文章目录
- 1、介绍一下Go语言的特点和优势。
- [2、Go 和 Java 对比](#2、Go 和 Java 对比)
- [3、Go string 和 \[\]byte 的区别](#3、Go string 和 []byte 的区别)
- 4、make和new的区别
- 5、数组和切片的区别
- 6、切片是如何扩容的
- 7、扩容前后的Slice是一样的吗
- [8、go slice的底层实现(https://go.dev/blog/slices-intro)](#8、go slice的底层实现)
- 9、Go语言参数传递
- [10、Go语言map是有序的还是无序的, 为什么](#10、Go语言map是有序的还是无序的, 为什么)
- [11、go map的底层实现原理](#11、go map的底层实现原理)
- 12、map如何扩容
- [13、如何想要按照特定顺序遍历map, 怎么做](#13、如何想要按照特定顺序遍历map, 怎么做)
- 14、go里面的map是并发安全的吗?如何并发安全
- [15、Go 的错误处理和 Java 的异常处理对比](#15、Go 的错误处理和 Java 的异常处理对比)
- 16、Go有异常类型吗
-
- [panic 和 recover](#panic 和 recover)
- 按执行顺序详细解释(时间线)
- 17、介绍一下panic和recover
-
- [1. panic](#1. panic)
- [2. recover](#2. recover)
- 18、什么是defer?有什么作用
- 19、Go面向对象是怎么实现的?
1、介绍一下Go语言的特点和优势。
- 语法简单
- 支持轻量级线程(goroutine)和通信(channel),高效并发
- 内置垃圾回收
2、Go 和 Java 对比
- Java使用广泛,但是Go比Java更适合高并发和轻量级的应用
- Java通过线程和锁来处理并发 ,Goroutines和channels是Go语言的并发特性的核心
- Java是一门功能丰富、面向对象的语言,支持面向对象编程、泛型等高级特性。Go语言的设计注重简洁和清晰,具有简单的语法和类型系统。它摒弃了一些复杂的特性,强调代码的可读性。
- Go语言具有垃圾回收机制,开发者无需手动管理内存。Java同样拥有垃圾回收机制,这减轻了开发者的负担,但在一些情况下可能引入一些不可控的暂停。
- Go适用于构建高性能、高并发的后端服务、网络应用、云服务以及分布式系统。Java广泛应用于大型企业应用、Android应用、大规模分布式系统和企业级应用。
3、Go string 和 \[\]byte 的区别
如果需要频繁地修改字符串内容,或者处理二进制数据,使用 \[\]byte 更为合适 。如果字符串内容基本保持不变,并且主要处理文本数据,那么使用 string 更为方便。
- 不可变性
string 是不可变的数据类型,一旦创建就不能被修改。任何修改 string 的操作都会产生一个新的 string,而原始的 string 保持不变。相比之下,\[\]byte 是可变的切片,可以通过索引直接修改切片中的元素。 - 类型转换
可以在 string 和 \[\]byte 之间进行类型转换。使用 \[\]byte(s) 可以将 string 转换为 \[\]byte,而使用 string(b) 可以将 \[\]byte 转换为 string。这个操作会创建新的底层数组,因此在转换后修改其中一个不会影响另一个。 - 内存分配
- string 是一个不可变的视图,底层数据是只读的。string 的内存分配和释放由Go运行时管理。
- \[\]byte 是一个可变的切片,底层数据是可以修改的。\[\]byte 的内存管理由程序员负责。
- Unicode字符
string 中的每个元素是一个 Unicode 字符,而 \[\]byte 中的每个元素是一个字节。因此,string 可以包含任意字符,而 \[\]byte 主要用于处理字节数据。
4、make和new的区别
make 和 new 是两个用于分配内存的内建函数,在使用场景和返回值类型上有明显的区别。
- make 用于创建并初始化切片、映射和通道等引用类型。它返回的是被初始化的非零值(非nil)的引用类型。
go
// 创建并初始化切片
slice := make([]int, 5, 10)
// 创建并初始化映射
myMap := make(map[string]int)
// 创建并初始化通道
ch := make(chan int)- new 用于分配值类型的内存,并返回该值类型的指针。它返回的是分配的零值的指针。
go
// 分配整数类型的内存,并返回指针
ptr := new(int)
go
package main
import "fmt"
func main() {
// 使用 make 创建并初始化切片
slice := make([]int, 5, 10)
fmt.Println(slice) // 输出: [0 0 0 0 0]
// 使用 new 分配整数类型的内存,并返回指针
ptr := new(int)
fmt.Println(*ptr) // 输出: 0
}总结:
- new只用于分配内存,返回一个指向地址的指针。它为每个新类型分配一片内存,初始化为0且返回类型*T的内存地址,它相当于&T{}
- make只可用于slice,map,channel的初始化,返回的是引用。
5、数组和切片的区别
- 数组
- 固定长度:在声明数组时,需要指定数组的长度,且不能更改。
- 值类型:当将一个数组赋值给另一个数组时,会进行值拷贝。这意味着修改一个数组的副本不会影响原始数组。
- 数组的元素在内存中是顺序存储的,分配在一块连续的内存区域。
- 切片
- 切片的长度可以动态调整,而且可以不指定长度。
- 切片是引用类型,当一个切片赋值给另一个切片时,它们引用的是相同的底层数组 。修改一个切片的元素会影响到其他引用该底层数组的切片。
- 切片本身不存储元素,而是引用一个底层数组,切片的底层数组会在需要时进行动态扩展。
go
// 创建切片
slice1 := make([]int, 3, 5) // 长度为3,容量为5的切片
slice2 := []int{1, 2, 3} // 直接初始化切片
slice3 := arr[:] // 从数组截取切片6、切片是如何扩容的
- 切片的扩容容量是按指数增长的。当切片的容量不足时,Go运行时系统会分配一个更大的底层数组,并将原来的元素拷贝到新数组中。新数组的大小通常是原数组的两倍(但并不一定严格遵循2倍关系)
- 在切片扩容时,Go运行时系统会预估未来的元素增长,并提前分配足够的空间。这可以减少频繁的内存分配和拷贝操作。
- 对于小切片,扩容时增加的容量可能相对较小,避免了内存的过度浪费。而对于大切片,扩容时增加的容量可能较多。
首先判断,如果新申请容量大于2倍的旧容量,最终容量就是新申请的容量
否则判断,如果旧切片的长度小于1024,则最终容量就是旧容量的两倍
否则判断,如果旧切片长度大于等于1024,则最终容量从旧容量开始循环,增加原来的 1/4,直到最终容量大于等于新申请的容量
如果最终容量计算值溢出,则最终容量就是新申请容量
最后一句话大概就是这个意思
go
newcap := oldcap
for newcap < need {
next := newcap + newcap/4 // 或 newcap*2 等
if next < newcap { // 发生回绕/溢出的一种典型信号
newcap = need // 兜底:至少装得下
break
}
newcap = next
}7、扩容前后的Slice是一样的吗
如果扩容后的容量仍然能够容纳新元素,系统会尽量在原地进行扩容,否则会分配一个新的数组,将原有元素复制到新数组中。
- 如果容量够(newLen <= cap),就继续用原来的底层数组(看起来像原地增长 len)
- 如果容量不够(newLen > cap),就换一块新数组并拷贝
也就是:能不搬家就不搬家;一旦放不下就搬家。
一个最直观的验证方式(看地址变没变)
- 不扩容:底层数组地址不变
- 扩容:底层数组地址改变(指向新数组)
8、go slice的底层实现
切片本身并不是动态数组或者数组指针。它内部实现的数据结构通过指针引用底层数组,设定相关属性将数据读写操作限定在指定的区域内 。切片本身是一个只读对象,其工作机制类似数组指针的一种封装。主要通过一个结构体来表示,该结构体包含了以下三个字段:
go
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 切片的当前长度
cap int // 切片的容量
}9、Go语言参数传递
对于基本数据类型(如整数、浮点数、布尔值等)和结构体,传递的是值的副本,修改形参的值不会影响实参。
go
package main
import "fmt"
func modifyValue(x int) {
x = 10
}
func main() {
a := 5
modifyValue(a)
fmt.Println(a) // 输出: 5, 因为a的值未被修改
}对于切片、映射、通道等引用类型,传递的是引用的副本,修改形参的内容会影响到实参。
go
package main
import "fmt"
func modifySlice(s []int) {
s[0] = 10
}
func main() {
slice := []int{1, 2, 3}
modifySlice(slice)
fmt.Println(slice) // 输出: [10 2 3], 因为slice的内容被修改
}10、Go语言map是有序的还是无序的, 为什么
Go语言中,map 是一种用于存储键值对的集合类型。它是一种无序的集合,其中每个元素都由一个唯一的键和对应的值组成 。当 map 的元素数量达到一定阈值时,Go语言会动态调整 map 的大小。
这是因为 map 的实现采用了散列表(hash table)的数据结构。散列表通过哈希函数将键映射到存储桶(bucket),散列表中的存储桶是无序的,它们并不保证元素按照特定顺序存储。
11、go map的底层实现原理
Go语言中的 map 的底层实现原理主要基于散列表 (hash table)。散列表是一种用于实现字典结构的数据结构,它通过一个哈希函数将键映射到存储桶(bucket) ,每个存储桶存储一个链表或红黑树,用于处理哈希冲突。存储桶的数量是固定的,由 map 的大小和负载因子来确定。
12、map如何扩容
Go语言中的 map 在元素数量达到一定阈值时,会触发扩容操作,其扩容是自动进行的。
- 计算新的存储桶数量 :当 map 的元素数量达到负载因子(load factor)的上限时,会触发扩容。新的存储桶数量通常是当前存储桶数量的两倍。
- 分配新的存储桶和散列数组:创建新的存储桶和散列数组,大小为新的存储桶数量。这个过程会涉及到内存分配。
- 重新散列元素:遍历当前 map 的每个存储桶,将其中的元素重新散列到新的存储桶中。这一步是为了保持元素在新的存储桶中的顺序。
- 切换到新的存储桶和散列数组 :将 map 的内部数据结构指向新的存储桶和散列数组。这个过程是原子的,以确保在切换期间不会影响并发访问。
- 释放旧的存储桶和散列数组 :释放旧的存储桶和散列数组的内存空间。这个过程是为了避免内存泄漏。
13、如何想要按照特定顺序遍历map, 怎么做
- 遍历 map,将键存储在切片中,切片是有序的。
- 使用排序函数对存储键的切片进行排序。
- 使用排好序的切片,按照顺序遍历 map。
下面是一个演示:按照键的字母顺序遍历 map
go
package main
import (
"fmt"
"sort"
)
func main() {
myMap := map[string]int{
"apple": 5,
"banana": 3,
"orange": 7,
"grape": 1,
}
// 将键存储在切片中
keys := make([]string, 0, len(myMap))
for key := range myMap {
keys = append(keys, key)
}
// 对切片进行排序
sort.Strings(keys)
// 按照排序后的顺序遍历map
for _, key := range keys {
fmt.Printf("%s: %d\n", key, myMap[key])
}
}14、go里面的map是并发安全的吗?如何并发安全
Go 中的标准 map 类型是非并发安全的,这意味着在多个 Goroutine 中并发读写同一个 map 可能导致数据竞争和不确定的行为 。为了在并发环境中使用 map,Go 提供了 sync 包中的 sync.Map 类型,它是一种并发安全的映射。
go
import "sync"
// 创建一个并发安全的 map
var myMap sync.Map
// 在 Goroutine 中使用
go func() {
// 存入数据
myMap.Store("key", "value")
// 从 map 中读取数据
if value, ok := myMap.Load("key"); ok {
// 处理 value
}
}()15、Go 的错误处理和 Java 的异常处理对比
Go
- Go语言使用返回值来处理错误,函数通常返回两个值,一个是正常的返回值,另一个是 error 类型的值,用于表示可能出现的错误。开发者需要显式地检查错误并进行处理,通过判断返回的 error 值是否为 nil 来确定函数是否执行成功。
- Go中的错误是普通的值,是实现了 error 接口的类型。
- Go的错误处理机制在性能上通常更为高效,因为它不会引入额外的控制流程(异常栈的构建和查找等)
go
result, err := someFunction()
if err != nil {
// 处理错误
}Java
- Java使用异常机制处理错误。当出现错误时,可以通过 throw 关键字抛出异常,而在调用栈中寻找匹配的 catch 块来捕获并处理异常。
- Java中的异常是对象,是某个类的实例。Java的异常类型必须继承自 Throwable 类或其子类
- 异常处理机制可能在性能上带来一定开销,特别是在抛出和捕获异常的过程中。
go
try {
// 可能抛出异常的代码
result = someFunction();
} catch (SomeException e) {
// 处理异常
}16、Go有异常类型吗
Go鼓励使用返回值来处理错误,在Go中,函数通常会返回两个值,其中一个是函数的正常返回值,另一个是 error 类型的值,表示函数执行是否成功。
go
result, err := someFunction()
if err != nil {
// 处理错误
}此外,还可以通过使用 panic 和 recover 关键字来实现类似异常处理的机制。panic 用于引发运行时错误,而 recover 用于捕获并处理 panic
go
func example() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered:", r)
}
}()
panic("Something went wrong!")
}
func main() {
example()
}
bash
root@GoLang:~/proj/goforjob# go run main.go
Recovered: Something went wrong!
root@GoLang:~/proj/goforjob# panic 和 recover

按执行顺序详细解释(时间线)
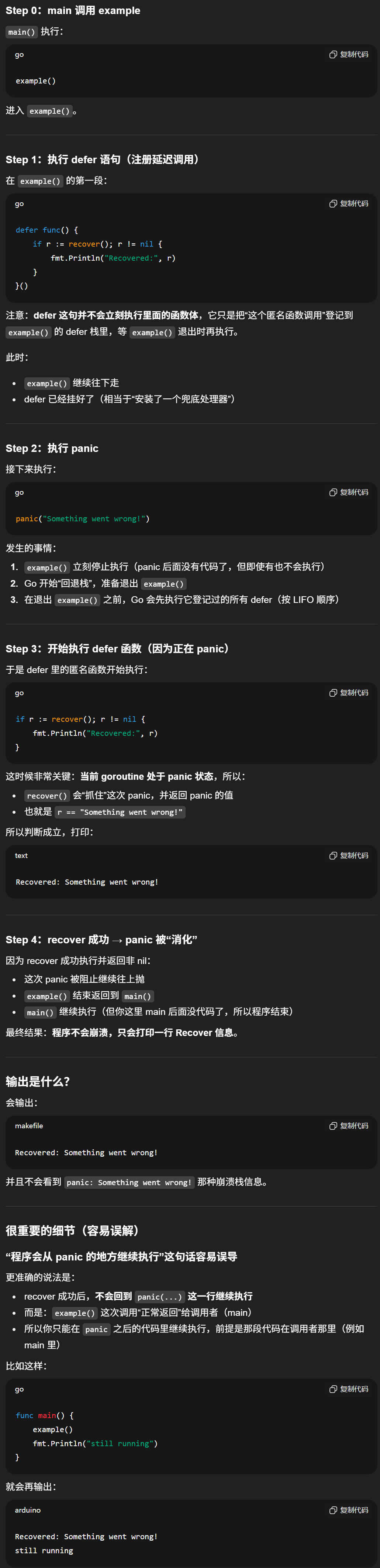
17、介绍一下panic和recover
panic 和 recover 是用于处理运行时错误和恢复程序执行的两个关键字。但是在一般情况下,Go语言更倾向于使用显式的错误处理,而不是依赖于 panic 和 recover。
1. panic
panic 是一个内建函数,用于引发运行时错误,通常表示程序遇到了不可恢复的错误。
当程序执行到 panic 语句时,它会立即停止当前函数的执行,并沿着函数调用栈向上搜索,执行每个被调用函数的 defer 延迟函数(如果有的话),然后程序终止。
panic 通常用于表示程序遇到了一些致命错误,例如切片越界、除以零等。
go
func example() {
panic("Something went wrong!")
}
func main() {
example()
}2. recover
- recover 是一个内建函数,用于从 panic 引发的运行时错误中进行恢复。
- recover 只能在 defer 延迟函数中使用,用于捕获 panic 的值,并防止程序因 panic 而崩溃。
- 如果在 defer 函数中调用了 recover,并且程序处于 panic 状态,那么 recover 将返回 panic 的值,并且程序会从 panic 的地方继续执行。
go
func example() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered:", r)
}
}()
panic("Something went wrong!")
}
func main() {
example()
fmt.Println("Program continues after panic recovery.")
}18、什么是defer?有什么作用
defer 用于延迟函数的执行,它会将函数调用推迟到包含 defer 语句的函数执行完成之后。通常用于资源释放、锁的释放、日志的记录等。
Q:执行顺序
defer 语句是按照后进先出(LIFO)的顺序 执行的,即最后一个 defer 语句会最先执行。
Q:函数参数是在哪个时刻确定的?
defer 语句中的函数参数在 defer 语句被执行时就已经确定了,而不是在函数实际调用时。因此,如果 defer 语句中有函数参数,这些参数的值是在 defer 语句执行时就会被计算并保留。
Q:对性能有没有影响
defer 语句的性能影响通常很小,因为它是在函数退出时执行的。但如果在循环中使用了大量的 defer 语句,可能会导致性能问题,因为 defer 语句的执行会被延迟到函数退出时,循环可能会在函数退出之前执行许多次。
Q:在什么情况下会有问题?
如果在循环中使用 defer,并且 defer 中引用了循环变量 ,由于 defer 语句的延迟执行特性,可能导致循环结束后函数执行时使用的是最后一次循环变量的值。这被称为"defer在循环中的陷阱"。
go
for i := 0; i < 5; i++ {
defer func() {
fmt.Println(i)
}()
}上述代码输出的结果是5个5,而不是0到4。避免这种问题的一种方法是在循环体内部创建一个局部变量,将循环变量的值传递给 defer 中的函数。
go
for i := 0; i < 5; i++ { // ① 外层 i:循环变量
i := i // 创建一个新的局部变量,保存当前 i 的值
// ② 内层 i:在循环体作用域里新声明的变量(遮蔽外层 i)
defer func() {
fmt.Println(i) // 这里用的是②这个 i
}()
}19、Go面向对象是怎么实现的?
Go没有类的概念,而是通过结构体(struct)和接口(interface)来实现面向对象的特性。
- 结构体是一种用户定义的数据类型,可以包含字段(成员变量)和方法(成员函数)。
go
type Person struct {
Name string
Age int
}
// 方法
func (p *Person) SayHello() {
fmt.Println("Hello, my name is", p.Name)
}- Go语言通过接口来定义对象的行为,而不是通过明确的继承关系。一个类型只要实现了接口定义的方法,就被视为实现了该接口。
go
type Speaker interface {
Speak()
}
type Person struct {
Name string
}
// Person 实现了 Speaker 接口
func (p *Person) Speak() {
fmt.Println("Hello, my name is", p.Name)
}- Go语言通过结构体的组合特性来实现对象的组合。一个结构体可以包含其他结构体作为其字段,从而实现对象的复用。
- 尽管Go语言没有像传统面向对象语言那样的私有成员访问修饰符,但通过首字母大小写来控制成员的可见性,实现了封装的效果。首字母大写的成员是公有的,可以被外部包访问;首字母小写的成员是私有的,只能在定义的包内访问。
之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!