目录
[1.policy gradient A](#1.policy gradient A)
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是policy gradient中评价A的定义及计算方法,训练过程中需要注意的问题和exploration的概念
1.policy gradient A
控制actor的行为,重点在我们如何定义A
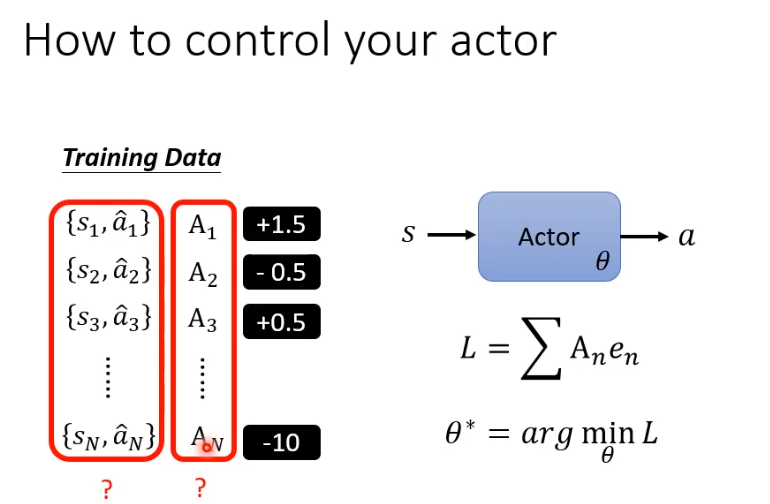
先用一个最简单但不正确的方法帮助理解,收集到足够多的s和a的资料后,用A对他们进行评价,将reward作为A的评价,reward为正就希望偏向做这样的行为,为负就不希望做这样的行为。
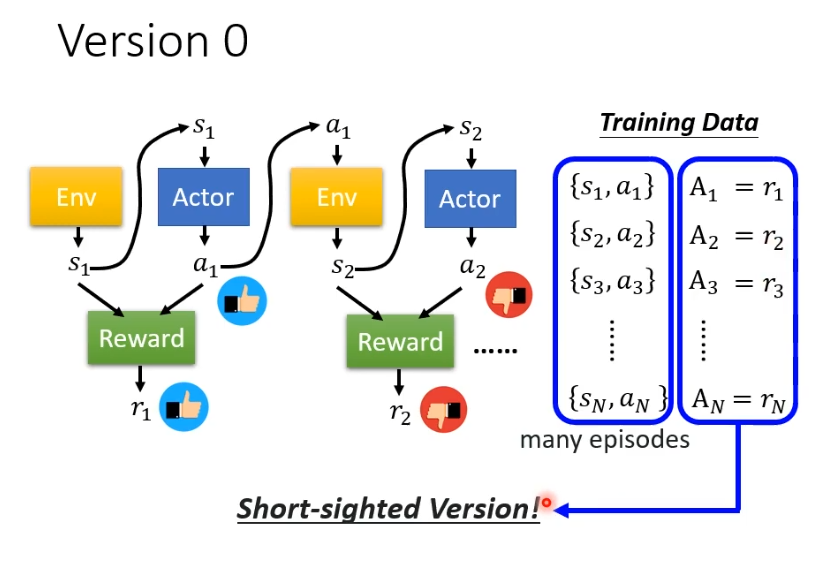
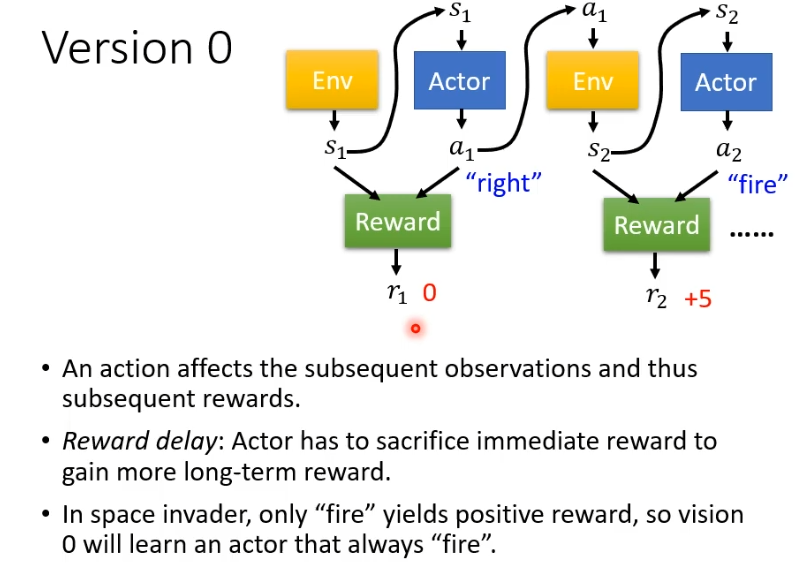
但这样训练得到的actor并不好,因为我们可能需要左右移动之后射击才会得到reward,但是左右移动的reward为0,这并不代表左右移动不重要。如果照这样训练,得到的actor只会开火。
正确的做法是,a1有多好不取决于r1而是取决于r1之后的所有r,把他们加起来得到一个数值G1,把G1作为A,A2,A3以此类推。
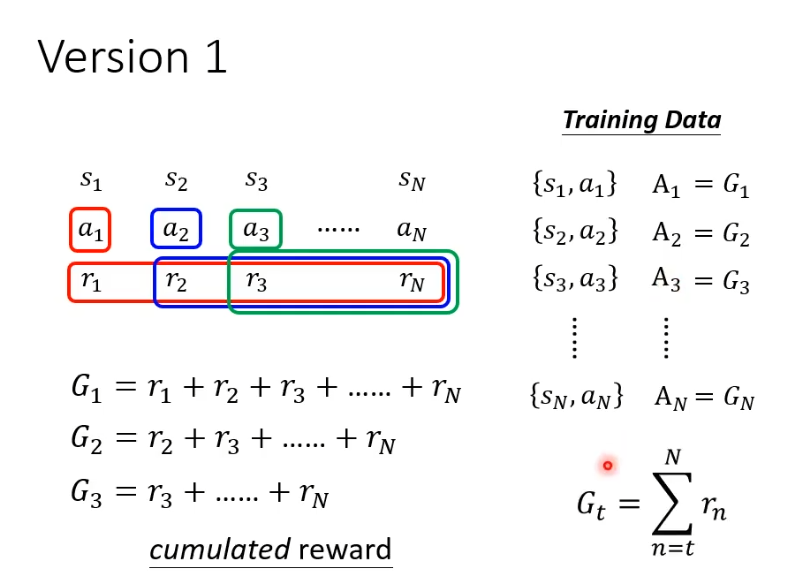
当游戏非常长时,a1的影响力可能并不会影响到全部reward,因此对G进行改进得到G',在之后的r增加系数,每到下一个就多乘一次系数
,这样越远影响力就越小。

但好或坏是相对的,可能所有的行为得到分数都是正的,就会导致有些不好的行为,仍然鼓励actor去做,因此需要做标准化,还需要让所有的G'减去一个baseline B,目的是为了让A有正有负。

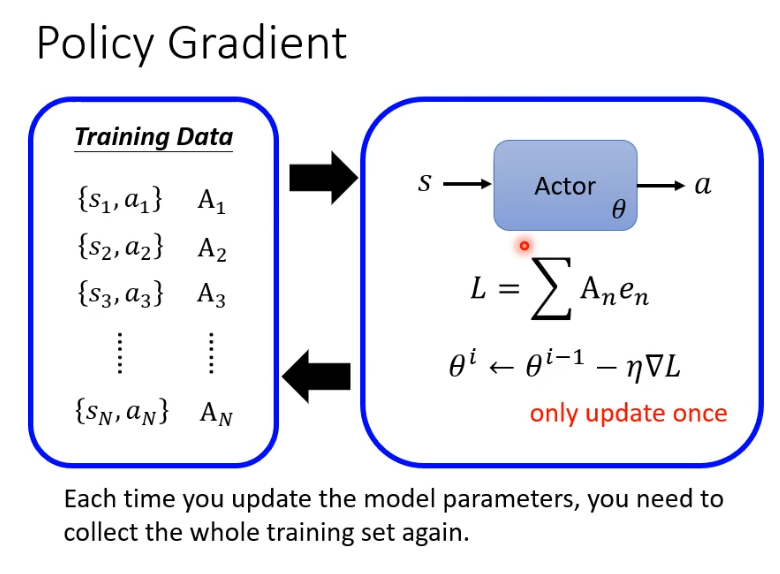
整个过程总结一下,首先需要定义初始参数,假设训练T轮,用actor与环境互动得到s和a,计算评价A,计算loss去更新参数。

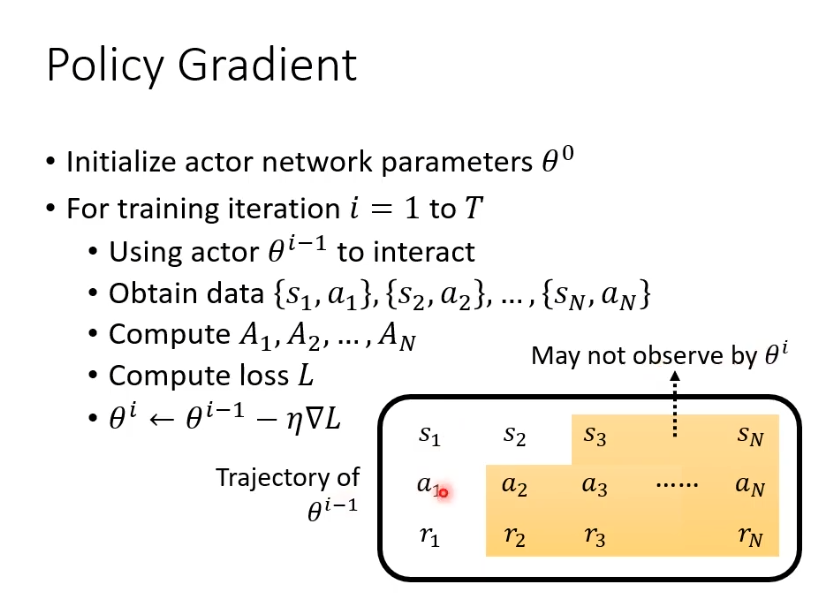
复杂的是收集资料在循环内,也就是我们每一次更新参数都需要重新收集资料,每次收集的资料只能更新一次参数。
出现这样状况的原因是,每一轮的行为不同。假设第i轮和第i-1轮他们在s1都会采取a1,但是在s2时他们采取的行为就不一样了,所以一轮的资料只能训练一次。
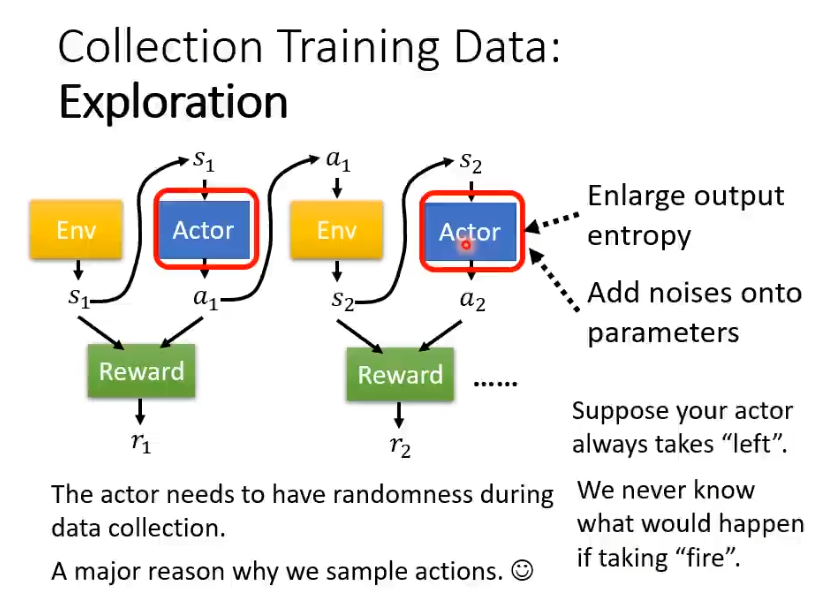
2.exploration
actor执行行为是需要一定的随机性的,随机性不够可能会导致无法训练起来。假设actor只会向右移动,从来不知道开火,如果它从来不开火就永远不会知道开火这件事情是好还是不好。所有在训练过程中,是需要一定的随机性的,这样才能收集到更多的资料。为了加大随机性,可能会主动采取一些行为,比如刻意加大输出的entropy或者在参数上加入噪声让actor每次的行为都不一样,这就是exploration。