1.所用函数
1.sklearn.feature_extraction:sklearn中的特征提取API
2.DictVectorizer:专门提取字典文本特征的函数
2.示例
python
from sklearn.feature_extraction import DictVectorizer
##字典特征提取:可以提取是字典结构的数据或者是包含字典的迭代器
trans=DictVectorizer(sparse=False)##生成提取器对象,sparse=False表示返回的是one-hot编码的数据,不加默认是返回稀疏矩阵的形式即无0的表示方法
data=[{"city":"北京","temperature":100},{"city":"上海","temperature":60},{"city":"深圳","temperature":30}]#包含字典的迭代器
tezheng=trans.fit_transform(data)##对象.fit_transform(data)提取字典的特征数据
print(trans.feature_names_)##获取特征名称
print(tezheng)#获取特征数据是one-hot编码的形式one-hot编码格式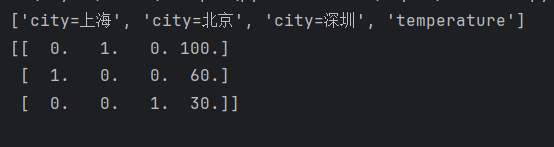
系数矩阵格式
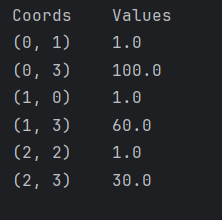
注意:第一列是第二列values数据的位置是用下标构成的(对比one-hot图可验证)