利用Limix模型对tabular-benchmark数据集实现分类和回归任务
LimiX 是一个专为结构化数据设计的轻量级大模型(仅约 16M 参数),无需任何下游训练即可直接推理,同时具备优秀的泛化能力与概率校准性能。在多种分类与回归任务中,其无训练模式已能达到或超越传统表格模型基线,表现稳健。结合可选的检索增强推理机制(Retrieval Ensemble),模型能够进一步利用训练样本关系改善复杂分布下的预测精度。整体而言,LimiX 在推理成本与效果之间实现了高效平衡,适合在低训练资源场景中快速获得可靠结果。
创建项目
点击工作台右上角 创建项目 新建项目。
初始化配置
按照下图推荐配置,选择镜像、数据及模型
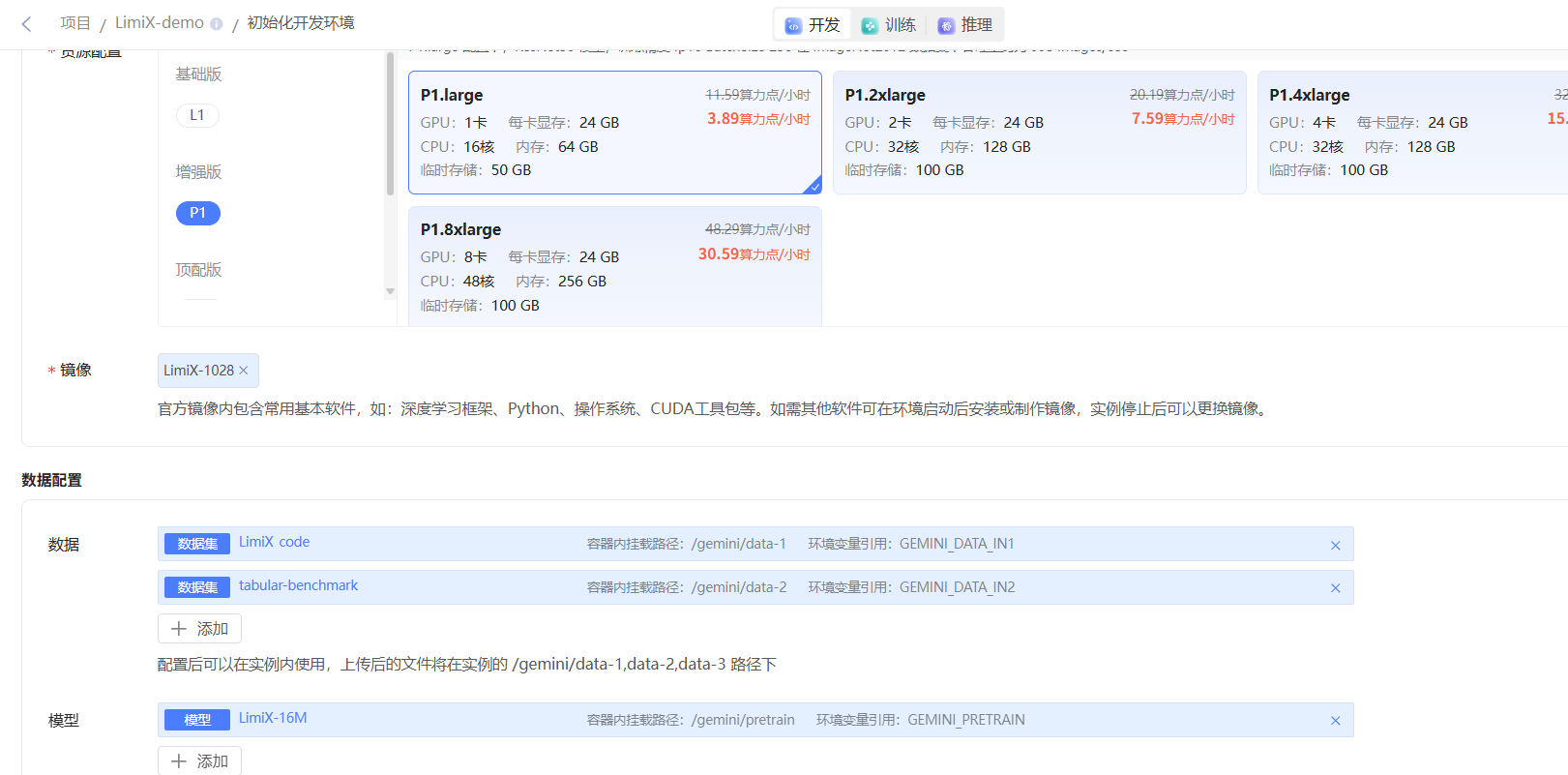
资源配置:P1.large及以上,算力直接影响到生成结果语音的速度,若您选择更高配置,请您确保您有足够的算力点
镜像:选择LimiX-1028
数据:选择LimiX-code、tabular-benchmark
模型:暂无
代码拷贝
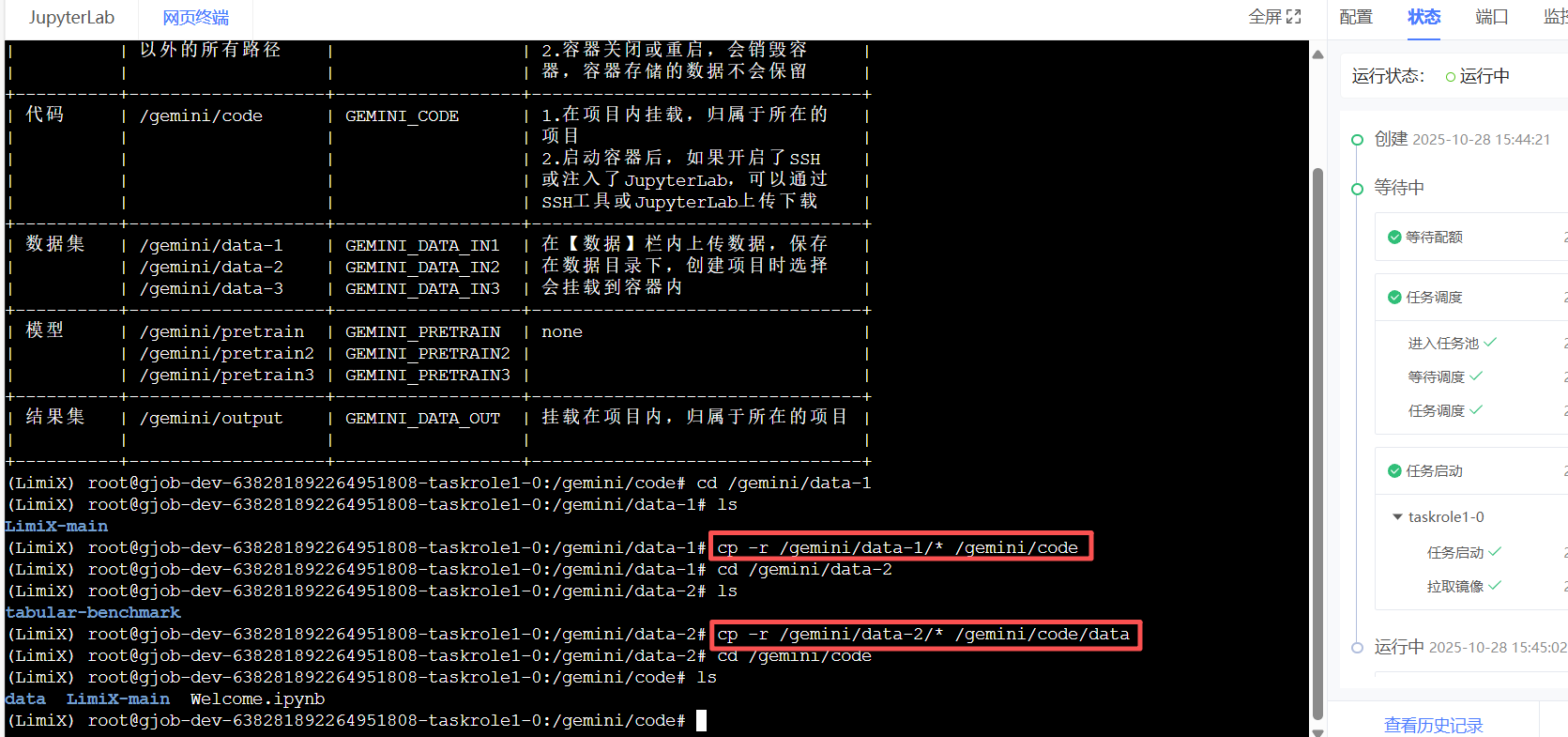
cd到LimiX目录下,执行以下指令,将代码拷贝到 /gemini/code 目录下,将数据集拷贝到 /gemini/code/data 目录下
cp -r /gemini/data-1/* /gemini/code
cp -r /gemini/data-2/tabular-benchmark /gemini/code/data
执行完后,可使用 ls命令 检查是否成功,如图所示
数据预处理
利用 process_data.py 脚本对 tabular-benchmark 进行数据预处理,以便LimiX模型进行推理
cd /gemini/code/LimiX-main # 进入启动目录
处理分类数据集示例
python process_data.py \
--input_dir /gemini/code/data/tabular-benchmark/clf_cat \
--output_dir /gemini/code/data/tabular-benchmark_clf_cat_split \
--task_type classification
处理回归数据集示例
python process_data.py \
--input_dir /gemini/code/data/tabular-benchmark/reg_cat \
--output_dir /gemini/code/data/tabular-benchmark_reg_cat_split \
--task_type regression


以上代码仅为示例,只对 clf_cat 与 reg_cat 两组数据进行处理,您也可自行更换输入输出路径,请标明任务类型 task_type 为 classification(分类)或 regression(回归)
模型推理
利用 inference_classifier.py 和 inference_regression.py 脚本分别执行分类和回归任务
cd /gemini/code/LimiX-main # 进入启动目录
执行分类任务
python inference_classifier.py \
--save_name cls_clfcat_noretrieval \
--inference_config_path config/cls_default_noretrieval.json \
--data_dir /gemini/code/data/tabular-benchmark_clf_cat_split \
--model_path /gemini/pretrain/LimiX-16M/LimiX-16M.ckpt
处理回归数据集示例
python inference_regression.py \
--save_name reg_clfcat_noretrieval \
--inference_config_path config/reg_default_noretrieval.json \
--data_dir /gemini/code/data/tabular-benchmark_reg_cat_split \
--model_path /gemini/pretrain/LimiX-16M/LimiX-16M.ckpt

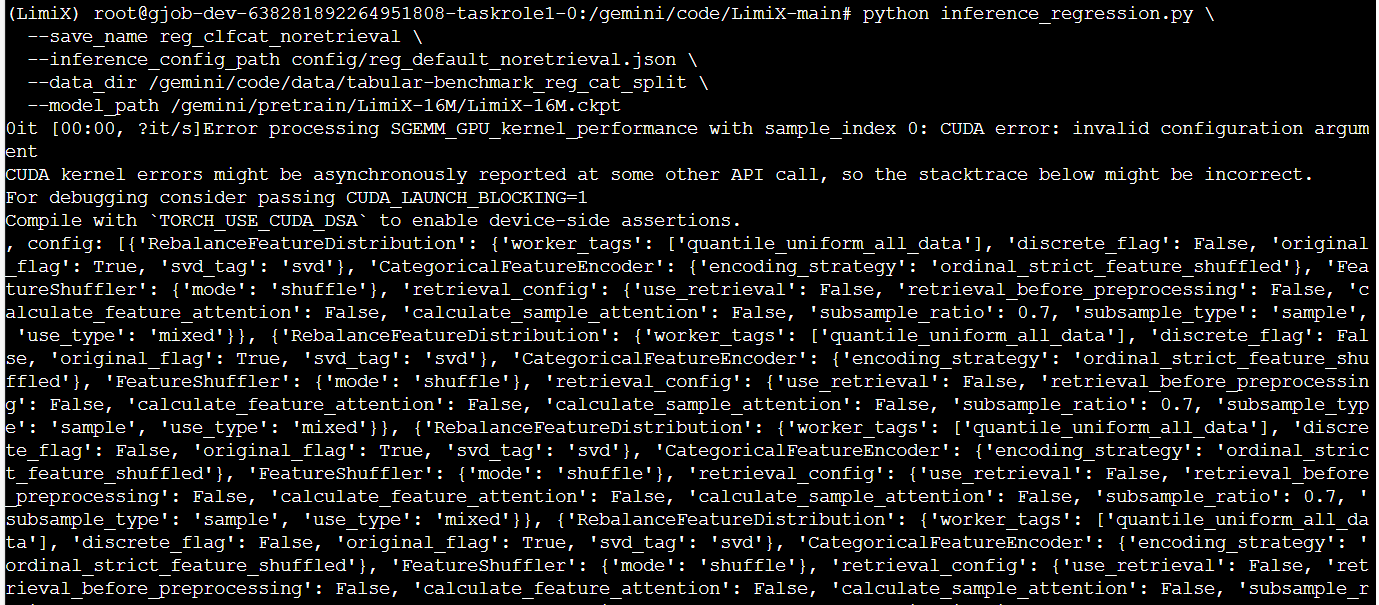
以上代码仅为示例,只对处理过的 clf_cat 与 reg_cat 数据进行处理,模式为无需检索模式(notrieval),速度更快,所需性能和内存较低,
查看推理结果
利用JupyterLab打开 /gemini/code/LimiX-main/result 文件夹,查看刚刚分类和回归的输出,指标保存在 all_rst.csv 中


温馨提示: 完成项目后,记得及时关闭开发环境,以免继续产生费用。如果担心自己忘记关闭,可以提前在右边栏配置处设置自动停止时间。
北数云正在加速接入
更多"科研级"前沿模型 !
我们相信,通用大模型的普惠化,不仅是技术进步,更是科研创新生态的重要推动力。未来,北数云还将持续上线更多前沿与工具。
欢迎各位用户留言告诉我们:你最希望在北数云看到哪些模型?
我们会持续关注大家的实际科研需求,把算力与模型能力结合,助力每一位开发者和研究者,以最低成本释放最大潜能!
高校专属算力普惠计划进行中!完成认证领1000算力点