摘要
背景
设计计算高效的网络架构是计算机视觉的持续需求
方法
将状态空间语言模型Mamba改编为具有线性时间复杂度的视觉主干网络Vmamba
核心是带有2D选择性扫描模块的可视状态空间(VSS)块的堆栈,通过四条扫描线路的遍历,SS2D弥合了一维选择性扫描的有序性质与二维视觉数据的非循序结构之间的差距,并有助于从各种来源和角度收集上下文信息,基于VSS块开发了VMamba架构,并通过一系列架构和实现增强加速他们
贡献
广泛的实验证明了VMamba在各种视觉感知任务的出色表现,凸显了与现有基准模型相比卓越的输入拓展效率
引言
背景
视觉表示学习仍然是计算机视觉领域的基础研究领域,为表示视觉数据中复杂模式,主干网络的两大类分别是CNN和ViT,ViT集成了自注意力机制,在大规模数据上通常表现出优越的学习能力,
挑战
然而自注意力的二次复杂性与标记的数量不同在涉及大空间分辨率的下游任务中施加了大量计算开销。
研究现状
人们做出了重大努力提高注意力计算效率,然而现有方法要么限制了有效感受野大小,要么在各种任务中表现明显下降,这促使开发一种既保留自注意力机制的固有优势,即全局感受野和动态加权参数。
在NLP领域的状态空间模型Mamba以成为有前途的线性复杂度的长序列建模方法,
提出新方法
基于此推出了Vmamba,这是一种视觉骨干网络,集成了SSM块以实现高效的视觉表示学习。核心算法是并行选择性扫描操作,本质上是处理一维顺序数据而设计,为解决这个问题提出了二维选择性扫描(SS2D),设置一种专为空间域遍历的四向扫描机制。SS2D通过图像patch仅通过沿其相应扫描路径计算的压缩隐藏状态获取上下文知识,从将计算复杂度从二次降至线性。
贡献
提出了VMamba,一种基于SSM的视觉骨干,具有线性时间复杂度的视觉表示学习
引入SS2D桥接一维阵列扫描和二维平面遍历,从而能够扩展选择性SSM处理视觉数据
VMamba在各种视觉任务中取得了良好的性能,并表现出对输入序列长度的显著适应性,显示计算复杂度的线性增长
方法部分
对于给定输入 I ∈ R H × W × 3 I \in \mathbb{R}^{H \times W \times 3} I∈RH×W×3
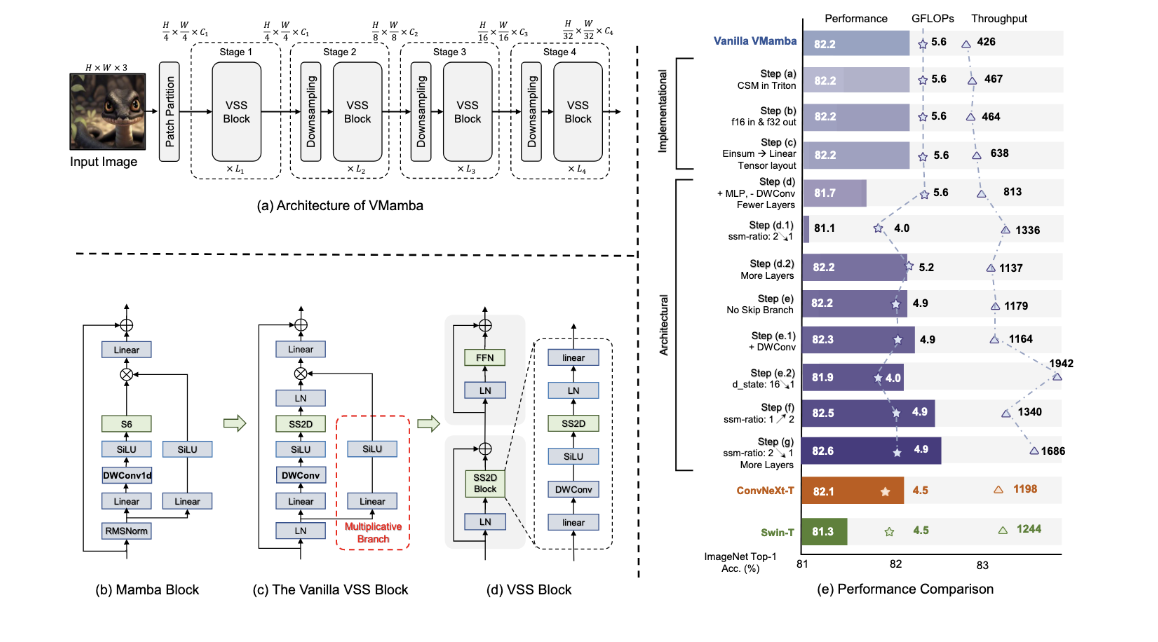
先划分成 H / 4 × W / 4 H/4 \times W/4 H/4×W/4的二维特征图,再通过包含一个下采样层(第一阶段除外)和若干个视觉状态空间(VSS)块,构建不同分辨率的分层表示。
具体来说,每个VSS块删除了乘法分支,并替换为了SS2D模块,如图d所示,改进的VSS块由一个具有两个残差模块的网络分枝组成。
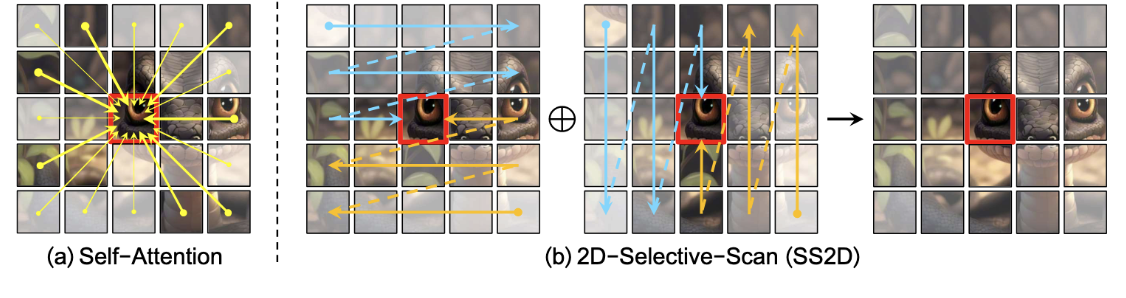
视觉数据的2D选择性扫描(SS2D)
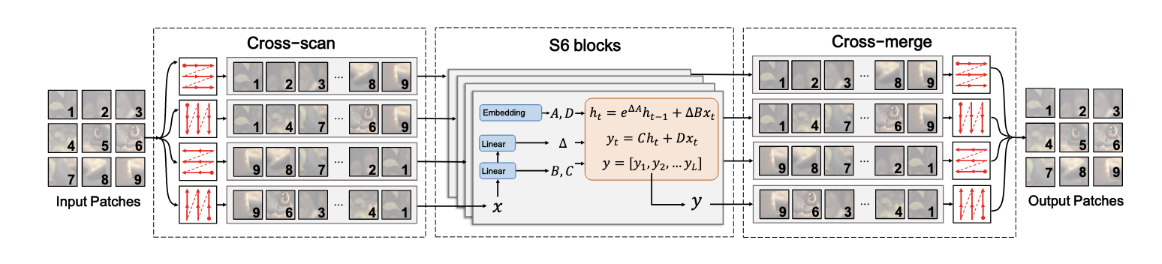
SS2D包括三个步骤,交叉扫描,选择性扫描和交叉合并
交叉扫描:将输入patch沿着四个不同的遍历路径展开序列
选择性扫描:通过选择性扫描并行处理每个patch序列
交叉合并:将生成的序列重塑并合并形成输出映射
SS2D允许图像中每个像素跨不同方向整合其他来自其他所有像素的信息,有助于在2D空间建立全局感受野
实验
图像分类
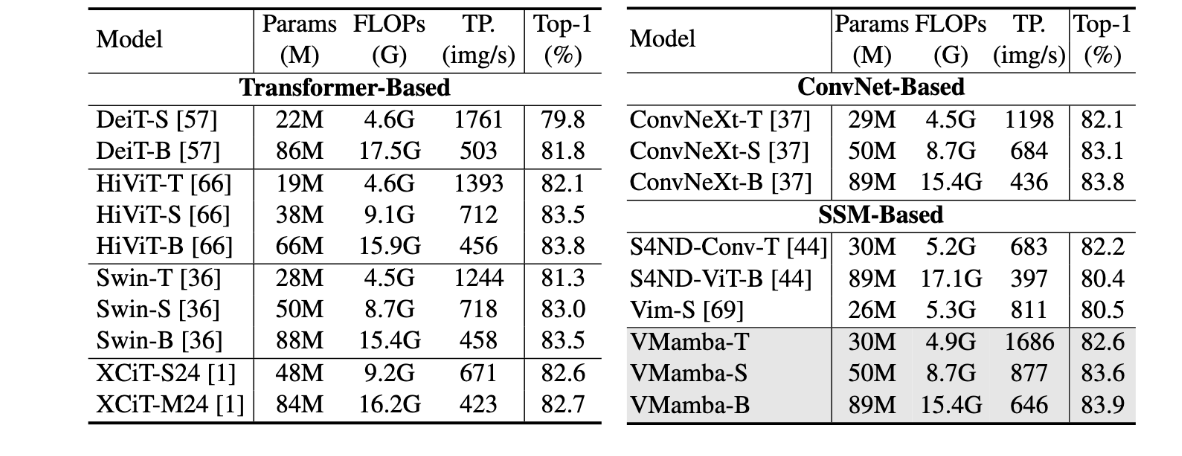
在ImageNet-1K上评估了图像分类的性能
在FLOP中,VMamba-T达到了82.6%的Top-1,优于 DeiT-S 2.8% 和 1.3% Swin-T。值得注意的是,VMamba 在小型和基本规模上都保持了其性能优势。例如,VMamba-B 的 top-1 精度超过 83.9% DeiT-B 2.1% ,超越 0.4% Swin-B。
在计算效率上,Vmamba-T实现了 1,686 张图像/秒的吞吐量,这要么优于最先进的方法,要么可与最先进的方法相媲美。 VMamba-S 和 VMamba-B 延续了这一优势,分别实现 877 了映像吞吐量和 646 映像吞吐量。与基于SSM的模型相比,VMamba-T 的吞吐量 1.47× 高于 S4ND-Conv-T 和 1.08× Vim-S,同时分别保持了明显的性能领先于 0.4% 2.1% 这些模型。
下游任务
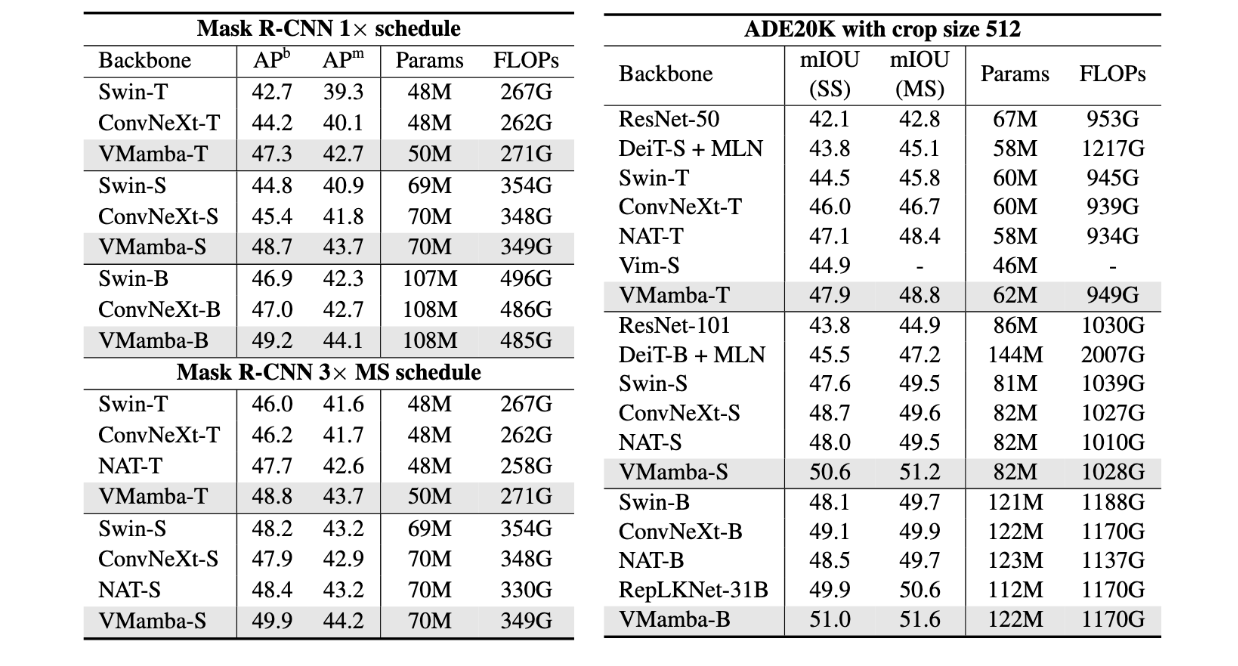
在目标检测上,通过12个epoch的微调后,VMamba-T/S/B 的目标检测 mAP 分别优于 47.3%/48.7%/49.2% mAP 的 4.6%/3.9%/2.3% Swin-T/S/B 和 mAP 的 3.1%/3.3%/2.2% ConvNeXt-T/S/B。VMamba-T/S/B 实现的实例分割 mAP 分别超过 3.4%/2.8%/ Swin-T/S/B 1.8 % mAP 和 ConvNeXt-T/S/B 2.6%/1.9%/ 1.4 % mAP。此外,VMamba 的优势在使用多尺度训练的 36 个 epoch 微调计划中得以延续,凸显了其在需要密集预测的下游任务中的强大潜力。
在语义分割上,VMamba-T 在单尺度 (SS) 设置中实现了 3.4% 高于 Swin-T 和 1.9% ConvNeXt-T 的 mIoU,并且在多尺度 (MS) 输入中优势仍然存在。对于小型和基础级别的模型,VMamba-S/B 在 SS 设置中优于 2.6% NAT-S 2.5% /B 25 / mIoU,在 MS 设置中优于 1.7% / 1.9% mIoU。
结论
方法
提出了VMmaba,这是一种使用状态空间模型构建的高效视觉骨干模型,将选择性SSM的优势集成到了视觉数据处理中,通过SS2D模块弥合了有序1D扫描和非顺序2D遍历之间的差距。
效果
在线性时间复杂度下VMamba在大分辨率输入的下游任务中有优势
局限
现有预训练方法与VMamba等基于SSM架构的兼容性有待探索
尚未大规模探索VMamba架构并进行细粒度的超参数搜索
尚未探索如何弥合SS2D与通用任务扫描模式的差距