博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈
以Python作为主要开发语言,基于Flask框架搭建Web应用系统,采用MySQL数据库存储各类数据,运用requests爬虫技术获取相关数据资源,结合Echarts可视化工具将数据以图表形式直观呈现。
功能模块
- 电影制片地区饼图分析
- 电影数据信息
- 首页
- 电影数据漏斗图分析
- 饼图分析
- 电影类型数据柱状图
- 导演作品柱状图分析
- 评分与评论人数散点图
- 每年电影数量折线图
- 数据采集页面
项目介绍
本项目为基于Python开发的豆瓣电影数据可视化分析系统,整合Flask、MySQL、requests爬虫及Echarts等技术,构建了从豆瓣电影数据采集、清洗、存储到多维度可视化分析的全流程体系。系统通过requests爬虫技术抓取豆瓣电影相关数据,经清洗整理后存储至MySQL数据库,依托Echarts将数据转化为饼图、柱状图、折线图等可视化图表,围绕制片地区、电影类型、上映年份等维度开展分析,有效解决了电影数据分散、分析效率低下、展示形式不直观的问题,为电影爱好者和行业研究者提供了易用的数据分析工具。
2、项目界面
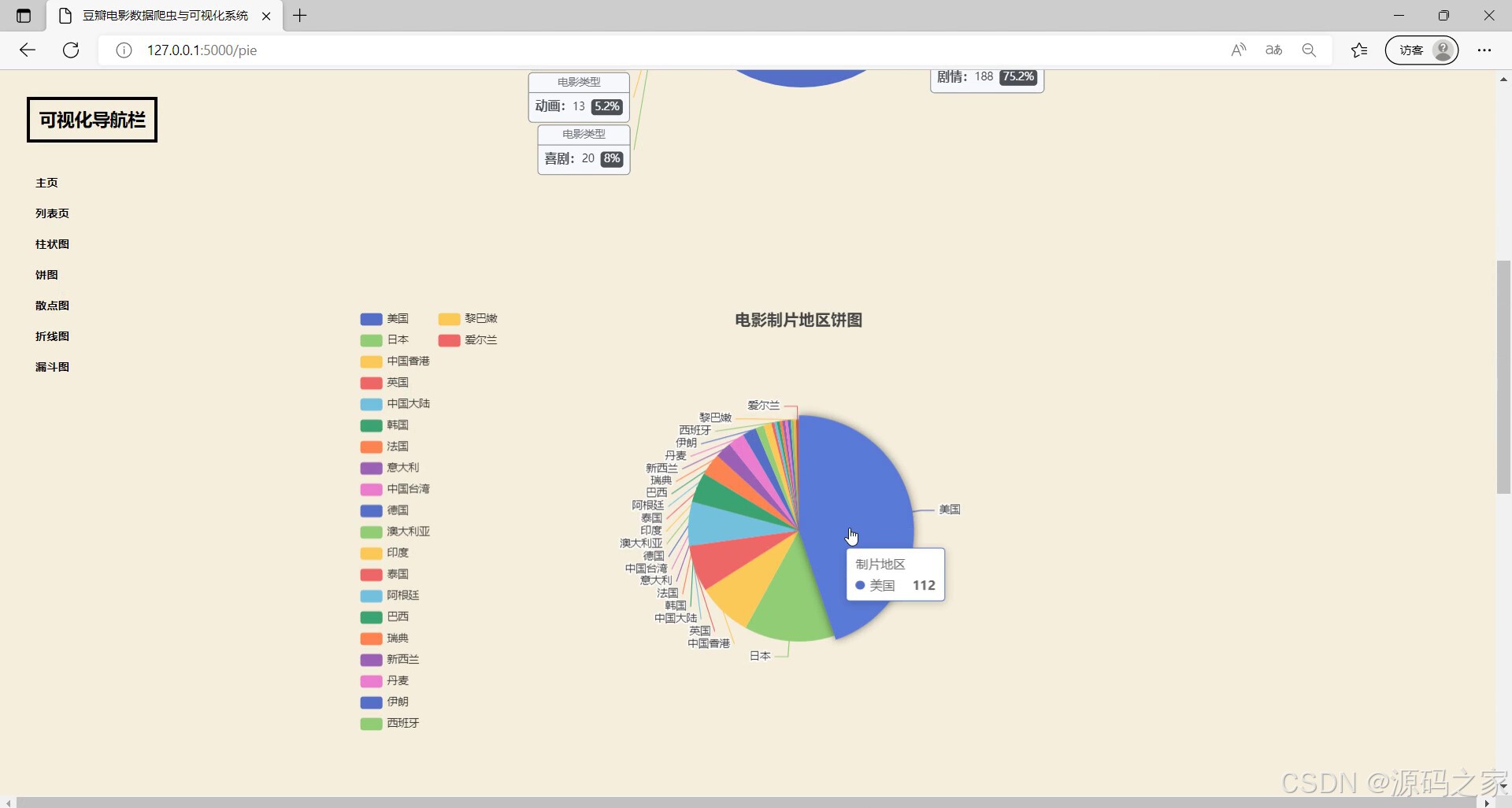
(1)电影制片地区饼图分析
包含可视化导航栏可切换不同图表类型,当前展示电影制片地区饼图,能呈现不同地区的制片占比,还可通过交互查看对应地区的制片数据情况。
(2)电影数据信息
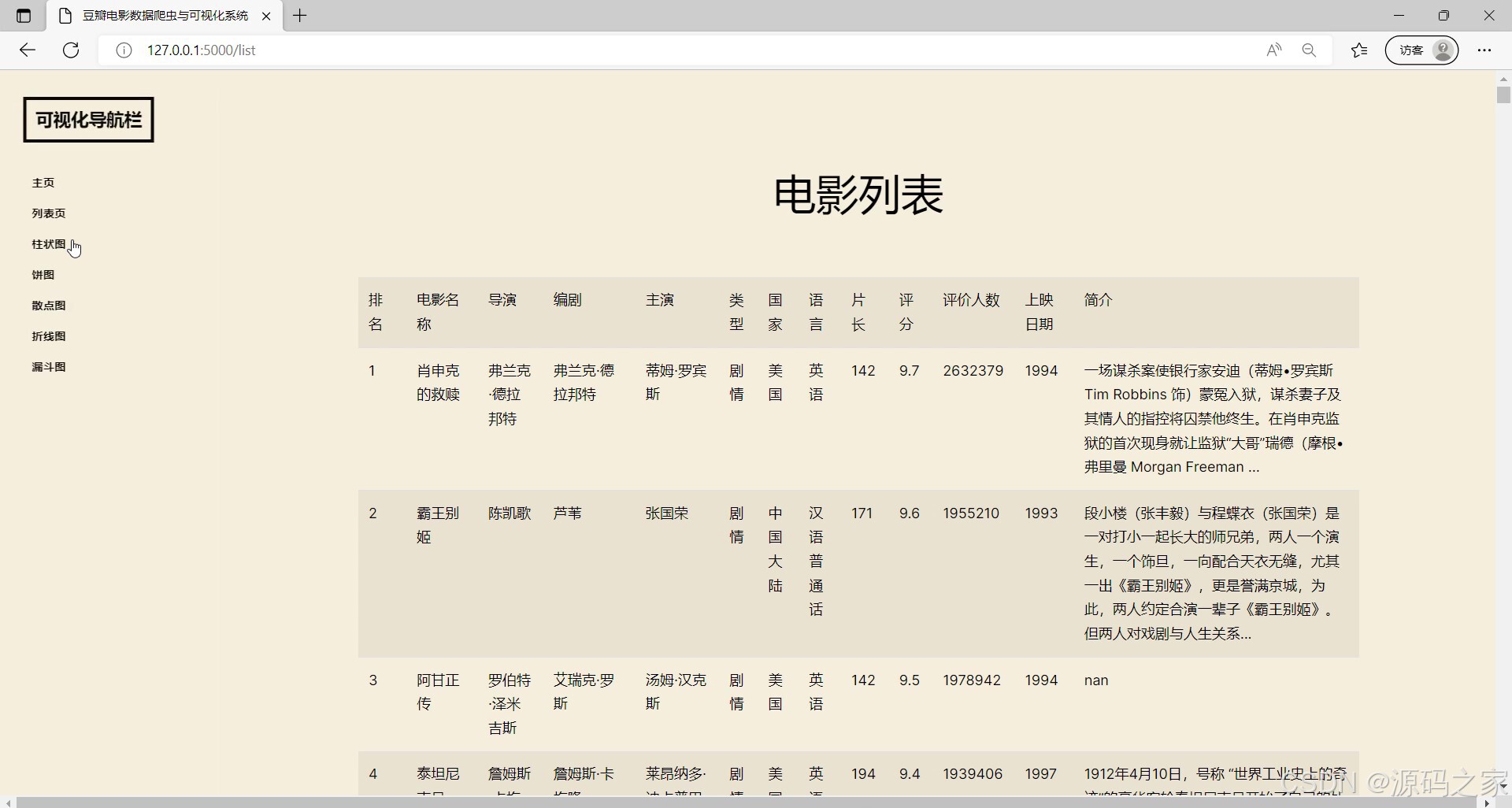
左侧设有可视化导航栏可切换不同功能页面,当前展示电影列表模块,呈现电影的各类基础信息与相关数据,能集中展示多部电影的详细内容,方便用户查看电影的多维度信息。
(3)首页
左侧设有可视化导航栏,包含主页、列表页及多种图表类型的入口,可实现不同功能页面的切换,当前主页展示系统名称及相关信息,作为系统的初始访问界面,为用户提供功能导航的入口。

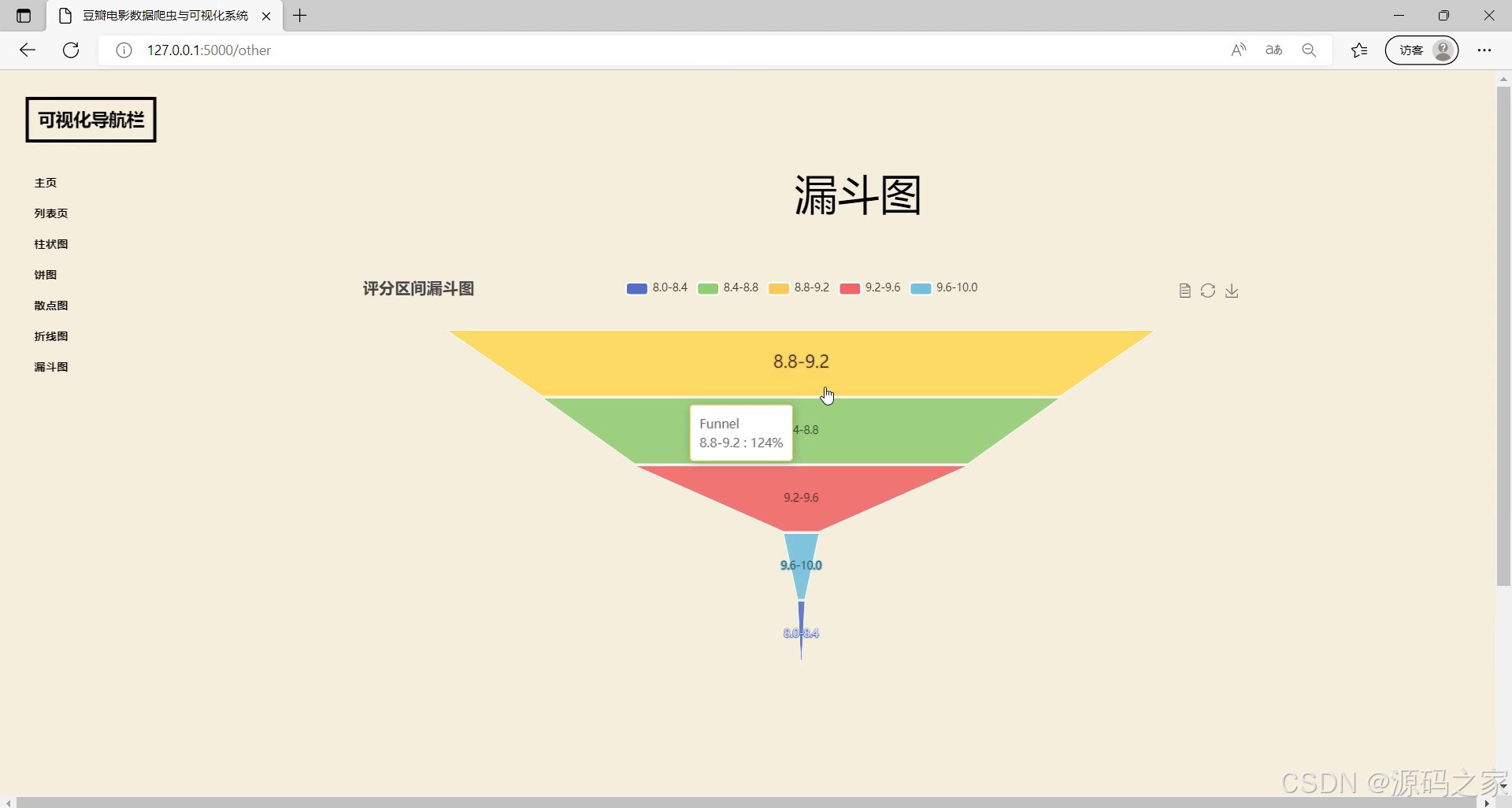
(4)电影数据漏斗图分析
左侧配有可视化导航栏可切换不同功能页面,当前展示的是漏斗图模块,呈现电影评分区间的漏斗图,能直观展示不同评分区间的分布情况,同时支持交互查看对应区间的相关数据,助力用户分析电影评分的分布特征。
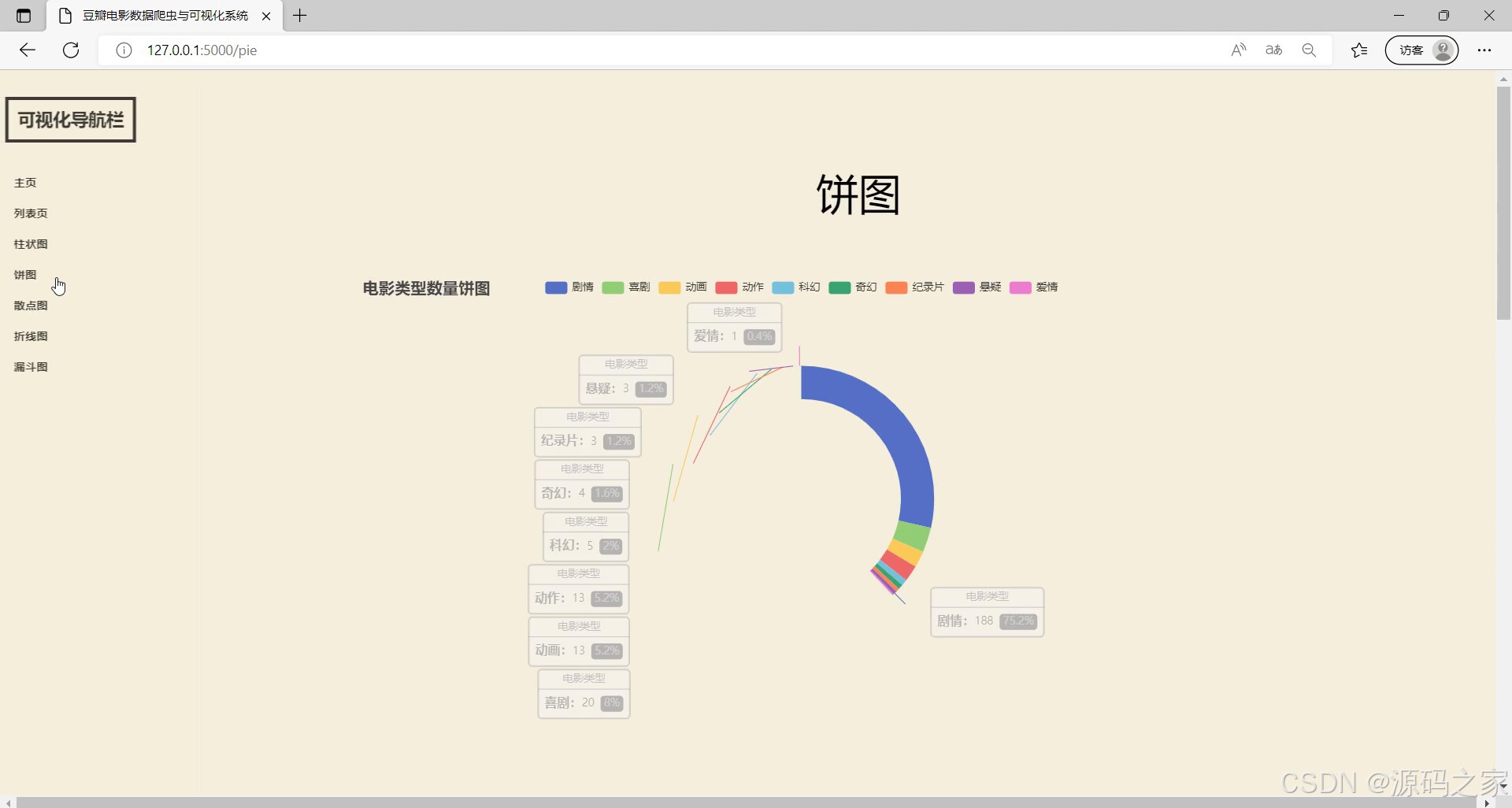
(5)饼图分析
左侧有可视化导航栏可切换不同功能页面,当前展示的是饼图模块,呈现电影类型数量的饼图,能清晰展示不同电影类型的数量占比情况,同时支持交互查看对应类型的相关数据,帮助用户直观了解电影类型的分布特征。
(6)电影类型数据柱状图
左侧设有可视化导航栏可切换不同功能页面,当前展示的是柱状图模块,呈现电影类型数量的柱状图,能直观展示不同电影类型的数量对比情况,帮助用户清晰了解各电影类型的数量分布差异,同时支持交互查看对应类型的详细数据。
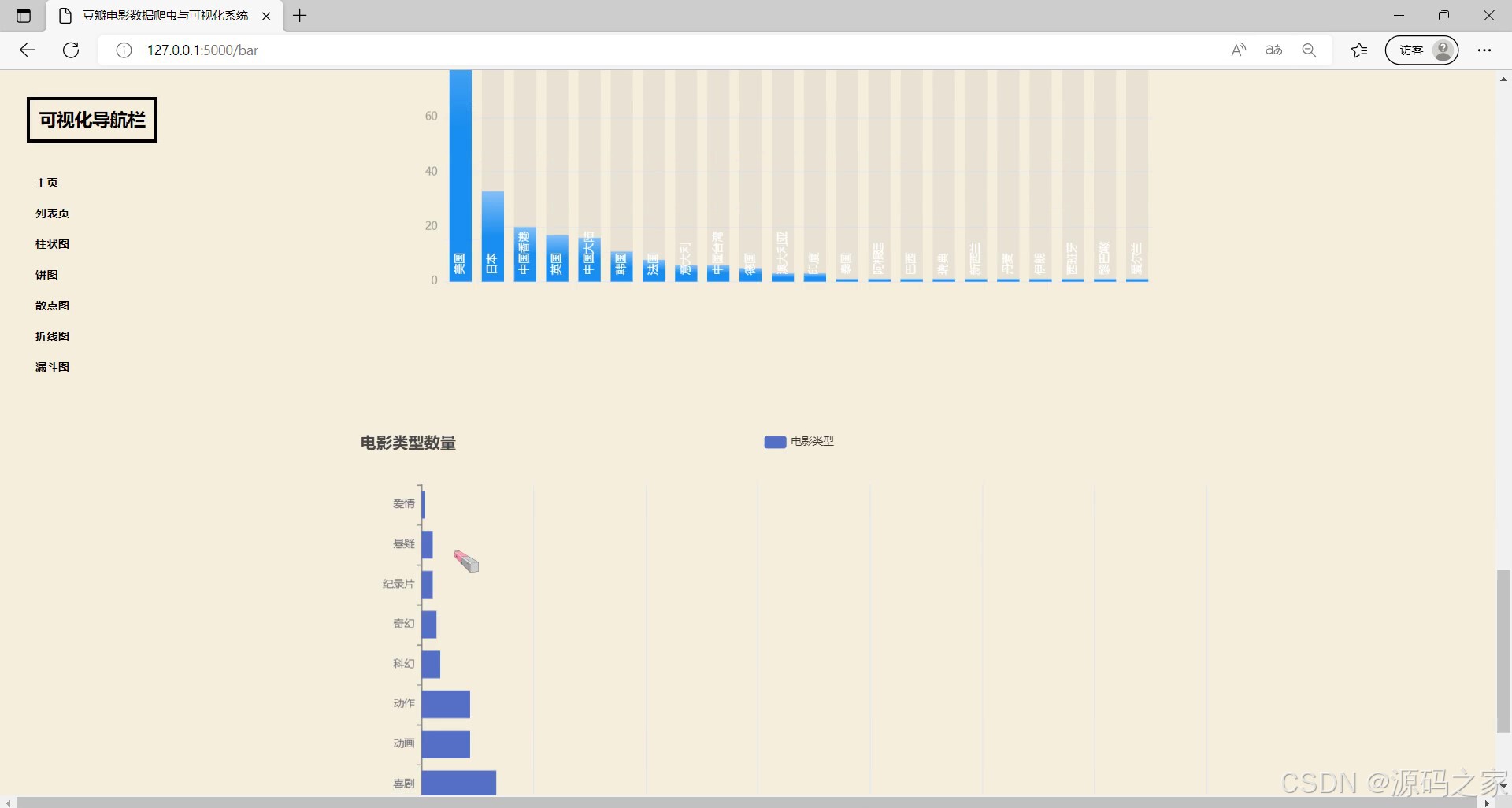
(7)导演作品柱状图分析
左侧配有可视化导航栏可切换不同功能页面,当前展示的是柱状图模块,呈现导演作品数量的相关柱状图,能直观展示不同导演的作品数量对比情况,帮助用户了解导演作品的数量分布,同时支持交互查看对应导演的详细数据。
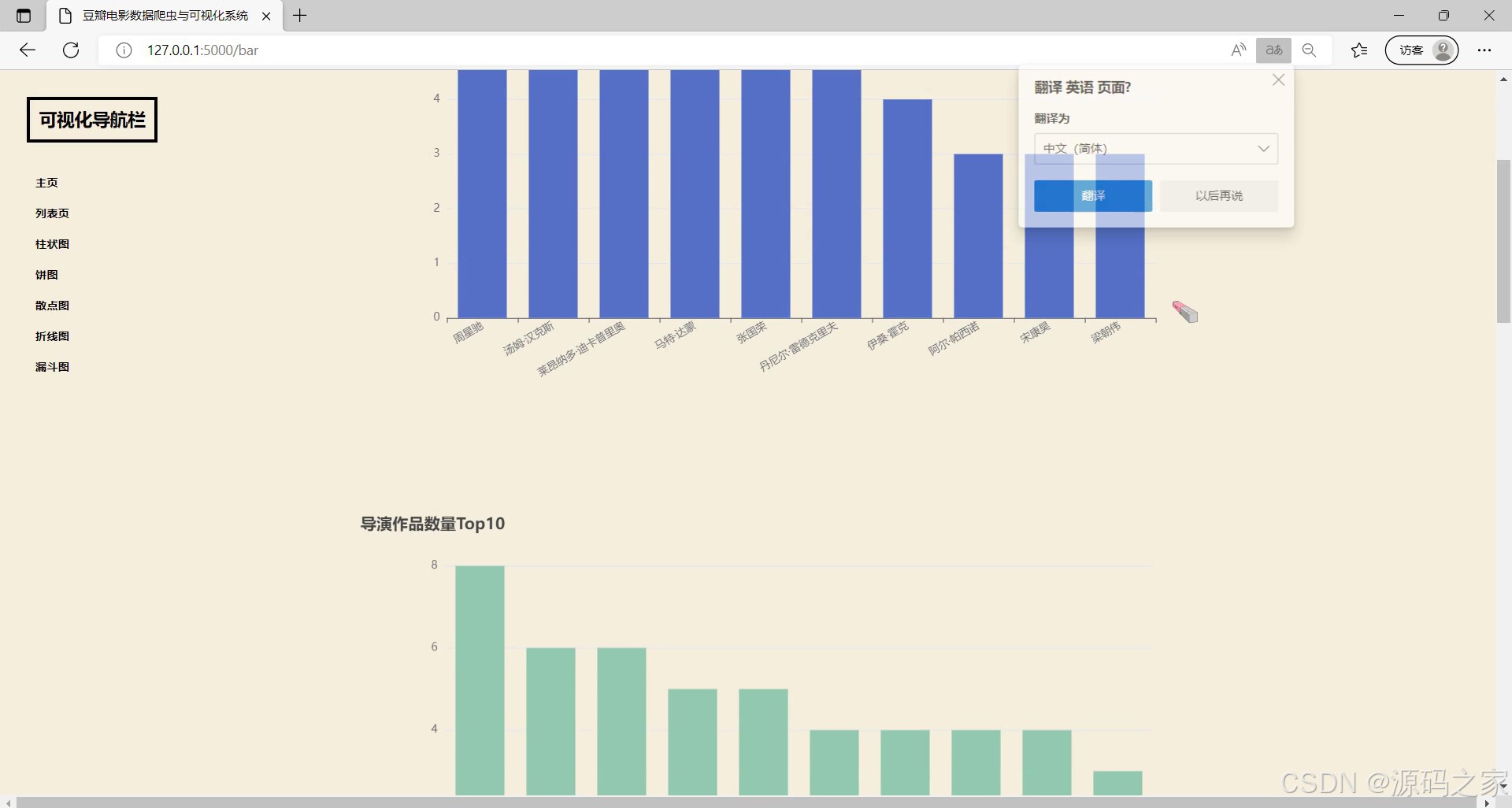
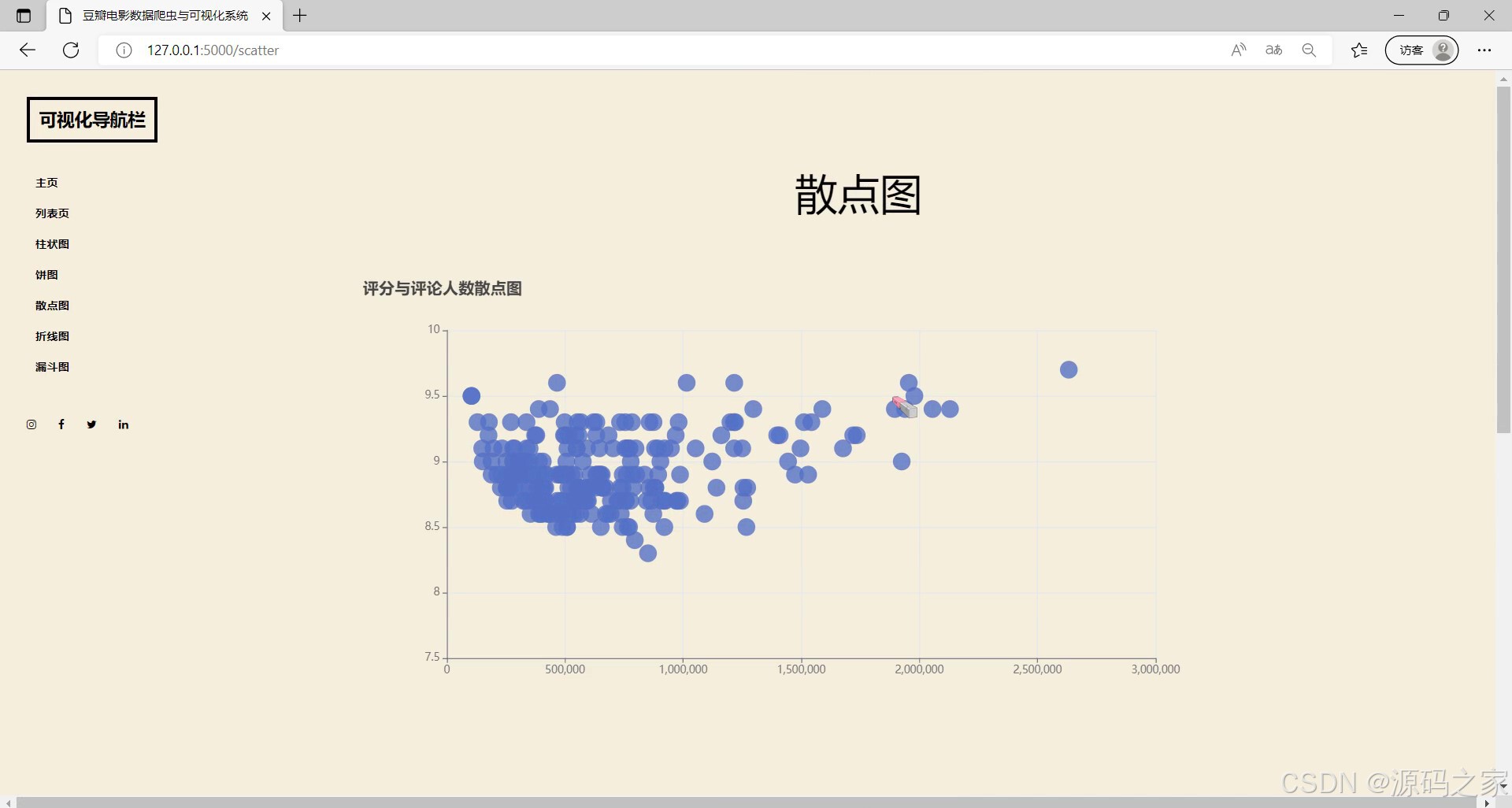
(8)评分与评论人数散点图
左侧设有可视化导航栏可切换不同功能页面,当前展示的是散点图模块,呈现电影评分与评论人数的散点图,能直观呈现两者间的关联分布情况,支持交互查看对应数据点的详细信息,帮助用户分析评分与评论人数的潜在关系。
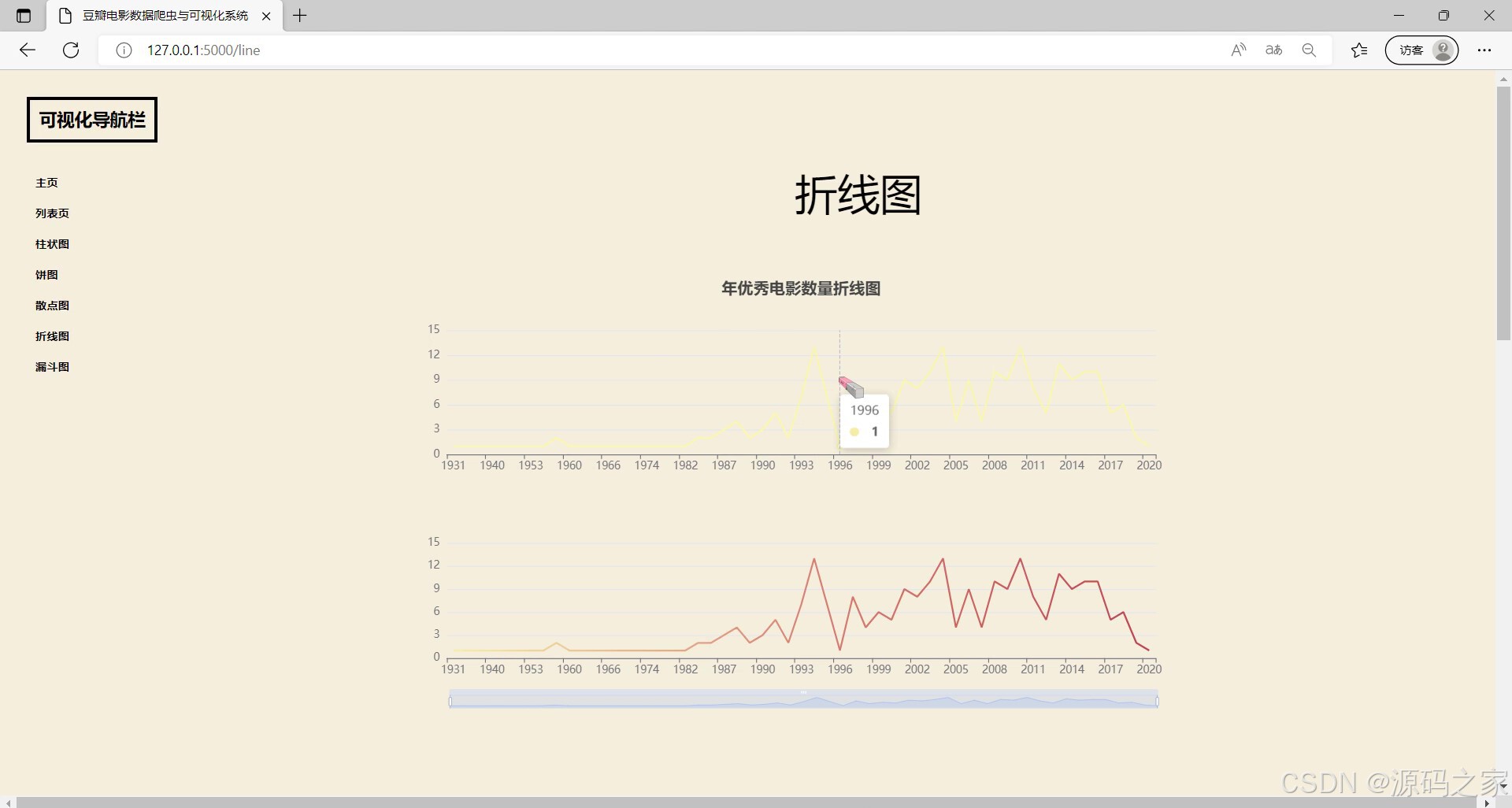
(9)每年电影数量折线图
左侧设有可视化导航栏可切换不同功能页面,当前展示的是折线图模块,呈现每年优秀电影数量的折线图,能直观展示不同年份优秀电影数量的变化趋势,支持交互查看对应年份的详细数据,帮助用户了解电影数量随年份的波动情况。
(10)数据采集页面
展示了爬虫脚本的代码编辑界面,可编写代码实现电影导演、编剧等信息的采集,同时能查看系统运行时的请求日志,支持数据采集相关的代码编写、运行及过程监控,助力完成电影数据的爬取工作。
3、项目说明
一、技术栈
本项目以Python为主要开发语言,基于Flask框架搭建Web应用系统,采用MySQL数据库存储各类电影相关数据,运用requests爬虫技术获取豆瓣电影数据资源,结合Echarts可视化工具将各类数据转化为饼图、柱状图等图表形式直观呈现。
二、功能模块详细介绍
- 电影制片地区饼图分析:模块内设有可视化导航栏可切换不同图表类型,当前页面展示电影制片地区饼图,能够清晰呈现不同地区的制片占比,还可通过交互操作查看对应地区的制片数据详情。
- 电影数据信息:左侧配置可视化导航栏支持切换不同功能页面,当前展示电影列表模块,集中呈现多部电影的各类基础信息与相关数据,方便用户查看电影的多维度信息。
- 首页:作为系统初始访问界面,左侧设有可视化导航栏,包含主页、列表页及多种图表类型的入口,可实现不同功能页面的快速切换,主页核心展示系统名称及相关基础信息,为用户提供功能导航入口。
- 电影数据漏斗图分析:左侧配有可视化导航栏可切换不同功能页面,当前展示漏斗图模块,呈现电影评分区间漏斗图,直观展示不同评分区间的分布情况,支持交互查看对应区间相关数据,助力分析电影评分分布特征。
- 饼图分析:左侧有可视化导航栏可切换不同功能页面,当前展示饼图模块,呈现电影类型数量饼图,清晰展示不同电影类型的数量占比,支持交互查看对应类型相关数据,帮助直观了解电影类型分布特征。
- 电影类型数据柱状图:左侧设有可视化导航栏可切换不同功能页面,当前展示柱状图模块,呈现电影类型数量柱状图,直观展示不同电影类型的数量对比,帮助了解各类型数量分布差异,支持交互查看对应类型详细数据。
- 导演作品柱状图分析:左侧配有可视化导航栏可切换不同功能页面,当前展示柱状图模块,呈现导演作品数量相关柱状图,直观展示不同导演的作品数量对比,帮助了解导演作品数量分布,支持交互查看对应导演详细数据。
- 评分与评论人数散点图:左侧设有可视化导航栏可切换不同功能页面,当前展示散点图模块,呈现电影评分与评论人数散点图,直观呈现两者关联分布情况,支持交互查看对应数据点详细信息,助力分析评分与评论人数的潜在关系。
- 每年电影数量折线图:左侧设有可视化导航栏可切换不同功能页面,当前展示折线图模块,呈现每年优秀电影数量折线图,直观展示不同年份优秀电影数量变化趋势,支持交互查看对应年份详细数据,帮助了解电影数量随年份的波动情况。
- 数据采集页面:展示爬虫脚本的代码编辑界面,可编写代码采集电影导演、编剧等信息,同时能查看系统运行时的请求日志,支持数据采集相关的代码编写、运行及过程监控,助力完成电影数据爬取工作。
三、项目总结
本项目是面向豆瓣电影数据的可视化分析系统,基于Python、Flask构建Web架构,借助requests爬虫采集数据并存储至MySQL数据库,通过Echarts实现多维度可视化分析。系统覆盖数据采集、存储、可视化展示全流程,提供制片地区、电影类型、导演作品等多维度的图表分析功能,还支持数据采集脚本的编写与监控。该系统有效解决了电影数据分散、分析效率低、展示形式不直观的问题,为电影爱好者和行业研究者提供了便捷、易用的数据分析工具,提升了电影数据的分析效率与可视化呈现效果。
4、核心代码
python
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import xlwt
import time
import random
import sqlite3
def main():
baseurl = "https://movie.douban.com/top250?start="
#1.爬取网页
datalist = getData(baseurl)
savepath='豆瓣Top250.xls'
saveData(datalist,savepath)
# askURL(baseurl)
#爬取网页
def getData(baseurl):
#存储详情页链接
href_list =[]
#存储所有电影的信息
datalist = []
'''
0*25=0
1*25=25
...
'''
#调用获取页面信息的函数 10次
for i in range(0,10):
time.sleep(random.random() * 5)
url = baseurl + str(i*25)
#保存网页源码
html = askURL(url)
#2.逐一解析数据
bs = BeautifulSoup(html,'html.parser')
#找到所有的class=item的div,并保存到列表中
item_list = bs.find_all('div',class_='item') #查找符合要求的字符串
for item in item_list:
#正则表达式是字符串匹配,需要把item转化为字符串
item = str(item)
#提取详情页链接
detail_href = re.findall(r'<a href="(.*?)">',item)[0]
# print(detail_href)
href_list.append(detail_href)
# print(href_list)
# print(item)
for href in href_list:
time.sleep(random.random() * 5)
#获取详情页源码
detail_html = askURL(href)
# print(detail_html)
#保存一部电影的所有信息
data = []
# 获取片名
title = ''
try:
title = re.findall(r'"v:itemreviewed">(.*?)</span>', detail_html)[0]
except:
print("获取片名失败")
data.append(title)
# 获取导演名
director = ''
try:
director = re.findall(r'"v:directedBy">(.*?)</a>', detail_html)[0]
except:
print("获取导演信息失败")
data.append(director)
# print(director)
# 获取第一编剧
scriptwriter = ''
try:
scriptwriter = re.findall(r"编剧.*?: <span class='attrs'><a href=.*?>(.*?)</a>", detail_html)[0]
except:
print("获取编剧信息失败")
data.append(scriptwriter)
# 获取第一主演
star = ''
try:
star = re.findall(r'rel="v:starring">(.*?)</a>', detail_html)[0]
except:
print("获取演员信息失败")
data.append(star)
# print(star)
# 获取类型
filmtype = ''
try:
filmtype = re.findall(r'"v:genre">(.*?)</span>', detail_html)[0]
except:
print("获取电影类型信息失败")
data.append(filmtype)
# print(filmtype)
# 获得制片国家
country = ''
try:
country = re.findall(r'<span class="pl">制片国家/地区:</span> (.*?)<br/>', detail_html)[0]
except:
print("获取制片国家失败")
data.append(country)
# print(country)
# 获得语言
lag = ''
try:
lag = re.findall(r'<span class="pl">语言:</span> (.*?)<br/>', detail_html)[0]
except:
print("获取语言失败")
data.append(lag)
# print(lag)
# 获得片长
runtime = ''
try:
runtime = re.findall(r'<span property="v:runtime" content="(.*?)">', detail_html)[0]
except:
print("获取片长失败")
data.append(runtime)
# print(runtime)
# 获得评分 ----------------
score = ''
try:
score = re.findall(r'property="v:average">(.*?)</strong>', detail_html)[0]
except:
print("获取评分失败")
data.append(score)
# print(score)
# 获得评价人数
num = ''
try:
num = re.findall(r'<span property="v:votes">(.*?)</span>人评价', detail_html)[0]
except:
print("获取评价人数失败")
data.append(num)
# print(num)
year = ''
try:
year = re.findall(r'<span class="year">(.*?)</span>', detail_html)[0]
except:
print("获取上映日期失败")
data.append(year)
# print(year)
description = ''
try:
description = re.findall(r'<meta property="og:description" content="(.*?)" />', detail_html)[0]
except:
print("获取简介失败")
data.append(description)
# print(description)
image = ''
try:
image = re.findall(r'<meta property="og:image" content="(.*?)" />', detail_html)[0]
except:
print("获取图片失败")
data.append(image)
# print(image)
print(data)
datalist.append(data)
# print(datalist)
return datalist
#得到指定一个URL的网页内容
def askURL(url):
#模拟浏览器头部信息,向豆瓣服务器发送消息
# headers = {
# 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
# }
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44'
}
content = ''
#请求对象
req = urllib.request.Request(url,headers = headers)
try:
#得到响应信息
response = urllib.request.urlopen(req)
#读取响应信息
content = response.read().decode('utf-8')
# print(content)
except urllib.error.URLError as e:
#hasattr 检查指定属性是否存在
if hasattr(e,'code'):
print(e.code)
if hasattr(e,'reason'):
print(e.reason)
return content
def saveData(datalist,savepath):
# 创建workbook对象
workbook = xlwt.Workbook(encoding='utf-8',style_compression=0)
# 创建工作表
worksheet = workbook.add_sheet('豆瓣电影Top250',cell_overwrite_ok=True)
col = ('电影名','导演','编剧','主演','类型','制片国家','语言','片长','评分','评价人数','上映日期','简介','图片')
for i in range(0,13):
# 写入表头
worksheet.write(0,i,col[i])
for i in range(0,250):
print('第%d条'%(i+1))
data = datalist[i]
for j in range(0,13):
worksheet.write(i+1, j, data[j])
workbook.save(savepath) #保存
if __name__ == '__main__':
main()5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻