本文介绍了美团技术团队在国际顶会ICCV 2025中发表的5篇论文。同时,在ICCV 2025 举办的多模态推理竞赛中,美团基础研发平台/计算和智能平台组建的ActiveAlphaAgent团队,斩获赛题1真实场景视觉定位(VG-RS)冠军,赛题2空间感知视觉问答(VQA-SA)季军和赛题3创意广告视频视觉推理(VR-Ads)季军。本文也分享了这三道赛题的解题思路,希望相关研究能给同学们带来一些帮助或启发。

计算机视觉国际大会(ICCV, International Conference on Computer Vision),是由IEEE主办的顶级会议之一,与计算机视觉模式识别会议(CVPR)和欧洲计算机视觉会议(ECCV)并列为计算机视觉领域的三大顶级会议,中国计算机学会CCF推荐的A类会议。 ICCV每两年举办一次,被公认为三大会议中级别最高的会议。
01 DisTime: Distribution-based Time Representation for Video Large Language Models
论文类型:ICCV Main Conference
论文下载 :PDF
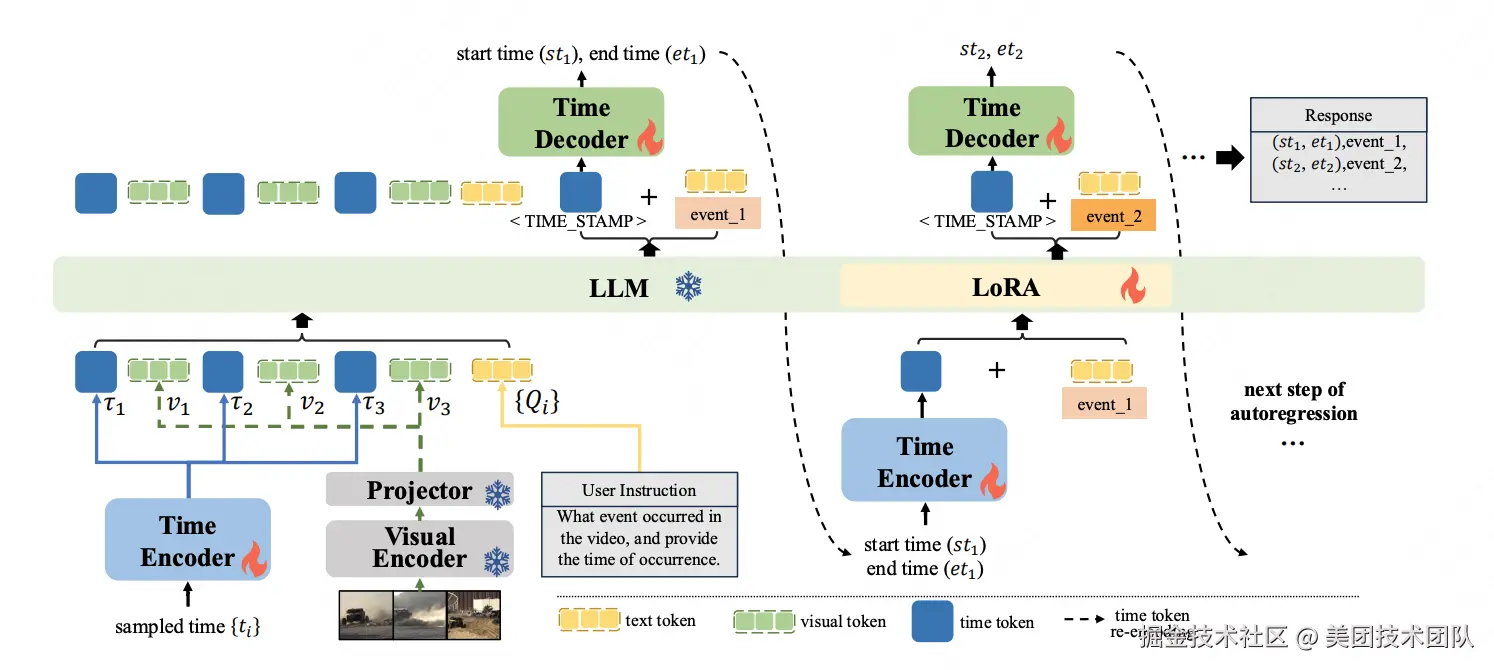
论文简介:尽管视频大型语言模型(Video-LLMs)在通用视频理解方面取得了进展,但是在精确的时间定位上仍面临挑战,这主要是由于离散的时间表示和有限的时序感知数据集。现有的时间表达方法要么将时间与基于文本的数值混淆,要么添加一系列专用的时间标记,或者通过专门的时间定位头回归时间。
为了解决这些问题,我们引入了DisTime,这是一种轻量级框架,旨在增强视频大型语言模型的时间理解能力。DisTime使用单个可学习的时间标记来创建一个连续的时间嵌入空间,并结合基于分布的时间解码器,生成时间概率分布,有效缓解边界模糊性并保持时间连续性。此外,基于分布的时间编码器重新编码成时间戳,为视频大型语言模型提供时间标记。为了克服现有无监督数据集中的时间粗粒度,我们提出了一种自动化标注模式,将视频大型语言模型的描述能力与专用时间模型的时序定位相结合。这促进了InternVidTG的创建,这是一个包含17.9万个视频和125万个时间定位事件的大型数据集,是ActivityNet-Caption的55倍。大量实验表明,DisTime在三个不同的时间敏感任务的基准测试中达到了最先进的性能,同时在视频问答任务中保持了竞争力。
02 ARIG: Autoregressive Interactive Head Generation for Real-time Conversations
论文主页 :ARIG
论文下载 :PDF
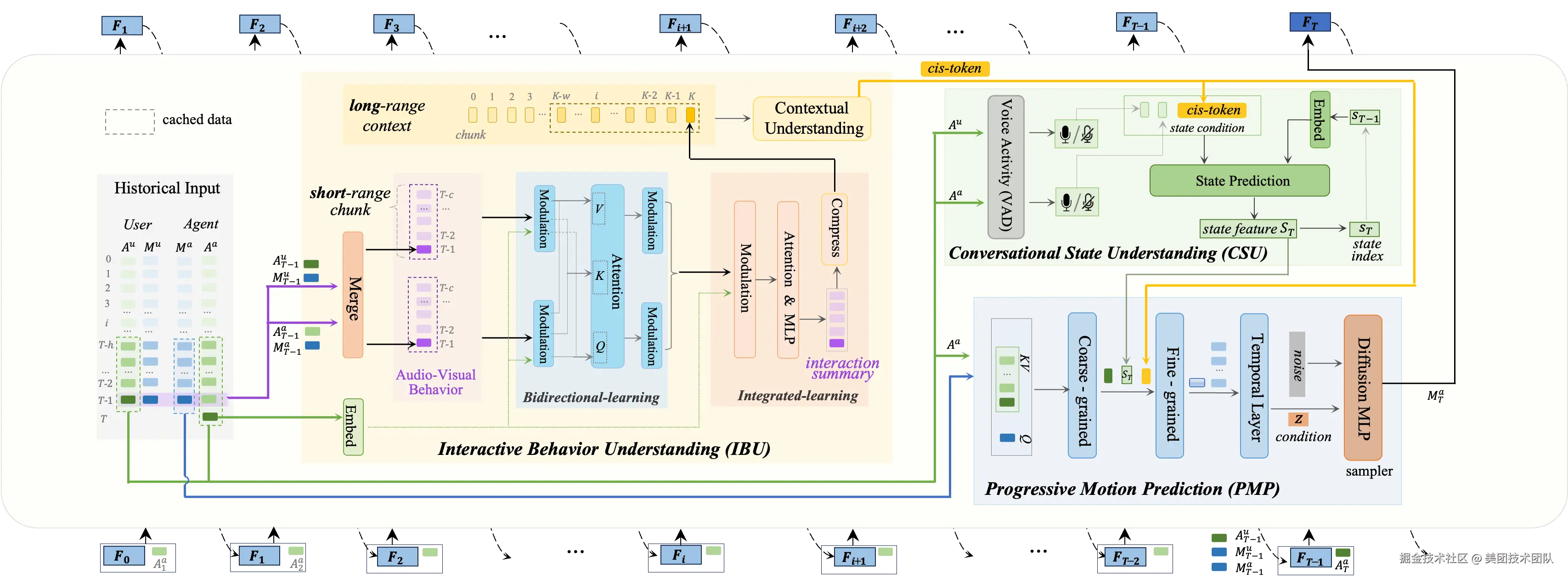
论文简介:在2D可交互数字人生成任务中,之前研究采用了clip-wise的diffusion生成范式或显式的听者/说者切换方法,它们在未来信号获取、上下文行为理解和状态切换平滑度方面存在局限性,难以实现实时性和真实感。本文提出了一种基于自回归 (AR) 的逐帧生成框架 ARIG,采用AR+diffusion框架以实现流式实时生成,并充分利用上下文语境和复杂对话状态理解实现了更高的交互真实感。
为了实现实时生成,论文将运动预测建模为非向量量化的 AR 过程。与离散码本索引预测不同,论文使用扩散过程表征运动分布,从而在连续空间中实现更准确的预测。为了提高交互真实感,论文注重交互式行为理解 (IBU) 和复杂对话状态理解 (CSU)。在IBU中,基于双路双模态信号,通过双向集成学习总结短距离行为,并在长距离范围进一步实现上下文理解。在CSU中,利用语音活动信号和上下文特征来理解实际对话中存在的各种复杂状态(打断、反馈、停顿等),并以此作为最终渐进式动作预测的条件,最终通过扩散过程实现动作生成。
03 Advancing Visual Large Language Model for Multi-granular Versatile Perception
论文类型:ICCV Main Conference
论文下载 :PDF
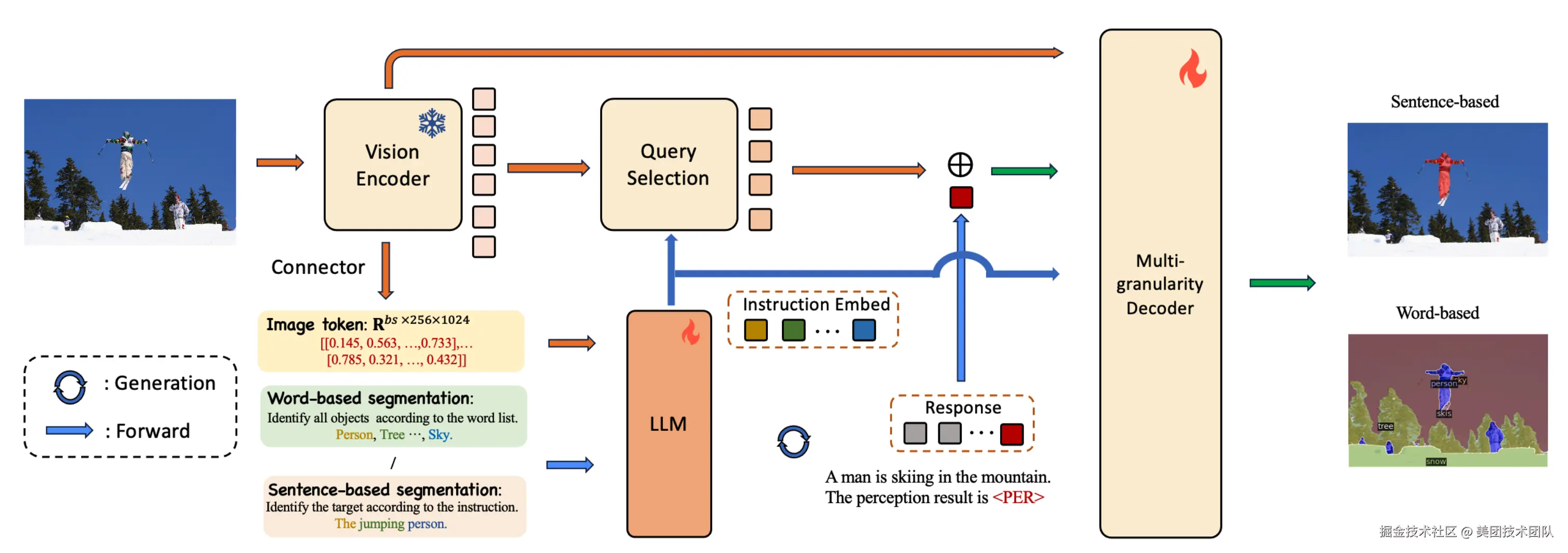
论文简介:感知是计算机视觉领域中的一项基础任务,涵盖了多种不同的子任务。这些子任务可以根据预测类型和指令类型两个维度,系统地划分为四个不同的类别。值得注意的是,现有研究往往只专注于这些潜在组合中的一小部分,这限制了它们在不同场景下的适用性和多样性。 针对这一挑战,我们提出了MVP-LM------一种融合了视觉大语言模型的多粒度、多功能感知框架。我们的框架旨在于单一架构中整合基于词语和基于句子的感知任务,支持框及掩码的预测。MVP-LM配备了创新的多粒度解码器,并结合了受链式思维启发的数据集统一策略,使其能够在包括全景分割、检测、定位和指代表达分割等在内的广泛任务上实现无缝的有监督微调。此外,我们还提出了一种查询混合增强策略,旨在充分利用视觉大语言模型固有的解码与生成能力。在基于词语和基于句子的感知任务的多个基准测试中,我们进行了大量实验,结果验证了我们框架的有效性。
04 A Token-level Text Image Foundation Model for Document Understanding
论文类型:International Conference on Computer Vision
论文下载 :PDF
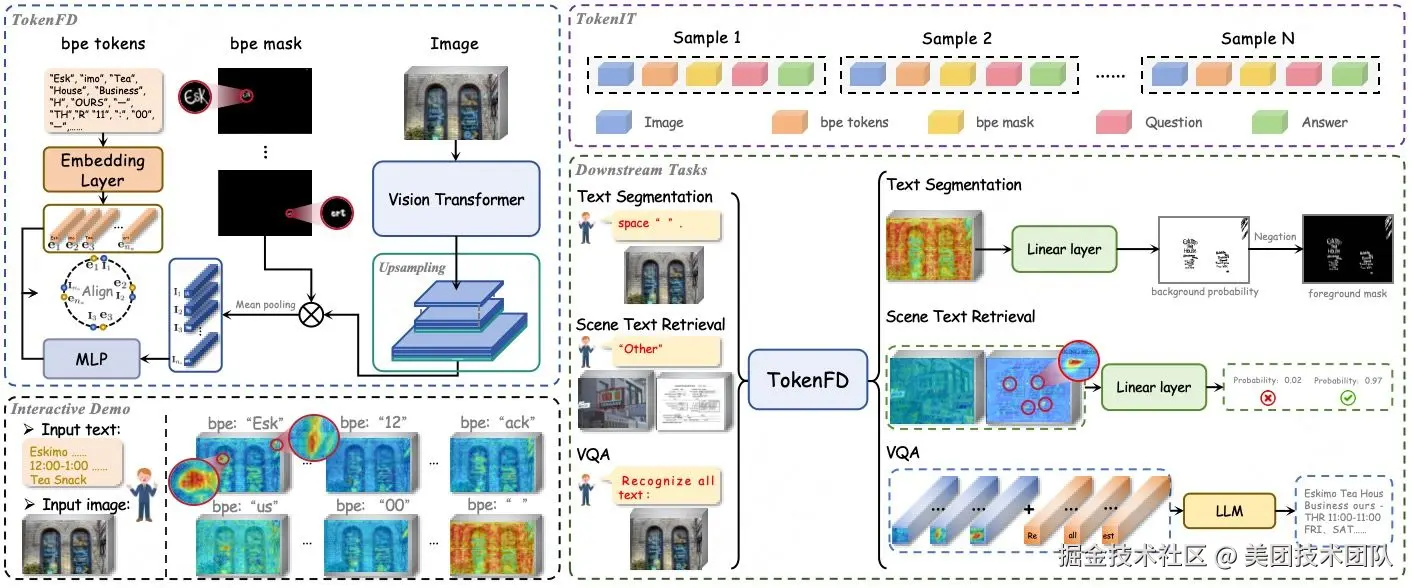
论文简介:百亿Token级掩码数据构建图文领域首个细粒度大一统基座,模态GAP不再存在 CLIP、DINO、SAM基座的重磅问世,推动了各个领域的任务大一统,也促进了多模态大模型的蓬勃发展。然而,这些经过图像级监督或弱语义训练的基座,并不是处理细粒度密集预测任务的最佳选择,尤其在理解包含密集文字的文档图像上。
为解决这一限制,我们实现了图文对齐粒度的新突破,其具备三大核心优势:
- 构建业内首个token级图文数据集TokenIT:该数据集包含 2000 万条公开图像以及 18 亿高质量的Token-Mask对。图像中的每个BPE子词均对应一个像素级掩码。数据体量是CLIP的5倍,且比SAM多出7亿数据对。
- 构建图文领域首个细粒度大一统基座TokenFD:仅需通过简单的一层语言编码,依托亿级的 BPE-Mask 对打造出细粒度基座 TokenFD。真正实现了图像Token与语言Token在同一特征空间中的共享,从而支持Token级的图文交互和各种下游任务。
- TokenVL打通模态GAP:进一步开放图像即文本的语义潜力,首次实现在大语言模型中进行token级的模态对齐,赋能密集型的多模态文档理解任务。
05 InstructSeg: Unifying Instructed Visual Segmentation with Multi-modal Large Language Models
论文类型:ICCV Main Conference
论文下载 :PDF
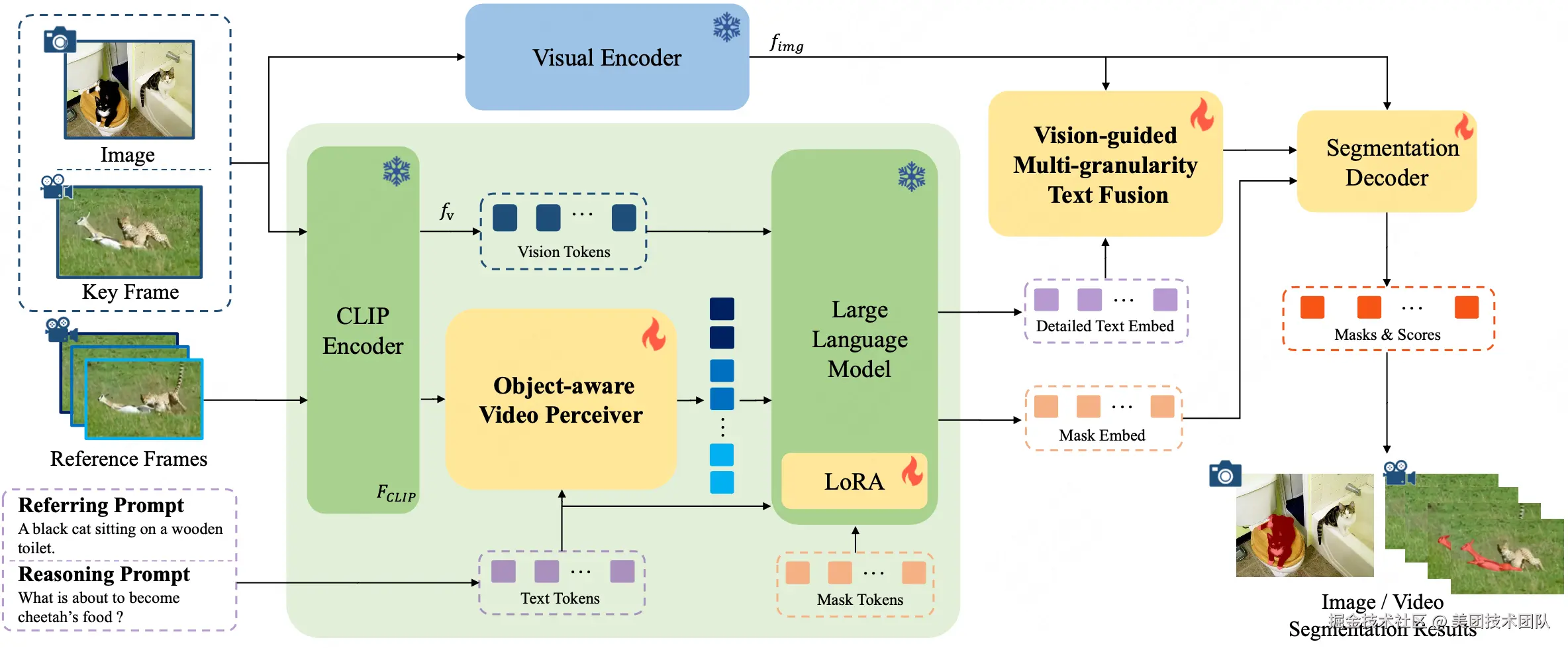
论文简介:受多模态大型语言模型 (MLLM) 推动,用于图像和视频领域的文本引导通用分割模型近年来取得了快速发展。然而,这些方法通常是针对特定领域单独开发的,而忽略了这两个领域在任务设置和解决方案上的相似性。本文首先把图像和视频级的参考分割和推理分割的统一归到指导视觉分割 (IVS)框架下,并提出了 InstructSeg,一种专用于 IVS任务 的 基于MLLM 的端到端分割模型。InstructSeg利用目标感知的视频感知器从参考帧中提取时间和目标双重信息,从而提升模型的视频理解能力。此外,我们引入了视觉引导的多粒度文本融合,更好地将全局和细节的文本信息与细粒度的视觉引导相结合。通过利用多任务和端到端训练,InstructSeg 在各类图像和视频任务中表现出色,仅通过单一模型超越了以往的分割专家模型和基于 MLLM 的方法。
ICCV 2025 多模态推理竞赛解题方案
大推理模型(LRM)时代已经来临,这为计算机视觉领域带来了新的机遇与挑战。大语言模型(LLM)强大的语义智能与大推理模型(LRM)的链式推理能力,为视觉理解和解释开辟了新的前沿领域。
为了弥合计算机视觉与大语言/推理模型之间的鸿沟,本次会议将探讨多模态大模型如何通过思维链(Chain-of-Thought)、多步推理(Multi-step Reasoning)等慢思考方法理解复杂关系,深入理解复杂场景中的对象交互。在此背景下,本次举办的Challenge on Multimodal Reasoning,重点关注需要高级推理能力的多模态复杂任务,具体包括:
- 赛题1:真实场景视觉定位(VG-RS),评估模型在复杂多模态场景中的场景感知、物体定位与空间推理能力。
- 赛题2:空间感知视觉问答(VQA-SA),评估模型基于具体物理规律,遵循用户指令进行空间推理、常识推理与反事实推理的能力。
- 赛题3:创意广告视频视觉推理(VR-Ads),评估模型在广告视频中理解非物理性及抽象视觉概念的认知推理能力。
三道赛题均未提供官方训练数据,最终需要提交模型和推理方案由组委会进行复现。
美团/基础研发平台/计算和智能平台部组建的ActiveAlphaAgent团队参加了ICCV 2025举办的Challenge on Multimodal Reasoning,斩获赛题1真实场景视觉定位(VG-RS)冠军,赛题2空间感知视觉问答(VQA-SA)季军和赛题3创意广告视频视觉推理(VR-Ads)季军。
赛题1:真实场景视觉定位(VG-RS)
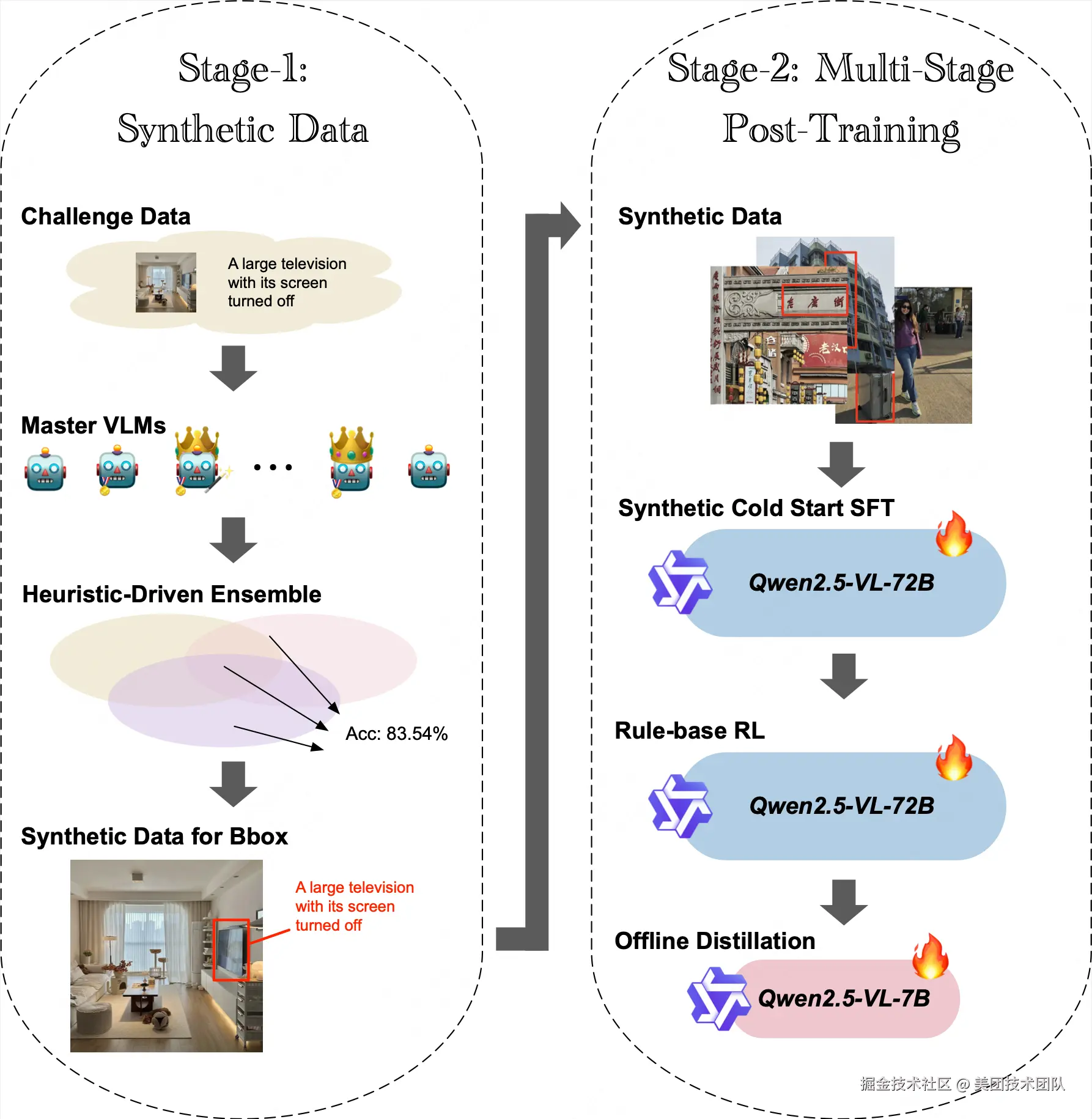
解决方案简介 | 我们提出了一种结合信噪比驱动数据合成、多阶段对齐与强化训练的视觉定位框架VG-SMART。具体而言:
- 首先通过精心调优prompt提升SOTA模型在该任务上的表现, 并集成多个SOTA模型结果合成初始数据集;
- 随后在初始数据集上为每条数据采样计算pass rate,并基于自定义信噪比(SNR)指标对数据进行严格筛选构建有难度的高质量合成数据集;
- 然后基于高质量的合成数据集进行Qwen2.5-VL-72B-Instruct的多阶段训练,包含监督微调(SFT)阶段和采用IoU中心奖励函数的强化学习(RL)阶段;
- 最终我们将训练好的Qwen2.5-VL-72B-Instruct蒸馏至Qwen2.5-VL-7B,在保持性能的同时优化了推理速度,在排行榜上以0.6671分获得第一名。
赛题2:空间感知视觉问答(VQA-SA)
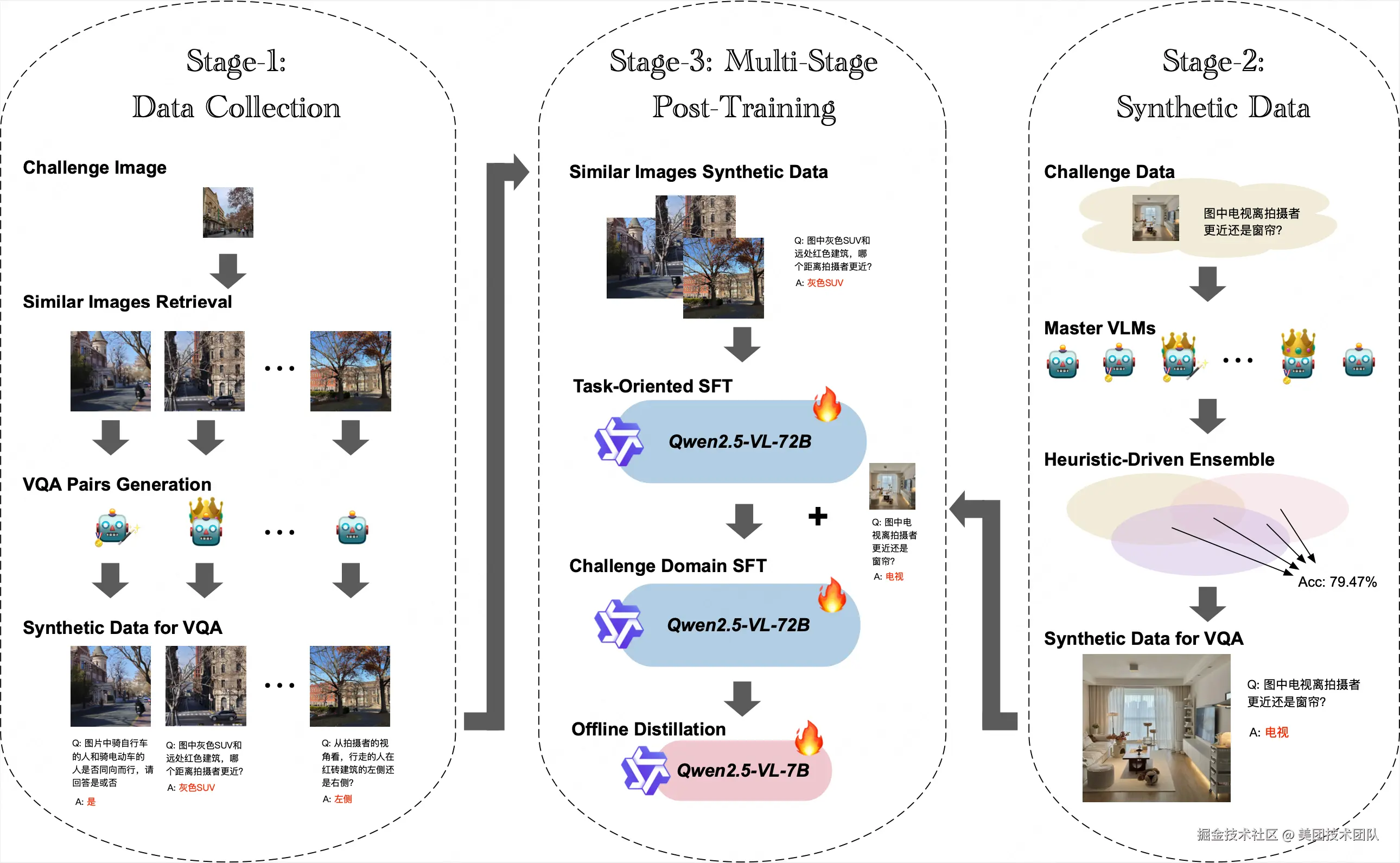
解决方案简介 | 我们提出了一种适合多模态VQA任务的多阶段数据合成与训练框架STAGES,具体包括:
-
首先以无答案的比赛图片为种子利用图搜工具检索与比赛数据相似的图片,并参考比赛数据集形式,精心调优prompt,利用LLM和LVLMs合成80万类似VQA数据;
-
然后在这80万合成数据上对Qwen2.5-VL-72B-Instruct进行第一阶段SFT,显著提升了模型在该类任务的表现;
-
接着在无答案比赛数据集上,我们进一步精调多个SOTA模型prompt,并以集成方式合成出少量高置信的比赛数据样本,之后使用这批合成数据对Qwen2.5-VL-72B-Instruct进行第二阶段SFT,进一步提升了模型在比赛数据上的表现;
-
最终我们将训练好的Qwen2.5-VL-72B-Instruct蒸馏至Qwen2.5-VL-7B,在保持性能的同时优化了推理速度,在排行榜上以0.6972分获得第三名。
赛题3:创意广告视频视觉推理(VR-Ads)
解决方案简介 | 我们提出了面向创意广告视频的测试时策略调优与自适应推理方法T-STAR,该方案聚焦于优化Qwen2.5-VL-72B-Instruct的推理策略,通过精细调节关键推理参数来最大化模型在该复杂任务中的固有推理能力。具体方法:
- 首先对视频采样帧率和图像分辨率进行了系统实验,探索视觉信息密度与处理效率之间的权衡;
- 在此基础上,我们叠加了约束性拒绝采样策略,确保输出简洁且符合任务要求;
- 最终,我们以Test-time scaling方式,使用Qwen2.5-VL-72B-Instruct以0.53分在最终排行榜上位列第三。
关注「美团技术团队」微信公众号,在公众号菜单栏对话框回复【2024年货】、【2023年货】、【2022年货】、【2021年货】、【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明"内容转载自美团技术团队"。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 tech@meituan.com 申请授权。