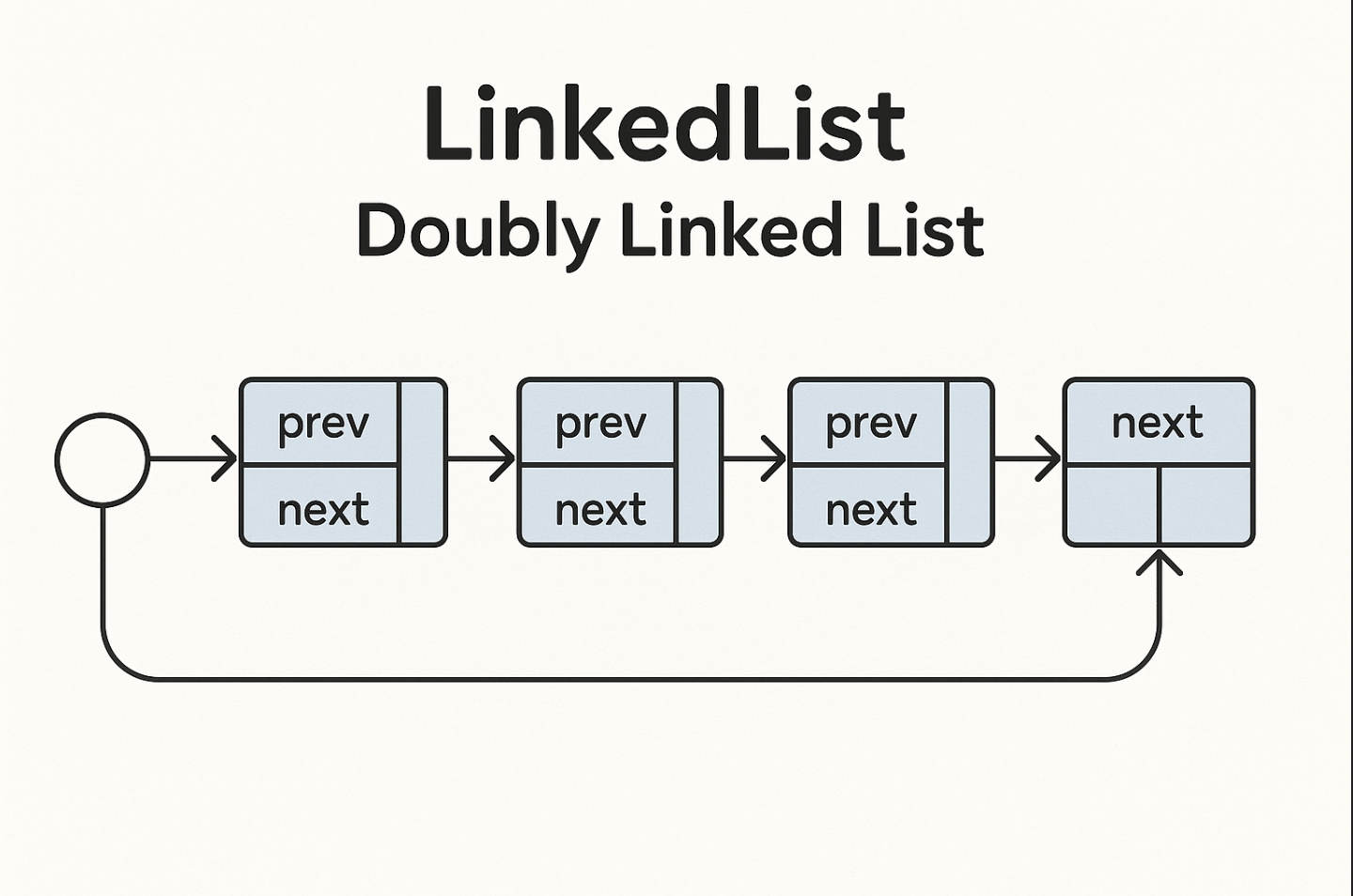
1. 双向链表基础概念 📚
双向链表是一种基础的数据结构,每个节点包含三个部分:
-
数据域:存储实际数据
-
前驱指针:指向前一个节点
-
后继指针:指向后一个节点
[prev] ← [data] → [next]
与数组相比,链表的优势在于:
- ✅ O(1) 时间复杂度的插入和删除(在已知位置时)
- ✅ 动态大小,无需预分配内存
- ❌ O(n) 的随机访问时间
- ❌ 额外的内存开销(指针)
2. Rust 标准库中的 LinkedList 实现 🔧
Rust 的 std::collections::LinkedList 是一个双向链表的实现。让我们先看看它的基本结构:
rust
pub struct LinkedList<T> {
head: Option<NonNull<Node<T>>>,
tail: Option<NonNull<Node<T>>>,
len: usize,
marker: PhantomData<Box<Node<T>>>,
}
struct Node<T> {
next: Option<NonNull<Node<T>>>,
prev: Option<NonNull<Node<T>>>,
element: T,
}关键设计要点:
NonNull 指针 🎯
- 非空指针类型,提供编译时保证
- 比原始指针更安全,但仍需要 unsafe 代码操作
- 协变性(covariance)支持
PhantomData 👻
- 标记所有权关系
- 告诉编译器 LinkedList 拥有 Node
- 影响 drop checker 的行为
3. 内存布局与指针结构 🧩
节点在堆上的分配
每个节点都是独立分配在堆上的:
rust
// 简化的内存布局示意
Heap:
┌─────────────────────┐
│ Node 1 │
│ ┌─────────────────┐ │
│ │ prev: null │ │
│ │ next: *Node2 │ │
│ │ element: "A" │ │
│ └─────────────────┘ │
└─────────────────────┘
│
↓
┌─────────────────────┐
│ Node 2 │
│ ┌─────────────────┐ │
│ │ prev: *Node1 │ │
│ │ next: *Node3 │ │
│ │ element: "B" │ │
│ └─────────────────┘ │
└─────────────────────┘指针循环与内存安全 ⚠️
Rust 的所有权系统通常不允许循环引用,但 LinkedList 通过以下方式解决:
- 使用 unsafe 代码:内部操作原始指针
- 明确的生命周期管理:LinkedList 拥有所有节点
- Drop 实现:确保正确释放内存
rust
impl<T> Drop for LinkedList<T> {
fn drop(&mut self) {
while let Some(_) = self.pop_front() {}
}
}4. 所有权与借用机制 🔐
插入操作的所有权转移
rust
let mut list = LinkedList::new();
let value = String::from("Hello");
list.push_back(value); // value 的所有权转移到 list
// println!("{}", value); // ❌ 编译错误!迭代器与借用
rust
let list = LinkedList::from([1, 2, 3, 4]);
// 不可变借用
for item in &list {
println!("{}", item); // ✅
}
// 可变借用
for item in &mut list {
*item *= 2; // ✅
}
// 消费迭代器(获取所有权)
for item in list {
// list 的所有权被转移
println!("{}", item);
}
// list 不再可用 ❌5. 性能特性分析 📊
时间复杂度对比
| 操作 | LinkedList | Vec |
|---|---|---|
| push_back | O(1) | O(1)* |
| push_front | O(1) | O(n) |
| pop_back | O(1) | O(1) |
| pop_front | O(1) | O(n) |
| insert (中间) | O(1)** | O(n) |
| 索引访问 | O(n) | O(1) |
| 遍历 | O(n) | O(n) |
* 摊销时间
** 假设已有指向位置的指针
内存开销
rust
use std::mem::size_of;
// 在 64 位系统上
println!("Node<i32> size: {}", size_of::<Node<i32>>());
// 约 24 字节:两个指针(16) + i32(4) + 填充(4)
println!("Vec<i32> overhead: {}", size_of::<Vec<i32>>());
// 24 字节:指针 + 容量 + 长度关键观察 🔍:
- LinkedList 每个元素都有额外的指针开销
- 小数据类型使用 LinkedList 会有显著的内存浪费
- 缓存不友好:节点分散在堆上
6. 常见操作的实现原理 ⚙️
push_back 实现分析
rust
pub fn push_back(&mut self, element: T) {
let mut node = Box::new(Node {
next: None,
prev: None,
element,
});
let node_ptr = NonNull::new(Box::into_raw(node)).unwrap();
unsafe {
if let Some(tail) = self.tail {
// 链表非空
(*node_ptr.as_ptr()).prev = Some(tail);
(*tail.as_ptr()).next = Some(node_ptr);
} else {
// 链表为空
self.head = Some(node_ptr);
}
self.tail = Some(node_ptr);
}
self.len += 1;
}步骤解析:
- 📦 在堆上分配新节点(Box)
- 🔄 转换为原始指针
- 🔗 更新前后指针关系
- 📍 更新 tail 指针
- ➕ 增加长度计数
split_off 实现
split_off 在指定位置分割链表,这展示了指针操作的复杂性:
rust
pub fn split_off(&mut self, at: usize) -> LinkedList<T> {
let len = self.len;
assert!(at <= len, "split point out of bounds");
if at == 0 {
return mem::replace(self, LinkedList::new());
} else if at == len {
return LinkedList::new();
}
// 找到分割点
let mut split_node = self.head;
for _ in 0..at {
split_node = unsafe {
(*split_node.unwrap().as_ptr()).next
};
}
// 创建新链表并更新指针...
// (简化版本)
}7. 使用场景与最佳实践 💡
✅ 适合使用 LinkedList 的场景
- 频繁的头部插入/删除
rust
let mut queue = LinkedList::new();
queue.push_back(task1); // 入队
queue.pop_front(); // 出队- 需要分割/合并操作
rust
let mut list1 = LinkedList::from([1, 2, 3]);
let list2 = list1.split_off(2); // O(n) 定位,O(1) 分割- 实现某些算法(如 LRU 缓存)
❌ 不推荐使用的场景
- 需要频繁随机访问
rust
// ❌ 性能差
list[100] // LinkedList 不支持索引
// ✅ 使用 Vec
vec[100] // O(1) 访问- 小数据类型的集合
rust
// ❌ 内存效率低
LinkedList<u8> // 每个 1 字节数据需要 16+ 字节指针
// ✅
Vec<u8> // 紧凑存储- 性能敏感的代码
- LinkedList 的缓存局部性差
- 现代 CPU 更适合连续内存访问
最佳实践建议 🌟
rust
// 1. 优先考虑 Vec
let mut data = Vec::new(); // 默认选择
// 2. 需要双端队列时考虑 VecDeque
use std::collections::VecDeque;
let mut deque = VecDeque::new(); // 比 LinkedList 快
// 3. 确实需要链表特性时才用 LinkedList
let mut list = LinkedList::new();总结与思考 🤔
Rust 的 LinkedList 实现展示了如何在安全的高级语言中处理底层数据结构:
- unsafe 的必要性:指针操作无法避免 unsafe
- 所有权的精妙设计:通过类型系统保证内存安全
- 性能权衡:灵活性 vs 性能
关键启示:
- 🎯 理解数据结构的真实成本
- 🔍 根据具体场景选择合适的容器
- ⚡ 优化热路径上的数据结构选择