义的变量(局部变量)
int z = a + b;
return z;
}
int list(int arr[], int len)
{
// i就是for循环表达式1的变量(局部变量)
for(int i = 0; i < len; i++)
{
// num就是复合语句中定义的变量(局部变量)
int num = arr[i];
}
}使用全局变量的优缺点:
优点:
- 利用全局变量可以实现一个函数对外输出的多个结果数据。
- 利用全局变量可以减少函数形参的个数,从而降低内存消耗,以及因为形参传递
带来的时间消耗。
缺点:
- 全局变量在程序的整个运行期间,始终占据内存空间,会引起资源消耗。
- 过多的全局变量会引起程序的混乱,操作程序结果错误。
- 降低程序的通用性,特别是当我们进行函数移植时,不仅仅要移植函数,还要考
虑全局变量。
- 违反了"高内聚,低耦合"的程序设计原则。
总结:
我们发现弊大于利,建议尽量减少对全局变量的使用,函数之间要产生联系,仅
通过实参+形参的方式产生联系。
注意:
如果全局变量和局部变量同名,程序执行的时候,就近原则(区分作用域)
c
int a = 10; // 全局变量 全局作用域
int main()
{
int a = 20; // 局部变量 函数作用域
printf("%d\n", a); // 20 就近原则
for (int a = 0; a < 5; a++) // 局部变量 块作用域
{
printf("%d", a); // 0 1 2 3 4 就近原则
}
printf("%d\n",a); // 20 就近原则
}变量的生命周期
定义
**概念:**变量在程序运行中的存在时间(内存申请到内存释放的时间)
根据变量存在的时间不同,变量可分为静态存储方式 和动态存储方式
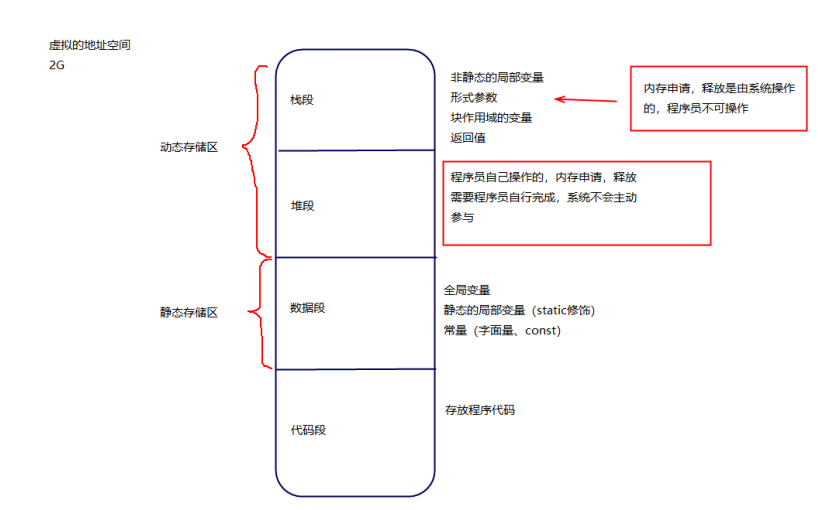
变量的存储类型
语法:
存储类型:
c
变量的完整定义格式: [存储类型] 数据类型 变量列表;- auto
auto存储类型只能修饰局部变量,被auto修饰的局部变量是存储在动态存储区(栈区
和堆区)的。auto也是局部变量默认的存储类型。
c
int main()
{
int a;
int b;
// 以下写法等价于上面写法
auto int a;
auto int b;
int a,b;
// 以下写法等价于上面写法
auto int a,b;
}- static
**修饰局部变量:**局部变量会被存储在静态存储区。局部变量的生命周期被延长。但是
作用域不发生改变,不推荐
**修饰全局变量:**全局变量的生命周期不变,但是作用域衰减,一般限制全局变量只能
在本源文件内访问,其他文件不可访问。
**修饰函数:**被static修饰的函数,只能被当前文件访问,其他引用该文件的文件是无法
访问的,有点类似于java中private
extern
外部存储类型:只能修饰全局变量,此全局变量可以被其他文件访问,相当于扩展了
全局变量的作用域。
extern修饰外部变量,往往是外部变量进行声明,声明该变量是在外部文件中定义
的。起到一个标识作用。函数同理。
demo01.c
c
#include "demo01.h"
int fun_a = 10;
int fun1(){..}demo02.c
c
#include "demo01.h"
// 声明访问的外部文件的变量
extern int fun_a;
// 声明访问的外部文件的函数
extern int fun1();
int fun2();- register
寄存器存储类型:只能修饰局部变量,用register修饰的局部变量会直接存储到CPU的
寄存器中,往往将循环变量设置为寄存器存储类型(提高读的效率)
c
for (register int i = 0; i < 10; i++)
{
...
}面试题
static****关键字的作用
- static修饰局部变量,延长其生命周期,但不影响局部变量的作用域。
- static修饰全局变量,不影响全局变量的生命周期,会限制全局变量的作用域仅
限本文件内使用(私有化);
- static修饰函数:此函数就称为内部函数,仅限本文件内调用(私有化)。 static int funa(){...}
内部函数和外部函数
内部函数:使用static修饰的函数,称作内部函数,内部函数只能在当前文件中调用。
外部函数:使用extern修饰的函数,称作外部函数,extern是默认的,可以不写(区
分编译环境),也就是说本质上我们所写的函数基本上都是外部函数,建议外部函数
在被其他文件调用的时候,在其他文件中声明的时候,加上extern关键字,主要是提
高代码的可读性。