你有没有这种感觉?看了很多Transformer、LLM的文章,却总觉得云里雾里?今天我们来聊聊大型语言模型(LLM)中的一个核心概念------Token。
直到我彻底掌握了"Token"和"分词器"的概念,这成为我理解Transformer架构的首次突破性领悟,或许也是我研究大模型时唯一无需反复琢磨就能完全领悟的知识点。
尽管这些概念显得"初级",但它们构成了所有大模型进行推理、训练和性能优化的根本基础。无论是deepseek还是claude,Token都是实现文本理解与生成的核心机制。
要理解大模型为啥按Tokens收费这个问题,我们先得知道到底什么是所谓的tokens?
"Tokens"常见释义为"代币;令牌;标记;符号" 。在计算机领域,它常指用于标识或验证的一种机制;在加密货币领域,通常指各种 数字代币;
而在语言学中,"Tokens"指语言符号,在语料库语言学里,"tokens"是"形符",即文本中出现的所有词的个数。
更多AI大模型学习视频及资源,都在智泊AI。
无论你是刚入门的大模型爱好者,还是在实践中苦于 Token 限制的开发者,这篇文章都会帮你从根本上理清思路。
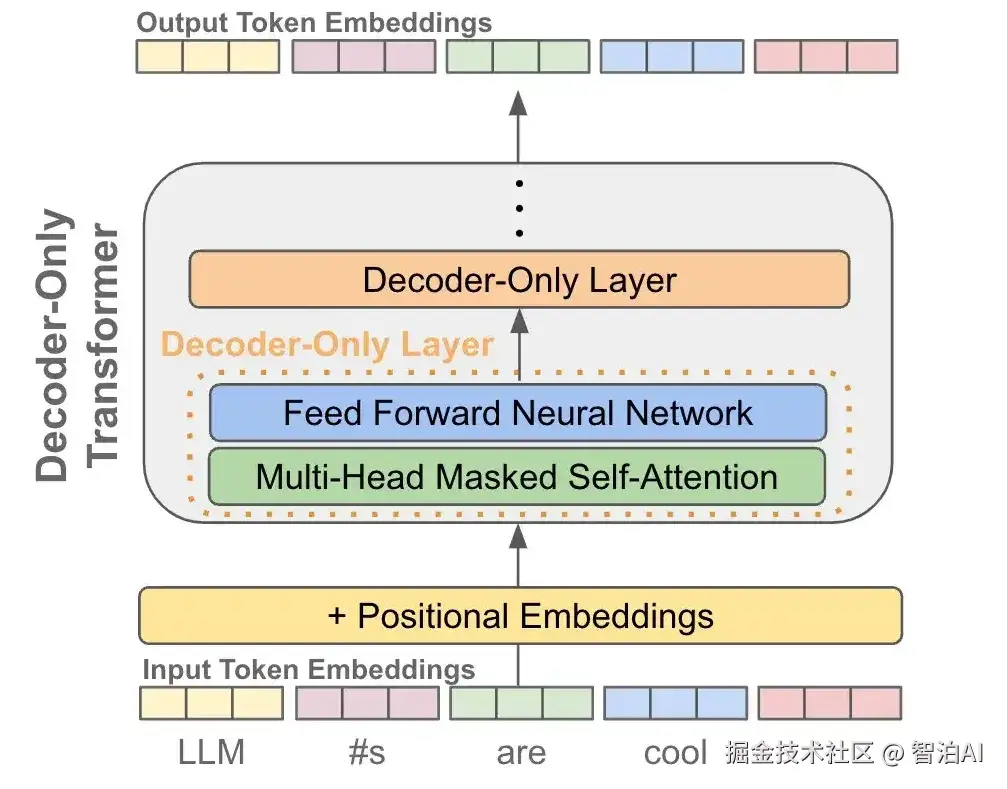
一、Token是什么?
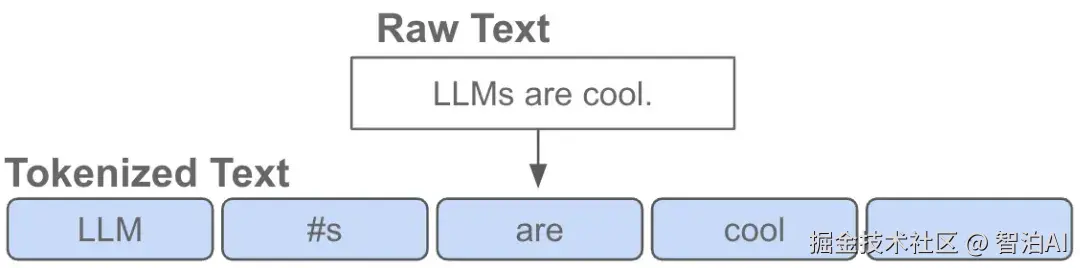
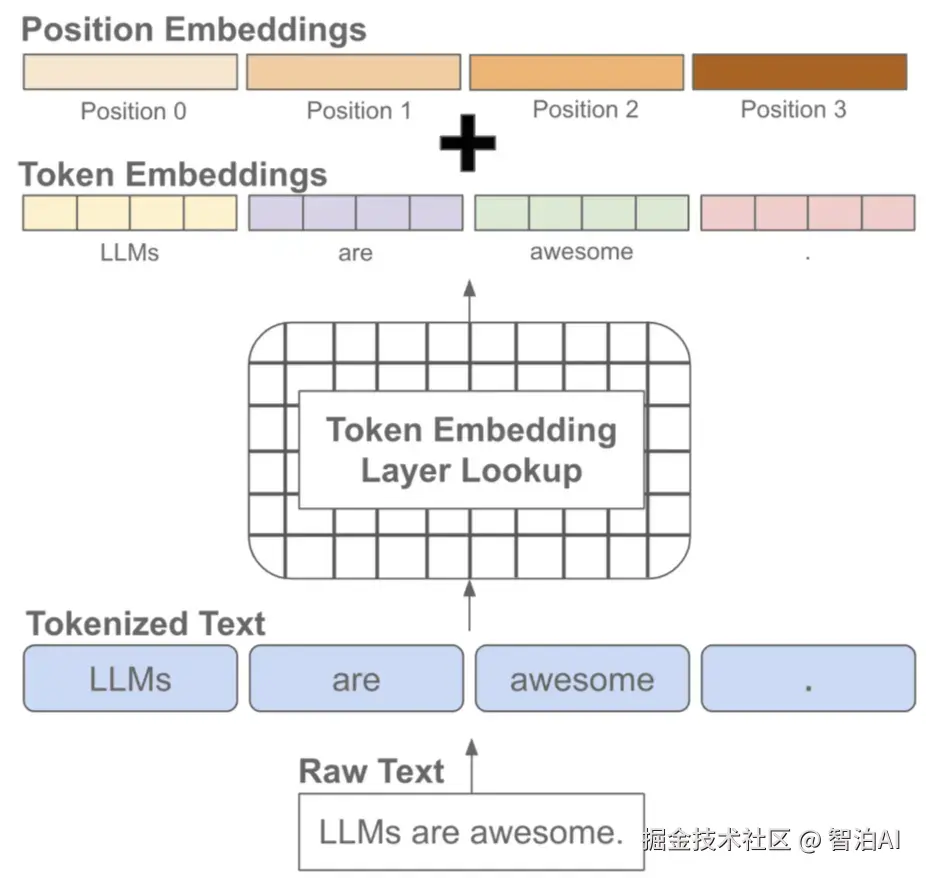
Token,本质上就是文本处理的基本单元。
想象你面前有一本写满文字的书,这些文字在LLM(大语言模型)中被分解为Token:可能是完整的词语(如"苹果"或"你好")
也可能是词语片段(如"unhappiness"拆分为"un"和"happiness"),甚至单个字母(如"apple"拆分为"a"、"p"、"p"、"l"、"e")。
这种灵活性的根源在于语言特性差异。英语等单词边界清晰的语言适合用完整单词作为Token,而中文这类无显式分隔的语言则需要更细粒度的拆分策略。
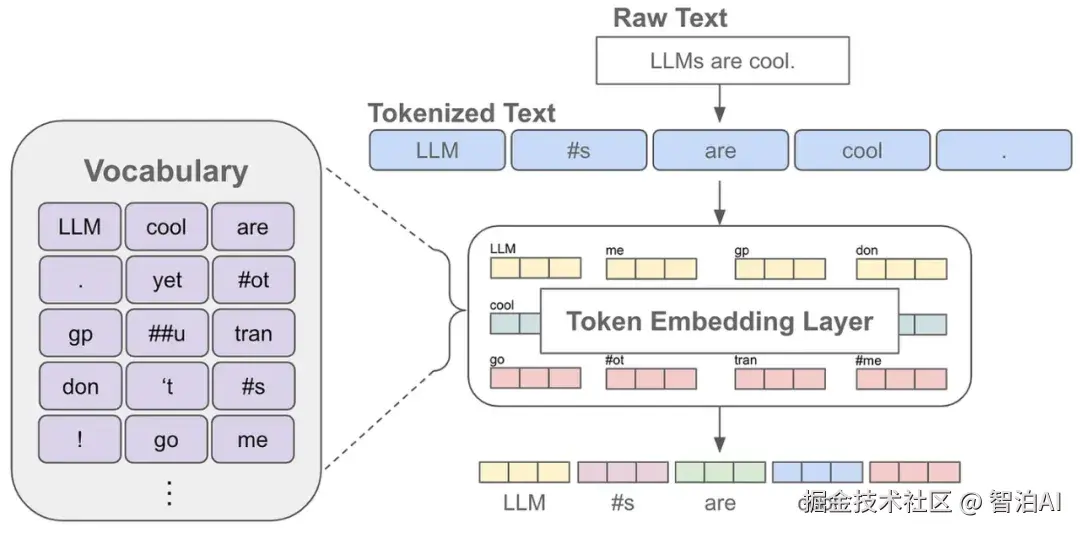
在自然语言处理技术领域,Tokens(词元)作为文本处理的基本单元,可直观视为模型解析文本的最小语义片段。
其划分逻辑由模型的分词策略决定:当采用字节对编码(BPE)等子词分词方法时,部分汉字或词汇可能被拆分为更细粒度的子单元,导致占用更多Token。例如:
腾讯混元大模型:1Token ≈ 1.8个汉字
通义千问:1Token ≈ 1个汉字
英文场景:1Token通常对应3-4个字母或一个完整单词
这一技术过程称为Tokenization,即通过将连续文本转化为离散的模型可处理单元,其效率直接关联计算资源消耗与输出质量。
举例:
在中文中:一个汉字通常为1个Token,但组合词可能拆分,比方说 "人工智能"可能拆为"人工"+"智能"。
而在英文中:一个单词可能对应1个Token,如 "apple",有可能是多个Token,如"ChatGPT" 拆为 "Chat" + "G" + "PT"。
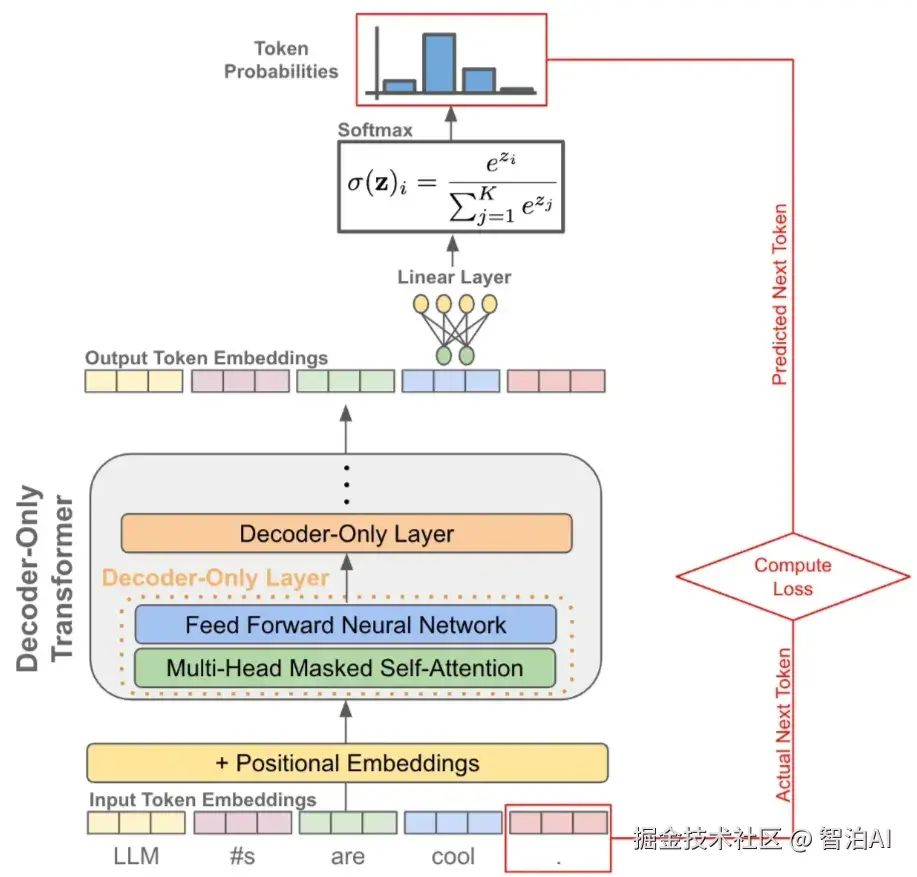
理解了Tokens是啥了以后,我们就好理解为什么按tokens收费是比较合理的原因了。
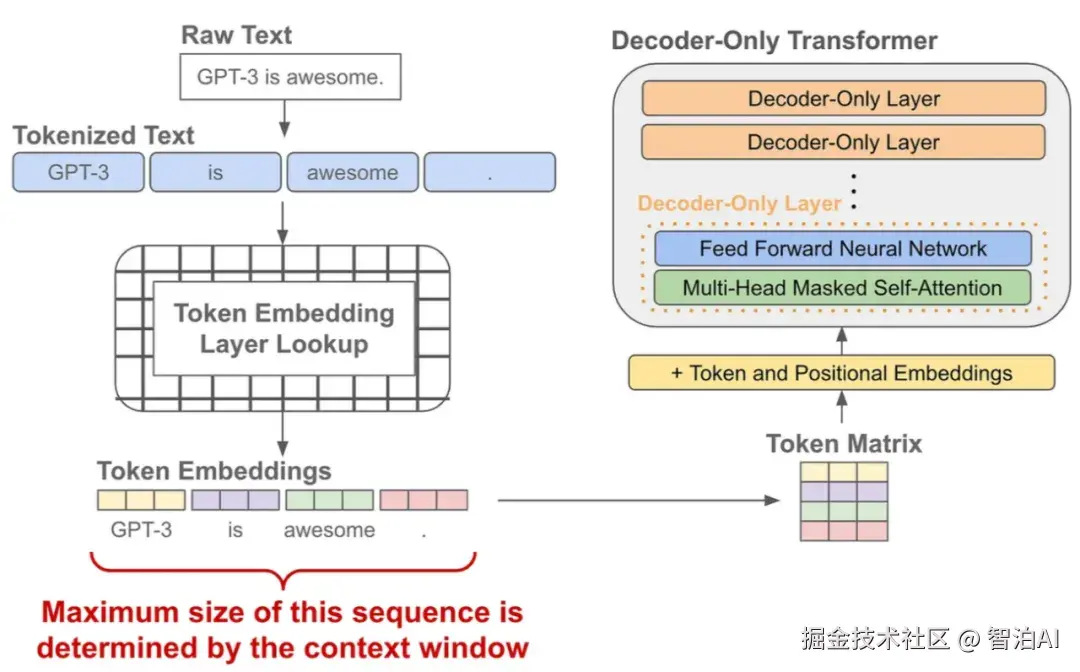
二、分词器
这些Token究竟是如何从原始文本中提取出来的? 答案在于分词器(Tokenizer)。它就像一位语言解码员,负责将人类输入的句子转化为AI可识别的Token序列。
分词器有几种常见的"翻译"方法:
字典分词:就像查字典,把句子里的词跟一个预先准备好的词表对上号。
BPE(Byte-Pair Encoding):从字符开始,把最常出现的字符组合起来,慢慢拼成更大的词块。
SentencePiece:有点像BPE,但更灵活,不管什么语言都能用。
WordPiece:BERT模型爱用的方式,也是把词拆成小块再组合。
举个例子:拿"Hello, I'm an AI assistant."这句话来说,用BPE分词器可能会把它拆成这样:'Hello', ',', ' I', "'m", ' an', ' AI', ' assistant', '.'。每个小块就是一个Token,AI就靠这些小块理解整句话。
三、中文的分词
中文分词面临独特挑战,因其缺乏类似英语的空格分隔机制。大型语言模型(LLM)如何应对这一难题?主要采用以下三种策略:
字符级分词
将每个汉字视为独立Token,如"你好"拆分为"你, 好"。该方案实现简单,但难以理解词汇语义。
词汇级分词
借助词典或统计模型进行切分,例如"长沙欢迎你"处理为"长沙, 欢迎, 你"。其效果高度依赖分词工具的质量。
子词级分词
采用类似BPE(字节对编码)的技术,组合高频字符序列。如"我爱长沙"可能拆分为"我, 爱, 长, 沙"或更大单元。
在LLM实践中,子词分词成为主流方案,因其能平衡处理生僻词(out-of-vocabulary words)的效率和准确性。
以LLaMA系列为例,其通过子词分词器处理中文文本。
虽然该方法在应对新词和计算效率上表现优异,但仍可能误判某些复合词结构,例如将"的事"错误合并而非识别为"事物"(To Merge or Not to Merge)。
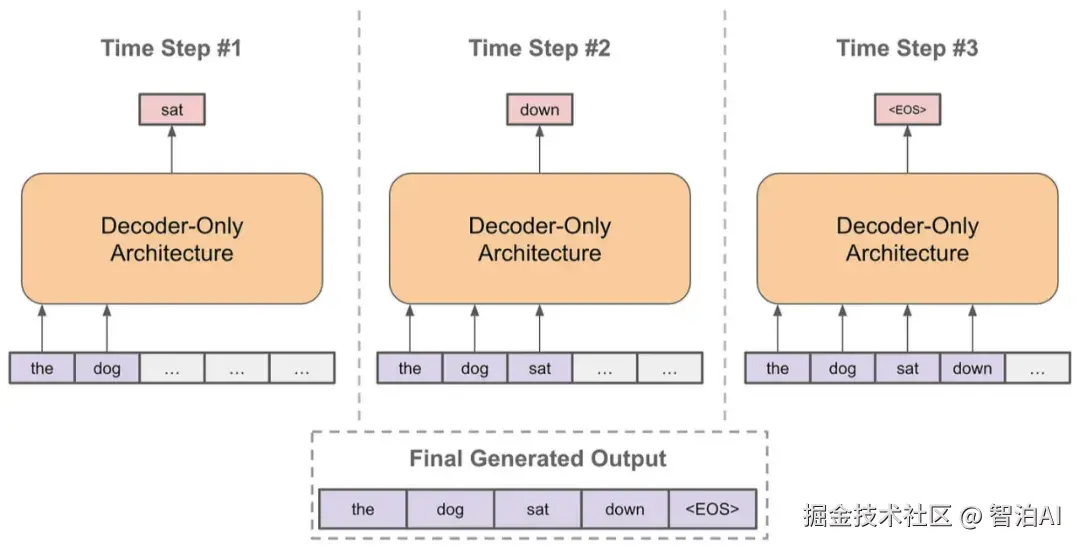
四、特殊Token------文字里的"交通标志"
除了普通的Token,LLM里还有一些"特殊Token",它们就像路上的交通标志,告诉模型一些特别的信息。常见的几种有:
CLS:表示一段文字的开头。
SEP:用来分开不同的句子。
PAD:如果句子长度不够,就用这个填充一下。
UNK:遇到不认识的词,就用这个代替。
MASK:有些模型(比如BERT)用这个来玩"填空游戏",训练时遮住一部分词。
这些特殊Token就像给AI指路的小助手,让它知道句子的结构和重点。
五、Token计数------为什么数量这么重要?
你可能会疑惑,Token数量多些少些能有多大影响?实际影响非常显著! 在大型语言模型(LLM)中,Token数量直接决定了运算成本和耗时。
以GPT-3为例,它采用BPE分词技术,通常一个英文单词会被拆分为约1.3个Token。
假设你输入100个Token,AI返回50个Token,累计消耗便是150个Token。多数AI服务商按Token总量计费,Token消耗量越高,费用支出就越明显。
比如:向AI提问"现在几点了?"可能仅需5个Token,但若提交一整份研究报告,Token数量可能突破上千。因此,使用AI服务时,实时关注Token消耗量是控制成本的关键细节。
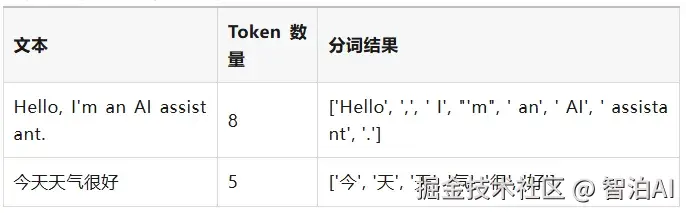
以下是一个Token计数的示例:
六、LLaMA系列模型的分词器演进
现在我们来看看具体的模型。LLaMA系列是Meta(前Facebook AI)开发的大型语言模型,目前已经发布了Llama 2和Llama 3。我们来看看它们的分词器是怎么演进的。
1、Llama 2的分词器:BPE和SentencePiece
Llama 2采用字节对编码(Byte Pair Encoding, BPE)作为其分词算法的核心。BPE作为一种无监督学习方法,通过统计语料中高频字符对的迭代合并来构建词汇表。
具体实现上,该分词器以字符为初始单元,逐次识别并合并频率最高的字符对,将新生成的组合纳入词汇表,此过程持续至词汇表规模达到预设值(约32,000个Token)或无法进一步合并为止(Understanding the Llama2 Tokenizer)。
此外,Llama 2的分词系统整合了SentencePiece框架。该无监督文本编码器通过统一接口支持BPE、WordPiece及Unigram等多种算法,其突出优势体现在跨语言适应性上。
由于直接处理原始文本且无需依赖空格等语言特定特征,SentencePiece能够实现对多领域和多语言场景的灵活兼容。
2、Llama 3的分词器:更大的词汇量和Tiktoken
Llama 3的分词器实现了重要改进。其词汇规模从Llama 2的32,000个令牌扩展至128,256个令牌,显著增强了文本编码的粒度。
这一提升不仅优化了输入输出的编码精度,还通过更高效的令牌分配改善了整体任务表现 (Llama 3 Tokenizer)。
技术选型方面,Llama 3采用Tiktoken替代了原有的SentencePiece方案。
作为OpenAI推出的新一代分词工具,Tiktoken在语言适应性和处理效率上具有突出优势,其多语言兼容性及与GPT系列模型的统一性可能是Llama 3转向该方案的关键考量 (In-depth understanding of Llama Tokenizer)。
3、Llama 4的分词器:尚未公布
截至目前,Meta尚未公开LLaMA 4的全部细节,但据行业推测,LLaMA 4的分词器可能具备以下特征:
继续使用Tiktoken,优化多语言处理;
词汇表可能进一步扩大,覆盖更广泛的词汇;
在分词效率、中文支持和噪声控制方面进行深度优化;
更好地支持"指令跟随(Instruction Tuning)"等复杂任务。
资源消耗
大模型的运行需要巨大的计算资源投入(如GPU/TPU算力),Token数量与处理文本的计算量呈正相关关系。采用Token计费方式能够更精准地反映不同长度文本的真实资源消耗。
例如,处理1000万Token的长文档所消耗的算力显著高于短文本,这种按实际用量收费的模式能有效克服传统统一定价的局限性。
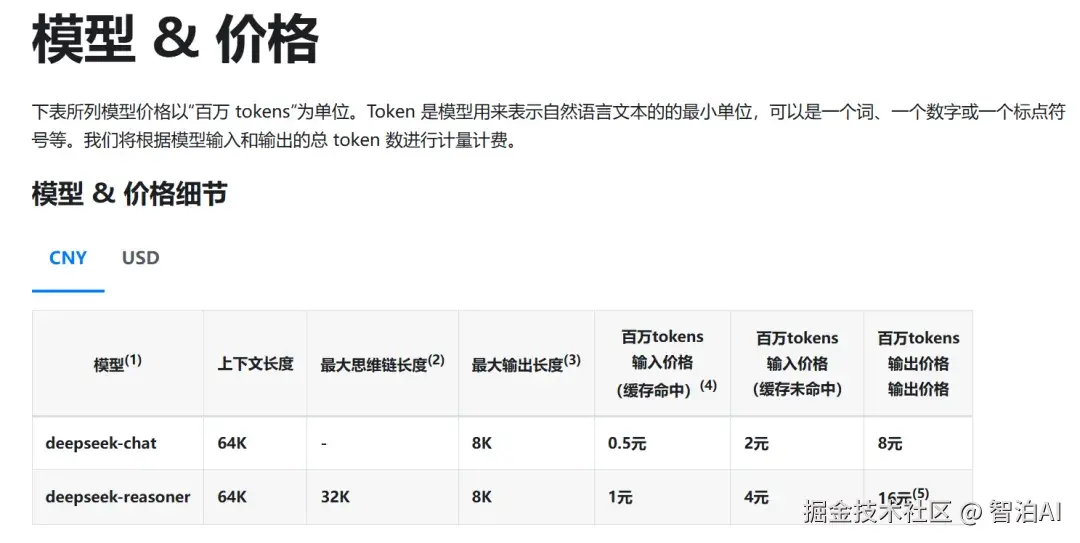
商业模式
Token计费通过将输入与输出的文本量统一转换为标准化计量单位(如输入1k Token + 输出2k Token = 总消耗3k Token),使用户能够清晰预估成本。
而传统API按次计费(如每次0.01元)的模式,难以体现简单请求与复杂任务之间的资源占用差异。
此外,大模型的全生命周期成本极高,研发训练阶段可能耗资数千万美元,采用Tokens计费可有效覆盖持续推理所需的实时算力支出,实现成本分摊的精细化。
七、总结
Token和分词器堪称大语言模型的"隐形引擎"。Token作为AI解析文本的原子单元,分词器则是实现文本到Token转换的精密工具。
从最初的WordPiece、BPE,到现今的SentencePiece与Tiktoken,技术演进揭示了一个关键事实:分词器的设计远非技术细节那么简单。
它不仅关乎文本编码的效能优化,更从根本上塑造着模型的语言认知能力、训练资源消耗以及实际推理效果。
不过Tokens计价并非单一方案,部分服务商推行复合计费模式,例如:会员制+按Tokens结算,或为小型模型设置免费用量。
当前行业对Tokens的界定尚未形成共识,各平台中文Tokens与字符的换算比例存在差异,可能造成跨平台成本波动。但不可否认的是,Tokens作为"AI经济体系的通用货币",已成为大模型商业应用中最广泛采用的计费标准。
通过本文,相信你能系统掌握Token与分词器的核心价值。唯有深入理解Token的本质,我们才能精准操控大模型,使其服务于各类应用场景。
更多AI大模型学习视频及资源,都在智泊AI。