同事使用Alter语句变更了Hive分区表的字段长度,发现历史分区的字段长度没有被改变,查百度,问AI也没问出个所以然,问我是怎么回事。
这让我联想起了之前建表没有定义列分隔符,导入数据之后查询出来都是Null值,查看Hadoop的上存储的数据,发现数据都在,很显然hive根据建表时的定义去拆分数据,没有指定列分隔符hive就懵逼了。基于这个经验,猜想hive会根据存储的元数据去展示不同的分区下的数据。
基于这个猜想准备试验数据,创建日期表test01,只有一个字符串类型的字段,长度为2:
sql
DROP TABLE IF EXISTS test01;
--创建表
CREATE TABLE IF NOT EXISTS test01(
col1 VARCHAR(2) COMMENT '列1'
)COMMENT '测试用表'
PARTITIONED BY (BATCH_DATE VARCHAR(10))
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS textfile
;导入数据:
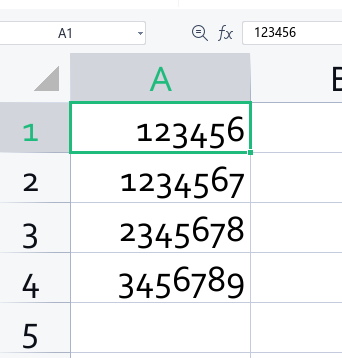
sql
load data local inpath '/home/tim/test01.csv' into table test01 partition(batch_date='2025-10-08');hive查询数据如下:
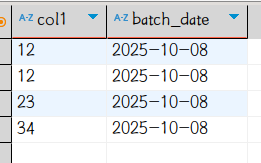
Hadoop文件内容:
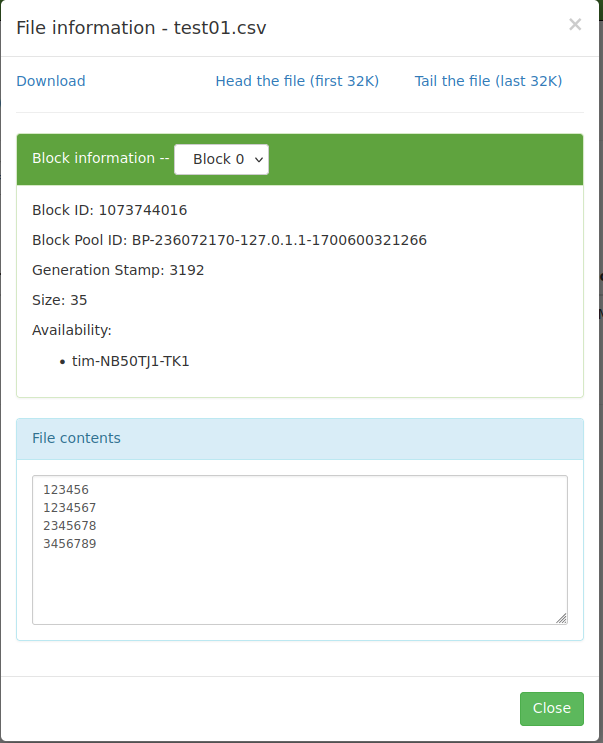
可见Hive确实是依据DDL的定义截断并"展示"数据。
接下来使用Alter语句将字段扩增至4位长度并将同样的数据插入下一日分区,并查看数据
sql
alter table test01 change col1 col1 varchar(4);
load data local inpath '/home/tim/test01.csv' into table test01 partition(batch_date='2025-10-09');
select * from test01;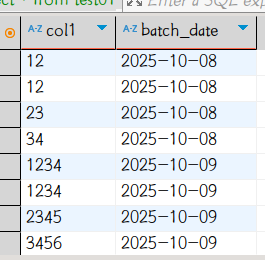
到此已经复现了同事遇到的问题,重复上面操作,使用Alter语句将字段扩增至10位长度并将同样的数据插入下一日分区,并查看数据:
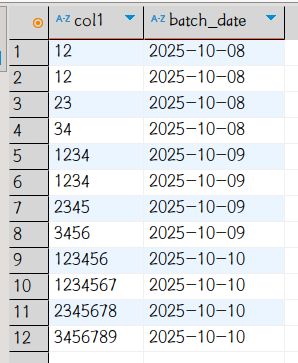
可以看到问题依旧。使用下列语句MySQL查询元数据库
sql
/*查看分区,列名,类型名*/
select t1.SD_ID ,t1.CD_ID ,t1.LOCATION ,t2.COLUMN_NAME ,t2.TYPE_NAME from hive.sds t1 join hive.columns_v2 t2 on t1.CD_ID =t2.CD_ID
where COLUMN_NAME='col1'可以看到:

分区表的每个分区和表自身都被记录了一个历史长度,hive根据元数据解释(展现)存储的数据,超过长度的就被截断了。
外网回答这个时候需要在Alter语句后面加cascade关键字,才能把分区的元数据一起改了。
sql
alter table test01 change col1 col1 varchar(10) cascade;然而执行了并没有什么用:元数据还是那样。经过实验发现,先扩增到比任何分区都长的精度,然后再调回来即可,可能是个Bug吧
先执行alter table test01 change col1 col1 varchar(200),表级的长度是200了,分区级的还是不变。

再执行alter table test01 change col1 col1 varchar(10) cascade,所有分区的字段长度就都统一了。
