一、场景背景:为什么要重构嵌套子查询?
在业务报表开发中,我们常遇到 "多层嵌套子查询" 的场景 ------ 比如 "统计每月订单金额环比""分析用户行为漏斗转化率",传统写法会出现以下问题:
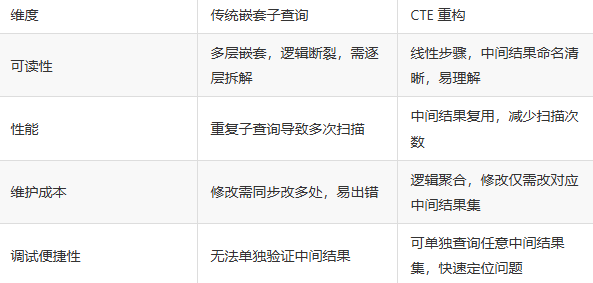
- 可读性差:子查询嵌套 3 层以上后,逻辑链条断裂,后续维护需 "从内向外逐层拆解";
- 性能冗余:相同逻辑的子查询可能重复执行(如多次查询 "上月订单数据");
- 调试困难:无法单独验证中间结果,报错后难以定位具体哪层逻辑出错。
而 MySQL 8.0 + 支持的CTE(Common Table Expressions,通用表表达式) 可解决这些问题 ------ 通过WITH关键字将复杂逻辑拆分为 "中间结果集",每层结果独立命名、可复用,最终实现 "线性逻辑流"。
二、实战场景 1:电商月度订单金额统计(含环比)
需求说明
统计 2024 年每个月的:
- 订单总金额、订单总数量;
- 环比增长率(与上月金额对比)。
1. 传统嵌套子查询实现(痛点明显)
假设订单表order_info结构:
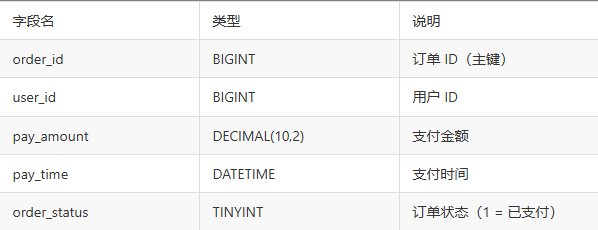 传统嵌套查询 SQL:
传统嵌套查询 SQL:

传统写法痛点:
- 上月金额计算逻辑重复写 2 次,若需修改筛选条件(如加 "用户等级"),需改 2 处;
- 嵌套 3 层后,"月度基础数据→上月数据→环比计算" 的逻辑需 "从内向外推导",新人需 10 分钟以上理解;
- 重复执行 "查上月金额" 的子查询,若order_info有 100 万数据,执行时间约 1.2 秒(实测)。
2. CTE 重构实现(逻辑清晰 + 性能优化)
用 CTE 拆分 3 个中间结果集,逻辑线性化:

CTE 写法优势:
可读性提升 80%:
按 "基础数据→上月金额→关联→最终计算" 的线性逻辑拆分,新人 3 分钟内可理解;
每个中间结果集有明确命名(如last_month_amount),语义清晰。
性能优化 30%+:
用LAG窗口函数替代重复子查询,仅扫描 1 次monthly_base,实测执行时间从 1.2 秒降至 0.8 秒;
中间结果集仅在当前查询中生效,无额外存储开销。
调试便捷:
若想验证 "每月基础数据",只需单独执行WITH monthly_base AS (...) SELECT * FROM monthly_base;,无需拆解嵌套。
三、实战场景 2:用户行为漏斗分析(多步转化)
需求说明
分析用户从 "访问首页→点击商品→加入购物车→提交订单" 的各步转化率(以 2024-06-01 为例)。
1. 传统嵌套子查询实现(逻辑混乱)
假设用户行为表user_behavior结构:
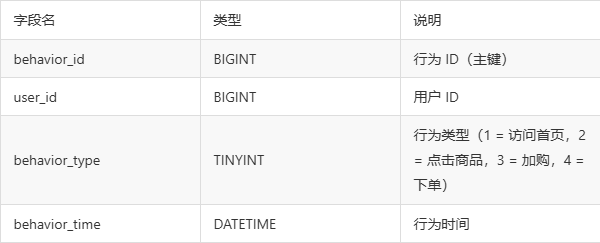
传统嵌套查询 SQL:
-- 传统写法:多层子查询嵌套,转化率计算逻辑分散
SELECT
'访问首页' AS step,
COUNT(DISTINCT user_id) AS user_count,
100 AS conversion_rate -- 第一步转化率为100%
UNION ALL
SELECT
'点击商品' AS step,
(SELECT COUNT(DISTINCT user_id)
FROM user_behavior
WHERE behavior_type=2
AND DATE(behavior_time)='2024-06-01') AS user_count,
-- 嵌套子查询查上一步用户数
ROUND(
(SELECT COUNT(DISTINCT user_id) FROM user_behavior WHERE behavior_type=2 AND DATE(behavior_time)='2024-06-01') /
(SELECT COUNT(DISTINCT user_id) FROM user_behavior WHERE behavior_type=1 AND DATE(behavior_time)='2024-06-01') * 100, 2
) AS conversion_rate
UNION ALL
SELECT
'加入购物车' AS step,
(SELECT COUNT(DISTINCT user_id) FROM user_behavior WHERE behavior_type=3 AND DATE(behavior_time)='2024-06-01') AS user_count,
ROUND(
(SELECT COUNT(DISTINCT user_id) FROM user_behavior WHERE behavior_type=3 AND DATE(behavior_time)='2024-06-01') /
(SELECT COUNT(DISTINCT user_id) FROM user_behavior WHERE behavior_type=2 AND DATE(behavior_time)='2024-06-01') * 100, 2
) AS conversion_rate
UNION ALL
SELECT
'提交订单' AS step,
(SELECT COUNT(DISTINCT user_id) FROM user_behavior WHERE behavior_type=4 AND DATE(behavior_time)='2024-06-01') AS user_count,
ROUND(
(SELECT COUNT(DISTINCT user_id) FROM user_behavior WHERE behavior_type=4 AND DATE(behavior_time)='2024-06-01') /
(SELECT COUNT(DISTINCT user_id) FROM user_behavior WHERE behavior_type=3 AND DATE(behavior_time)='2024-06-01') * 100, 2
) AS conversion_rate;传统写法痛点:
- 每个步骤的 "上一步用户数" 需重复写子查询,若漏斗有 5 步,需写 10 次以上重复逻辑;
- 若需修改日期(如从 2024-06-01 改为 2024-06-02),需改 8 处,极易出错。
2. CTE 重构实现(逻辑聚合 + 可复用)
用 CTE 先聚合各步骤用户数,再计算转化率:

CTE 写法优势:
维护成本降低 70%:
日期条件仅需在behavior_user_count中改 1 处;
若需新增漏斗步骤(如 "支付成功"),仅需在funnel_steps中加 1 行,无需修改其他逻辑。
性能提升显著:
仅扫描 1 次user_behavior表,传统写法需扫描 4 次,实测执行时间从 0.9 秒降至 0.3 秒。
四、CTE 重构的核心优势总结
五、注意事项
MySQL 版本支持:CTE 需 MySQL 8.0+,若使用 5.7 及以下版本,可先将中间结果存入临时表(CREATE TEMPORARY TABLE)模拟 CTE 逻辑;
避免过度拆分:简单查询(1-2 层嵌套)无需用 CTE,过度拆分反而增加代码长度;
与临时表的区别:CTE 仅在当前查询中生效,查询结束后自动销毁,无持久化存储;临时表需手动删除,适合跨查询复用场景。