一天下午正在愉快的写代码,组长走过来打开了系统的一个功能,跟我说这个玩意查询要18秒,忍受不了啊,最主要它还引发了其它问题,所以让我想办法解决,那我就排查一下吧.
直接从前端找到接口,定位到相应的接口,这个接口很简单里面就一些简单逻辑然后调用mapper层的一个方法最终返回数据给前端,那这样直接拿这个sql跑一下就知道了
把where条件给干掉之后,limit100条先看看什么情况先
好家伙给干出了34秒,妥妥的慢sql了,先看看具体的sql
sql
SELECT
DISTINCT
i.*,
csc.suit_sku_image,
(
SELECT
string_agg (sort_name, ',')
FROM
commodity_info_sort k
JOIN commodity_sort k1 ON k.sort_id = k1.id
WHERE
k.info_id = i.id
) AS "type",
(
SELECT
SUM(CASE WHEN csgd.sales_type = '1' THEN csgd.amount ELSE 0 END)
FROM
commodity_store_goods_detail csgd
WHERE
csgd.info_id = i.id
) AS "total_amount_sale_type_1",
(
SELECT
SUM(CASE WHEN csgd.sales_type = '0' THEN csgd.amount ELSE 0 END)
FROM
commodity_store_goods_detail csgd
WHERE
csgd.info_id = i.id
) AS "total_amount_sale_type_0",
(SELECT ci.name FROM commodity_info ci WHERE ci.id = i.from_where) AS "infoname",
(SELECT ci.main_image FROM commodity_info ci WHERE ci.id = i.from_where) AS "infomainImage"
FROM
commodity_info i
LEFT JOIN commodity_package_relationship cpr ON cpr.info_id = i.id
LEFT JOIN commodity_suit_compose csc ON csc.only_info_id = i.id
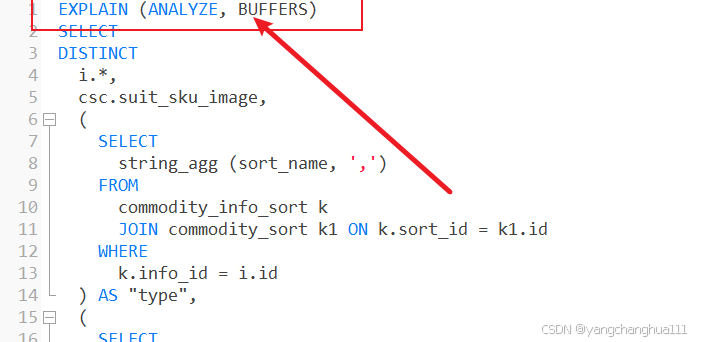
-- limit 10一眼看过去已经觉得这个sql绝对不会快了,有 DISTINCT ,有5个子查询,其实有两个还是针对该sql的主表的,不管三七二十一跑个执行计划看看我们用的是pgsql所以我是这样跑的
用关键字 EXPLAIN
优先看有没有 Scan on 全表扫描的
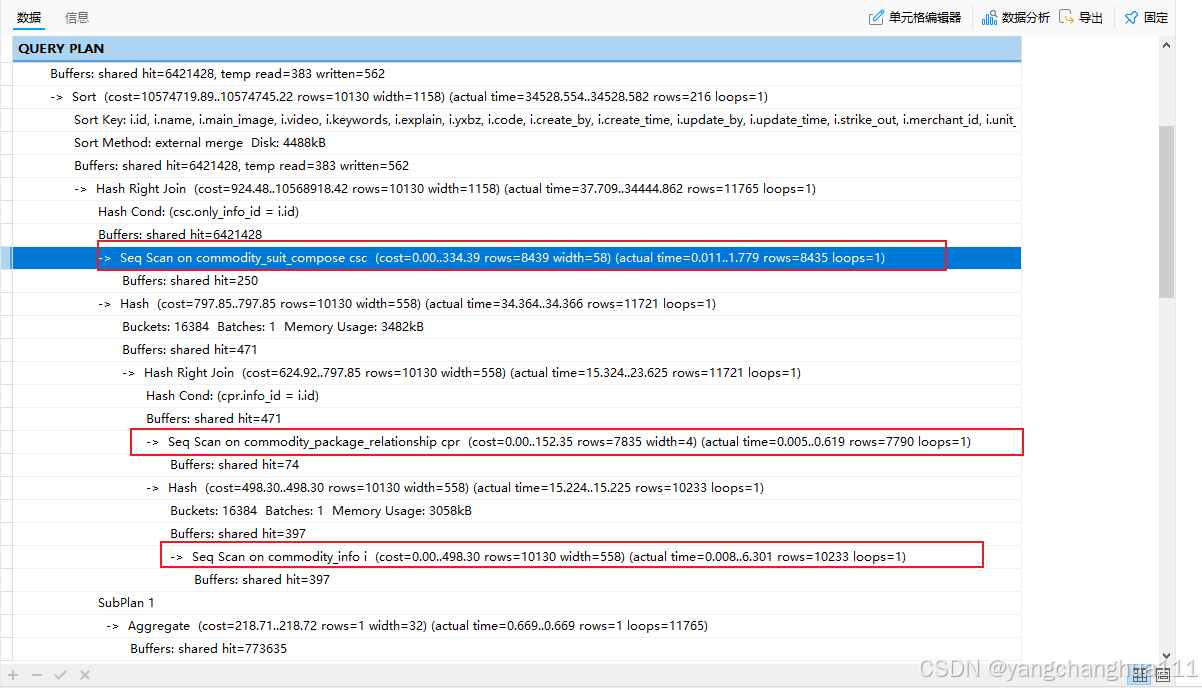
根据上图的执行计划可以看到这三张表都走了全表扫描,原以为问题就在这里了,但是一看消耗才这么一点,那肯定不是这个了,继续往下看,再看 相关子查询 SubPlan,不看不知道一看吓一跳
第一个子查询
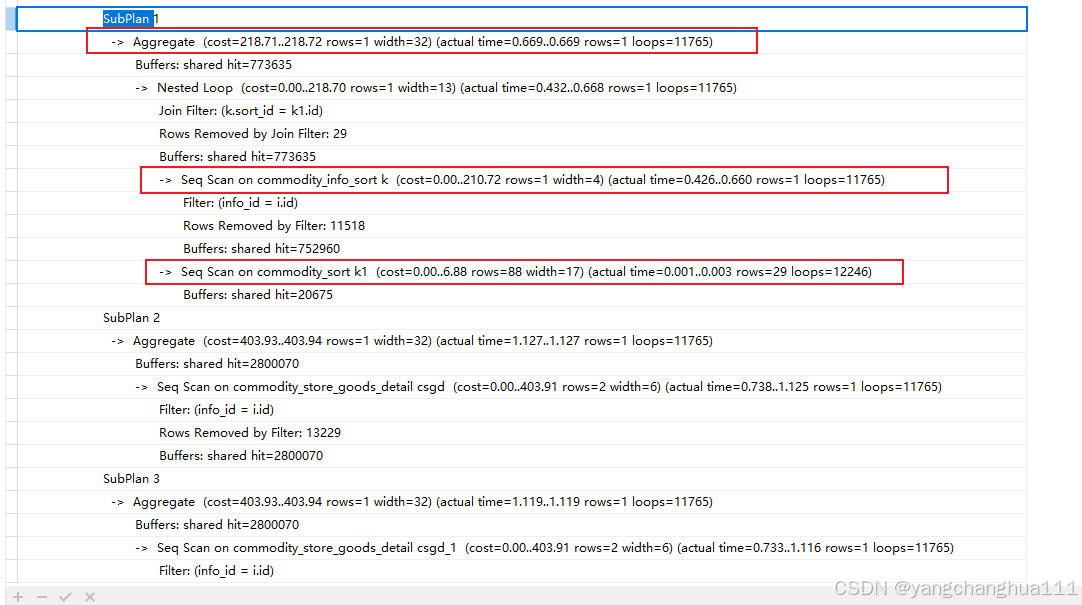
我们根据第一行 Aggregate可以看出 每次返回 1行(rows=1)消耗时间0.669毫秒(actual time=0.669)姑且算0.7毫秒,然后
loops=11765 也就是被执行了11765次,一次就是0.7毫秒,11765次就是11765x0.7=8,235.5毫秒
换算成秒也就是8秒钟,一个子查询就8秒钟了能不慢嘛.
问题来了,为什么慢呢?
往下看 ,嵌套循环连接 ,条件是 k.sort_id = k1.id
-> Nested Loop (cost=0.00..218.70 rows=1 width=13) (actual time=0.432..0.668 rows=1 loops=11765)
Join Filter: (k.sort_id = k1.id)
Rows Removed by Join Filter: 29
排除了29条数据这里看不出太多东西不过也可以根据Join Filter看出这个连接没有走索引
继续往下看,重点来了
-> Seq Scan on commodity_info_sort k (cost=0.00..210.72 rows=1 width=4) (actual time=0.426..0.660 rows=1 loops=11765)
Filter: (info_id = i.id)
Rows Removed by Filter: 11518
Seq Scan on全表扫描,条件是info_id = i.id
说明一下i.id是最外层的主表的id,
意味着外层主表的每一行数据都跟这个子查询里面的每一行数据都去查询了是不是=.
所以他的查询次数就变成N × M
id是天然的索引,这里没有走索引的话可以看看commodity_info_sort的 info_id 字段是不是没有创建索引.创建了索引我感觉这里会快一大半
Rows Removed by Filter: 11518 这个意味着在扫描的过程中有11518是不符合要求被过滤掉的,说明每次扫描读取了很多不相关行,每次都要遍历大量行,只留下极少数匹配,重复 11,765 次 极其低效
到现在答案呼之欲出了,下面的几个子查询也是如出一辙,都是耗时大户
2025.10.28排查记录先写到这里,后面花时间继续写改造这个sql的过程