环境准备
docker可以快速部署应用,非常方便。
在linux系统中,需要安装docker和docker compose,安装教程如下:
https://blog.csdn.net/liangmengbk/article/details/144644446
https://blog.csdn.net/liangmengbk/article/details/144943003
ELK是什么
ELK 是一个流行的开源日志分析和可视化平台,由三个主要组件组成:Elasticsearch、Logstash 和 Kibana。它们通常一起使用,因此被称为 ELK 堆栈。
ElasticSearch:用于日志存储、检索统计
Logstash:用户日志收集、转换、筛选
Kibana:用户人机交互和查询展示
他们之间的关系如下,当应用系统产生日志后,通过应用日志收集客户端(例如spring boot提供的Logstash Logback Encoder组件),可以把产生的日志,推送给Logstash,由Logstash对日志进行转换和筛选。接着把日志存储到ElasticSearch中,可以简单理解ElasticSearch是个数据库,把日志信息存在ElasticSearch里面进行持久化保存。最后通过Kibana进行日志的查询和展示。

ELK部署
ELK的部署包括ElasticSearch、Logstash、Kibana的部署,这是三个软件。可以每个软件单独安装,只不过这样比较麻烦,使用docker compose可以一次性将三个软件安装完成。下面是具体的步骤:
编写docker compose脚本
docker compose脚本,用于对容器进行编排,简单说就是它定义了要安装的软件和软件的安装顺序。在docker中一般把软件称为镜像(类似windows的软件安装包),镜像启动后,就产生了容器,容器可以对外提供访问。
# Docker Compose 版本
version: '3.8'
services:
# ========================================
# Elasticsearch - 搜索和分析引擎
# ========================================
elasticsearch:
image: elasticsearch:8.11.0 # 使用官方镜像
container_name: elasticsearch # 容器名称
environment:
- discovery.type=single-node # 单节点模式(适合测试/开发)
- xpack.security.enabled=false # 关闭安全认证(简化使用,生产环境建议开启)
- "ES_JAVA_OPTS=-Xms512m -Xmx512m" # JVM 堆内存设置(最小512M,最大512M)
ports:
- "9200:9200" # API 访问端口(可通过 curl http://localhost:9200 测试)
volumes:
- es-data:/usr/share/elasticsearch/data # 数据持久化存储
# ========================================
# Logstash - 日志收集和处理
# ========================================
logstash:
image: logstash:8.11.0 # 使用官方镜像
container_name: logstash # 容器名称
ports:
- "5000:5000" # 日志接收端口(TCP/JSON格式)
# 动态创建配置文件并启动 Logstash
command: |
bash -c '
cat > /usr/share/logstash/pipeline/logstash.conf <<EOF
input {
tcp {
port => 5000
codec => json
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "logs-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
EOF
/usr/local/bin/docker-entrypoint
'
depends_on:
- elasticsearch # 依赖 Elasticsearch,确保先启动 ES
# ========================================
# Kibana - 可视化界面
# ========================================
kibana:
image: kibana:8.11.0 # 使用官方镜像
container_name: kibana # 容器名称
ports:
- "5601:5601" # Web 访问端口(浏览器访问 http://localhost:5601)
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200 # 连接到 Elasticsearch
- I18N_LOCALE=zh-CN # 界面语言设置为中文
depends_on:
- elasticsearch # 依赖 Elasticsearch
# ========================================
# 数据卷 - 持久化存储
# ========================================
volumes:
es-data: # Elasticsearch 数据存储卷(停止容器后数据不丢失)编写启动ELK脚本
为了方便启动ELK,定义启动脚本,用于配置一些系统参数和运行上面定义的docker compose脚本。
#!/bin/bash
echo "=========================================="
echo " 一键启动 ELK"
echo "=========================================="
echo ""
# 配置系统参数
echo "1. 配置系统参数..."
sudo sysctl -w vm.max_map_count=262144 2>/dev/null || sysctl -w vm.max_map_count=262144
# 检测 docker-compose 命令
if command -v docker-compose &> /dev/null; then
DOCKER_COMPOSE="docker-compose"
else
DOCKER_COMPOSE="docker compose"
fi
echo "2. 启动 ELK..."
$DOCKER_COMPOSE -f docker-compose.elk.yml up -d
echo ""
echo "3. 等待服务启动..."
sleep 10
echo ""
echo "=========================================="
echo " 启动完成!"
echo "=========================================="
echo ""
echo "Kibana 访问地址: http://服务器IP地址:5601"
echo ""
echo "发送测试日志:"
echo " echo '{\"message\":\"测试日志\",\"level\":\"INFO\"}' | nc localhost 5000"
echo ""
echo "查看日志:"
echo " docker compose -f docker-compose.elk.yml logs -f"
echo ""
echo "停止服务:"
echo " docker compose -f docker-compose.elk.yml down"
echo ""上传脚本
将上面定义好的两个脚本,上传到linux服务器上

我是把文件放到opt/elk目录下面
脚本赋权
要想执行sh文件,首先需要确保sh文件具有执行的权限,所以要先对sh文件进行赋权,让它具有可执行权利。
chmod +x 启动ELK.sh
启动
在sh文件所在的路径下面,执行下面的命令,用于执行 启动ELK.sh 文件。
./启动ELK.sh
接下去就是等待了,docker会去拉取对应的镜像,然后创建容器。这个过程需要一些时间。
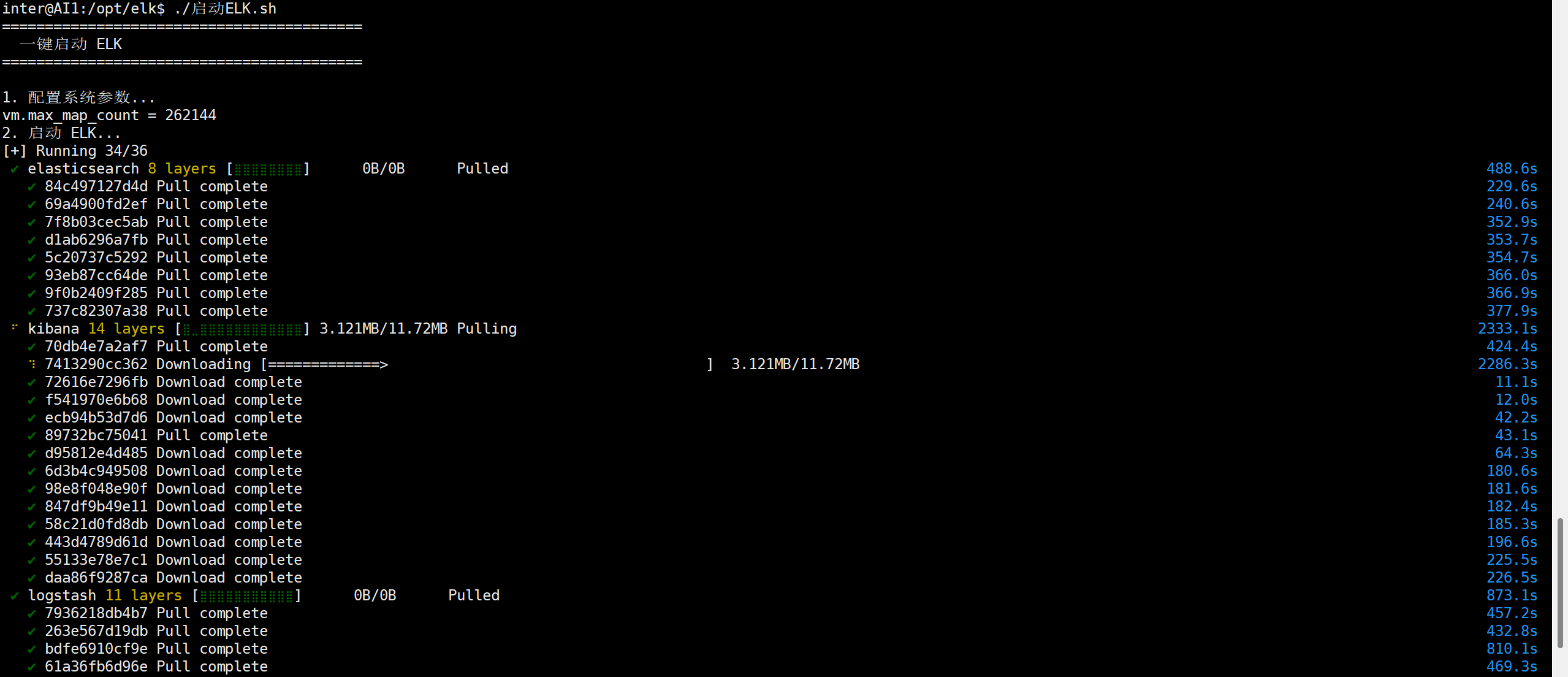
执行完毕,如下图所示
镜像默认是去docker hub,这个镜像仓库进行拉取,如果因为网络原因,拉取镜像失败了,可以尝试通过修改docker的默认镜像仓库地址,换成国内的一些镜像仓库,可以解决这个问题。
具体操作参考文章:
https://blog.csdn.net/liangmengbk/article/details/153920297
小技巧:如果配置了国内的镜像仓库后,下载到某个地方卡住了,然后过了很久都没动静,那就按Ctrl + C,停止本次镜像的拉取,重新执行 ./启动ELK.sh 命令,会接着上次继续下载没有完成的镜像。
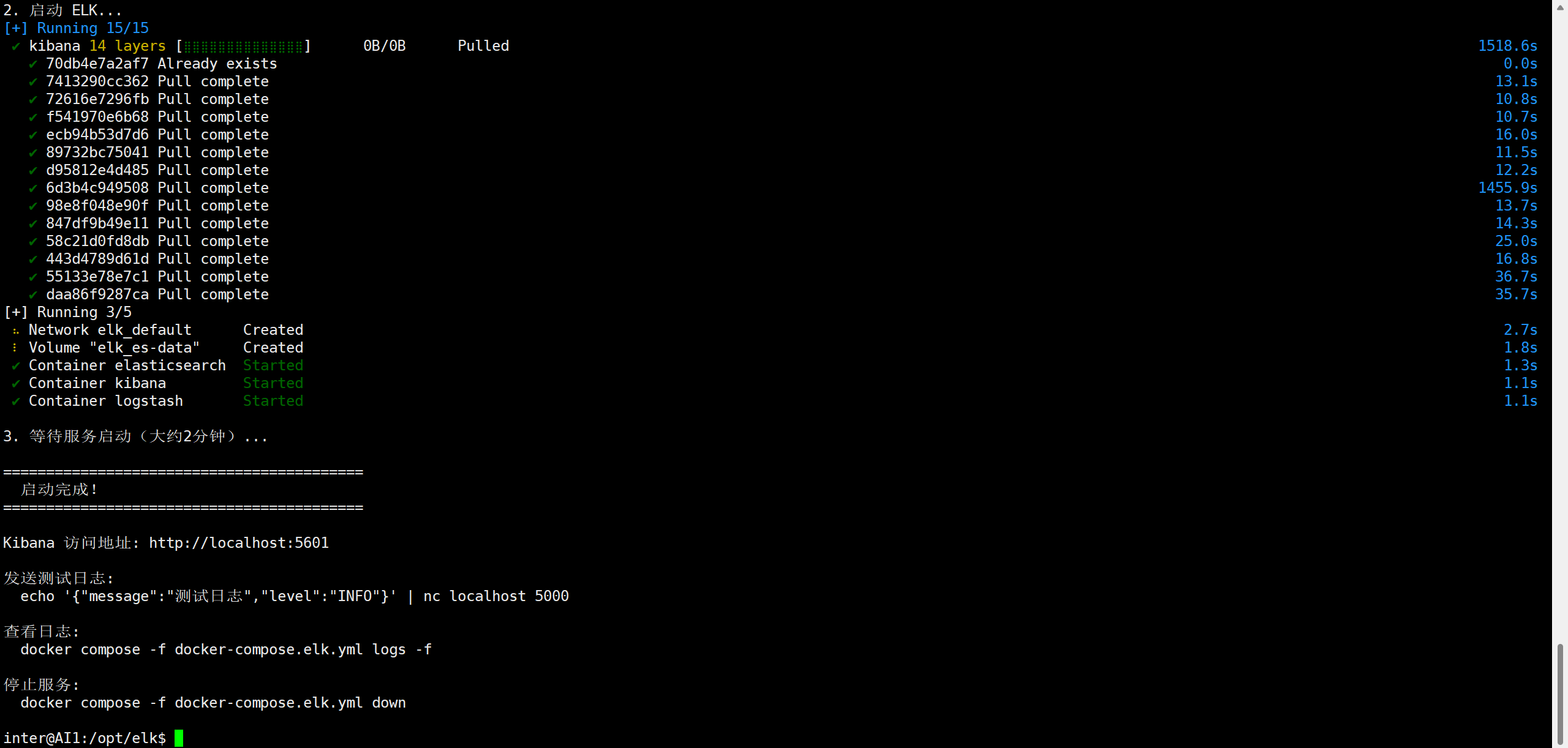
查看启动状态
查看容器状态
docker compose -f docker-compose.elk.yml ps
或查看实时日志
docker compose -f docker-compose.elk.yml logs -f
三个容器都启动成功,如图所示:

验证服务是否就绪
测试 Elasticsearch(等1-2分钟后)
测试 Kibana(等1-2分钟后)
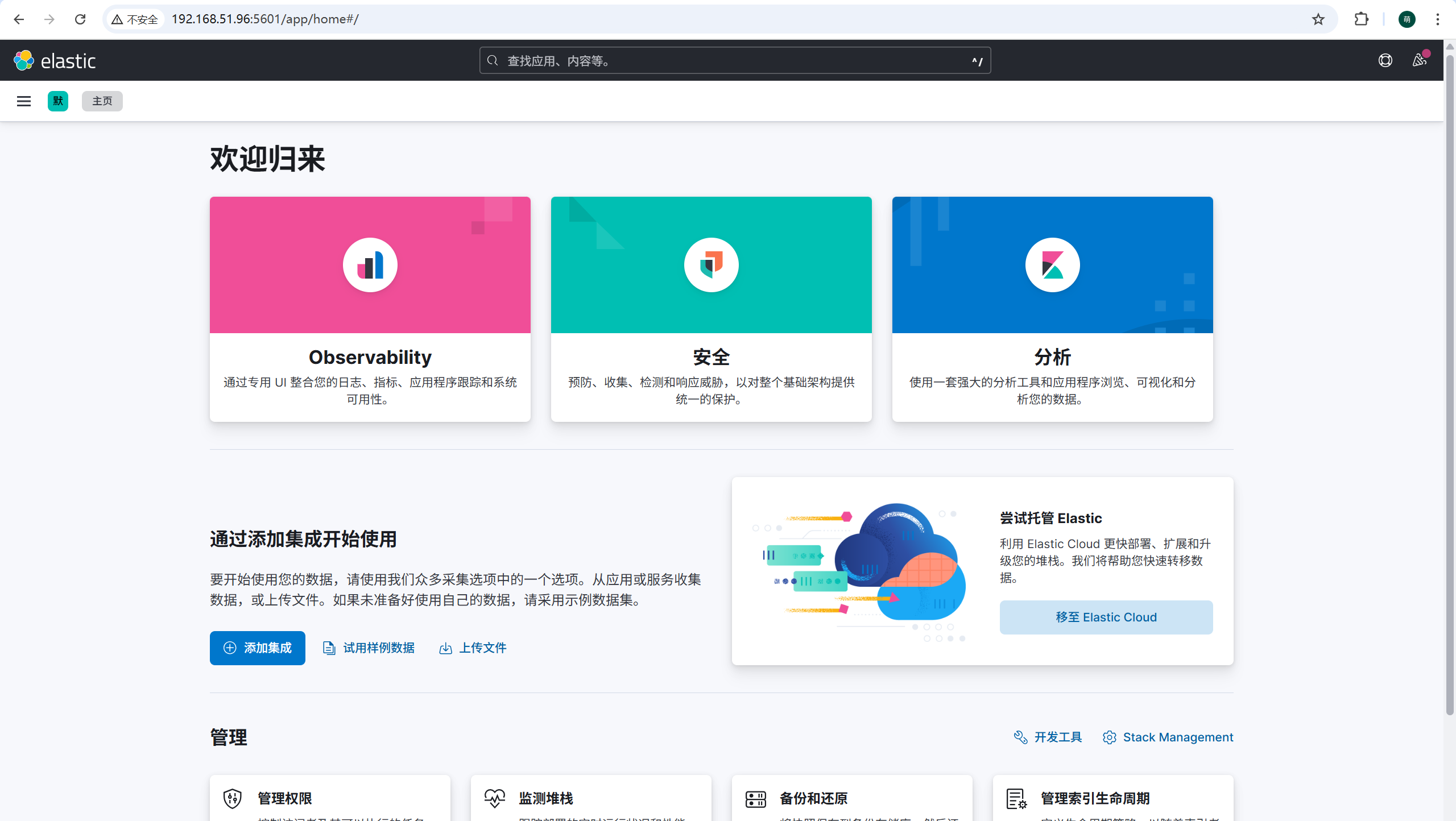
访问 Kibana
linux服务器的IP+5601端口进行访问,例如:
常用管理命令
停止服务
docker compose -f docker-compose.elk.yml down
停止并删除数据
docker compose -f docker-compose.elk.yml down -v
重启服务
docker compose -f docker-compose.elk.yml restart
重启单个服务
docker compose -f docker-compose.elk.yml restart elasticsearch
docker compose -f docker-compose.elk.yml restart kibana
docker compose -f docker-compose.elk.yml restart logstash
查看日志
所有服务
docker compose -f docker-compose.elk.yml logs -f
单个服务
docker compose -f docker-compose.elk.yml logs -f elasticsearch
docker compose -f docker-compose.elk.yml logs -f kibana
docker compose -f docker-compose.elk.yml logs -f logstash
查看资源占用
docker stats
ELK使用
通过应用程序,向Logstash发送日志信息,再通过Kibana查看日志。
以Java的spring boot项目为例,演示ELK的具体使用。
下载项目
通过下面的地址,可以直接下载已经创建好的spring boot项目
https://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/it300/download/203.zip
代码中核心内容说明
在pom.xml文件中的logstash-logback-encoder依赖是很重要的,有了它之后,就可以自动向Logstash进行日志的推送。
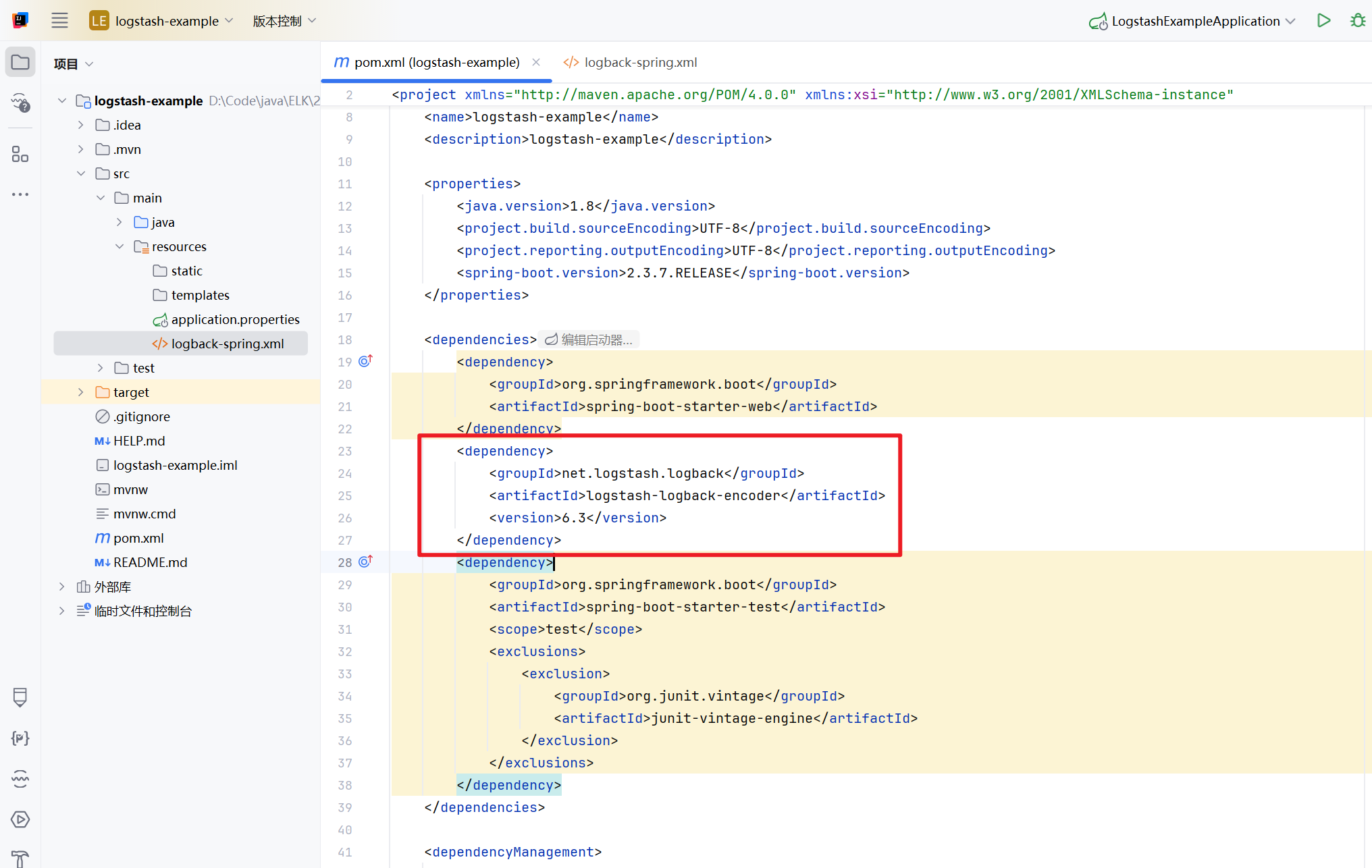
logback配置文件,这个配置文件用来说明日志往哪里进行推送和一些配置
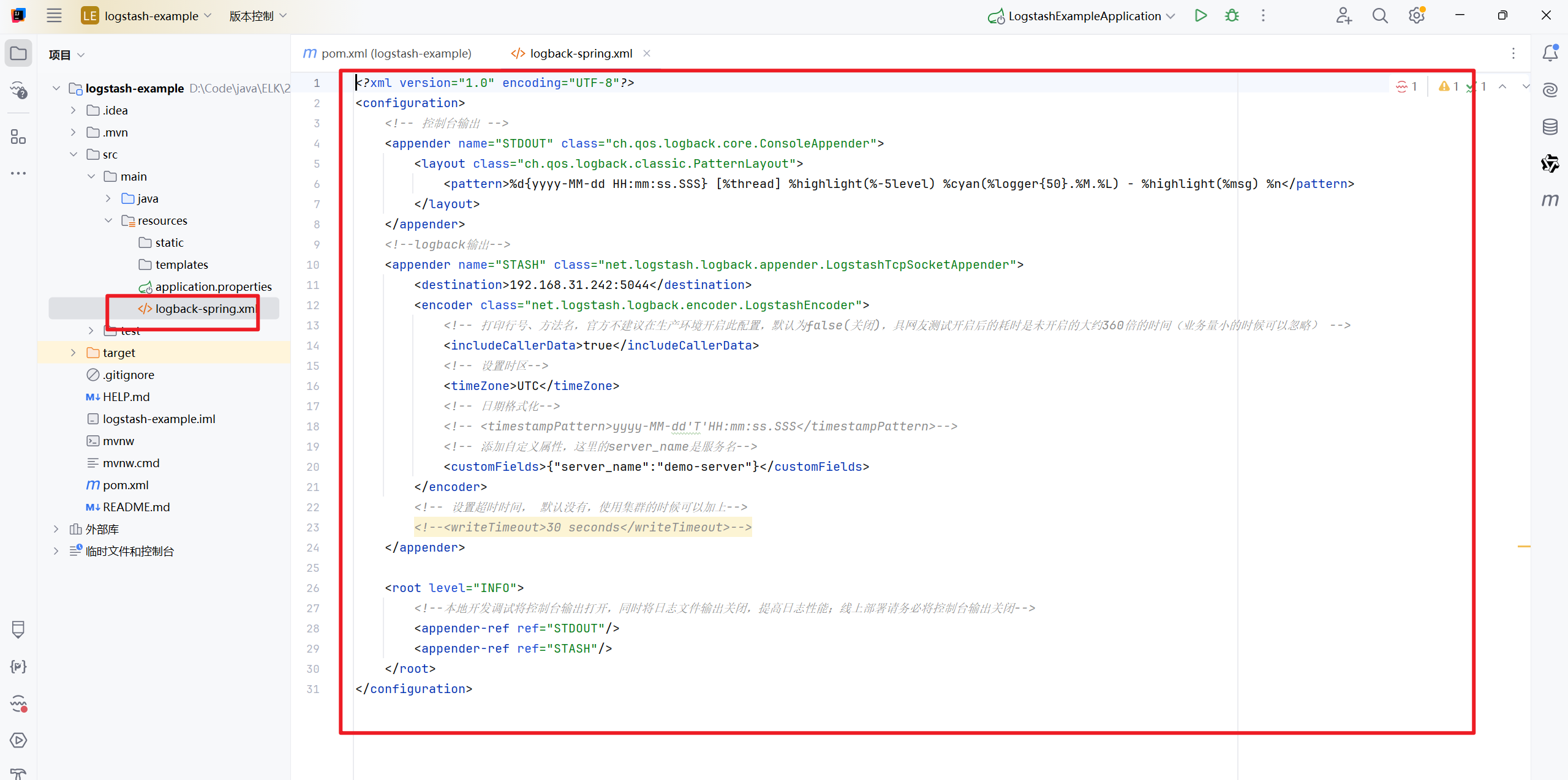
注意destination配置的值,表示logstash服务的地址和端口,需要改为自己的IP,端口是5000
启动spring boot应用
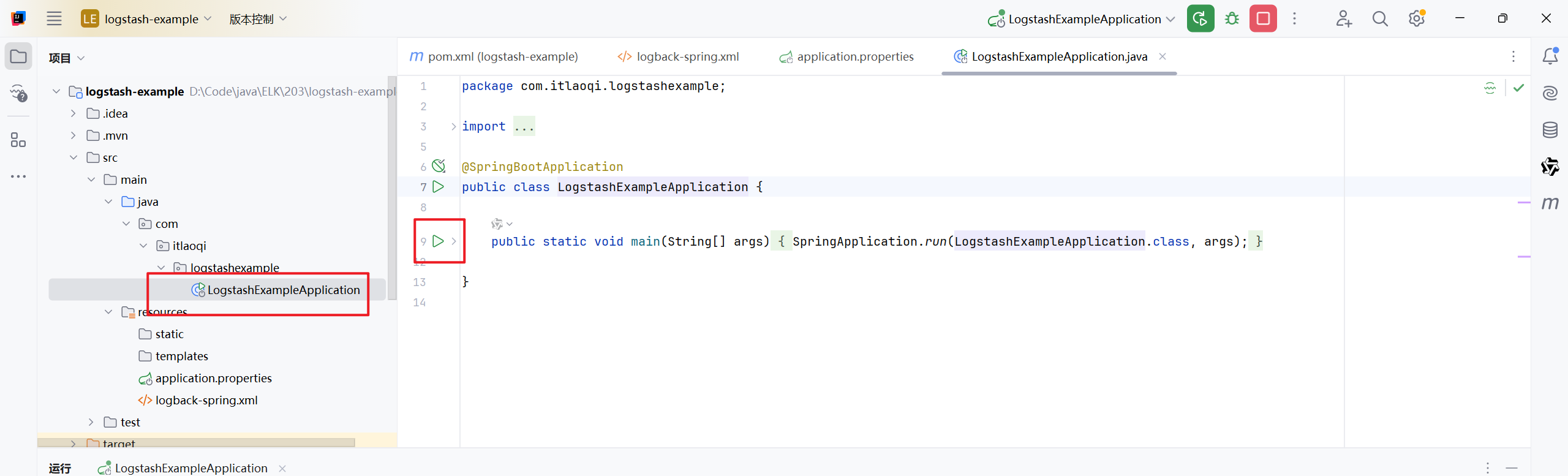
启动成功,控制台会输出一些日志信息
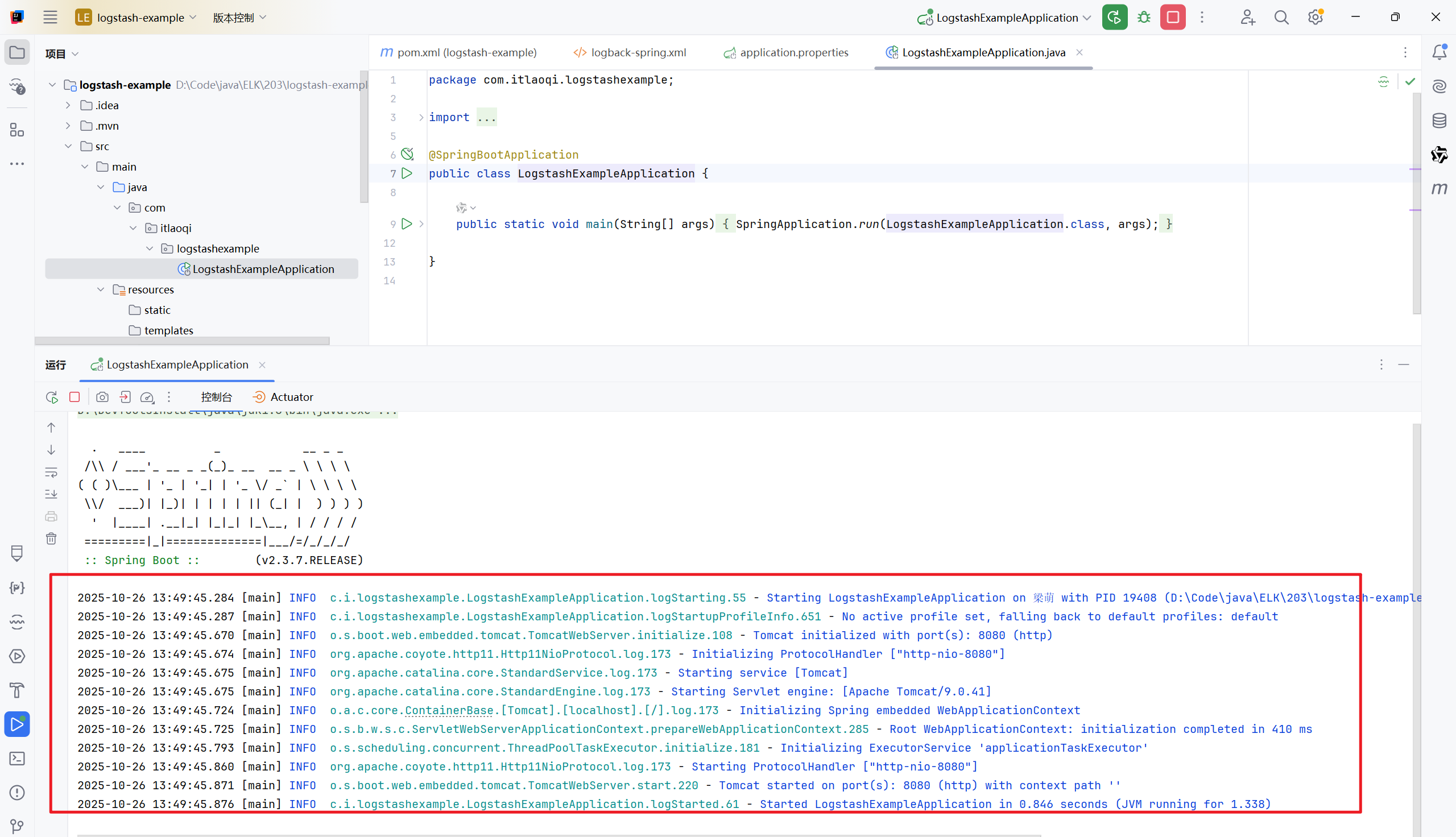
这些日志会通过配置的logback,自动推送到Logstash服务。
在Kibana中查看日志
可以看到三个组件都正常加载了
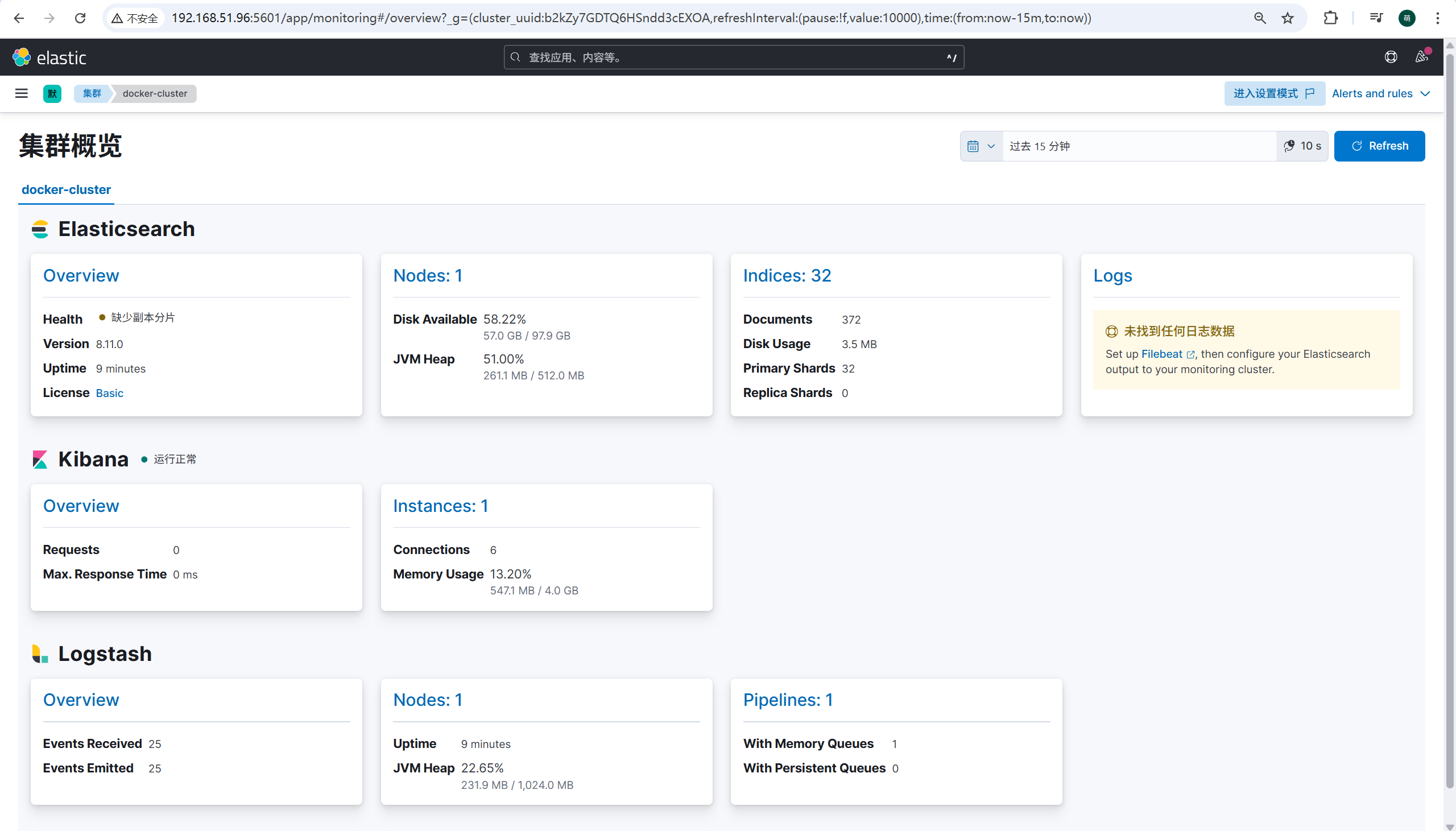
通过堆栈管理,可以 看到日志文件的 信息
找到索引管理
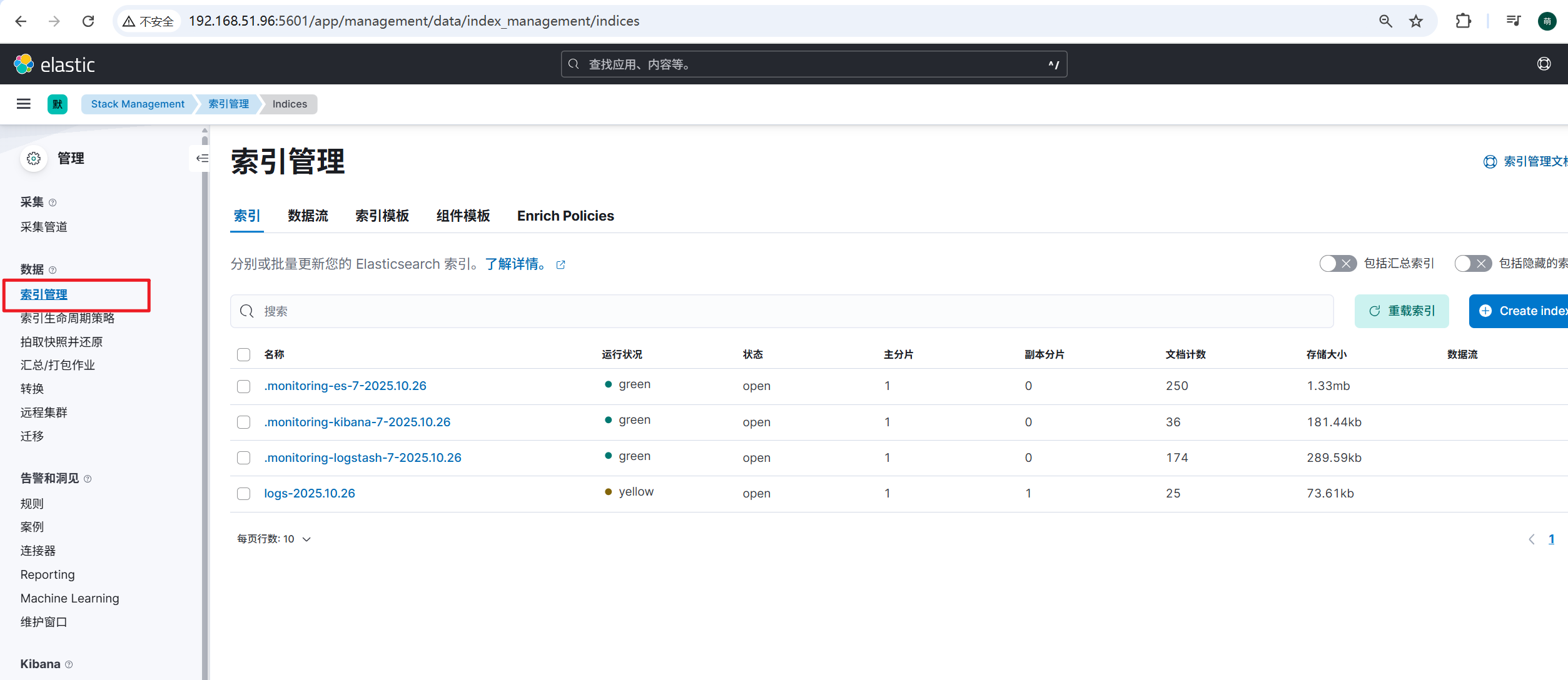
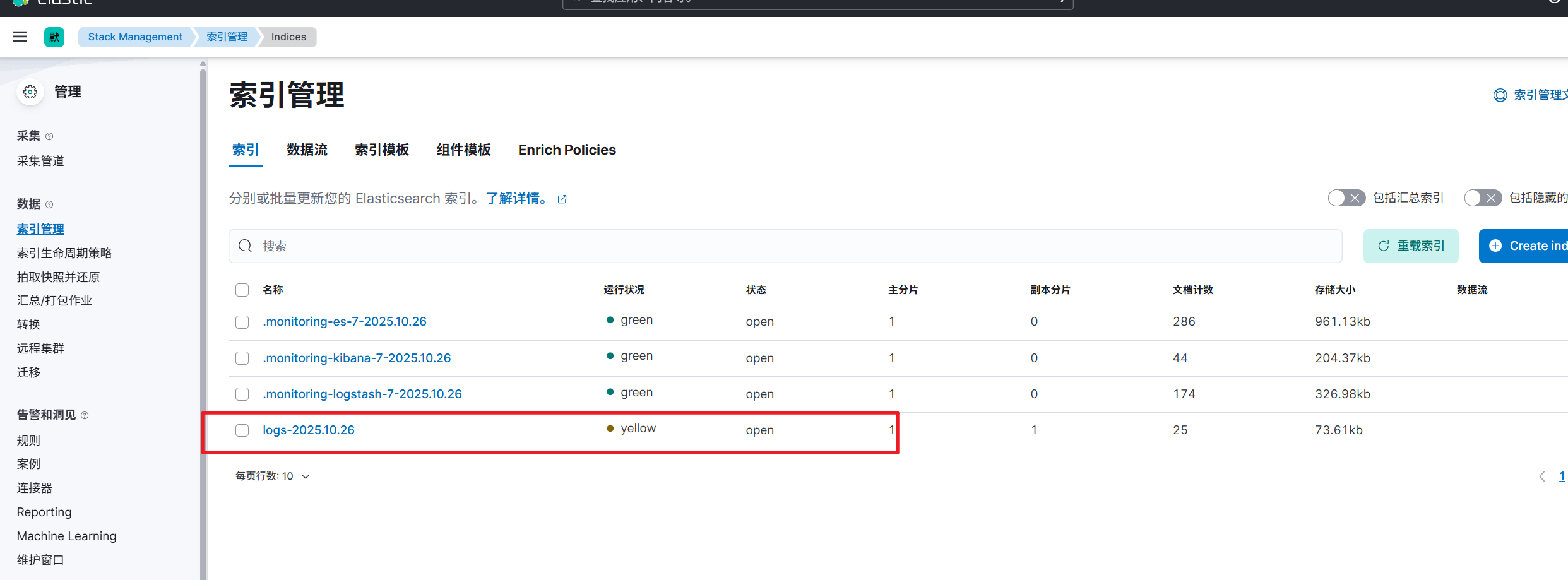
log这条记录,就是spring boot应用产生的日志信息
下面查询具体的日志信息
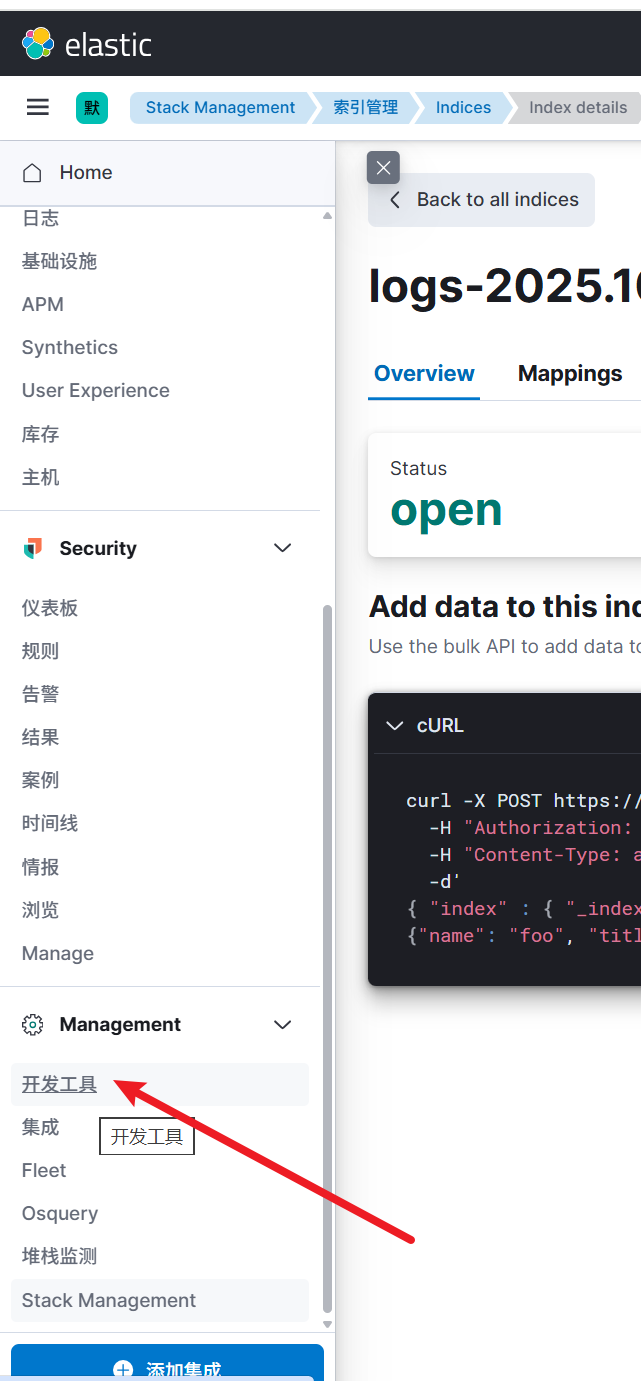
开发工具可以帮助我们进行日志的筛选。例如下面的查询,代表找出logs-2025.10.26索引文件中,级别为INFO的信息,按照时间进行倒序查询。
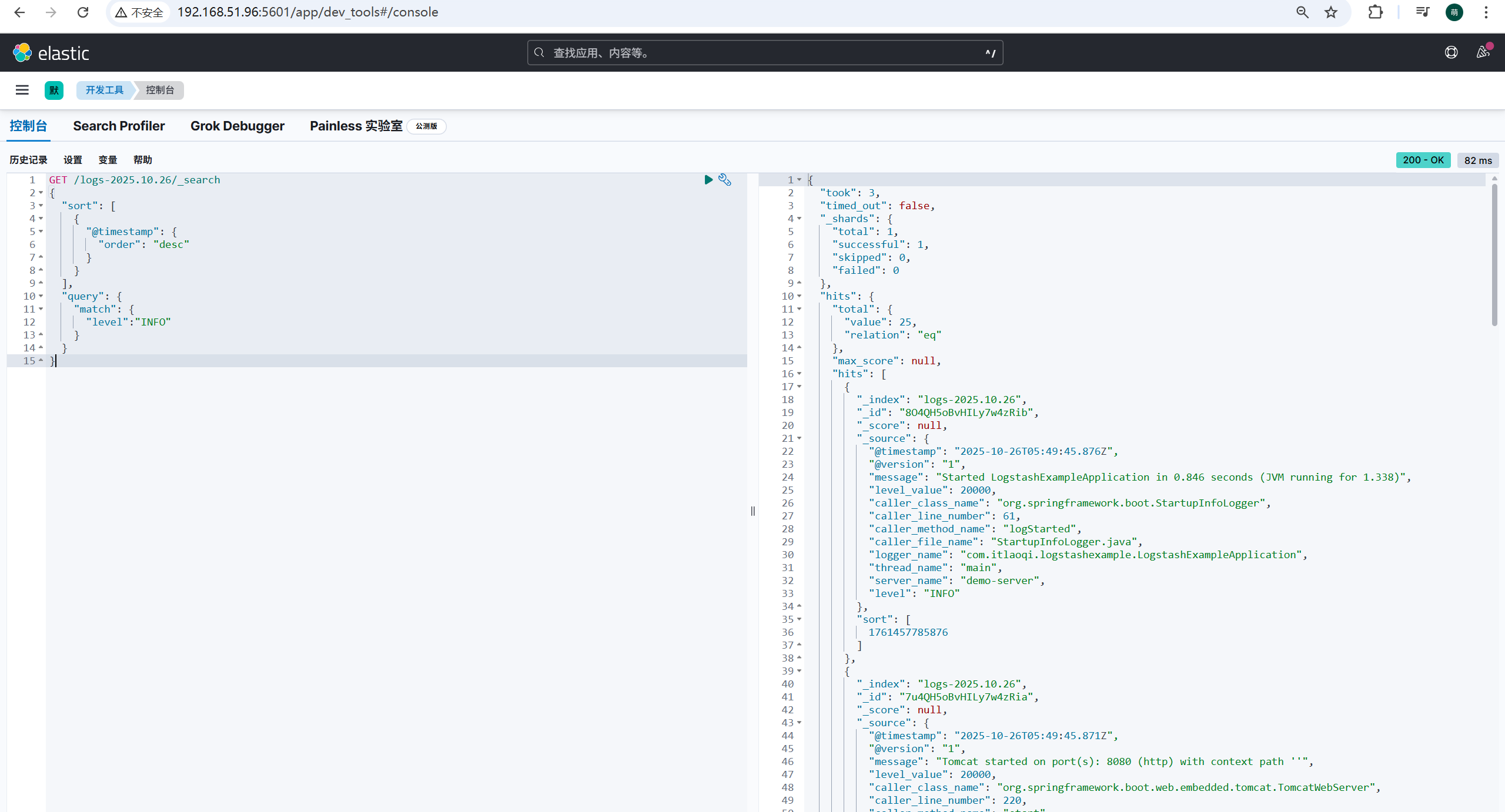
GET /logs-2025.10.26/_search
{
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
],
"query": {
"match": {
"level":"INFO"
}
}
}
可以看到查询出来的日志信息跟idea控制台输出的信息格式不一样,这是因为日志信息被客户端的logstash-logback-encoder插件,进行了分门别类的整理。
再举个查询的例子,比如查询出message中包含'梁萌'关键字的信息
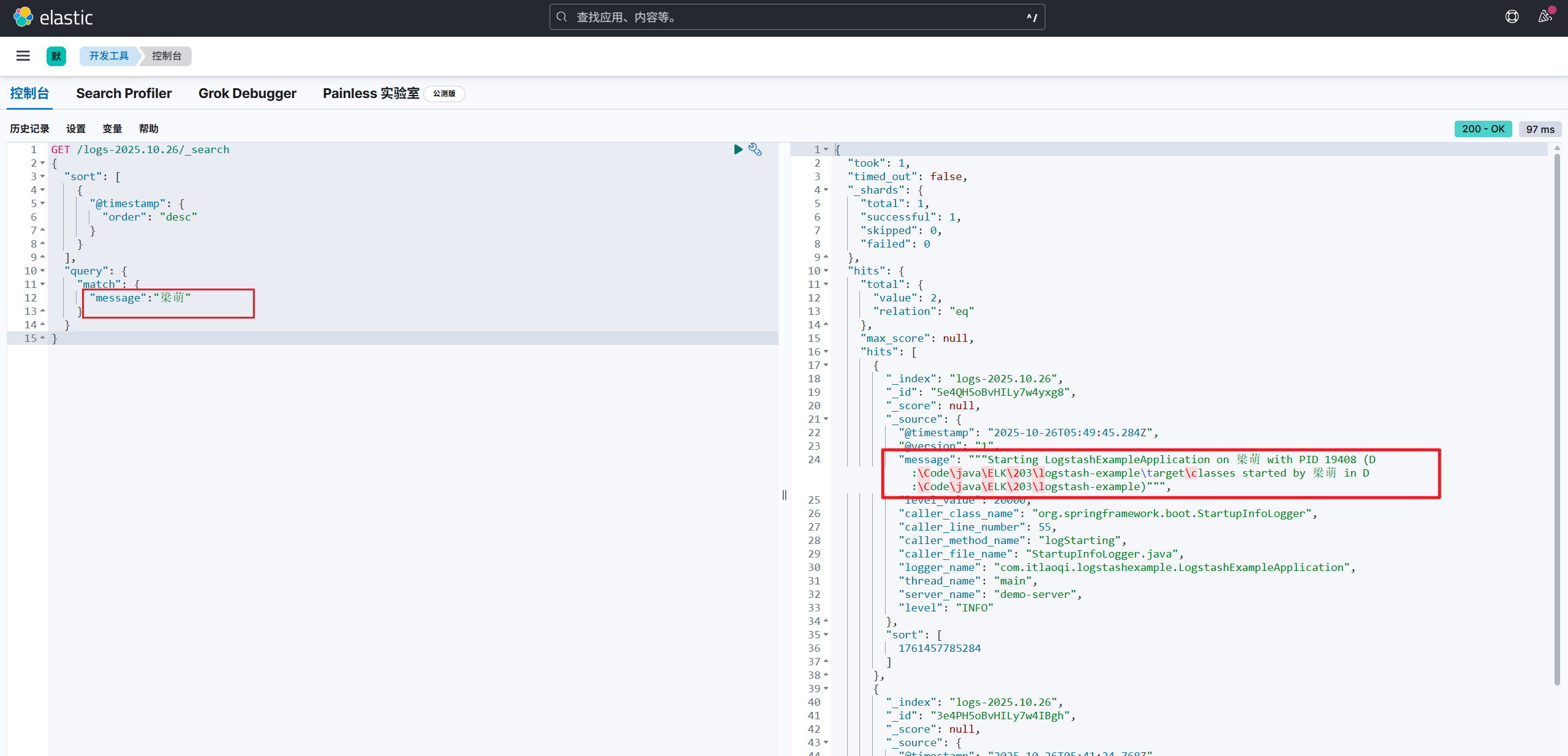
到此为止,从ELK的搭建到使用,已经完成了。