目录
[1 作用](#1 作用)
[2 代码](#2 代码)
[2.1 最大/平均池化层](#2.1 最大/平均池化层)
[2.2 填充和步幅](#2.2 填充和步幅)
[2.3 多个通道](#2.3 多个通道)
[3 卷积神经网络算法](#3 卷积神经网络算法)
[3.1 背景](#3.1 背景)
[3.2 LeNet](#3.2 LeNet)
[3.3 AlexNet](#3.3 AlexNet)
[3.3.1 AlexNet架构](#3.3.1 AlexNet架构)
[3.3.2 代码](#3.3.2 代码)
[3.4 VGG](#3.4 VGG)
[3.4.1 VGG块](#3.4.1 VGG块)
[3.4.2 VGG架构](#3.4.2 VGG架构)
[3.4.3 代码](#3.4.3 代码)
[3.5 NiN](#3.5 NiN)
[3.5.1 特点](#3.5.1 特点)
[3.5.2 架构](#3.5.2 架构)
[3.5.3 代码](#3.5.3 代码)
[4 电脑配置查询](#4 电脑配置查询)
[4.1 CPU](#4.1 CPU)
[4.2 内存](#4.2 内存)
[4.3 GPU](#4.3 GPU)
[4.4 所有硬件信息](#4.4 所有硬件信息)
注意:
本章开始需要进行模型复现,硬件设备尤其是GPU性能要求变高,如在复现时出现out of memory(OOM)报错可以采用降低模型参数、使用云服务器、使用CPU训练等方法,详情https://blog.csdn.net/weixin_45728280/article/details/155074452?sharetype=blogdetail&sharerId=155074452&sharerefer=PC&sharesource=weixin_45728280&spm=1011.2480.3001.8118,同时电脑配置查询方法详见本章4。
1 作用
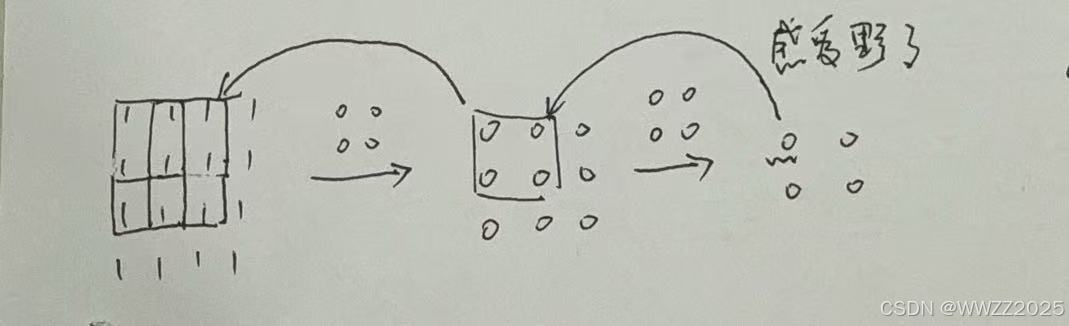
(1)降采样,降低计算量、减少参数;
(2)扩大感受野,捕捉更大结构;
(3)平移不变性,稳定性强;
(4)特征筛选,去噪、保留关键特征。
有最大池化、平均池化,最大池化最常用、保留了区域内最强特征;平均池化会使图像更加柔和。


2 代码
2.1 最大/平均池化层
import torch from torch import nn from d2l import torch as d2l def pool2d(X, pool_size, mode='max'): p_h, p_w = pool_size Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)) for i in range(Y.shape[0]): for j in range(Y.shape[1]): if mode == 'max': Y[i, j] = X[i: i + p_h, j: j + p_w].max() elif mode == 'avg': Y[i, j] = X[i: i + p_h, j: j + p_w].mean() return Y X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]]) pool2d(X, (2, 2)) pool2d(X, (2, 2), 'avg')同卷积层类似。
2.2 填充和步幅
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4)) X pool2d = nn.MaxPool2d(3) pool2d(X) pool2d = nn.MaxPool2d(3, padding=1, stride=2) pool2d(X) pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1)) pool2d(X)

2.3 多个通道
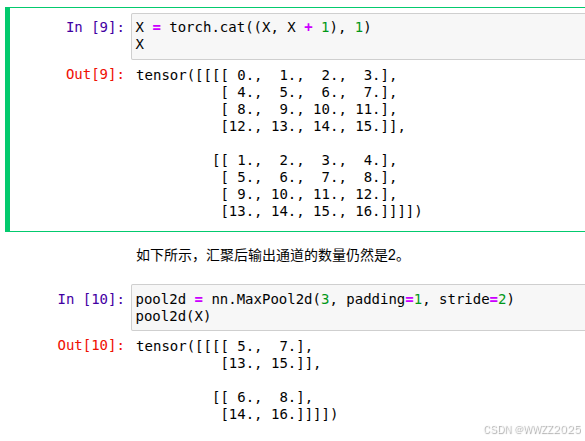
X = torch.cat((X, X + 1), 1) X pool2d = nn.MaxPool2d(3, padding=1, stride=2) pool2d(X)
3 卷积神经网络算法
3.1 背景
(1)硬件发展
(2)数据集的扩充

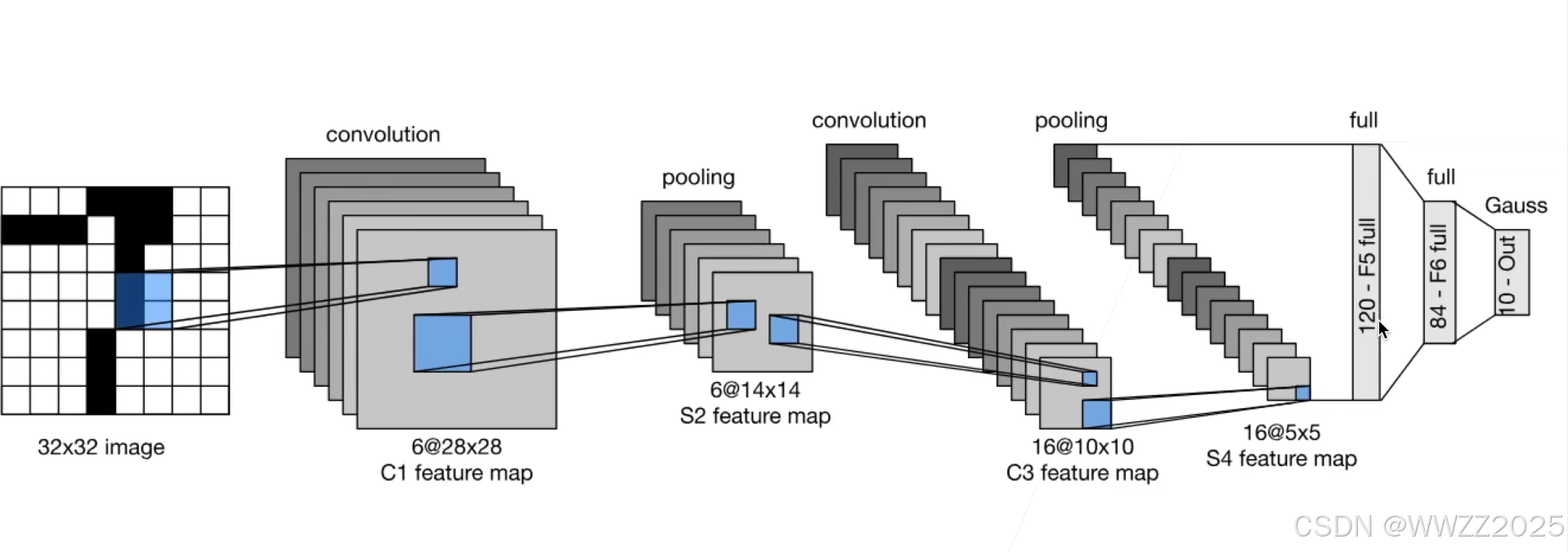
3.2 LeNet
3.3 AlexNet
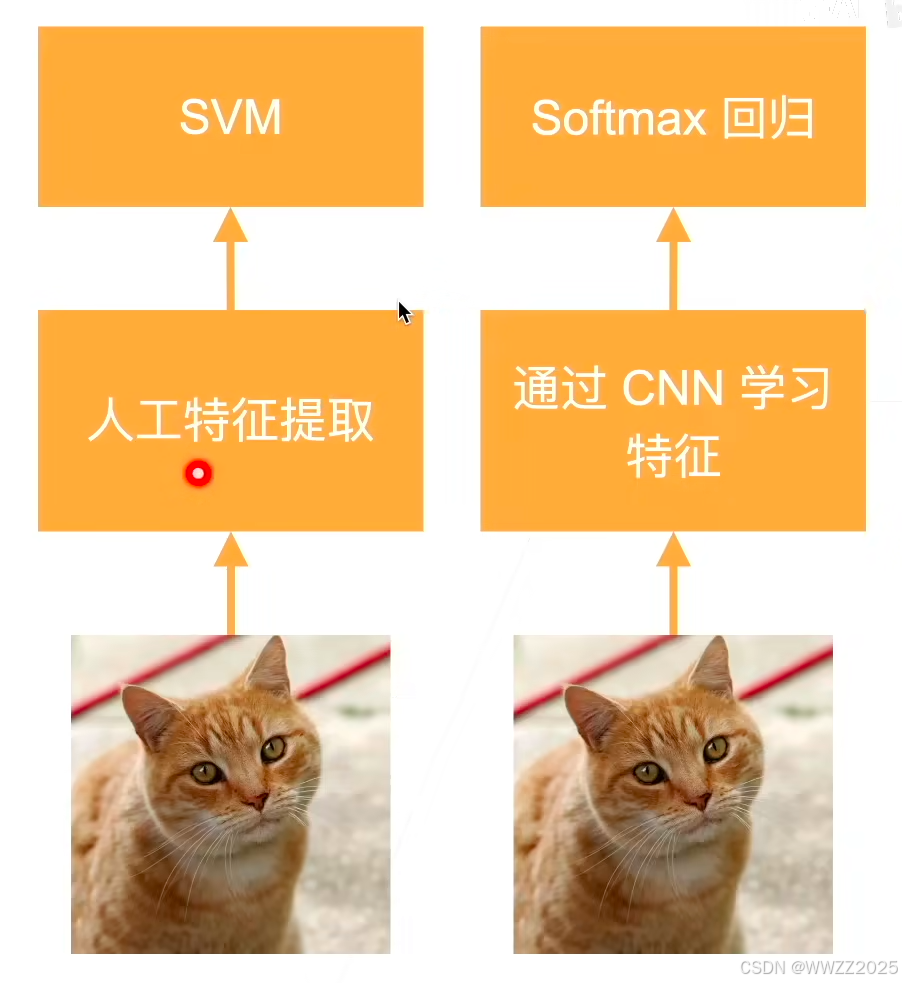
2012年,引起深度学习热潮。本质是更深、更大的LeNet,改进点:丢弃法、ReLu、MaxPooling,其使得计算机视觉方法论改变。左图为标准机器学习处理方案、右图为深度学习处理方案。
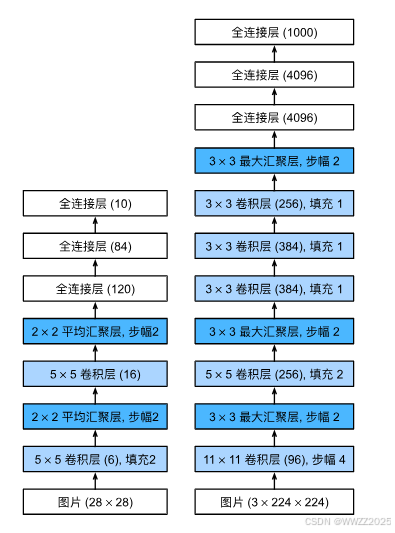
3.3.1 AlexNet架构
右图为LeNet、左图为AlexNet,更多细节:
(1)激活函数从sigmoid变到ReLu(减缓梯度消失);
(2)隐藏全链接层后加入丢弃层;
(3)数据增强。
3.3.2 代码
(1)容量控制及预处理
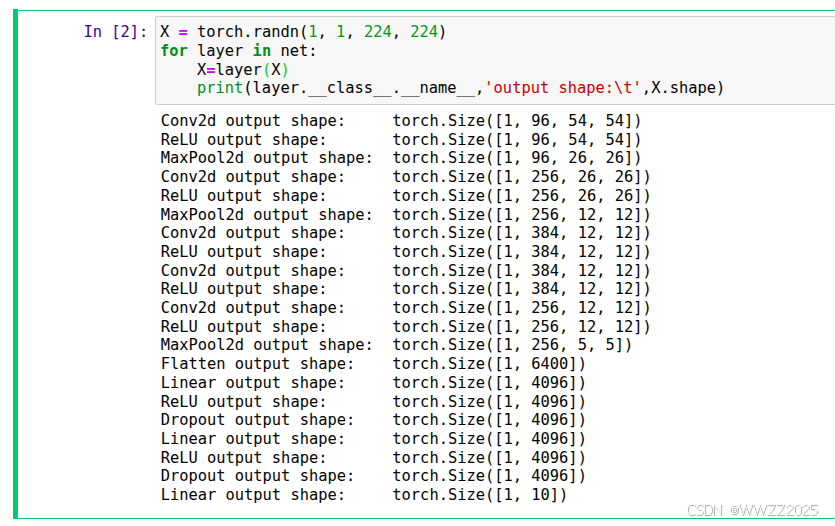
import torch from torch import nn from d2l import torch as d2l net = nn.Sequential( #大卷积+大步幅=快速拉开不同物体的空间差异 # 这里使用一个11*11的更大窗口来捕捉对象。 # 同时,步幅为4,以减少输出的高度和宽度。 # 另外,输出通道的数目远大于LeNet nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), #提取中层图像特征,如边缘组合、纹理 # 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数 nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), #提取高层抽象特征,如脸部结构、物体部件、类别相关形状 # 使用三个连续的卷积层和较小的卷积窗口。 # 除了最后的卷积层,输出通道的数量进一步增加。 # 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度 nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), #将多通道卷积特征展开为一维向量 nn.Flatten(), # 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合 nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5), # 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000 nn.Linear(4096, 10))(2)观察每一层输出情况
X = torch.randn(1, 1, 224, 224) for layer in net: X=layer(X) print(layer.__class__.__name__,'output shape:\t',X.shape)(3)读取数据集
AlexNet论文中使用ImageNet数据,量更大;此处用的是Fashion-MNIST(训练集6万张、测试集1万张),将其像素调整为和ImageNet一致224*224。
batch_size = 128 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)(4)训练AlexNet
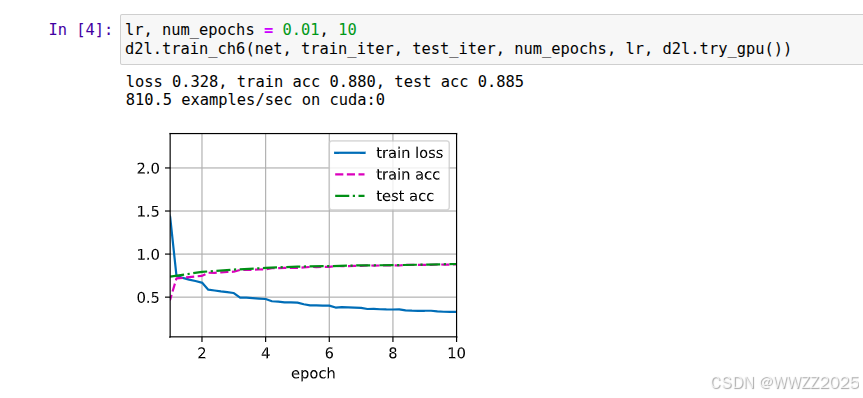
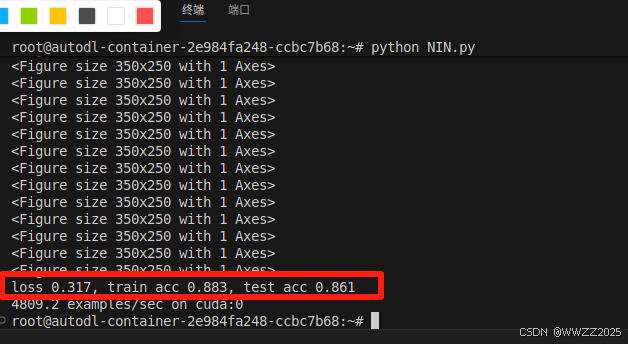
lr, num_epochs = 0.01, 10 d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())训练效果查看方法:
a.train loss越低越好,说明模型在训练集上拟合得越来越好;
b.train acc越高越好,但不能比test acc高太多,正常情况是逐渐上升最终接近100%;
c.test.cc越高越好,表示泛化能力好。



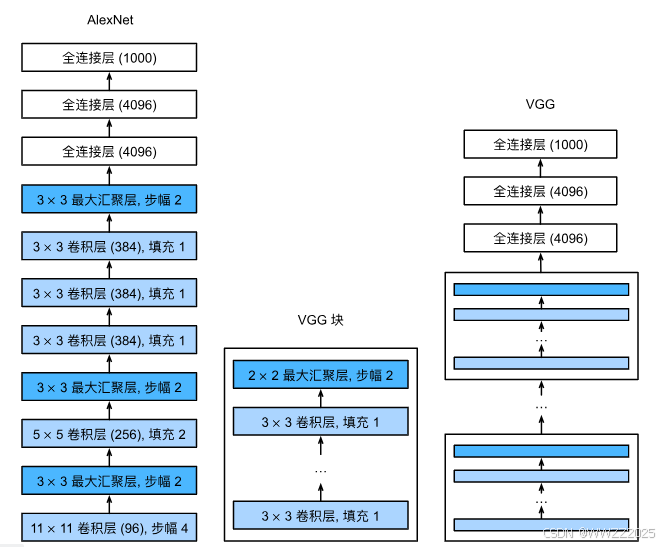
3.4 VGG
更大更深的AlexNet。
3.4.1 VGG块
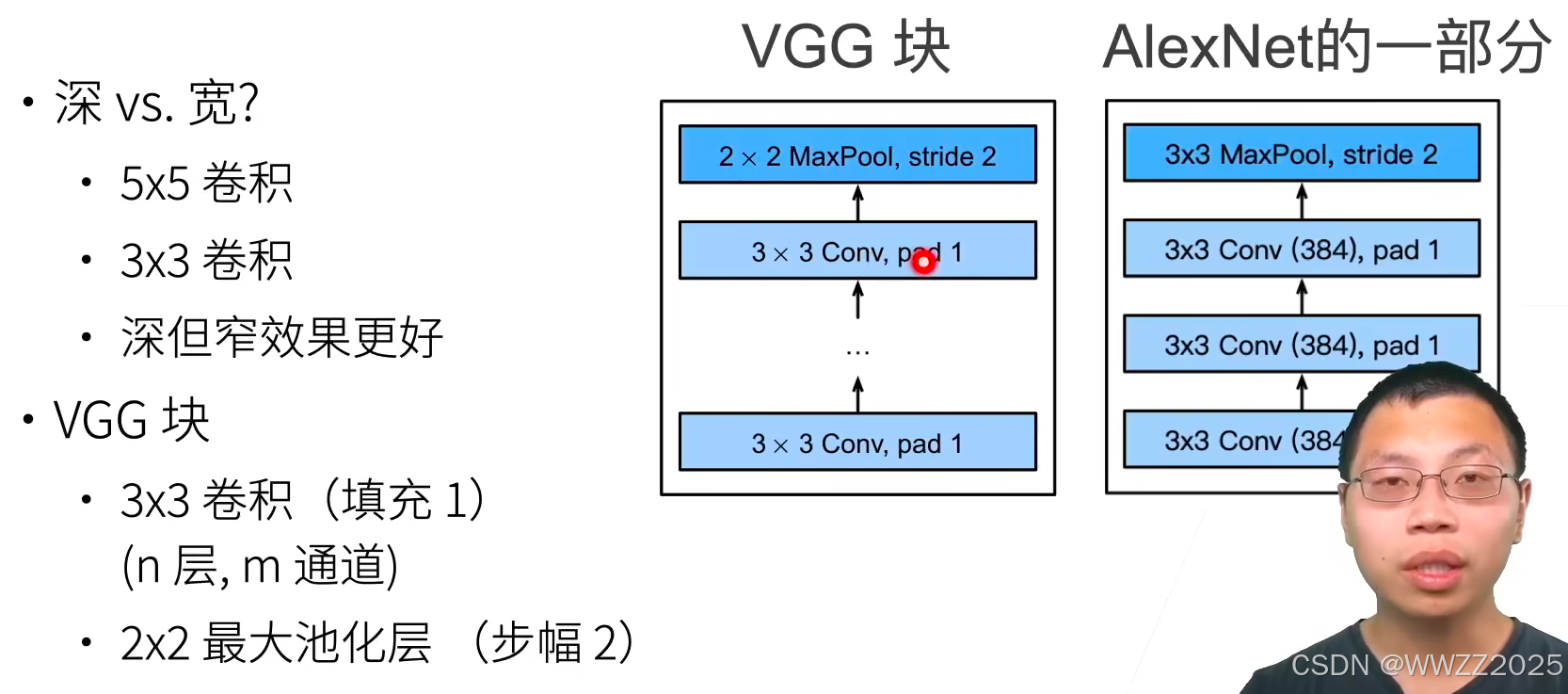
3.4.2 VGG架构
3.4.3 代码
(1)VGG块
import torch from torch import nn from d2l import torch as d2l def vgg_block(num_convs, in_channels, out_channels): layers = [] for _ in range(num_convs): layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)) layers.append(nn.ReLU()) in_channels = out_channels layers.append(nn.MaxPool2d(kernel_size=2,stride=2)) return nn.Sequential(*layers)(2)VGG网络
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) def vgg(conv_arch): conv_blks = [] in_channels = 1 # 卷积层部分 for (num_convs, out_channels) in conv_arch: conv_blks.append(vgg_block(num_convs, in_channels, out_channels)) in_channels = out_channels return nn.Sequential( *conv_blks, nn.Flatten(), # 全连接层部分 nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 10)) net = vgg(conv_arch) X = torch.randn(size=(1, 1, 224, 224)) for blk in net: X = blk(X) print(blk.__class__.__name__,'output shape:\t',X.shape)(3)模型训练
ratio = 4 small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch] net = vgg(small_conv_arch) lr, num_epochs, batch_size = 0.05, 10, 8 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224) d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
3.5 NiN
这个网络现在使用较少,了解思想即可。
3.5.1 特点
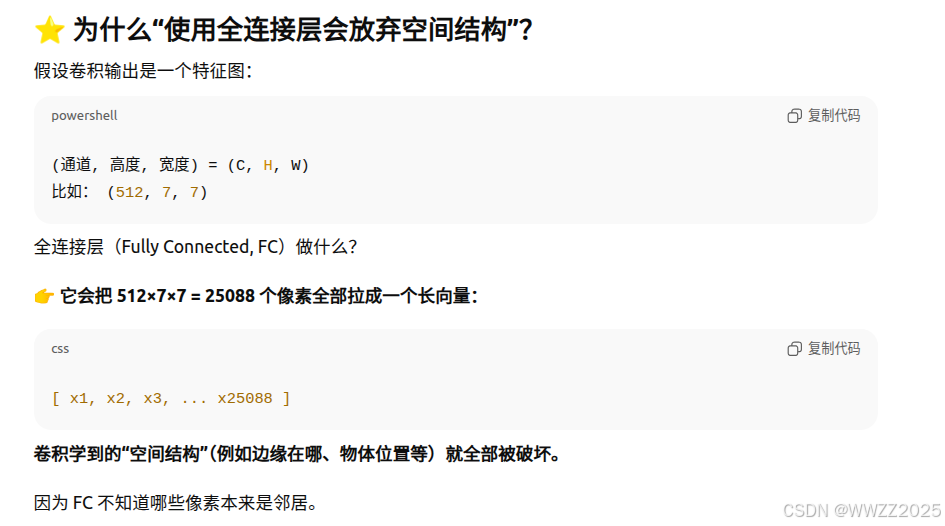
LeNet、AlexNet和VGG使用全连接层,可能会完全放弃表征的空间结构。 NiN提供了一个非常简单的解决方案,在每个像素的通道上分别使用多层感知机。
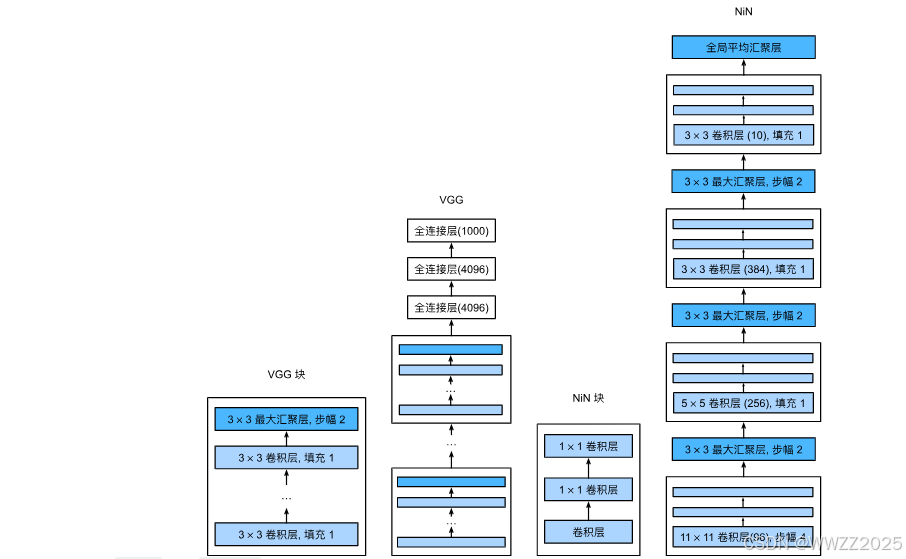
(1)NiN块使用卷积层+两个1x1卷积层,后者对每个像素增加了非线性;
(2)NiN使用全局平均池化层替代VGG、AlexNet中全连接层,不易过拟合、更少的参数个数。

3.5.2 架构
3.5.3 代码
(1)库
import torch from torch import nn from d2l import torch as d2l def nin_block(in_channels, out_channels, kernel_size, strides, padding): return nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding), nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())(2)NIN模型
net = nn.Sequential( nin_block(1, 96, kernel_size=11, strides=4, padding=0), nn.MaxPool2d(3, stride=2), nin_block(96, 256, kernel_size=5, strides=1, padding=2), nn.MaxPool2d(3, stride=2), nin_block(256, 384, kernel_size=3, strides=1, padding=1), nn.MaxPool2d(3, stride=2), nn.Dropout(0.5), # 标签类别数是10 nin_block(384, 10, kernel_size=3, strides=1, padding=1), nn.AdaptiveAvgPool2d((1, 1)), # 将四维的输出转成二维的输出,其形状为(批量大小,10) nn.Flatten()) #查看每层输出 X = torch.rand(size=(1, 1, 224, 224)) for layer in net: X = layer(X) print(layer.__class__.__name__,'output shape:\t', X.shape)(3)训练模型
lr, num_epochs, batch_size = 0.1, 10, 128 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224) d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
4 电脑配置查询
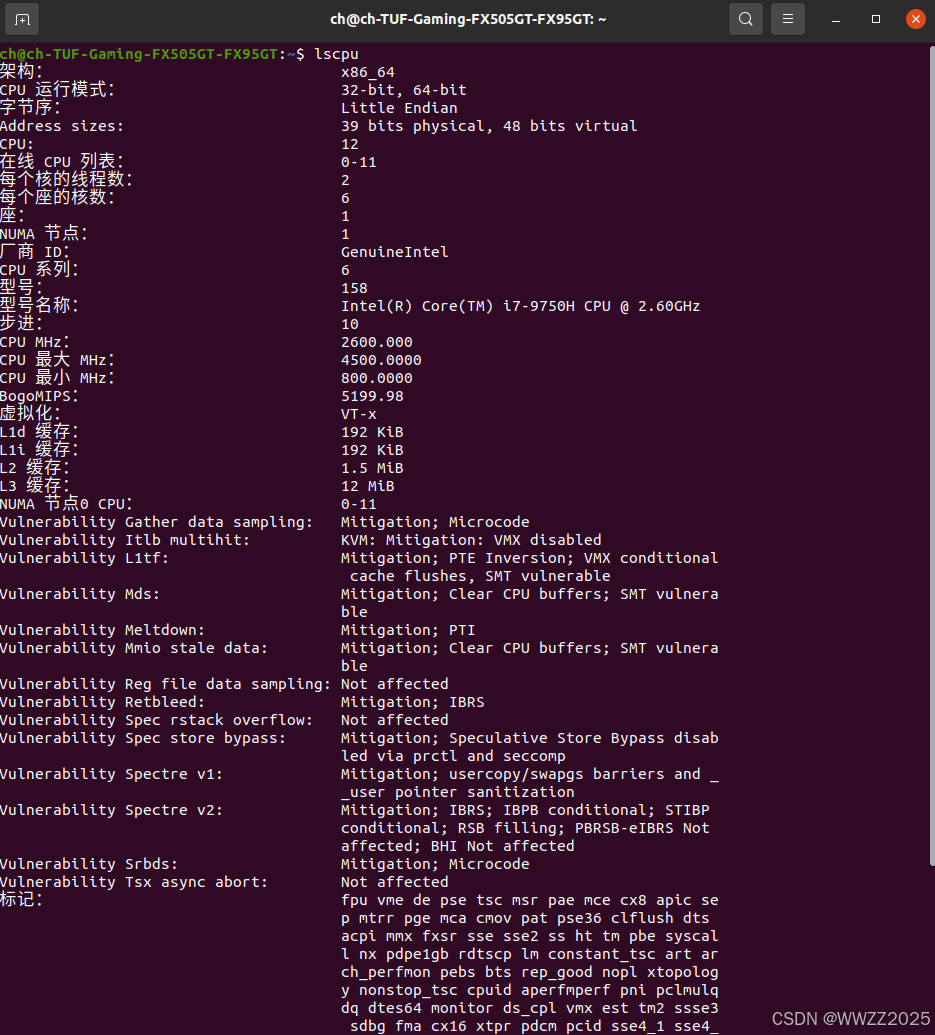
4.1 CPU
lscpu
4.2 内存
free -h

4.3 GPU
nvidia-smi

4.4 所有硬件信息
sudo lshw -short