此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第二课第一周,1.8的内容。
本周为第二课的第一周内容,就像课题名称一样,本周更偏向于深度学习实践中出现的问题和概念,在有了第一课的机器学习和数学基础后,可以说,在理解上对本周的内容不会存在什么难度。
当然,我也会对一些新出现的概念补充一些基础内容来帮助理解,在有之前基础的情况下,按部就班即可对本周内容有较好的掌握。
本篇继续上篇的内容,在完成正则化部分后,再补充一些课程里提到的其他缓解过拟合的方法。
1.数据增强
之前提到解决过拟合最好的方法就是增加数据量,但受限于各个方面有时获取新数据并不容易。
因此,就出现了数据增强,数据增强并不是引入新数据 ,而是以一些方式增强现有数据 ,到达"丰富数据集"的效果。
什么方式?看一眼就明白了:
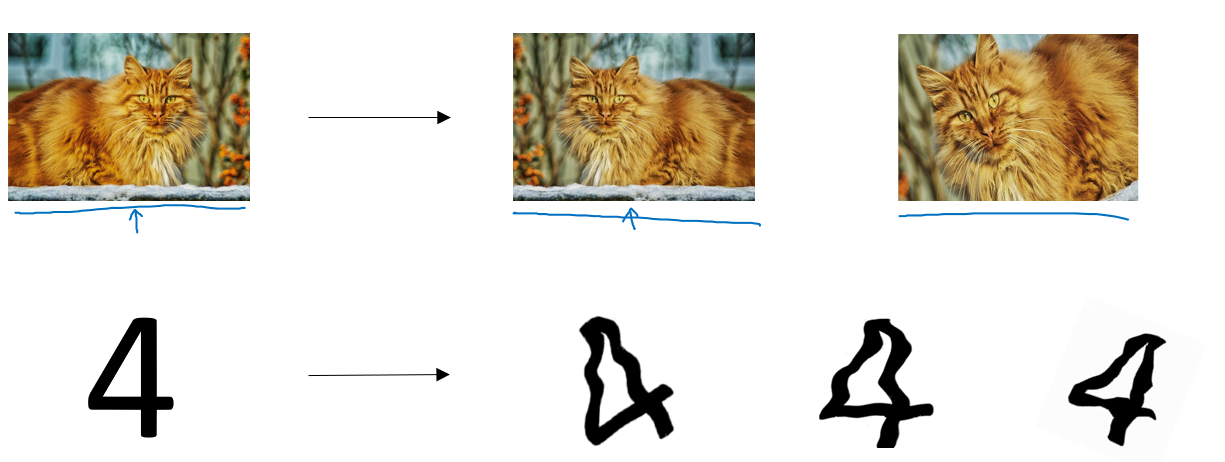
我们可以对图像进行翻转、裁剪、旋转、模糊、亮度变化 等处理。虽然这些样本并没有提供全新的信息,但它们能让模型学习到更广泛的特征变化。
这样的操作看起来有些取巧,但也确实能做到一些查漏补缺,配合正则化有时能实现不错的效果。
简单举个例子:上图里的猫,我们对其处理后并不能提供太多新信息,从高维上讲,模型依旧拟合的是橘猫的模样,但是反转,裁剪后,我们可以改变猫头的位置,在图中的比例。或者在模糊后训练模型的"视力"。模型可以学会识别"同一类目标在不同条件下的表现",起到丰富低维特征的作用。
要强调一点的是,课程中提到,数据增强也可以被称为一种正则化方法。
2.早停(early stopping)
我们再回顾一下过拟合,在训练神经网络时,我们常常会遇到这样一种现象:
模型在训练集上的损失不断下降,但在验证集上的性能却在某个时刻开始变差------也就是说,模型开始记住训练数据的噪声 ,出现了过拟合 。
"早停"正是针对这一问题的一种简单而有效的策略。
早停的核心思想是:当模型在验证集上的表现不再提升时,就提前停止训练,而不是一味追求训练损失的最小化。
换句话说,我们不让模型在训练集上"学得太好",而是在它刚开始出现过拟合的拐点提前终止,让模型保持在一个"泛化性能最好"的状态。
通常的做法是:
- 在每一轮(epoch)训练后,计算模型在验证集上的损失;
- 如果验证集损失在连续若干轮(称为耐心值 patience)中没有显著改善,就停止训练;
- 最后保留验证集效果最好的那一轮的模型参数。
如图所示:
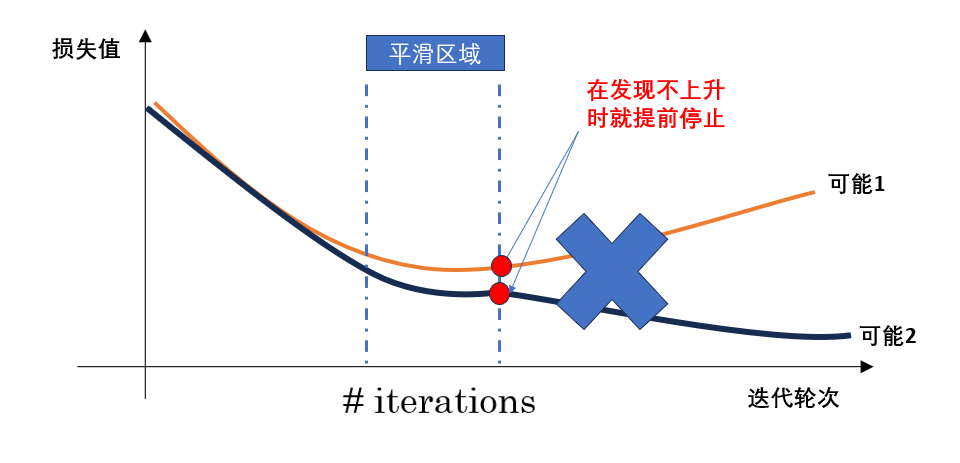
总的来说,早停的优点在于它能在验证集性能开始下降前及时停止训练,从而有效防止过拟合,并节省训练时间;实现起来也十分简单。
但它也有不足------如果停止得太早或验证集波动较大,模型可能还没学到足够的特征就被迫中断,导致欠拟合 ;同时,早停依赖验证集的表现,可能带来一定的不稳定性。
本篇内容不多,加上前两篇,这部分内容总结了一些帮助缓解过拟合的方法,涉及到一些新的概念,因此花费了一些篇幅来帮助理解,之后的内容在理解上的难度就没有这部分高了,进度也会快一些。